文章目录
- 前置安装
- Huggingface介绍
- NLP模块分类
- transformer流程
- 模块使用详细讲解
- tokennizer
- model
- datasets
- Trainer
- Huggingface使用
- 网页直接体验
- API调用
- 本地调用(pipline)
- 本地调用(非pipline)
前置安装
-
anaconda安装
-
使用conda创建一个新环境并安装
pytorch打开链接 https://pytorch.org/get-started/locally/, 选择对应的系统即可
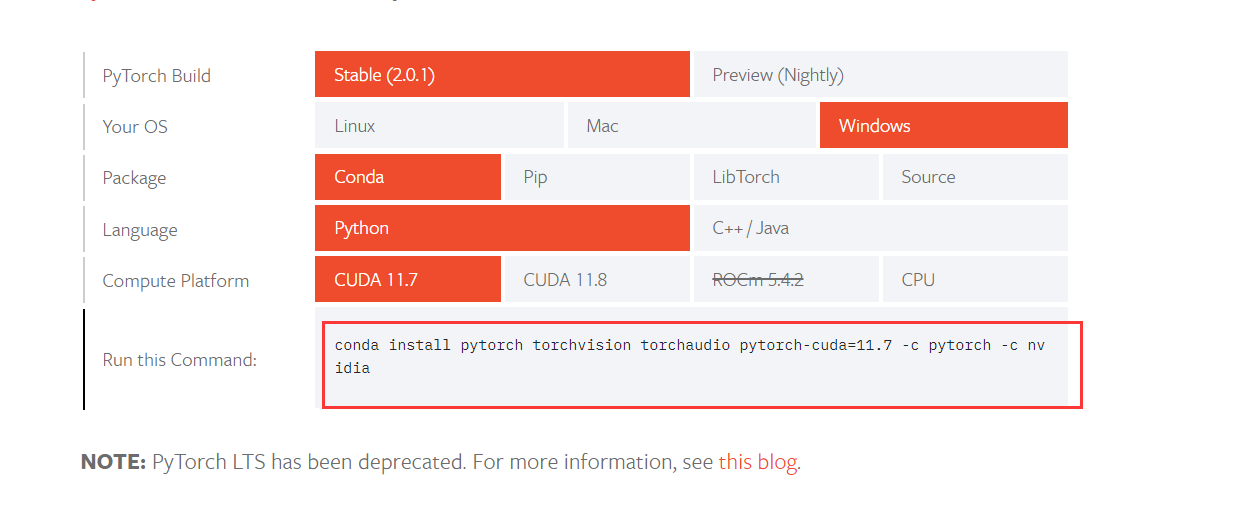
-
安装
transformers和datasets
pip install transformers
pip install datasets
这两个是huggingface最核心的模块
- 安装
torch
pip install torch
Huggingface介绍
本次只介绍 NLP(Natural Language Processing)相关的模型,其他的,如 文本生成语音,文本生成图片相关的模型不做过多介绍,使用起来基本都大差不差的。也可以直接阅读Huggingface提供的官方文档:https://huggingface.co/learn/nlp-course/zh-CN/chapter0/1?fw=pt
NLP模块分类
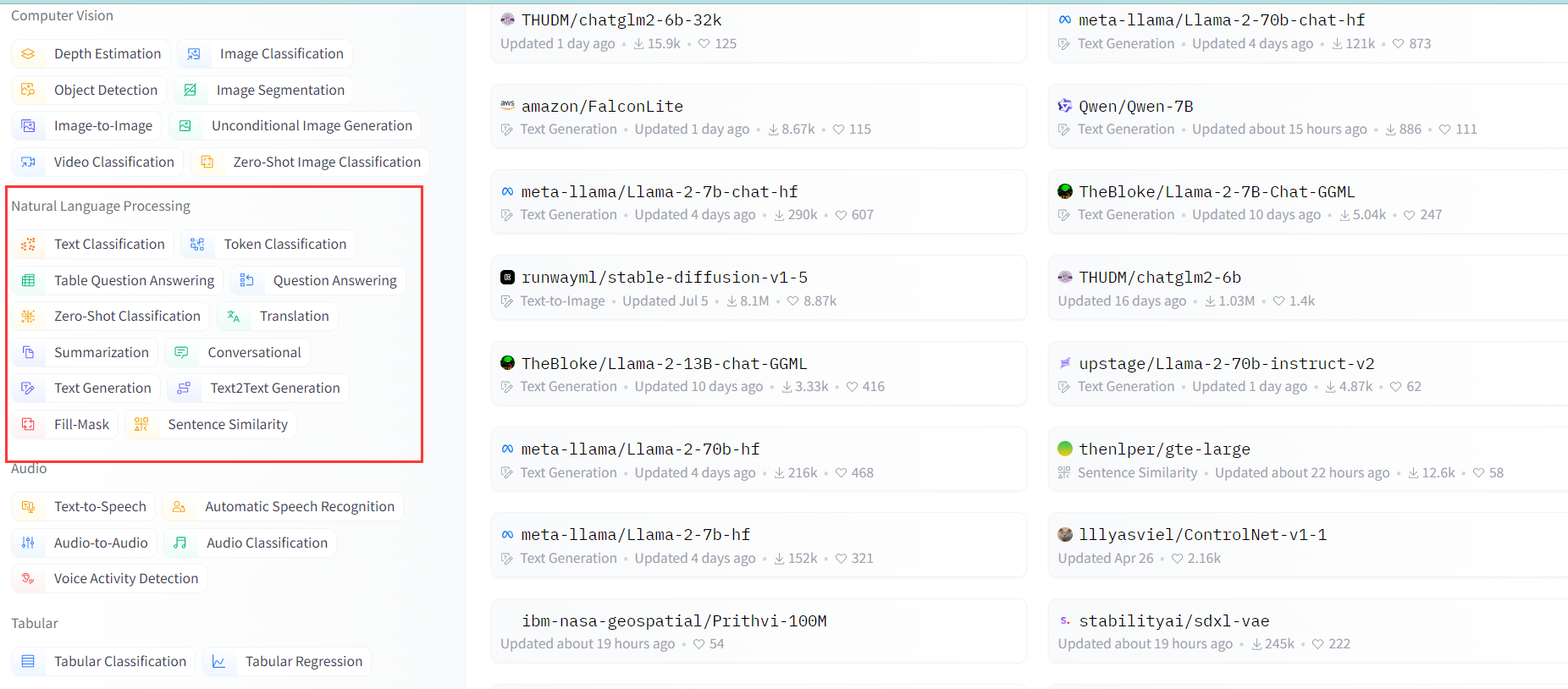
NLP 一共有以下几大模型类别,每个类别下模型做的事情也不一样,有的是用来翻译的,有的是分类,而有的是文本生成,具体有那些可通过这个链接查看:https://huggingface.co/models
- text-classification 文本分类,给一段文本进行打标分类
- feature-extraction 特征提取:把一段文字用一个向量来表示
- fill-mask 填词:把一段文字的某些部分mask住,然后让模型填空
- ner 命名实体识别:识别文字中出现的人名地名的命名实体
- question-answering 问答:给定一段文本以及针对它的一个问题,从文本中抽取答案
- summarization 摘要:根据一段长文本中生成简短的摘要
- text-generation文本生成:给定一段文本,让模型补充后面的内容
- translation 翻译:把一种语言的文字翻译成另一种语言
transformer流程
一般transformer模型有三个部分组成:1.tokennizer,2.Model,3.Post processing

- 分词器将我们输入的信息转成 Input IDs
- 将Input IDs输入到模型中,模型返回预测值
- 将预测值输入到后置处理器中,返回我们可以看懂的信息
模块使用详细讲解
tokennizer
官网文档地址
分词器的职责
- 将输入拆分为单词、子单词或符号(如标点符号),称为标记(token)
- 将每个标记(token)映射到一个整数
- 添加可能对模型有用的其他输入
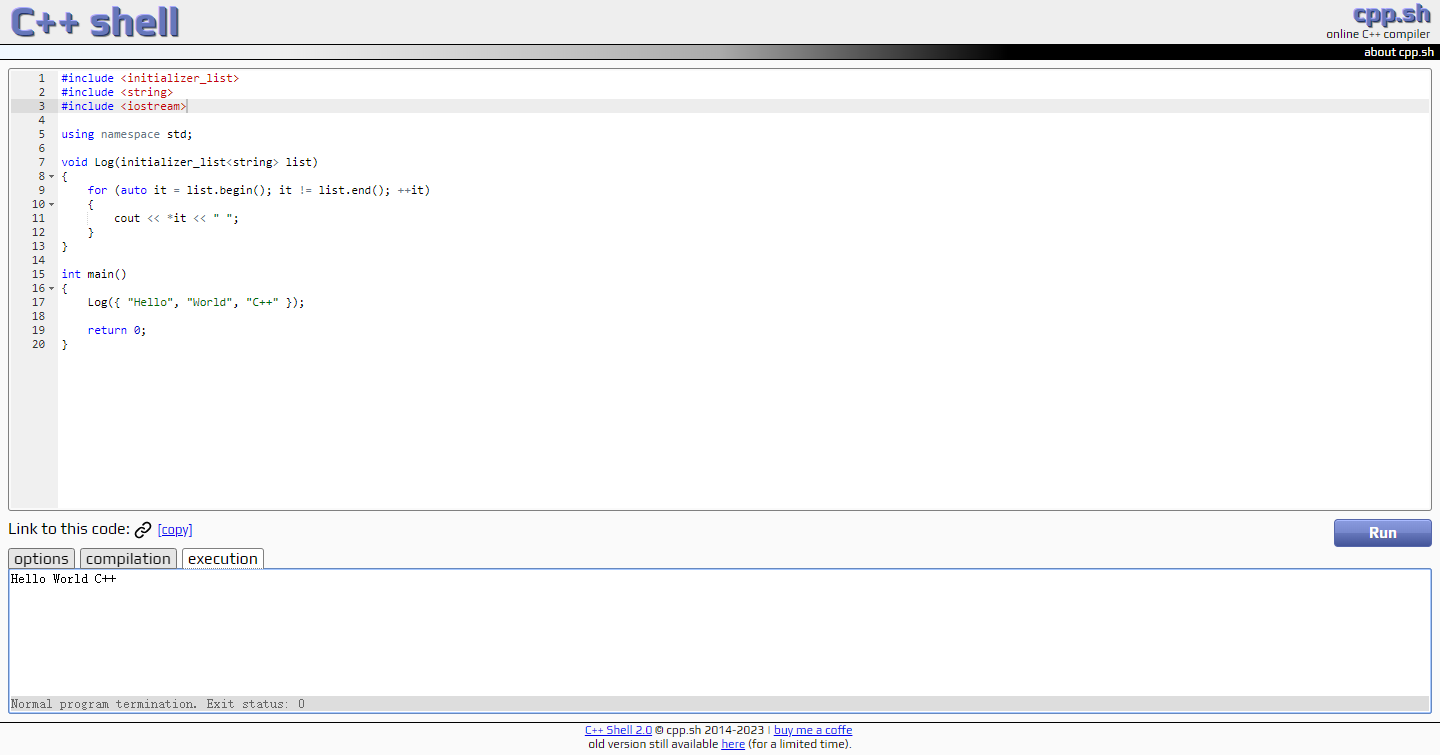
代码使用
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"I love you",
"I love you so much",
]
