系统性能调优
分为四个层次
- 基础设施
- 网络
- 编解码
- 分布式系统性能整体提升
一:基础设施优化
从提升单机进程的性能入手,包括高效的使用主机的CPU、内存、磁盘等硬件,通过提高并发编程提升吞吐量,根据业务特性选择合适的算法
01 CPU缓存:怎样写代码能够让CPU更快?
1.1 CPU的多级缓存
离CPU核心越近的缓存,读写速度越快。成本原因,CPU三级缓存相对较小。一级二级缓存比三级缓存大,是因为每个核心有自己的一、二级缓存,三级是一颗CPU共享。
执行代码,回先将内存中的数据载入到三级缓存中,再进入每个核心的二级缓存,最后进入一级缓存,之后才能被CPU使用。
如果CPU所要操作的数据在缓存中,则直接读取-缓存命中。命中会带来很大的性能提升,因为,我们代码优化的目标是提升CPU缓存命中率诺依曼计算机体系结构
中,代码指令与数据是放在一起的,但执行时却是分开进入指令缓存与数据缓存的
1.1.1 提升数据缓存的命中率
缓存一次载入的数据大小:一般是64字节,载入数据,不够64个字节的时候,会向后读取,补足后续元素。所以元素是4个字节整数的时候,比8个字节的浮点型快,因为缓存一次载入的元素会更多。
因此,遇见这边遍历数组的时候,按照内存布局顺序访问将带来很大的性能提升。
下例中:不是顺序访问内存的话,需要加载多次cache line
if (!slowMode) {
for(int i = 0; i < TESTN; i++) {
for(int j = 0; j < TESTN; j++) {
//arr[i][j]是连续访问的
arr[i][j] = 0;
}
}
} else {
for(int i = 0; i < TESTN; i++) {
for(int j = 0; j < TESTN; j++) {
//arr[j][i]是不连续访问的 ,跳跃访问
arr[j][i] = 0;
}
}
}
CPU Cache Line
在Nginx中,哈希表存放域名、HTTP头等数据,哈希表里面桶的大小就是 CPU Cache Line **,哈希表的桶按照此大小排序,尽量减少内存访问次数。(避免不规则的设置,导致cache line 多次读取,分割开)
1.1.2 提升指令缓存的命中率
CPU含有分支预测器
- 如果猜错了,处理器要flush掉pipelines, 回滚到之前的分支,然后重新热启动,选择另一条路径。
- 如果猜对了,处理器不需要暂停,继续往下执行
分析历史运行记录
当代码出现if、switch等语句的时候,意味着至少跳转到两段代码执行。如果分支预测器可以预测执行那段代码,提前将指令放到缓存中,CPU执行更快。当数组中的元素完全随机,预测器就无法有效工作。有序的话,预测,命中率非常搞。
先排序的遍历时间只有后排序的三分之一
1.1.3 提升多核CPU的缓存命中率
操作系统提供了将进程或者线程绑定到某一颗CPU上的能力。(多个核心,线程来回换,造成缓存命中的问题)
02 | 内存池:如何提升内存分配的效率?
隐藏的内存池
当代码申请内存时,首先会到达应用层内存池,如果应用层内存池有足够的可用内存,就会
直接返回给业务代码,否则,它会向更底层的 C 库内存池申请内存 。
除了 JVM 负责管理的堆内存外,Java 还拥有一些堆外内存,由于它不使用JVM 的垃圾回收机制,所以更稳定、持久,处理 IO 的速度也更快。这些堆外内存就会由C 库内存池负责分配,这是 Java 受到 C 库内存池影响的原因
Linux 系统的默认 C 库内存池 Ptmalloc2
每个子线程预分配的内存是 64MB ,子线程内存池最多只能到 8 倍的 CPU 核数
每个线程都有自己的栈,分配内存时不需要加锁保护,而且栈上对象的尺寸在编译阶段就已经写入可执行文件了,执行效率更高
总结:
当我们分配内存时,如果在满足功能的情况下,可以在栈中分配的话,就选择栈
03 | 索引:如何用哈希表管理亿级对象?
