目录
- 1.什么是AWK
- 2.正则表达式
- 3.语法
- 4.内置变量
- 示例
- printf命令
- 5.复现awk经典实例
- (1).插入几个新字段
- (2).格式化空白
- (3).筛选IPv4地址
- (4).筛选给定时间范围内的日志
1.什么是AWK
awk、grep、sed是linux操作文本的三大利器,合称文本三剑客。三者的功能都是处理文本,但侧重点各不相同,其中属awk功能最强大,但也最复杂。grep更适合单纯的查找或匹配文本,sed更适合编辑匹配到的文本,awk更适合格式化文本,对文本进行较复杂格式处理。三剑客最好要搭配神兵利器正则表达式一起使用。
2.正则表达式

3.语法
- 1.awk
'program'` `var=valuefile… - 2.awk
file…`` - 3.awk
action;… }’
语法说明 - 1.pattern部分决定动作语句何时触发及触发事件:BEGIN、END
2.action 对数据进行处理,放在{}内指明:print、printf
3.最常用的是 print,默认以空白字符分隔
4.options 参数:输入分隔符,默认以空白字符分隔,通过 -F 选项来执行分隔符
4.内置变量
- FS :输入字段分隔符,默认为空白字符
- OFS :输出字段分隔符,默认为空白字符
- RS :输入记录分隔符,指定输入时的换行符,原换行符仍有效
- ORS:输出记录分隔符,输出时用指定符号代替换行符
- NF :字段数量,共有多少字段, N F 引用最后一列, NF引用最后一列, NF引用最后一列,(NF-1)引用倒数第2列
- NR :行号,后可跟多个文件,第二个文件行号继续从第一个文件最后行号开始
- FNR :各文件分别计数, 行号,后跟一个文件和NR一样,跟多个文件,第二个文件行号从1开始
- FILENAME :当前文件名
- ARGC:命令行参数的个数
- ARGV :数组,保存的是命令行所给定的各参数,查看参数
示例
[root@localhost ~]# cat awkdemo //示例文件
hello:world
linux:redhat:lalala:hahaha
along:love:youou
[root@localhost ~]# awk -v FS=':' '{print $1,$2}' awkdemo
hello world
linux redhat
along love
[root@localhost ~]# awk -v FS=':' -v OFS='---' '{print $1,$2}' awkdemo
hello---world
linux---redhat
along---love
[root@localhost ~]# awk -v FS=':' -v ORS='---' '{print $1,$2}' awkdemo
hello world---linux redhat---along love---[root@localhost ~]# awk -F: '{print NF}' awkdemo
2
4
3
[root@localhost ~]# awk -F: '{print $(NF-1)}' awkdemo
hello
lalala
love
[root@localhost ~]# awk '{print NR}' awkdemo awkdemo
1
2
3
4
5
6
[root@localhost ~]# awk END'{print NR}' awkdemo awkdemo
6
[root@localhost ~]# awk '{print FNR}' awkdemo awkdemo
1
2
3
1
2
3
[root@localhost ~]# awk '{print FILENAME}' awkdemo
awkdemo
awkdemo
awkdemo
[root@localhost ~]# awk 'BEGIN {print ARGC}' awkdemo awkdemo
3
printf命令
(1)格式化输出
printf` `"FORMAT"``, item1,item2, ...
