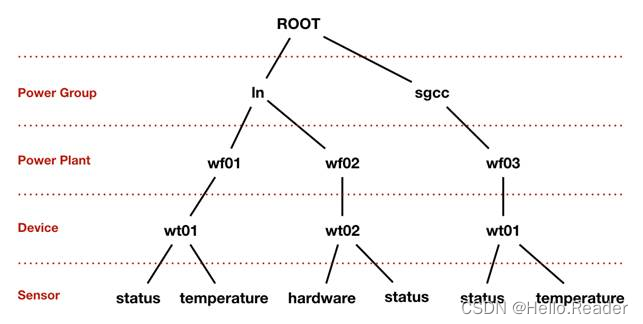
4.1 时间类型
在Flink中定义了3种时间类型:
- 事件时间(Event Time):事件的发生事件,数据本身自带时间字段。
- 处理时间(Processing Time):计算引擎处理时的系统时间。
- 和摄取时间(Ingestion Time):指事件进入流处理系统的时间。
4.2 窗口类型
- 计数窗口(Count Window):滚动/滑动
- 时间窗口(Time Window):滚动/滑动
- 会话窗口(Session Window):当超过一段时间,该窗口没有收到新的数据元素,则视为该窗口结束。
4.3 窗口原理与机制
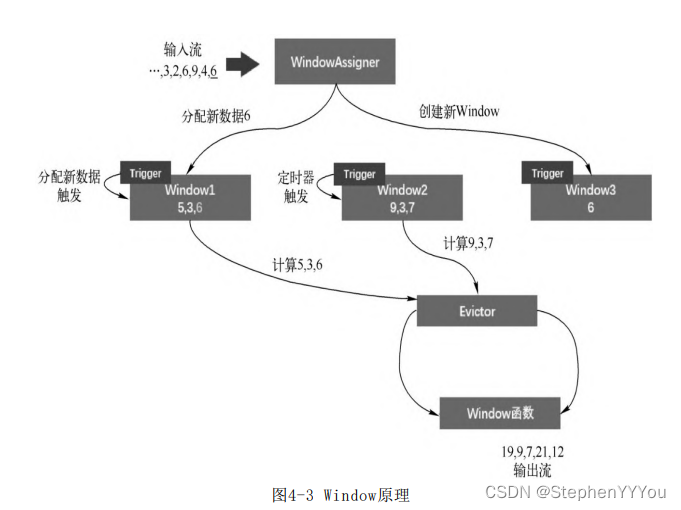

- 数据流进入算子前,被提交给WindowAssigner,决定元素被放到哪个或哪些窗口,同时可能会创建新窗口或者合并旧的窗口。
- 每一个窗口都拥有一个属于自己的触发器Trigger,每当有元素被分配到该窗口,或者之前注册的定时器超时时,Trigger都会被调用。
- Trigger被触发后,窗口中的元素集合就会交给Evictor(如果指定了),遍历窗口中的元素列表,并决定最先进入窗口的多少个元素需要被移除。
- 窗口函数计算结果值,发送给下游。
PS:Flink对一些聚合类的窗口计算(如sum和min)做了优化,因为只需要保存一个中间结果值。每个进入窗口的元素都会执行一次聚合函数并修改中间结果值。
(1)WindowAssigner:决定某个元素被分配到哪个/哪些窗口中去。
(2)WindowTrigger:拥有定时器,决定窗口何时触发/清除。处理时间和计数窗口的实现基于触发器完成。(事件时间窗口触发:watermark ≥ 窗口endTime)
(3)WindowEvictor:窗口数据的过滤器,可在WindowFunction执行前或后,从Window中过滤元素。