在面对海量用户的分布式服务中,使用更多的空间建立索引,换取更短的查询时间,使我们管理大数据常用的手段。
为什么选择哈希表
时间复杂度是O(1)。
首先:哈希表是基于数组实现数组可以根据下标随机访问任意元素。数组的内存是连续的,数组元素的大小相等。知道下标后,乘以元素大小,加上首地址,就是目标访问地址,可以直接获取到数据。
其次:哈希函数可以将查询关键字转换为数组下标,在通过数组下标的随机访问特性获取数据。
位图,它的时间复杂度也是O(1)。本质上,它是哈希表的变种,限制每个哈希桶只有1个比特位(0表示存在,1表示不存在),虽然它的空间消耗更少,但仅用于辅助数据的主索引,快速判断对象是否存在。
哈希表是基于数组的数据结构,其主要目的是通过散列函数将键映射到数组的索引位置,以实现高效的查找。然而,范围查询涉及连续的键值范围,这在哈希表中不容易直接支持,因为哈希函数通常是将键映射到离散的索引位置,而不是连续的范围。范围查询可能需要遍历大量的索引,不如使用其他数据结构(如平衡树、B+ 树)来处理这种情况更有效。
内存结构与序列化方案
动态(元素是变化的)哈希表,我们无法避免哈希冲突。如何解决哈希冲突:
- 链接法:落在同一个位置上,通过链表串在一起。查找的时候,再遍历链表比较。
- 开放寻址法: 插入时若发现对应的位置已经占用,或者查询时发现该位置上的数据与查询关键字不同,开放寻址法会按既定规则变换哈希函数(例如哈希函数设为 H(key,i),顺序地把参数 i 加 1),计算出下一个数组下标,继续在哈希表中探查正确的位置
为了传输,首先必须把哈希表序列化。
- 链表法简单,序列化代价大,因为使用了指针,内存不是连续的。
- 开放寻址法,所有的对象都在数组中。可以把数组用这段连续的内存原地映射到文件中(mmap),再通过备份文件备份哈希表。
当数据有上百字节,不能放进哈希桶,因为哈希桶有很多空桶,如果每个空桶占用上百字节,亿级规模会浪费大量内存。
降低哈希表的冲突概率
- 调优哈希函数
- 扩容
好的哈希函数,首先它的计算量不大,其次应尽量降低冲突概率。BKDR是一个优秀的哈希算法,记住-基数必须是素数
装载因子越接近1,冲突概率就越大。我们不能改变元素的数量,只能通过扩容来提升哈希桶的数量,减少冲突。
04 | 零拷贝:如何高效地传输文件?
磁盘是主机中最慢的硬件之一,常常是性能瓶颈,所以优化它能获得立竿见影的效果 。
你会如何实现文件传输?
普通:
磁盘文件->PageCache(内核态)->用户缓冲(用户态)->Socket(内核态)-》网卡
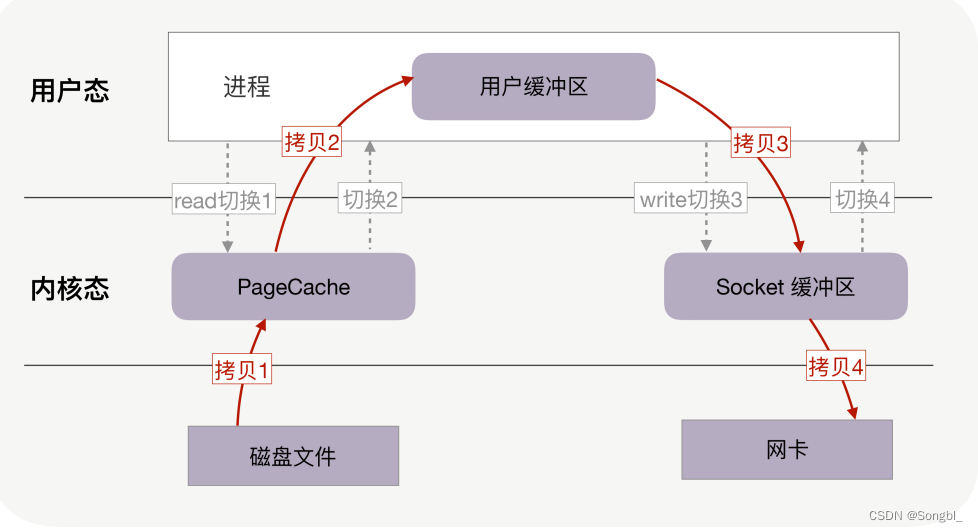
- read 系统调用读磁盘上的文件时:用户态切换到内核态;
- read 系统调用完毕:内核态切换回用户态;
- write 系统调用写到socket时:用户态切换到内核态;
- write 系统调用完毕:内核态切换回用户态。
经过4次用户态和内核态的转换,且发生了4次拷贝的过程。
零拷贝如何提升文件传输性能?