-
必须指定FORMAT
-
不会自动换行,需要显式给出换行控制符\n
-
FORMAT 中需要分别为后面每个item 指定格式符
(2)格式符:与item 一一对应
-
%c: 显示字符的ASCII码
-
%d, %i: 显示十进制整数
-
%e, %E: 显示科学计数法数值
-
%f :显示为浮点数,小数 %5.1f,带整数、小数点、整数共5位,小数1位,不够用空格补上
-
%g, %G :以科学计数法或浮点形式显示数值
-
%s :显示字符串;例:%5s最少5个字符,不够用空格补上,超过5个还继续显示
-
%u :无符号整数
-
%%: 显示% 自身
(3)修饰符:放在%c[/d/e/f…]之间
- #[.#]:第一个数字控制显示的宽度;第二个# 表示小数点后精度,%5.1f
- -:左对齐(默认右对齐) %-15s
- +:显示数值的正负符号 %+d
[root@localhost ~]# awk -F: '{print $1,$3}' /etc/passwd
root 0
bin 1
daemon 2
// 第一列显示小于20的字符串;第2列显示整数并换行
[root@localhost ~]# awk -F: '{printf "%20s---%u\n",$1,$3}' /etc/passwd
root---0
bin---1
daemon---2
// 使用-进行左对齐;第2列显示浮点数
[root@localhost ~]# awk -F: '{printf "%-20s---%-10.3f\n",$1,$3}' /etc/passwd
root ---0.000
bin ---1.000
daemon ---2.000
adm ---3.000
5.复现awk经典实例
(1).插入几个新字段
在"a b c d"的b后面插入3个字段e f g。
[root@localhost ~]# echo "a b c d" | awk '{$2=$2" e f g";print}'
a b e f g c d
(2).格式化空白
移除每行的前缀、后缀空白,并将各部分左对齐。
[root@localhost ~]# cat shiyan.txt
aaaa bbb ccc
bbb aaa ccc
ddd fff eee gg hh ii j
[root@localhost ~]# awk 'BEGIN{OFS="\t"}{$1=$1;print}' shiyan.txt
aaaa bbb ccc
bbb aaa ccc
ddd fff eee gg hh ii j
(3).筛选IPv4地址
从ip a命令的结果中筛选出除了lo网卡外的所有IPv4地址。
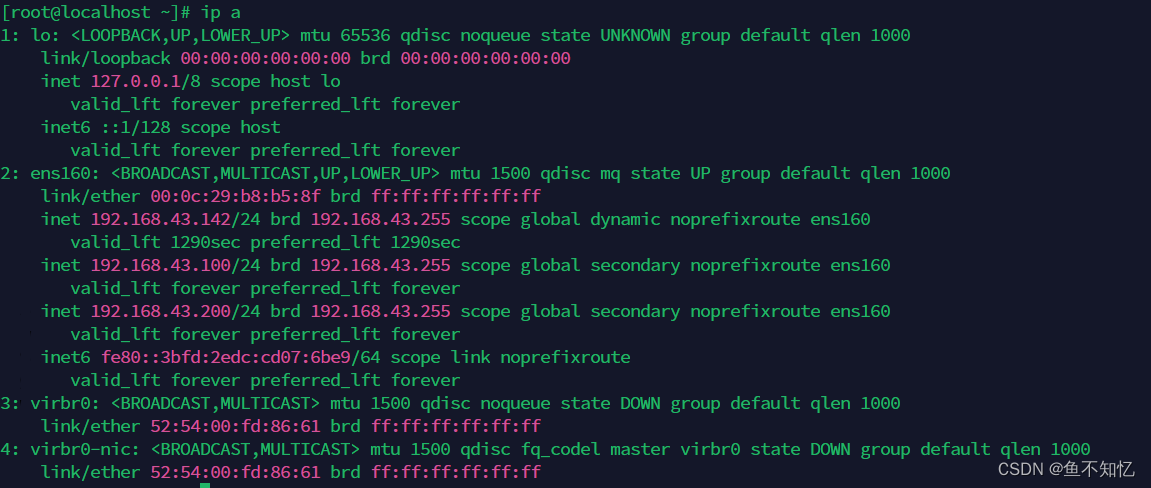

(4).筛选给定时间范围内的日志
下面strptime2()实现的是将10/Nov/2019:23:53:44+08:00格式的字符串转换成epoch值,然后和which_time比较大小即可筛选出精确到秒的日志。
BEGIN{
# 要筛选什么时间的日志,将其时间构建成epoch值
which_time = mktime("2019 11 10 03 42 40")
}
{
# 取出日志中的日期时间字符串部分
match($0,"^.*\\[(.*)\\].*",arr)
# 将日期时间字符串转换为epoch值
tmp_time = strptime2(arr[1])
# 通过比较epoch值来比较时间大小
if(tmp_time > which_time){
print
}
}
# 构建的时间字符串格式为:"10/Nov/2019:23:53:44+08:00"
function strptime2(str ,dt_str,arr,Y,M,D,H,m,S) {
dt_str = gensub("[/:+]"," ","g",str)
# dt_sr = "10 Nov 2019 23 53 44 08 00"
split(dt_str,arr," ")
Y=arr[3]
M=mon_map(arr[2])
D=arr[1]
H=arr[4]
m=arr[5]
S=arr[6]
return mktime(sprintf("%s %s %s %s %s %s",Y,M,D,H,m,S))
}
function mon_map(str ,mons){
mons["Jan"]=1
mons["Feb"]=2
mons["Mar"]=3
mons["Apr"]=4
mons["May"]=5
mons["Jun"]=6
mons["Jul"]=7
mons["Aug"]=8
mons["Sep"]=9
mons["Oct"]=10
mons["Nov"]=11
mons["Dec"]=12
return mons[str]
}