文章目录
- 机器学习基础
- 机器学习的关键术语
- k-近邻算法(KNN)
- 准备:使用python导入数据
- 实施kNN分类算法
- 示例:使用kNN改进约会网站的配对效果
- 准备数据:从文本文件中解析数据
- 分析数据
- 准备数据:归一化数值
- 测试算法:作为完整程序验证分类器
- 手写识别系统
机器学习基础
机器学习的关键术语
1、属性:将一种事务分类的特征值称为属性,例如我们在做鸟类分类时,我们可以将体重、翼展、脚蹼、后背颜色作为特征,特征通常时训练样本的列,它们是独立测量得到的结果,多个特征联系在一起共同组成一个训练样本
2、目标变量:就是我们要分类的那个结果
3、训练集和测试集:训练集作为算法的输入,用于训练模型,测试集用于检验训练的效果
k-近邻算法(KNN)
主要思想:我们先将已知标签的数据以及对应的标签输入,当输入未知标签的数据时,我们希望根据输入的特征值来判断该数据的特征值,我们先计算该数据与我们已知标签的数据的距离,并将距离排序,取前k个数据,根据前k个数据中出现次数最多的数据的标签作为新数据标签的分类
kNN算法主要是用于分类的一种算法

准备:使用python导入数据
from numpy import *
# kNN排序时将使用这个模块提供好的函数
import operator
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
实施kNN分类算法

def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1) - dataSet)
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(),
key = operator.itemgetter(1), reverse= True)
return sortedClassCount[0][0]
这里先说一下shape函数,只做简单说明,shape函数用于确定array的维度比如
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
print(group.shape)
这里输出的结果是(4,2)
也就是说返回的是矩阵或者数组每一维的长度,返回的结果是一个元组(tuple),元组和例表的区别不能忘记,元组不可修改,列表可以修改
tile()函数,tile是numpy模块中的一个函数,用于矩阵的复制,tile(A, reps), A表示我们要操作的矩阵,reps是我们复制的参数,可以是一个数也可以是一个矩阵(4, 2),tile(A, (4, 2))表示将A矩阵的列复制4次,行复制两次
argsort()方法,对数组进行排序,这里返回的是排序后的下标这和C++中的sort()方法不同
argsort()实现倒序排序
group = array([2, 3, 5, 4])
x = argsort(-group)
print(x)
字典中的get()方法
python中对于非数值型数据进行排序,例如字典
sorted(iterable, cmp=None, key=None, reverse=False)
iterable是一个迭代器,
cmp是比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse – 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
sortedClassCount = sorted(classCount.iteritems(),
key = operator.itemgetter(1), reverse= True)
python中的items()返回的是一个列表,iteritems()返回一个迭代器, itemgetter()方法可用于指定关键字排序,operator.itemgetter(1)是按字典中的值进行排序,reverse= True按降序排序,python3已经不支持iteritems(),这里用items()即可。
字典中的get()方法
dict_name.get(key, default = None)
key是我们要查找字典中的key,如果存在则返回对应的值,如果不存在就返回第二个我们设置的参数,当我们没设置时,默认返回None
示例:使用kNN改进约会网站的配对效果