inputs = tokenizer(raw_inputs, max_length=8, padding=True, truncation=True, return_tensors="pt")
print(inputs)
'''
输出{'input_ids': tensor([[ 101, 1045, 2293, 2017, 102, 0, 0],
[ 101, 1045, 2293, 2017, 2061, 2172, 102]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 0, 0], [1, 1, 1, 1, 1, 1, 1]])}
'''
# 将ids反解码
output = tokenizer.decode([ 101, 1045, 2293, 2017, 102])
print(output )
## 输出:[CLS] i love you [SEP]
输出结果说明
input_ids: 也就是输入到模型里的数据,每次数字都对应我们输入的一个词,这里可以看到 我们输入了 3个词,但输出了8个数字,这是因为 最两个0是用来补齐到最大长度的,而 除此之外的 首尾 数字 是个标识符,101标识这是做文本分类,102表示这行句子结束了attention_mask: 是有效运算字符标识,1表示ids里这个位置的字符是有效的,0表示这个位置是补齐的
tokenizer参数说明
max_length: 表示每一个的ids数组的最大长度padding: 表示是否需要补齐位数truncation: 表示超过最大长度后是否需要阶段return_tensors:表示返回的tensor为pytorch,也可以写tf表示 tensorflow
model
通过该地址可查看Huggingface的所有模型:https://huggingface.co/models
模型职责
模型Head将隐藏状态的高维向量作为输入,并将其投影到不同的维度。它们通常由一个或几个线性层组成。下图是模型的基本逻辑

在此图中,模型由其嵌入层和后续层表示。嵌入层将标记化输入中的每个输入ID转换为表示关联标记(token)的向量。后续层使用注意机制操纵这些向量,以生成句子的最终表示。
代码使用
## 最简单的使用
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
如果我们需要一个带有序列分类头的模型(能够将句子分类为肯定或否定)。我们实际上不会直接使用AutoModel类,而是使用AutoModelForSequenceClassification:
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
import torch
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
# 文本输入
raw_inputs = [
"I love you",
"I love you so much",
]
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# 执行分词器
inputs = tokenizer(raw_inputs, max_length=8, padding=True, truncation=True, return_tensors="pt")
# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
# 为了获得每个位置对应的标签,我们可以检查模型配置的id2label属性(下一节将对此进行详细介绍):
print(model.config.id2label)
