目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
日志概述
1、日志作用
在项目开发或测试过程中,项目运行一旦出现问题,记录日志信息就显得尤为重要。主要通过日志来定位问题,就好比侦探人员要根据现场留下的线索来推断案情。
2、日志级别
代码在运行的过程中会出现不同的情况,如调试信息、警告信息、报错等,那么采集日志时就需要对这些日志区分级别管理,这样才能更精确地定位问题。
日志级别一般分类如下(以严重程度递增排序):
| 级别 | 何时使用 |
|---|---|
| DEBUG | 调试信息,也是最详细的日志信息 |
| INFO | 证明事情按预期工作 |
| WARNING | 表明发生了一些意外,或不久的将来会发生问题(如磁盘满了),软件还是正常工作 |
| ERROR | 由于更严重的问题,软件已经不能执行一些工作了 |
| CRITICAL | 严重错误,表明软件已经不能继续运行了 |
日志级别排序为:CRITICAL > ERROR > WARNING > INFO > DEBUG
日志采集时设置低级别的日志,能采集到更高级别的日志,但不能采集到更低级别的日志。
例如:设置的日志级别为info级别,就只能采集到info、warning、error、critical级别的日志,不能采集到debug级别的日志。设置的日志级别为debug级别的话则能采集到所有级别的日志。默认设置级别为WARNING。
在自动化测试项目中,通常在一般情况时使用info日志,预计报错则使用error日志。
3、日志格式
将日志格式化是为了提高日志的可阅读性,比如:时间+模块+行数+日志级别+日志具体信息 的日志格式。如果输出的日志信息杂乱无章,就不利于问题的定位。如下所示就是日志格式化输出,非常便于阅读查看。
2023-08-08 10:45:05,119 logging_test.py[line:7] DEBUG this is debug message.
2023-08-08 10:45:05,119 logging_test.py[line:9] INFO this is info message.
2023-08-08 10:45:05,119 logging_test.py[line:11] WARNING this is warning message.
2023-08-08 10:45:05,120 logging_test.py[line:13] ERROR this is error message.
2023-08-08 10:45:05,120 logging_test.py[line:15] CRITICAL this is critical message.
4、日志位置
通常,在一个项目中会有很多的日志采集点,日志采集点的设置必须结合业务来确定。
比如在执行修改登录密码用例前插入“开始执行修改登录密码用例…”的日志信息。再比如在登录代码执行前可以插入“准备登录…”日志信息。
如果在登录完成后,再设置登录的提示日志就会给人造成误解,无法判断到底是登录之前的问题还是登录之后的问题,因此日志采集点的位置很重要。
logging 日志模块
logging为python自带的日志模块,提供了通用的日志系统,包括不同的日志级别。
logging可使用不同的方式记录日志,如使用文件,HTTP GET/POST,SMTP,Socket等方式记录。通常情况下,我们使用文件记录日志信息,文件格式一般为.txt或.log文件。
logging 第一种使用方法
简单配置使用
1、使用方法
logging.basicConfig(**kwargs)
2、basicConfig()部分参数说明
filename 指定日志名称或完整路径,如:E:/app-ui-autotest/log/log.txt
filemode 指定打开文件的模式(如果文件打开模式未指定,则默认为’a’)
常见的文件读写方式:
w 以写的方式打开;
W 清空后写入(文件已存在);
r 以读的方式打开;
a 以追加模式打开(即在文件原有的数据后面添加);
format 指定日志输出格式;
level 将根记录器级别设置为指定级别
3、示例1:
日志打印至控制台
import logging
logging.basicConfig(filename='./log.txt', level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d]
%(levelname)s %(message)s')
logging.debug('This is debug message')
logging.info('This is info message')
logging.warning('This is warning message')
logging.error('This is error message')
logging.critical('This is critical message')
控制台输出结果:
2023-08-08 10:45:05,119 logging_test.py[line:7] DEBUG This is debug message.
2023-08-08 10:45:05,119 logging_test.py[line:9] INFO This is info message.
2023-08-08 10:45:05,119 logging_test.py[line:11] WARNING This is warning message.
2023-08-08 10:45:05,120 logging_test.py[line:13] ERROR This is error message.
2023-08-08 10:45:05,120 logging_test.py[line:15] CRITICAL This is critical message.
4、示例2
日志保存至文件
logging.basicConfig(filename='log.txt', level=logging.INFO,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
logging.debug('This is debug message')
logging.info('This is info message')
logging.warning('This is warning message')
logging.error('This is error message')
logging.critical('This is critical message')
输出格式:
2023-08-08 10:45:05,119 logging_test.py[line:9] INFO This is info message.