零拷贝技术基于PageCache。
只要我们的代码执行 read 或者 write 这样的系统调用,一定会发生 2 次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行
解决方案:
把read、write两次系统调用合并成一次,在内核中完成磁盘与网卡的数据交换。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zZx0fi7r-1691487347090)(C:\Users\Administrator\Desktop\interviews\系统性能调优.assets\image-20230808101948761.png)]](https://img-blog.csdnimg.cn/8e8bb788831642c798ecf3395262fffb.png)
只在内核态处理。
如果网卡支持SG-DMA技术,还可以去除掉Socket缓冲区的拷贝,这样一共2次内存拷贝。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v5e6zIyr-1691487347090)(C:\Users\Administrator\Desktop\interviews\系统性能调优.assets\image-20230808102123595.png)]](https://img-blog.csdnimg.cn/6433faac48c54e6194d1195f068a12f8.png)
性能至少提升一倍以上!
PageCache,磁盘高速缓存
- 磁盘比内存的速度慢的多,想办法把读写磁盘变成读写内存,把磁盘中的数据复制到内存,就可以用内存代替磁盘。(通常刚访问的数据短时间再访问概率高-时间局部性原理,PageCache缓存最近访问的数据,空间不足,LRU淘汰)。读磁盘时优先到 PageCache 中找一找,如果数据存在
便直接返回,这便大大提升了读磁盘的性能 - PageCache 使用了预读功能(磁盘寻址很慢);比如read 0到32k的字节,内核会把随后32-64k的数据读到PageCache中。
以上的内容看出,**90%**以上的场景PageCache可以提升磁盘性能,但是某些情况,会降低性能。
大文件不能用PageCache(文件太大,很快占满,热点小文件无法使用了,而且大文件下次利用的概率也不大),进而也不应该使用零拷贝技术处理。
异步 IO + 直接 IO
大文件的处理,就使用直接IO(绕过 PageCache 的 IO 是个新物种,我们把它称为直接 IO。对于磁盘,异步 IO 只支持直接 IO )
总结:
这里面的性能优化技术,要么减少了磁盘的工作量(比如 PageCache 缓存),要么减少了 CPU 的工作量(比如直接 IO),要么提高了内存的利用率(比如零拷贝)。你在学习其他磁盘 IO 优化技术时,可以延着这三个优化方向前进,看看究竟如何降低时延、提高并发能力
五 分布式系统优化
19 | 如何通过监控找到性能瓶颈?
根据二八原则,只有优化处于性能瓶颈的少量代码,才能用最小的成本获得最大的收益。
单机:如何通过火焰图找到性能瓶颈
最直接有效的方式,从代码层面直接寻找调用最频繁、耗时最长的函数,通常这个就是瓶颈。
完成这样的目标,通常有3个约束条件
- 代码没有侵入性。如果代码前后都打时间戳,开发维护成本太高
- 覆盖代码中的全部函数。靠猜测部分函数不准确
- 搭建环境的成本要低。
火焰图
-
X轴:函数执行时间。图中方块的长度近似等于执行时间
-
Y轴:函数调用栈
Linux内核默认支持perf工具,可以通过perfs生成函数的采样数据,再用FlameGraph脚本生成火焰图。Arthas 阿尔萨斯提供的async-profiler生成火焰图
https://www.wdbyte.com/2019/12/async-profiler/
https://juejin.cn/post/6982844438527606797
通过普罗米修斯健康Java程序,监控内存、GC、CPU、堆、线程、元空间等情况,再结合火焰图优化
https://cloud.tencent.com/document/product/457/48724
分布式系统:全链路监控找到瓶颈
Skywalking
20 | CAP理论:怎样舍弃一致性去换取性能?