1)CountEvictor: 计数过滤器。在Window中保留指定数量的元素,并从窗口头部开始丢弃其余元素。 2)DeltaEvictor: 阈值过滤器。本质上来说就是一个自定义规则,计算窗口中每个数据记录,然后与一个事先定义好的阈值做比较,丢弃超过阈值的数据记录。 3)TimeEvictor: 时间过滤器。保留Window中最近一段时间内的元素,并丢弃其余元素。
(4)Window函数:
1)增量计算函数:数据到达后立即计算,窗口只保存中间结果。效率高,性能好,但不够灵活。
2)全量计算函数:缓存窗口的所有元素,触发后统一计算,效率低,但计算灵活。
4.4 水印
水印(Watermark)用于处理乱序事件。(也就是迟到数据)
4.4.1 watermark生成
- Datastream watermark生成
- Source function中生成
- DataStream API中生成
- AssignerWithPeriodicWatermarks:系统周期性的调用
getCurrentWatermark()来获取当前的Watermark,它返回的Watermark仅在大于上一次返回的Watermark情况下有效- BoundedOutOfOrdernessTimestampExtractor:初始化Watermark = Long.MIN_VALUE,对每条数据,根据extractTimestamp获取最大时间戳currentMaxTimestamp。周期性的调用getCurrentWatermark获取当前最新的Watermark。Watermark=当前收到的数据元素的最大 时间戳-固定延迟
- AscendingTimestampExtractor:默认是顺序数据,Watermark=当前收到的数据元素的时间戳-1。减1的目的是确保有最大时间戳的事件不会被当做迟到数据丢弃(书上说 -1 是为了确保有最大时间戳的事件不会被当做迟到数据丢弃,私认为不对,窗口是左闭右开的,最大时间戳的事件会被分配给下一个窗口,此时上一个窗口触发,不代表会丢弃这条数据,因为是在下一个窗口触发时计算)
- IngestionTimeExtractor:周期性调用getCurrentWatermark() 获取当前机器时间作为当前的Watermark。