# 输出 {0: 'NEGATIVE', 1: 'POSITIVE'} 表示越靠近0是负面的,越靠近1是正向的
# 调用模型输出
outputs = model(**inputs)
## 将模型输出的预测值logits给到torch,返回我们可以看懂的数据
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
# 输出 tensor([[1.3436e-04, 9.9987e-01],[1.3085e-04, 9.9987e-01]], grad_fn=<SoftmaxBackward0>)
# 第一句话,NEGATIVE=0.0001, POSITIVE=0.99 所以第一句话大概率是正向的
Transformers中有许多不同的体系结构,每种体系结构都是围绕处理特定任务而设计的。以下是一个非详尽的列表:
- *Model (retrieve the hidden states)
- *ForCausalLM
- *ForMaskedLM
- *ForMultipleChoice
- *ForQuestionAnswering
- *ForSequenceClassification
- *ForTokenClassification
- 其他
datasets
通过该地址可查看Huggingface的所有数据集:https://huggingface.co/datasets
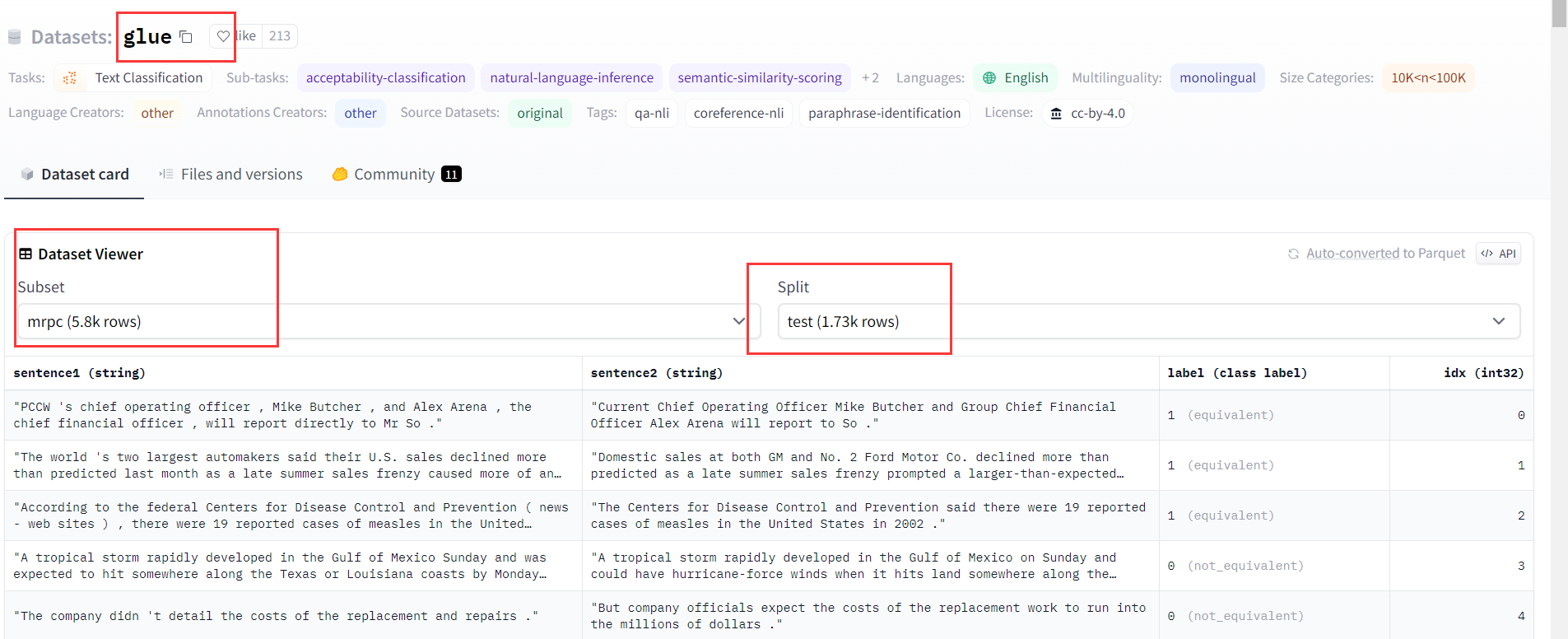
加载数据集
from datasets import load_dataset
dataset = load_dataset("glue", "mrpc")
print(dataset)
'''
输出
DatasetDict({
//训练的数据集
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
// 校验数据集
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
// 测试数据集
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})
'''
加载本地或远端数据集
from datasets import load_dataset
## 加载本地数据集
local_data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
squad_it_dataset = load_dataset("json", data_files=local_data_files , field="data")
## 加载外部远端上数据集
url = "https://github.com/crux82/squad-it/raw/master/"
data_files = {
"train": url + "SQuAD_it-train.json.gz",
"test": url + "SQuAD_it-test.json.gz",
}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
数据集操作
官方文档:https://huggingface.co/learn/nlp-course/zh-CN/chapter3/2?fw=pt
from datasets import load_dataset
