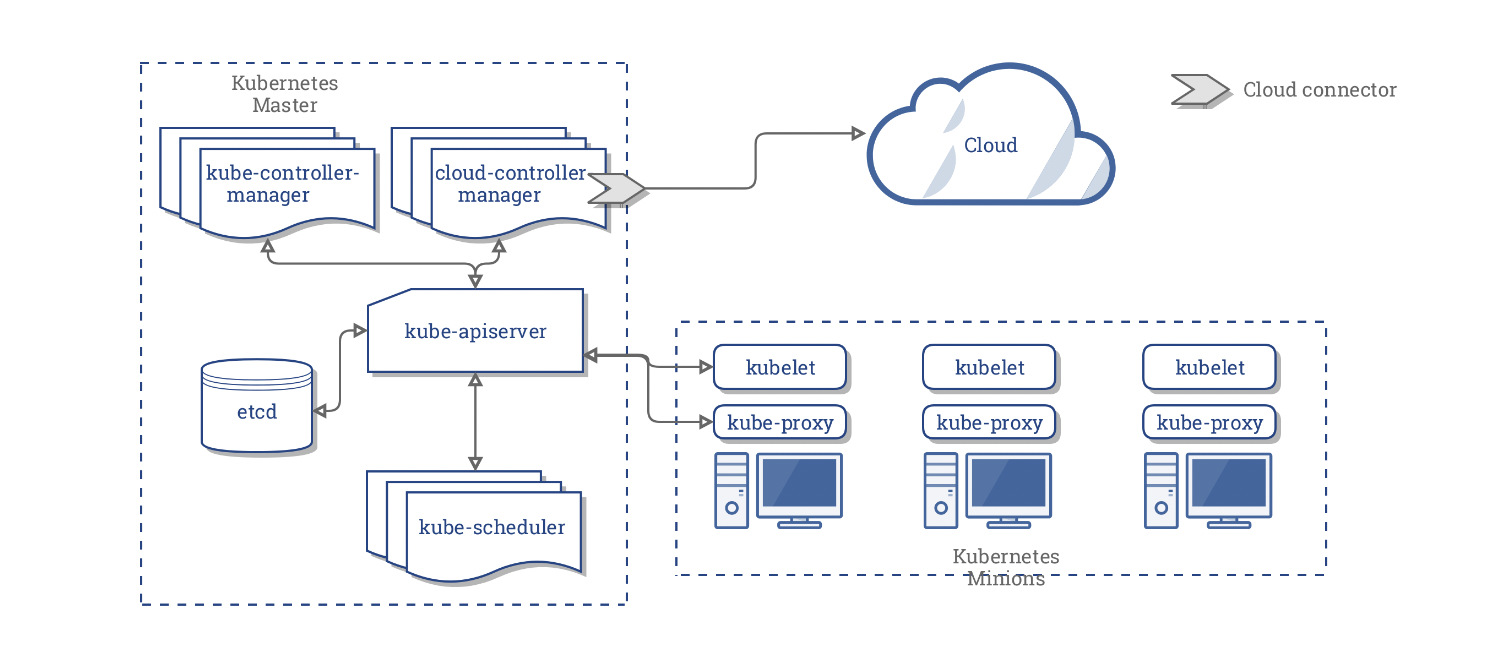
General Image-to-Image Translation with One-Shot Image Guidance
论文:https://arxiv.org/abs/2307.14352
代码:https://github.com/crystalneuro/visual-concept-translator
文章目录
- Abstract
- 1. Introduction
- 2. 相关工作
- 2.1 图像到图像转换
- 2.2. Diffusion-based Image Synthesis
- 3. Methods
- 4. Experiments
- 4.1. Implementation details
- 4.2. 与先前/同时进行的工作的比较
- 4.3. 消融研究
- 5. 结论
Abstract
最近,大规模的文本到图像模型在大量文本-图像对上进行预训练,表现出了出色的图像合成性能。然而,图像可以提供比纯文本更直观的视觉概念。人们可能会问:我们如何将期望的视觉概念集成到现有的图像中,比如我们的肖像?然而,当前的方法在满足这种需求方面还不足够,因为它们缺乏保留内容或有效地转换视觉概念的能力。受到这一问题的启发,我们提出了一种新颖的框架,名为视觉概念转换器(VCT),它具有保留源图像中内容并根据单个参考图像指导转换视觉概念的能力。所提出的VCT包含内容-概念反演(CCI)过程来提取内容和概念,并包含内容-概念融合(CCF)过程来收集提取的信息以获取目标图像。给定只有一个参考图像,所提出的VCT可以在各种图像到图像转换任务中取得出色的结果。我们进行了大量实验证明了所提出方法的优越性和有效性。代码可在https://github.com/CrystalNeuro/visual-concept-translator找到。

1. Introduction
图像到图像转换(I2I)任务旨在学习一个条件生成函数,将图像从源域翻译到目标域,并保留源内容并转移目标概念[35, 47]。通用I2I可以在不需要专门的模型设计或从头开始训练的情况下完成广泛的应用[46]。传统上,生成对抗网络(GAN)或正则化流[12]主要应用于I2I任务[20, 20, 35, 4]。然而,这些方法在缺乏适应性方面存在问题[42]。在一个源-目标数据集上训练的模型不能适应另一个数据集,因此在通用I2I场景中无法工作。