- AssignerWithPunctuatedWatermarks:对每一条数据生成一个watermark,它返回的Watermark仅在大于上一次返回的Watermark情况下有效
- AssignerWithPeriodicWatermarks:系统周期性的调用
- Flink SQL:与Datastream类似,主要是在TableSource中完成。
在实际的生产中Punctuated方式在TPS很高的场景下会产生大量的Watermark,会对下游算子造成一定计算压力,适用于实时性要求较高和TPS低的场景。
周期性适用于实时性要求不高,和TPS高的场景。
4.4.2 多流watermark
Apache Flink 内部要保证Watermark保持单调递增。存在多source watermark不一致的问题。
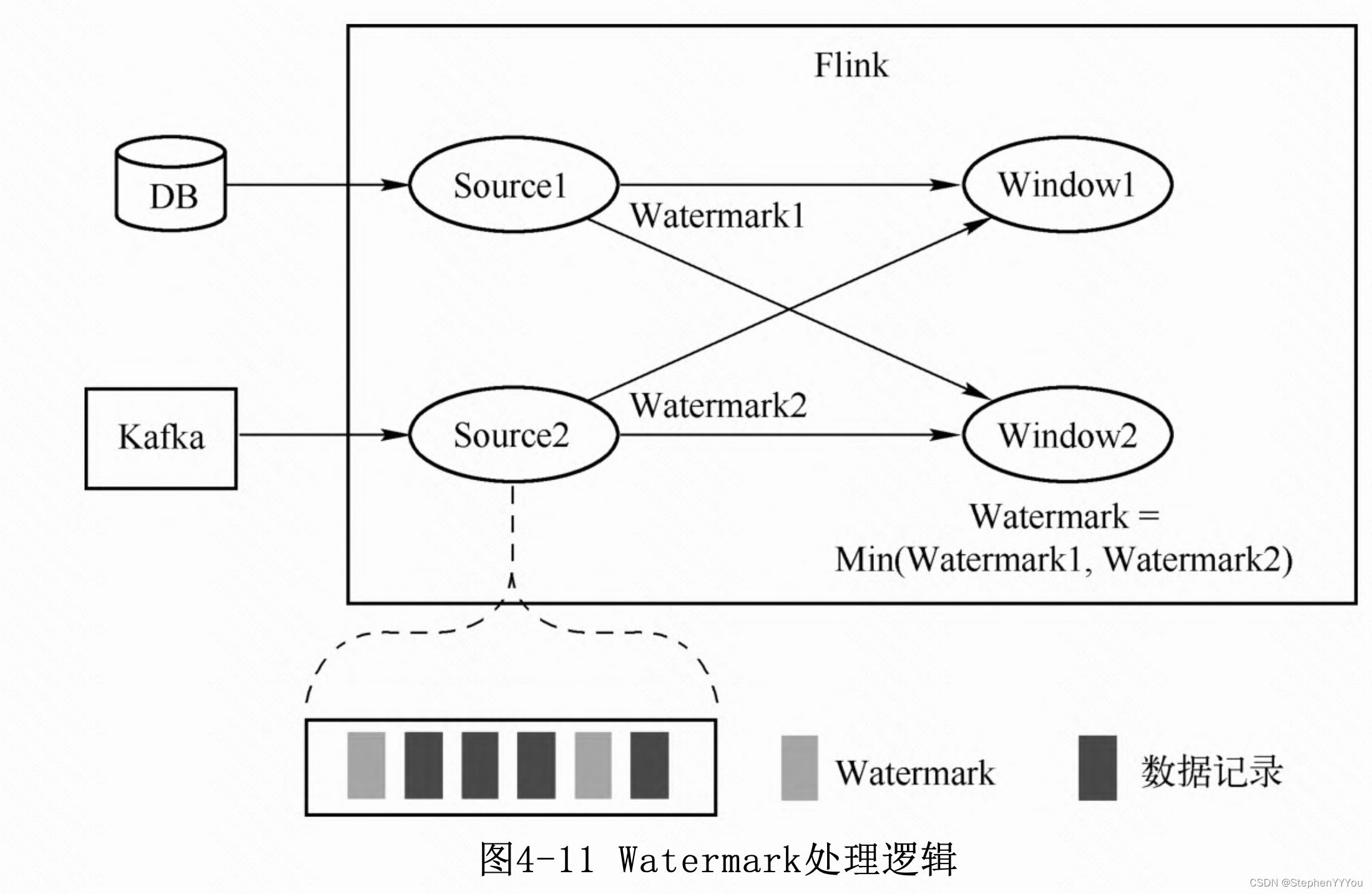
经过keyBy、partition之后,在Flink的底层执行模型上,多流输入会被分解为多个双流输入。下游watermark 取所有上游的最小值。
4.5 时间服务
4.5.1 定时器服务
定时器服务在Flink中叫作TimerService,TimeService是在算子中提供定时器的管理行为, 包含定时器的注册和删除。在算子中使用时间服务来创建定时器(Timer),并且 在Timer触发的时候进行回调,从而进行业务逻辑处理。
4.5.2 定时器
定时器在Flink中叫作Timer。注册Timer然后重写其onTimer()方法,在Watermark超过Timer的时间点之后,触发回调onTimer()。
- 对于事件时间,会根据Watermark,从事件时间的定时器队列中找到比给定时间小的所有定时器,触发该Timer所在的算子,然后由算子去调用UDF中的onTime()方法
- 处理时间是从处理时间 Timer优先级队列中找到Timer。处理时间因为依赖于当前系统,所以其使用的是周期性调度。