drug_sample= load_dataset("glue", "mrpc")
print(drug_sample)
# 抽样1000个数据,并打印前3个
print(drug_sample["train"].shuffle(seed=42).select(range(1000))[:3])
def tokenizer_datset(data):
return tokenizer(data["sentence1"], data["sentence2"], truncation=True)
# 对集合里每个数据进行分词处理
drug_sample = drug_sample.map(tokenizer_datset, batched=True)
print(drug_sample)
'''
输出, 可以看到分词器产生的列(input_ids,attention_mask)已经加到数据集里了
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx', 'input_ids', 'attention_mask'],
num_rows: 1000
})
'''
# 移除不需要的列
drug_sample = drug_sample.remove_columns(["sentence1", "sentence2", "idx"])
# 对列进行改名, label => labels
drug_sample = drug_sample.rename_column("label", "labels")
Trainer
官网文档:https://huggingface.co/learn/nlp-course/zh-CN/chapter3/3?fw=pt
代码使用
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding,TrainingArguments, AutoModelForSequenceClassification, Trainer
# 获取数据集
raw_datasets = load_dataset("glue", "mrpc")
# 加载分词器
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# 对集合里的数据进行分词
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
# 数据打包器
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
# 获取train参数
training_args = TrainingArguments("test-trainer")
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
# 开始训练
trainer.train()
为了查看模型在每个训练周期结束的好坏,我们可以使用compute_metrics()函数定义一个新的 Trainer
# 测算模型的准确率
import evaluate
def compute_metrics(eval_preds):
metric = evaluate.load("glue", "mrpc")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# evaluation_strategy,设置评估环节为epoch,这样每个训练周期结束就会测算下目前模型的准确率