由于大规模模型的应用,基于扩散的图像合成在近年来得到了快速发展[36, 38, 34]。它们的优势在于使用大量的图像-文本对进行模型训练,因此可以通过在潜在空间中根据特定文本提示进行采样来生成多样化的图像。然而,在我们日常生活中,我们接受大量包含丰富视觉概念的视觉信号。
这些视觉概念很难用纯文本来描述,就像谚语“一图胜千言”一样。此外,由参考图像指导的I2I在游戏制作、艺术创作和虚拟现实等方面具有广泛应用。因此,在图像引导的I2I研究在计算机视觉领域具有巨大潜力。
有几种方法尝试从图像中提取具有所需概念的视觉信息。具体来说,[10]提出了一种名为文本反演(TI)的技术,它固定模型并学习一个文本嵌入来表示视觉概念。在TI的基础上,提出了DreamBooth [37]和Imagic [21]来减轻由模型微调引起的过拟合问题。上述方法是在少样本设置下,但有时很难收集几个包含相同概念的相关图像。为了解决这个问题,[8]提出使用正负文本嵌入来适应一次性样本设置。然而,这些方法不能直接用于I2I任务,因为它们不能保留源图像中的内容。
为了保留源图像中的内容,最近提出的DDIM反演[7, 41]发现了扩散反向过程中的确定性噪声。然后,一些研究[31, 13]进一步将DDIM反演应用于文本引导的图像编辑。
然而,这些方法是文本条件的,因此它们无法理解参考图像中的视觉概念。另一方面,一些工作[50, 42]尝试通过图像条件将源域和目标域连接起来,但它们的模型是特定于任务的,因此不能用于通用I2I。
在本文中,为了完成由参考图像指导的通用I2I任务,我们提出了一种名为视觉概念转换器(VCT)的新框架,该框架具有保留源图像中内容并转换视觉概念的能力。所提出的VCT通过内容-概念反演(CCI)和内容-概念融合(CCF)两个过程来解决图像引导的I2I问题。
CCI过程通过枢轴转向反演和多概念反演从源图像和参考图像中提取内容和概念,CCF过程通过双流去噪架构收集提取的信息以获取目标图像。在只有一个参考图像的情况下,所提出的VCT可以完成各种各样的通用图像到图像转换任务,并取得优秀的结果。我们进行了大量实验,包括通用I2I和风格迁移的大规模任务,用于模型评估。
总的来说,我们的贡献如下:
(1)我们提出了一种名为视觉概念转换器(VCT)的新框架。在只有一个参考图像的情况下,VCT可以完成通用I2I任务,并具有保留源图像中内容并转换视觉概念的能力。
(2)我们提出了内容-概念反演(CCI),通过枢轴转向反演和多概念反演来提取内容和概念。我们还提出了内容-概念融合(CCF)过程,通过双流去噪架构收集提取的信息。
(3)我们进行了大量实验,包括通用I2I和风格迁移的大规模任务,用于模型评估。生成的结果显示了所提出方法的高优越性和有效性。