2023-08-08 10:45:05,119 logging_test.py[line:11] WARNING This is warning message.
2023-08-08 10:45:05,120 logging_test.py[line:13] ERROR This is error message.
2023-08-08 10:45:05,120 logging_test.py[line:15] CRITICAL This is critical message.
注意:
相较于控制台打印日志,文件保存日志的区别在于basicConfig()方法中加入了filename参数(即文件的完整路径)。
保存日志至文件示例中,因为参数level=logging.INFO,所以DEBUG级别的日志未输出
logging 第二种使用方法
日志流处理流程
1、logging四大组件介绍
logging模块包括Logger,Handler,Filter,Formatter四个部分。
Logger 记录器,用于设置日志采集。
Handler 处理器,将日志记录发送至合适的路径。
Filter 过滤器,提供了更好的粒度控制,它可以决定输出哪些日志记录。
Formatter 格式化器,指明了最终输出中日志的格式。
2、Logger 记录器
使用日志流采集日志时,须先创建Logger实例,即创建一个记录器(如果没有显式的进行创建,则默认创建一个root logger,并应用默认的日志级别WARNING,Handler和Formatter)
然后做以下三件事:
为程序提供记录日志的接口;
根据过滤器设置的级别对日志进行过滤;
将过滤后的日志根据级别分发给不同handler;
3、Handler 处理器
Handler处理器作用是,将日志记录发送至合适的路径。如发送至文件或控制台,此时需要使用两个处理器,用于输出控制台的处理器,另一个是用于输出文件的处理器。通过 addHandler() 方法添加处理器 。常用的处理器类型有以下两种:
StreamHandler
将日志信息发送至sys.stdout、sys.stderr或任何类似文件流对象,如在Pycharm IDE上显示的日志信息。
构造函数为:StreamHandler(strm)。参数strm是一个文件对象,默认是sys.stderr。
FileHandler
将日志记录输出发送至磁盘文件。 它继承了StreamHandler的输出功能,不过FileHandler会帮你打开这个文件,用于向一个文件输出日志信息。
构造函数为:FileHandler(filename, mode)。参数filename为文件名(文件完整路径),参数mode为文件打开方式,默认为’a’即在文末追加。
自动化测试使用这两种类型就够了,其他还有RotatingFileHandler、TimedRotatingFileHandler、NullHandler等处理器,有兴趣可以查找资料了解。
4、Filter 过滤器
顾名思义是用于过滤,Handlers 与 Loggers 使用 Filters 可以完成比级别更复杂的过滤。不多做介绍,有兴趣可以查找资料了解。
5、Formatter 格式化器
Formatter用于设置日志的格式与内容,默认的时间格式为%Y-%m-%d %H:%M:%S,更多格式如下:
%(levelno)s # 打印日志级别的数值
%(levelname)s #打印日志级别的名称
%(pathname)s #打印当前执行程序的路径
%(filename)s #打印当前执行程序的名称
%(funcName)s #打印日志的当前函数
