一、添加Kafka Connector依赖
pom.xml 中添加
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
二、启动Kafka集群
启动zookeeper
./bin/zookeeper-server-start.sh config/zookeeper.properties
启动 kafka
./bin/kafka-server-start.sh config/server.properties
启动一个消费者
./bin/kafka-console-consumer.sh --bootstrap-server hadoop100:9092 --topic topic_sensor
三、Flink sink 到 kafka
package com.lyh.flink06;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
public class SinkToKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<String> dataStreamSource = env.fromElements("a-----------------------------", "b*****************************");
DataStreamSource<Integer> integerDataStreamSource = env.fromElements(1, 2);
ConnectedStreams<String, Integer> datain = dataStreamSource.connect(integerDataStreamSource);
datain.getFirstInput().addSink(new FlinkKafkaProducer<String>("hadoop100:9092","topic_sensor",new SimpleStringSchema()));
env.execute();
}
}
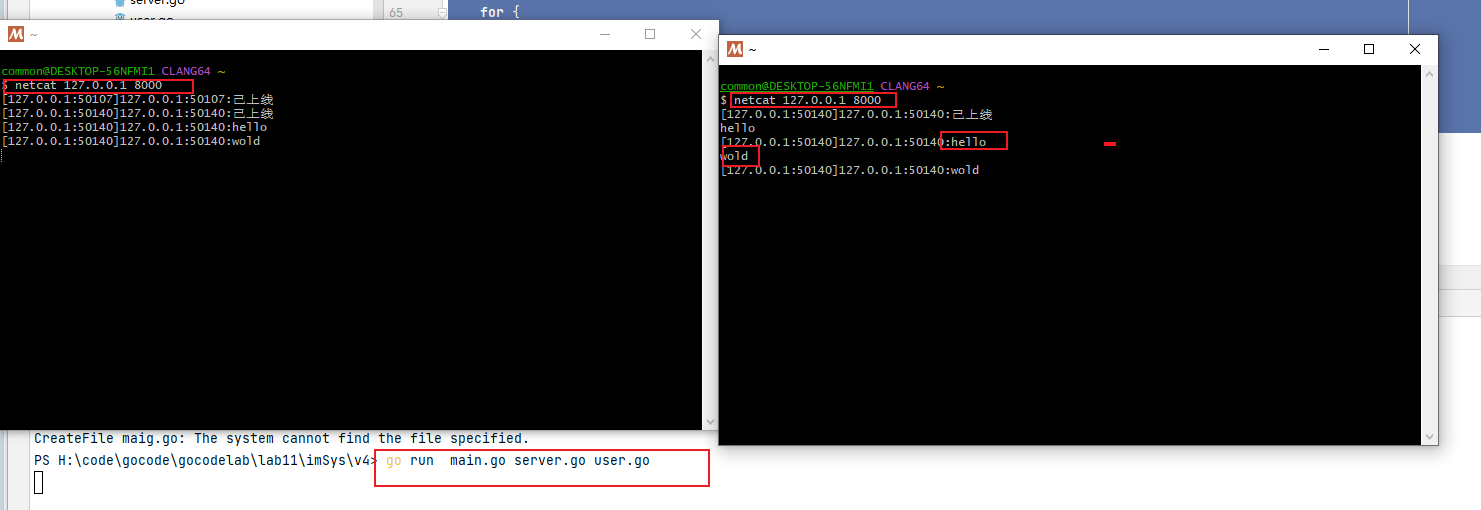
运行程序后看到消费者消费成功








![[QT编程系列-41]:Qt QML与Qt widget 深入比较,快速了解它们的区别和应用场合](https://img-blog.csdnimg.cn/1c9f91c427594e3783bf7ac581cc612a.png)