2. 相关工作
2.1 图像到图像转换
图像到图像转换旨在将图像从源域转换到目标域。当前的图像到图像转换方法大多基于生成对抗网络(GAN)[1, 30, 9, 54, 55, 51, 56]。然而,这些方法存在适应性不足的问题[42]。在一个源-目标数据集上训练的模型不能适应另一个数据集。此外,这些方法通常需要大尺寸的训练图像。
Lin等人提出的TuiGAN [28]可以仅通过一对图像实现转换,但他们的方法需要为每个输入对重新训练整个网络,非常耗时。
图像风格迁移是I2I中的一种特定类型,它尝试将图像风格从源转换到目标。Gatys等人的开创性工作[11]表明,通过深度神经网络可以通过分离内容和风格来生成艺术图像。然后,为了实现实时风格迁移,Johnson等人[19]训练了一个前馈网络来处理Gatys等人提到的优化问题。许多工作[48, 43, 44, 25, 18, 24]被归类为每种风格对应一个模型,训练的模型只能适应一种特定的风格。为了增加模型的灵活性,许多研究[16, 32, 17, 5, 29, 40, 49]实现了任意风格迁移,只需要对任何输入风格图像进行单个前向传递即可。然而,这些方法在处理细粒度信息方面不具备通用的图像到图像转换任务(如人脸交换)的能力,因此无法推广到一般的I2I任务。
2.2. Diffusion-based Image Synthesis
最近,基于纯文本的大规模扩散模型在高分辨率图像合成方面表现出良好的性能,例如Stable Diffusion [36]、Imagen [38]和DALL-E 2 [34]。这些方法使用大型文本-图像模型[6, 33]来实现文本引导的合成。然而,用于生成目标图像的文本有时是不可用的,因此许多研究[10, 37, 21]使用反演技术来学习文本嵌入,以指导预训练的大规模扩散模型。为了实现从源域到目标域的图像转换,DDIM反演[7, 41]在反向过程的逆方向上找到了带有文本条件的确定性噪声向量,但该方法仅通过文本进行引导。我们提出的方法试图解决上述缺点,并通过从图像中融合丰富的视觉概念来完成通用的图像到图像转换任务。
3. Methods
略
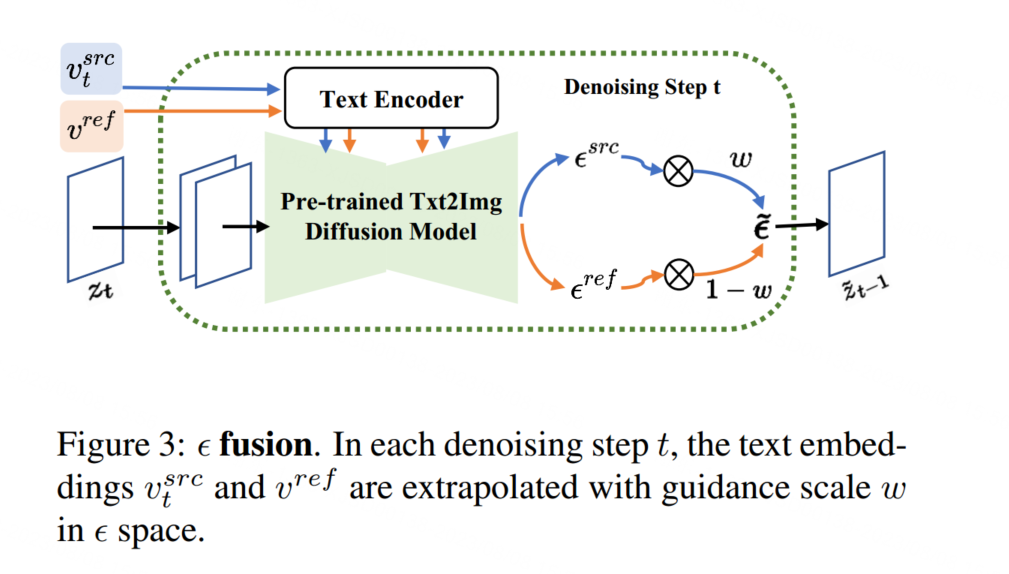
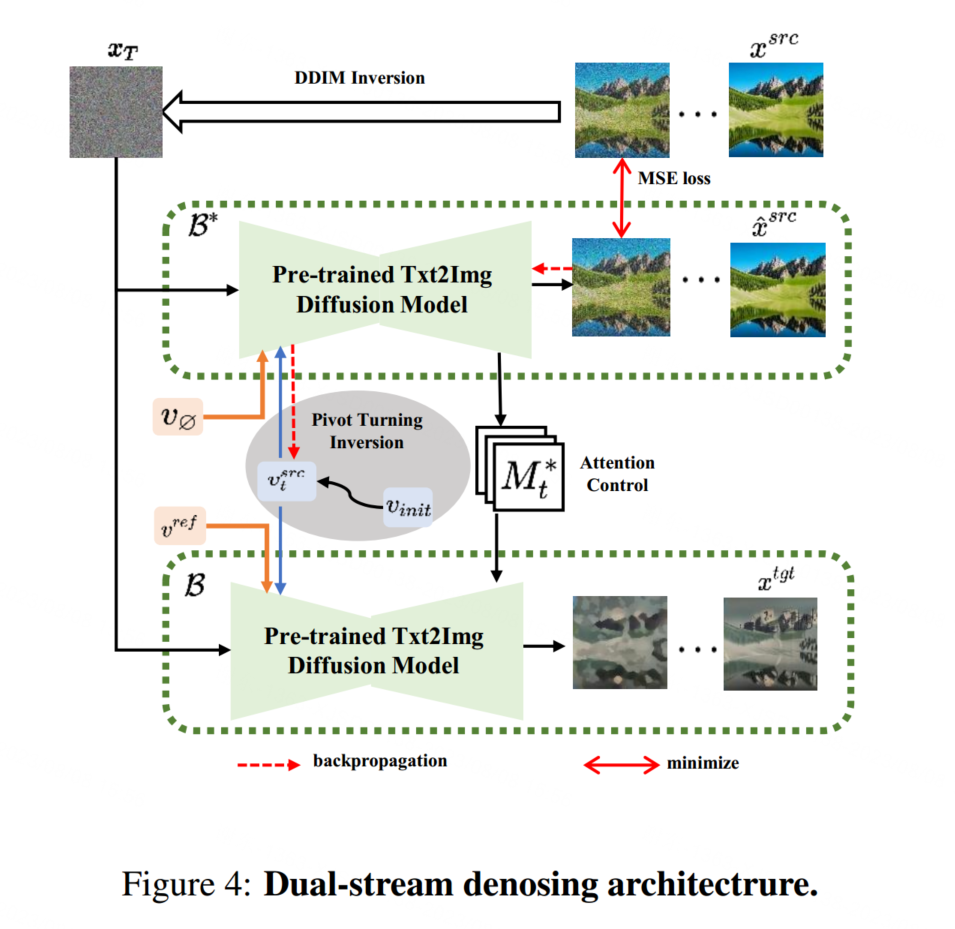
4. Experiments
4.1. Implementation details