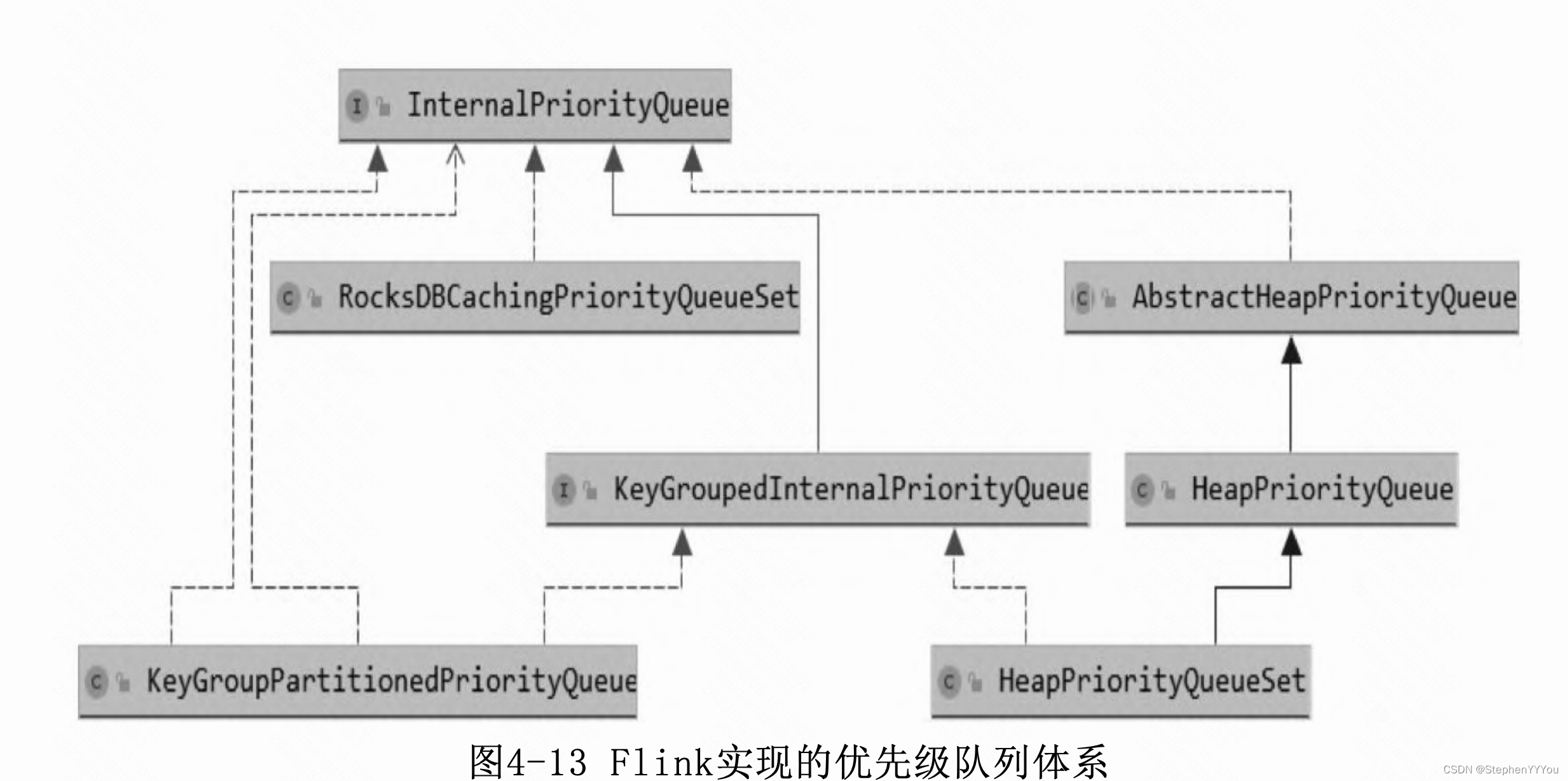
4.5.3 优先队列
Flink自己实现了优先级队列来管理Timer,共有2种实现。


- 基于堆内存的优先级队列HeapPriorityQueueSet:基于Java堆 内存的优先级队列,其实现思路与Java的PriorityQueue类似,使用了二叉树。
- 基于RocksDB的优先级队列:分为Cache+RocksDB量级,Cache 中保存了前N个元素,其余的保存在RocksDB中。写入的时候采用 Write-through策略,即写入Cache的同时要更新RocksDB中的数据,可 能需要访问磁盘。
基于堆内存的优先级队列比基于RocksDB的优先级队列性能好,但 是受限于内存大小,无法容纳太多的数据;基于RocksDB的优先级队列 牺牲了部分性能,可以容纳大量的数据。
4.6 窗口实现
在 Flink 中 有 3 类 窗 口 : CountWindow 、 TimeWindow 、 SessionWindow,其执行时的算子是WindowOperator。

事件窗口用的比较少。在Flink中提供了4种Session Window的默认实现。
- ProcessingTimeSessionWindows:处理时间会话窗口,使用固定会话间隔时长。
- DynamicProcessingTimeSessionWindows : 处理时间会话窗口,使用自定义会话间隔时长。
- EventTimeSessionWindows:事件时间会话窗口,使用固定会话间隔时长。
- DynamicEventTimeSessionWindows:事件时间会话窗口,使用自定义会话间隔时长。
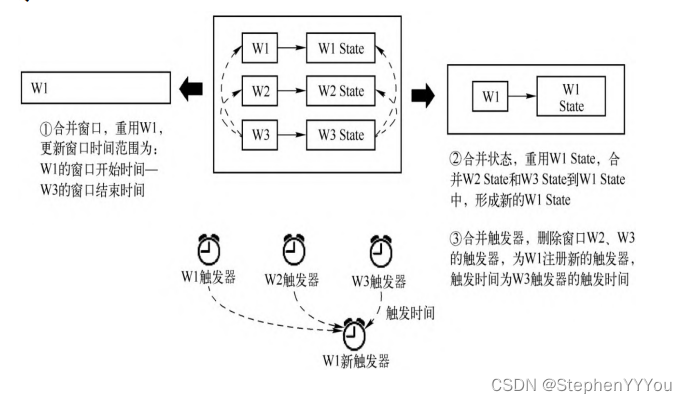
对于会话窗口,因为无法事先确定窗口的长度,也不知道该将数据元素放到哪个窗口,所以对于每一个事件分配一个SessionWindow。然后判断窗口是否需要与已有的窗口进行合并。窗口合并时按照窗口的起始时间进行排序,然后判断窗口之间是否存在时间重叠,重叠的窗口进行合并。