点击关注《golang技术实验室》公众号****,将****获取更多干货
介绍
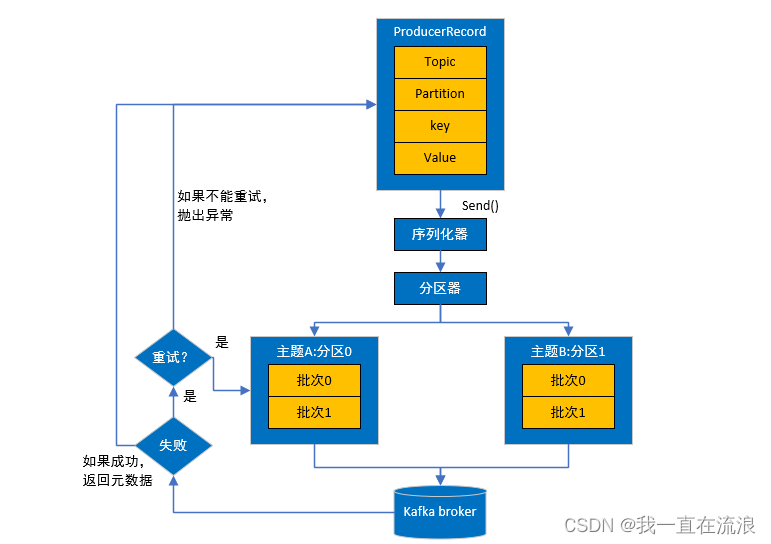
Kafka是一种高性能的分布式流处理平台,它的集群工作原理如下:
假设你是一个快递员,Kafka集群就是一个快递中转站。在这个中转站中,有很多个小窗口(Broker),每个窗口有一个工作人员(Broker)负责接收和分发快递。
-
- 发送快递(Producer):你的工作是将快递从不同的地方收集起来,然后送到中转站的一个窗口。你可以一次送多个快递,每个快递都有一个编号(消息的键),内容(消息的值)和地址(主题)。你将这些快递递给窗口工作人员。
- 中转站(Broker):窗口工作人员负责接收你送来的快递,并将它们存放在中转站中。这些快递被存放在不同的箱子中,每个箱子都有一个编号(分区)。中转站会确保快递的安全存储,并且可以将快递复制到其他窗口(副本)中,以防止数据丢失。
- 消费快递(Consumer):有些人(消费者)来到中转站,希望取走他们关心的快递。他们告诉窗口工作人员他们关心的快递的编号和地址,窗口工作人员会告诉他们快递在哪个箱子(分区)中,并将快递递给他们。消费者可以按照自己的节奏和需要来取走快递。
- 管理和协调(ZooKeeper):中转站还有一个管理员(ZooKeeper),负责监控中转站的状态,并管理分区和消费者的信息。管理员会确保每个窗口工作正常,箱子(分区)均匀分布,以及消费者获取快递的正确信息。总结起来,Kafka集群的工作原理就是:生产者将消息送到中转站的窗口,窗口工作人员将消息存放在不同的箱子(分区)中,消费者可以根据自己的需求取走他们关心的消息。管理员负责管理和协调整个中转站的运作。这样的设计使得Kafka集群具有高吞吐量、低延迟和高可靠性的特点,非常适合处理大规模的实时数据流。
部署
这边kafka集群基于docker部署,所以要先安装docker
| IP | 角色 | 备注 |
|---|---|---|
| 192.168.2.210 | kafka-01 | |
| 192.168.2.211 | kafka-02 | |
| 192.168.2.212 | kafka-03 |
安装docker-compose
curl -L "https://github.com/docker/compose/releases/download/1.25.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
docker-compose version # 查看版本信
安装docker
yum -y install yum-utils
yum-config-manager \ --add-repo \ http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.rep
yum install docker-ce docker-ce-cli containerd.io
systemctl start docker
systemctl enable docker
安装zookeeper集群
在每台机器上安装一个zookeeper和一个kafka组成整体的集群。.
进入三台服务器,创建目录/data/local/zk,并创建zk.yml文件
mkdir -p /data/local/kafka/zk/data/ && chmod -R 777 /data/local/kafka/zk/data/
cd /data/local/kafka/zk
touch zk.yml
zk.yml是docker-compose的编排文件,三台服务器的zk.yml文件内容分别如下:
192.168.2.210中的zk.yml
version: '3.1'
services:
zk1:
image: 'zookeeper:3.7'
restart: always
hostname: zoo1
container_name: zk1
network_mode: host
ports:
- 2181:2181
- 2888:2888
- 3888:3888
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=192.168.2.210:2888:3888;2181 server.2=192.168.2.211:2888:3888;2181 server.3=192.168.2.212:2888:3888;2181
volumes:
- /data/local/kafka/zk/data:/data
192.168.2.211中的zk.yml
version: '3.1'
services:
zk2:
image: 'zookeeper:3.7'
restart: always
hostname: zoo2
container_name: zk2
network_mode: host
ports:
- 2181:2181
- 2888:2888
- 3888:3888
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=192.168.2.210:2888:3888;2181 server.2=192.168.2.211:2888:3888;2181 server.3=192.168.2.212:2888:3888;2181
volumes:
- /data/local/kafka/zk/data:/data
192.168.2.212中的zk.yml
version: '3.1'
services:
zk1:
image: 'zookeeper:3.7'
restart: always
hostname: zoo3
container_name: zk3
network_mode: host
ports:
- 2181:2181
- 2888:2888
- 3888:3888
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=192.168.2.210:2888:3888;2181 server.2=192.168.2.211:2888:3888;2181 server.3=192.168.2.212:2888:3888;2181
volumes:
- /data/local/kafka/zk/data:/data
分别在三台机器的/data/local/zk目录下执行以下命令,开启zk集群
docker-compose -f zk.yml up -d
进入容器内部查看是否启动成功:
docker exec -it zk1 bash
zkServer.sh status
docker exec -it zk2 bash
zkServer.sh status
docker exec -it zk3 bash
zkServer.sh status
如果启动成功,可以看到如下内容:

至此,一个部署在三台服务器上的3节点zookeeper集群就搭建成功了。
安装kafka集群
进入三台服务器,创建目录/data/local/kafka,并创建zk.yml文件
mkdir -p /data/local/kafka/kafka/data/ && chmod -R 777 /data/local/kafka/kafka/data/
cd /data/local/kafka/kafka
touch kafka.yml
kafka.yml是docker-compose的编排文件,三台服务器的kafka.yml文件内容分别如下:
192.168.2.210中的kafka.yml
version: '2'
services:
k1:
image: 'bitnami/kafka:3.2.0'
restart: always
container_name: k1
network_mode: host
ports:
- 9092:9092
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=192.168.2.210:2181,192.168.2.211:2181,192.168.2.212:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_BROKER_ID=1
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.210:9092
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
- KAFKA_CFG_NUM_PARTITIONS=3
- KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3
volumes:
- /data/local/kafka/kafka/data:/bitnami/kafka/data
192.168.2.211中的kafka.yml
version: '2'
services:
k1:
image: 'bitnami/kafka:3.2.0'
restart: always
container_name: k2
network_mode: host
ports:
- 9092:9092
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=192.168.2.210:2181,192.168.2.211:2181,192.168.2.212:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_BROKER_ID=1
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.211:9092
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
- KAFKA_CFG_NUM_PARTITIONS=3
- KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3
volumes:
- /data/local/kafka/kafka/data:/bitnami/kafka/data
192.168.2.212中的kafka.yml
version: '2'
services:
k1:
image: 'bitnami/kafka:3.2.0'
restart: always
container_name: k3
network_mode: host
ports:
- 9092:9092
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=192.168.2.210:2181,192.168.2.211:2181,192.168.2.212:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_BROKER_ID=1
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.212:9092
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
- KAFKA_CFG_NUM_PARTITIONS=3
- KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3
volumes:
- /data/local/kafka/kafka/data:/bitnami/kafka/data
分别在三台机器的/data/local/kafka目录下执行以下命令,开启kafka集群
docker-compose -f kafka.yml up -d
创建topic并验证消费者和生产者,进入192.168.2.210的kafka容器内部
docker exec -it k1 bash
cd /opt/bitnami/kafka/bin
./kafka-topics.sh --create --bootstrap-server 192.168.2.210:9092 --replication-factor 1 --partitions 3 --topic devops11
进入其他机器的kafka容器内部,查看是否存在刚创建的topic,如果存在则说明Kafka集群搭建成功。
docker exec -it k2 bash
kafka-topics.sh --list --bootstrap-server 192.168.2.211:9092
docker exec -it k3 bash
kafka-topics.sh --list --bootstrap-server 192.168.1.212:9092

![P4381 [IOI2008] Island (求基环树直径)](https://img-blog.csdnimg.cn/9bad0e782a124e44921beff6fbc798b8.jpeg#pic_center)









![【LeetCode】数据结构题解(12)[用栈实现队列]](https://img-blog.csdnimg.cn/cd5db38a49474116b0b4f2c9246e5ada.png)