将所有组件组合在一起,我们的完整算法在我们的补充材料中呈现。核心训练过程包括两部分:使用x src进行关键调整反演和使用x ref进行多概念反演,这两部分可以独立实现。更多详细信息请参考我们的补充材料。
我们的实验是在单个A100 GPU上进行的。我们使用Adam[23]优化器进行训练。我们从包含50亿张图像的大规模LAION 5B数据集[39]中收集了评估图像。
4.2. 与先前/同时进行的工作的比较
一般I2I任务。在这里,我们评估了提出的框架在一般I2I任务中的性能,包括leopard→dog,face swap和mountain→snow mountain,如图5所示。我们将提出的方法与TuiGAN [28],PhotoWCT [27],stable diffusion (SD) [36],textual inversion (TI) [10]和prompt-to-prompt (Ptp) [13]进行了比较。
对于没有学习嵌入输入的文本到图像模型,包括SD和Ptp,我们使用BLIP图像字幕模型[26]来提取文本描述作为扩散模型的输入。
从图5可以看出,基于GAN的翻译方法TuiGAN和PhotoWCT无法仅通过一个图像输入很好地转换概念,并且生成质量较差。例如,从图5的第3-4列中可以看出,基于GAN的方法在leopard→dog和face swap任务中只能转换部分纹理特征,并且在mountain→snow mountain任务中图像质量较差。因此,基于GAN的方法无法在一次性设置中实现令人满意的结果。对于基于扩散的方法SD和TI,参考图像的概念可以很好地保留,但内容图像中的信息无法提取。如图5的第7列所示,Ptp可以很好地保留内容,但无法融合参考图像中的概念。通过解决上述方法的所有缺点,提出的VCT可以生成具有学习的概念和保留内容的最佳结果。
此外,为了评估提出的VCT的强大概念转换能力,我们固定内容图像并更换不同的参考图像,如图6所示。不同参考图像的生成结果显示出令人满意的内容保留和概念转换能力。
更多结果可以在补充材料中找到。
如图7所示,我们进一步与其他一次性对比方法进行比较:Paint-by-example[50]和ControlNet[53]。这些方法使用额外的条件来控制生成的图像,而我们的方法获得了更好的性能。
图像风格迁移。除了一般的I2I,提出的方法在图像风格迁移任务中也取得了出色的结果。我们将我们的方法与不同艺术风格的最新SOTA进行了比较。如图13所示,我们完全比较了三个基于GAN的方法,包括TuiGAN [28],PhotoWCT [27]和ArtFlow [3],以及三个基于扩散的方法,包括SD [36],TI [10]和Ptp [13]。按照一般I2I的设置,我们使用BLIP图像字幕模型为文本到图像模型SD和Ptp提取文本描述。