如何权衡性能与一致性?
这里针对有状态服务的性能优化。所谓有状态服务:进程会在处理完请求后,仍然保存着影响下次请求结果的用户数据-数据库进程,而无状态则是只从每个请求的输入中获取数据,处理结束不保留任何会话-业务处理进程。
CAP
- 一致性
- 可用性
- 分区容错性
对一致性模型分类:
- 数据出发设计的一致性模型:顺序一致性必须按照读写的次序来保证一致性,而不具备因果关系的读写操作并发
- 用户设计出发设计的一致性模型:单调读一致性保证客户端不会读到旧值,而单调写保证写操作是串行的。
工程中多了最终一致性概念,BASE理论:
- Basically Available 基本可用性
- Soft state 软状态
- Eventually consistent 最终一致性
如何舍弃一致性提升性能?
服务的性能,主要体现在请求的时延和并发性两个方面。通常把分布式系统分为纵向和横向两个维度,纵向是请求处理路径,横向则是同类服务之间数据同步路径。
纵向上:增加缓存降低时延长
横向上:增加数据副本,并在主机之间同步数据,提高并发性。
纵向缓存如何降低时延,保证最终一致性的。
缓存由读、写两个操作触发更新。
Write Back(牺牲一致性,低时延) 和Write through(很好的一致性,时延更久)
水平扩展:同步(一致性好,延迟高,并发低,性能低)和异步(性能高,而且异步后,主进程可以基于合并、批量处理等技巧,效率更高)。比如MySQL 主备,默认异步:同步所有和一个副本成功就行(增强半同步复制)。
宕机扩容等情况下,要结合快照,快照这点的数据,以及从改点到当前所有更新的操作。
21 | AKF立方体:怎样通过可扩展性来提高性能?
如何基于AKF X 轴扩展系统?
AKF把系统扩展分为以下三个维度:
X轴:直接水平复制应用进程来扩展系统
Y轴:讲功能拆分出来扩展系统(代码难)
Z轴:基于用户信息扩展系统(运维难)
AKF X轴:只能扩展无状态服务(如:业务处理进程),当有状态的数据库出现性能瓶颈时,X轴就无能为力。
用户频率越来越高,可以沿着Y轴把读写功能分离提升性能
数据库量大,SQL越来越慢,需要沿着AKF Z轴去分库分表提升性能。
如何基于 AKF Y 轴扩展系统?
当数据的CPU、网络带宽、内存、磁盘IO等某个指标到达上限后,系统的吞吐量就达到了瓶颈,此时沿着AKF X轴的扩展系统,是无法提升性能的(数据库限制了)。
更细分、专业化能带来更高的效率。当上述性能瓶颈后,拆分系统功能,使得各组件的职责、分工更细,可以提升系统的效率。比如拆分读写。
当一台主库无法抗住所有的写流量。需要基于业务特性拆分功能。拆分成多个子系统,由无状态业务代码分开调用,并通过事务组合在一起。(我理解:多个写服务,通过事务连接)。
我理解:当有状态的数据库出现瓶颈,单纯的AKF X横向扩展已经没有用了,需要扩展有状态的数据库进程。使用AKF Y周扩展,拆分(更拆分)、细化(或者更细化)。
沿着Y轴拆分,成本非常高,需要重构代码并且进行大量的测试工作,上线部署也很复杂。
如何基于 AKF Z 轴扩展系统?
从用户维度拆分系统。无论基于Y轴的功能怎么拆分表,都无法处理千万级单表。
分库分表是AKF 沿Z轴拆分系统的实践。比如用户表,上亿,拆分到10个库,每个库再拆分到10张表。利用固定的哈希函数,每个用户的数据映射到某个库的某张表。带来的问题就是,事务。
沿着Z轴拆分,可以做一些额外的工作,userId是拆分键,可以再这上面做一些逻辑,比如是免费和付费用户,可以提供不同水准的服务
22 | NWR算法:如何修改读写模型以提升性能?