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
自定义Trainer
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
from tqdm.auto import tqdm
import torch
from torch.utils.data import DataLoader
# 模型
checkpoint = "bert-base-uncased"
# 定义数据集
raw_datasets = load_dataset("glue", "mrpc")
# 定义分词器
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# 数据集预处理
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# 训练数据集加载器
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator
)
# 评估数据集加载器
eval_dataloader = DataLoader(
tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator
)
# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
# 优化器和学习率调度器,学习率调度器只是从最大值 (3e-5) 到 0 的线性衰减
optimizer = AdamW(model.parameters(), lr=3e-5)
# 如果支持GPT则使用GPU进行训练
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
# 训练周期为3个
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
# 加个进度条
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
分布式训练
使用
Accelerator进行分布式训练
from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
accelerator = Accelerator()
train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
train_dataloader, eval_dataloader, model, optimizer
)
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
Huggingface使用
网页直接体验
可以在某个模型下直接体验该模型的效果

API调用
这个调用每天有量级限制
- 获取token
- 通过API访问
import os, requests, json
API_TOKEN = os.environ.get("HUGGINGFACE_API_KEY")
model = "google/flan-t5-xxl"
API_URL = f"https://api-inference.huggingface.co/models/{model}"
headers = {"Authorization": f"Bearer {API_TOKEN}", "Content-Type": "application/json"}