准备数据:从文本文件中解析数据
from numpy import *
def file2matrix(filename):
fr = open(filename)
arrarOLines = fr.readlines()
numberOfLines = len(arrarOLines)
returnMat = zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrarOLines:
line = line.strip()
listFromLine = line.split('\t')
# 将数据的前三行直接存入特征矩阵
returnMat[index,:] = listFromLine[0:3]
# 将字符串映射成数字
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector
分析数据
from numpy import *
# kNN排序时将使用这个模块提供好的函数
import operator
import matplotlib
import matplotlib.pyplot as plt
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(),
key = operator.itemgetter(1), reverse= True)
return sortedClassCount[0][0]
# [group, labels] = createDataSet()
# m = classify0([0, 0], group, labels, 2)
# print(m)
def file2matrix(filename):
fr = open(filename)
arrarOLines = fr.readlines()
numberOfLines = len(arrarOLines)
returnMat = zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrarOLines:
line = line.strip()
listFromLine = line.split('\t')
# 将数据的前三行直接存入特征矩阵
returnMat[index,:] = listFromLine[0:3]
# 将字符串映射成数字
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector
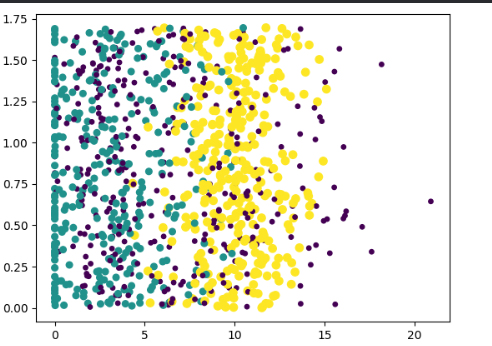
datingDataMat, datingLabels = file2matrix('C:/Users/cxy/OneDrive/桌面/datingTestSet.txt')
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2], 15.0*array(datingLabels), 15.0*array(datingLabels))
plt.show()
结果截图:
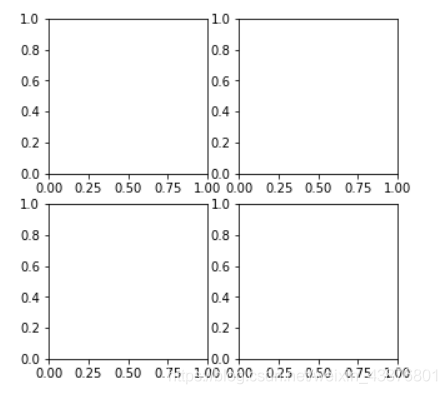
add_subplot(x)中参数的含义:
这里前两个表示几*几的网格,最后一个表示第几子图
可能说的有点绕口,下面上程序作图一看说明就明白
import matplotlib.pyplot as plt
fig = plt.figure(figsize = (5,5))
ax = fig.add_subplot(221)
ax = fig.add_subplot(222)
ax = fig.add_subplot(223)
ax = fig.add_subplot(224)
scatter()方法
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, *, edgecolors=None, plotnonfinite=False, data=None, **kwargs)
x,y:长度相同的数组,也就是我们即将绘制散点图的数据点,输入数据。
s:点的大小,默认 20,也可以是个数组,数组每个参数为对应点的大小。
c:点的颜色,默认蓝色 ‘b’,也可以是个 RGB 或 RGBA 二维行数组。
marker:点的样式,默认小圆圈 ‘o’。
cmap:Colormap,默认 None,标量或者是一个 colormap 的名字,只有 c 是一个浮点数数组的时才使用。如果没有申明就是 image.cmap。
norm:Normalize,默认 None,数据亮度在 0-1 之间,只有 c 是一个浮点数的数组的时才使用。
vmin,vmax::亮度设置,在 norm 参数存在时会忽略。
alpha::透明度设置,0-1 之间,默认 None,即不透明。
linewidths::标记点的长度。
edgecolors::颜色或颜色序列,默认为 ‘face’,可选值有 ‘face’, ‘none’, None。
plotnonfinite::布尔值,设置是否使用非限定的 c ( inf, -inf 或 nan) 绘制点。
**kwargs::其他参数。
我们主要用到的是前四个参数,第一个参数是我们要画散点图的横坐标,第二个是纵坐标,第三个散点图中点的颜色,第四个散点图中点的大小
准备数据:归一化数值
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m, 1))
normDataSet = normDataSet / tile(ranges, (m, 1))
return normDataSet, ranges, minVals
normMat, ranges, minVals = autoNorm(datingDataMat)
print(normMat)
min()、max()方法
minVals = dataSet.min(0) 返回dataSet中每一列中的最小值数组
minVals = dataSet.min(1) 返回dataSet中每一行中的最小值数组
测试算法:作为完整程序验证分类器
def datingClassTest():
hoRatio = 0.10
datingDataMat, datingLabels = file2matrix('C:/Users/cxy/OneDrive/桌面/datingTestSet.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
print(f"the classifier came back with: {classifierResult}, the real answer is : {datingLabels[i]}")
if classifierResult != datingLabels[i]:
errorCount += 1.0
print(f"the total error rate is : {errorCount / float(numTestVecs)}")
datingClassTest();
手写识别系统
from numpy import *
# kNN排序时将使用这个模块提供好的函数
import operator
import matplotlib
import matplotlib.pyplot as plt
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(),
key = operator.itemgetter(1), reverse= True)
return sortedClassCount[0][0]
# [group, labels] = createDataSet()
# m = classify0([0, 0], group, labels, 2)
# print(m)
def file2matrix(filename):
fr = open(filename)
arrarOLines = fr.readlines()
numberOfLines = len(arrarOLines)
returnMat = zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrarOLines:
line = line.strip()
listFromLine = line.split('\t')
# 将数据的前三行直接存入特征矩阵
returnMat[index,:] = listFromLine[0:3]
# 将字符串映射成数字
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector
# datingDataMat, datingLabels = file2matrix('C:/Users/cxy/OneDrive/桌面/datingTestSet.txt')
# print(datingDataMat)
# fig = plt.figure()
# ax = fig.add_subplot(111)
# ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2], 15.0*array(datingLabels), 15.0*array(datingLabels))
# plt.show()
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m, 1))
normDataSet = normDataSet / tile(ranges, (m, 1))
return normDataSet, ranges, minVals
# normMat, ranges, minVals = autoNorm(datingDataMat)
# print(normMat)
# def datingClassTest():
# hoRatio = 0.10
# datingDataMat, datingLabels = file2matrix('C:/Users/cxy/OneDrive/桌面/datingTestSet.txt')
# normMat, ranges, minVals = autoNorm(datingDataMat)
# m = normMat.shape[0]
# numTestVecs = int(m*hoRatio)
# errorCount = 0.0
# for i in range(numTestVecs):
# classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
# print(f"the classifier came back with: {classifierResult}, the real answer is : {datingLabels[i]}")
# if classifierResult != datingLabels[i]:
# errorCount += 1.0
# print(f"the total error rate is : {errorCount / float(numTestVecs)}")
#
# datingClassTest();
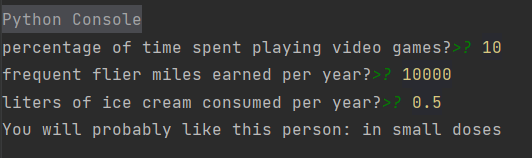
def classifyPerson():
resultList = ['not at all', 'in small doses', 'in large doses']
percentTats = float(input("percentage of time spent playing video games?"))
ffMiles = float(input("frequent flier miles earned per year?"))
iceCream = float(input("liters of ice cream consumed per year?"))
datingDataMat, datingLabels = file2matrix('C:/Users/cxy/OneDrive/桌面/datingTestSet.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([ffMiles, percentTats, iceCream])
classifierResult = classify0((inArr - minVals) / ranges, normMat, datingLabels, 3)
print(f"You will probably like this person: {resultList[classifierResult - 1]}")
classifyPerson()


![[保研/考研机试] 约瑟夫问题No.2 C++实现](https://img-blog.csdnimg.cn/a6f6e7f24e9244a9993053e684b781f4.png)