指在去中心化的系统中将1分数据存在N个节点上,每次操作时候,写W个节点、读R个节点,只要调整W、R与N的关系,就能动态地平衡一致性与性能。
从鸽巢原理到 NWR 算法
鸽巢原理告诉我们:只要哈希函数输入主键的值范围大于输出索引,出现冲突的概率一定大于0;只要存放元素的数量超过哈希桶的数量,就必然会发生冲突。
基于鸽巢算法,1979年提出Quorum算法:冗余数据存放到N个节点上,每次写操作成功写入W个节点,读操作则从R个节点中选择并读出正确的数据,只要保证W+R > N ,同一条数据就不能并发执行,这样客户端总能读到最新写入的数据。 特别是 W > N/2 时,就能使去中心的分布式系统获得强一致性。
比如,若 N 为 3,那么设置 W 和 R 为 2 时,在保障系统强一致性的同时,还允许 3 个节点中 1 个节点宕机后,系统仍然可以提供读、写服务,这样的系统具备了很高的可用性。 如果我们将 R、W 都设置成 2,这就满足了 R + W > N(3) 的场景,此时系统具备了强一致性。客户端读写数据时,必须有 2 个节点返回,才算操作成功。比如下图中读取数据时,只有接收到节点 1、节点 6 的返回,操作才算成功(两个节点返回正确的数据)
节点异常,NWR是如何保证强一致性的:
3个节点,写入两个,写入完成,另外一个超时了,强制性性的要求下,开始读取,必须能获取到第二步的数据;根据不同的timestamp 时间戳,Coordinator Node 发现节点 3 上的数据才是最后写入的数据,因此选择其上的数据返回客户端。这也叫Last-Write-Win策略
23 | 负载均衡:选择Nginx还是OpenResty?
对负载均衡最基本要求,它的吞吐量要远大于上游服务器。目前性能最好的是Nginx,以及在Nginx之上构建的OpenResty。
负载均衡是如何扩展系统提升性能的?
通过 AKF 立方体X轴扩展系统时,负载均衡只需要能够透传协议,并选择负载最低的上游
应用作为流量分发对象即可。这样,三层(网络层)、四层(传输层)负载均衡都可用于扩展系统,甚至在单个局域网内你还可以使用二层(数据链路层)负载均衡。
基于 AKF Y 轴扩展系统时,负载均衡必须根据功能来分发请求,也就是说它必须解析完应用层协议,才能明白这是什么请求。
因此,如 LVS 这样工作在三层和四层的负载均衡就无法满足需求了,我们需要 Nginx 这样的七层(应用层)负载均衡,它能够从请求中获取到描述功能的关键信息,并以此为依据路由请求。
基于 AKF Z 轴扩展时,如果只是使用了网络报文中的源 IP 地址,那么三层、四层(F5、LVS)负载均衡都能胜任。然而如果需要帐号、访问对象等用户信息扩展系统,仍然只能使用七层负载均衡从请求中获得
Nginx 上为什么可以执行 Lua 代码?
OpenRestry非常流行,它就是Nginx,只是通过扩展的C模块支持在Nginx中嵌入Lua语言。
编译 Nginx 时,OpenResty 将自己的第三方 C 模块按照 Nginx 的规则添加到可执行文件中,包括 ngx_http_lua_module 和 ngx_stream_lua_module 这两个 C 模块,它们允许 Lua 语言运行在 Nginx 进程中
Lua模块既能够享受Nginx的高性能,又能通过协程、Lua脚本提高开发效率。
Nginx 在进程启动、处理请求时提供了许多钩子函数,允许第三方 C 模块将其代码放在这些钩子函数中执行。同时,Nginx 还允许 C 模块自行解nginx.conf 中出现的配置项
Nginx 与 OpenResty 的差别在哪里?
OpenResty 放弃了 Nginx 官方的 configure 文件,用户需要使用 OpenResty 改造过的configure 脚本编译 Nginx
如果你需要使用OpenResty、TEngine 中的部分 C 模块,可以通过–add-module 选项将其加入到官方Nginx 中。
总结
Nginx 的开放式架构允许第三方模块通过 10 多个钩子函数,在不同的生命周期中处理请求。 同时,还允许 C 模块自行解nginx.conf 配置文件。
OpenResty 就通过 2 个C 模块,将 Lua 代码用 LuaJIT 编译到 Nginx 中执行,并通过 FFI 技术将 C 函数暴露给Lua 代码。这就是 OpenResty 允许 Lua 语言与 C 模块协同处理请求的原因
ngx_http_lua_module 和 ngx_stream_lua_module 这两个模块通过FFI 技术,将 C 函数通过 Ngx 库中的 Lua API,暴露给纯 Lua 代码
24 | 一致性哈希:如何高效地均衡负载?