从图13的结果可以看出,基于GAN的方法存在较大的缺陷,特别是TuiGAN和ArtFlow的结果,如图13的第3和第5列所示。基于扩散的方法SD和TI也存在与一般I2I相同的问题,即内容无法保留。对于Ptp,虽然内容得到保留,但参考图像中的概念无法被很好地转换。提出的方法也可以生成最令人满意的图像,如图13的第9列所示。



我们还通过固定参考图像并更改内容图像,以及反之亦然,评估了模型性能。结果如图9所示。优秀的翻译结果证明了所提出方法的泛化能力。
定量比较。由于风格转移任务缺乏真实标签,且两个域之间存在差异,定量评估仍然是一个挑战。回想一下,我们的目标是从源图像和参考图像创建一张新的图像。因此,我们使用以下三个指标来评估生成的图像。1)盲参考图像空间质量评估器(BRISQUE),这是一种无参考图像质量评分方法。2)学习的感知图像块相似性(LPIPS),用于评估源图像与目标图像之间的距离,以验证不同模型的内容保留性能。3)人类偏好得分(Pre.),我们邀请参与者通过用户研究对不同方法生成的结果进行投票。我们的模型在总体评估指标上表现优异。更多的实验设置可以在补充材料中找到。
4.3. 消融研究
最后,我们对方法的每个组成部分进行了消融研究,并展示了其有效性,包括多概念反演(MCI),关键调整反演(PTI)和注意力控制(AC)。
在图10中展示了可视化消融研究。 (a) 通过去除MCI,在我们的流程中使用单词’dog’来生成参考嵌入v ref ,生成的结果不是参考图像中特定的狗。 (b) 在没有使用PTI的情况下,由于DDIM采样轨迹不一致,内容匹配分支无法重构内容图像。 © 通过去除AC,结果无法保留内容图像的结构。
总的来说,通过使用我们所有提出的组件,我们可以获得最佳的生成输出,它更好地保留了内容图像的结构和语义布局,并与参考图像保持一致。更多的消融研究可以在补充材料中找到。




5. 结论
本工作受到日常生活中视觉概念的重要性的启发,通过提出名为VCT的新颖框架,完成了图像引导下的通用I2I任务。
它能够保留源图像中的内容,并通过单个参考图像来翻译视觉概念。我们在各种通用的图像到图像转换任务上评估了提出的模型,并取得了出色的结果。







![[保研/考研机试] 猫狗收容所 C++实现](https://img-blog.csdnimg.cn/59f202297ce2471a8ed815d7b0564cdb.png)