def query(payload, api_url=API_URL, headers=headers):
data = json.dumps(payload)
response = requests.request("POST", api_url, headers=headers, data=data)
return json.loads(response.content.decode("utf-8"))
question = "Please answer the following question. What is the capital of France?"
data = query({"inputs" : question})
print(data)
本地调用(pipline)
本地调用需要将model下载到本地,好处是可以自己训练,微调参数
不过有的模型比较大,下载起来会比较慢
pipline 背后的流程: tokenizer => model => post-processing
from transformers import pipeline
# 进行文本分类,模型为:finiteautomata/bertweet-base-sentiment-analysis
classifier = pipeline("text-classification", model="finiteautomata/bertweet-base-sentiment-analysis")
res = classifier(["I'd love to learn the HuggingFace course", "fuck you"])
print(res)
本地调用(非pipline)
如果不使用pipeline 也可以一步一步调用
from transformers import AutoTokenizer
from transformers import AutoModel
import torch
# 定义使用的模型
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
## 我们的输入
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
# tokenizer 定义分词词,一般分词器和model是一一对应的
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# 用分词器进行分词
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
# 加载模型
model = AutoModel.from_pretrained(checkpoint)
## 调用模型
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
# post-processing, 后置处理,将模型输出的信息转成我们可以看懂的数据
predictions = torch.nn.functional.softmax(outputs[0], dim=-1)
print(predictions)


![[保研/考研机试] KY187 二进制数 北京邮电大学复试上机题 C++实现](https://img-blog.csdnimg.cn/2ba7c4a470d3470eac0849d5ede4a2df.png)