必须解决分布式系统扩展时可能出现的两个问题:数据分布不均衡和访问量不均衡。
如何减少扩容、缩容时迁移的数据量?
一致性哈希算法,可以大幅减少数据迁移量。一致性哈希算法通过以下两个步骤建立数据和主节点间映射关系的:
- 将关键字经由通用的哈希函数映射为32位整形哈希值,最大数2的32次方相等于0。
- 其次:设集群节点为N,将哈希环由小到大分为N短。每个主机节点处理哈希值落在该段内的数据。(可以不均匀分布,性能好的,分配的多些)
在扩容、缩容的时候,虽然节点发生了变化,但是只需要小幅度调整各个节点的位置,就不会导致大量数据迁移。
比较:
总条数是M,节点数是N。比较:
传统的直接hash,时间复杂度是O(1)
一致性哈希算法:将关键字转成32位整数O(1),然后再根据Hash环各个节点的范围,找到所属节点,由于节点是有序的,所以二分法,O(logN)时间复杂度内完成。
但是比较数据迁移的话,传统的考虑迁移O(M)-全部;对应一致性哈希算算法,考虑均匀分布的情况下,迁移规模O(M/N)。
通过虚拟节点提高均衡度
一致性哈希算法虽然降低了数据迁移量。缺留下两个问题:
- 哈希映射后哈希环中的数字分布不均匀,数据倾斜
- 容灾与扩容时,哈循环上相邻的节点容易受到过大的影响(环是顺序的);比如节点0挂了,所有的数据都要迁移到节点1上,节点1能给访问挂掉,引起雪崩。扩容也只会减轻相邻节点的负载。
在真实的数据节点与哈希环之间引入一个虚拟节点层,就可以解决上述问题
至于虚拟节点为什么可以让数据的分布更均衡,这是因为在虚拟节点与真实节点间,又增加了一层哈希映射,哈希函数会将原本不均匀的数字进一步打散(我理解:增加了虚拟节点,原本假如4个节点,依次放一起,现在弄了更多的虚拟节点,假如32个,交错的放起来,每个真实的节点,处理的数据是总数的1/4,但是部分不连续了,还是能找到了,就是通过增加的那层hash映射)
25 | 过期缓存:如何防止缓存被流量打穿?
只要系统间的访问速度有较大差异,缓存就能提升性能。 缓存提升性能的幅度,不只取决于存储介质的速度,还取决于缓存命中率
缓存是最有效的性能提升工具
我们会使用高速的存储介质创建缓冲区,通过预处理、批处理以及缓冲数据的反复命中,提升系统的整体性能
缓存数据的更新方式
通常,缓存数据的添加或者更新,都是由用户请求出发的,这往往可以带来更高的命中率。
对磁盘操作,可以基于空间局部性原理,采用预读算法添加进缓存数据。
- 可以减少定位提高磁盘工作效率。
- 当后续的请求命中提前读入缓存数据的时候,请求延迟大幅降低,提高了用户体验。
两种常见的缓存淘汰算法: - FIFO
- LRU
为了避免缓存与源数据不一致,通常会基于过期时间来淘汰缓存。
Nginx 是如何防止流量打穿缓存的?
当热点缓存淘汰后,大量的并发请求会同时回源上游应用,其实这是不必要的。Nginx 的合并回源功能开启后,Nginx 会将多个并发请求合并为 条回源请求,并锁住所有的客户端请求,直到回源请求返回后,才会更新缓存,同时向所有客户端返回响应
总结
当组件间的访问速度差距很大时,直接访问会降低整体性能,在二者之间添加更快的缓存是常用的解决方案
根据时间局部性原理,将请求结果放入缓存,会有很大概率被再次
中,而根据空间局部性原理,可以将相邻的内容预取至缓存中,这样既能通过批处理提升效率,也能降低后续请求的时延
如何应对高并发,
- 并发应对三件套-缓存-限流-熔断降级
系统性能调优2个方面总结下