%(lineno)d #打印日志的当前行号
%(asctime)s #打印日志的时间
%(thread)d #打印线程ID
%(threadName)s #打印线程名称
%(process)d #打印进程ID
%(message)s #打印日志信息
6、使用示例:将日志输出至控制台,同时保存至文件
根据logging的模块化来编写代码,思路参考如下。
目录结构
logging_test.py
import logging
# 第一步,创建日志记录器
# 1,创建一个日志记录器logger
logger = logging.getLogger()
# 2,设置日志记录器的日志级别,这里的日志级别是日志记录器能记录到的最低级别,区别于后面Handler里setLevel的日志级别
logger.setLevel(logging.DEBUG)
# 第二步,创建日志处理器Handler。这里创建一个Handler,用于将日志写入文件
# 3,创建一个Handler,用于写入日志文件,日志文件的路径自行定义
logFile = './log.txt'
fh = logging.FileHandler(logFile, mode='a', encoding='utf-8')
# 4,设置保存至文件的日志等级
fh.setLevel(logging.INFO)
# 第三步,定义Handler的输出格式
# 5,日志输出格式定义如下
format= logging.Formatter('%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
# 6,设置 写入日志文件的Handler 的日志格式
fh.setFormatter(format)
# 第四步,将Handler添加至日志记录器logger里
logger.addHandler(fh)
# 同样的,创建一个Handler用于控制台输出日志
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
ch.setFormatter(format)
logger.addHandler(ch)
# 输出日志
logger.info("This is info message")
logger.warning("This is warning message")
logger.error("This is error message")
logger.critical("This is critical message")
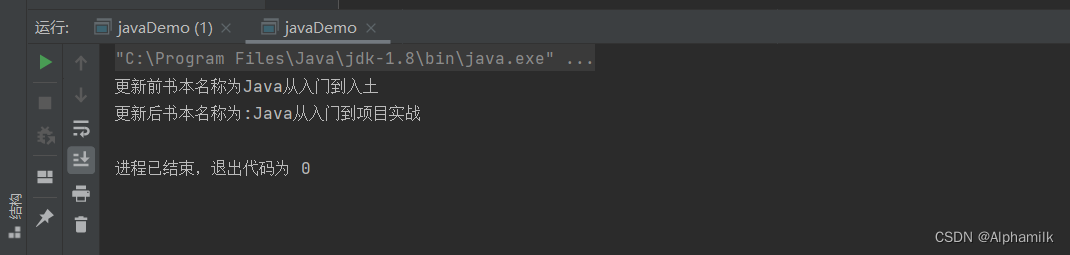
Pycharm运行logging_test.py模块,log.txt以及Pycharm控制台得到如下结果:
2023-08-08 15:54:04,752 test.py[line:3] INFO This is info message
2023-08-08 15:54:04,752 test.py[line:4] WARNING This is warning message
2023-08-08 15:54:04,752 test.py[line:5] ERROR This is error message
2023-08-08 15:54:04,752 test.py[line:6] CRITICAL This is critical message
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
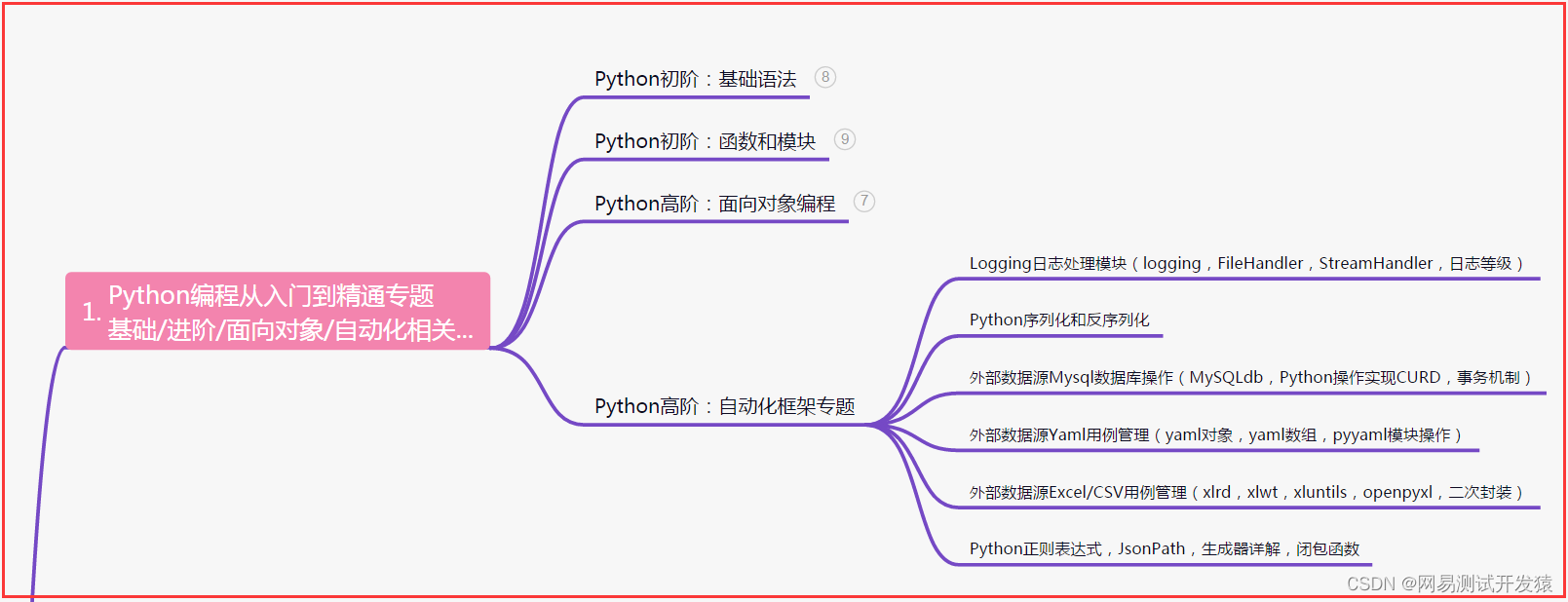
二、接口自动化项目实战
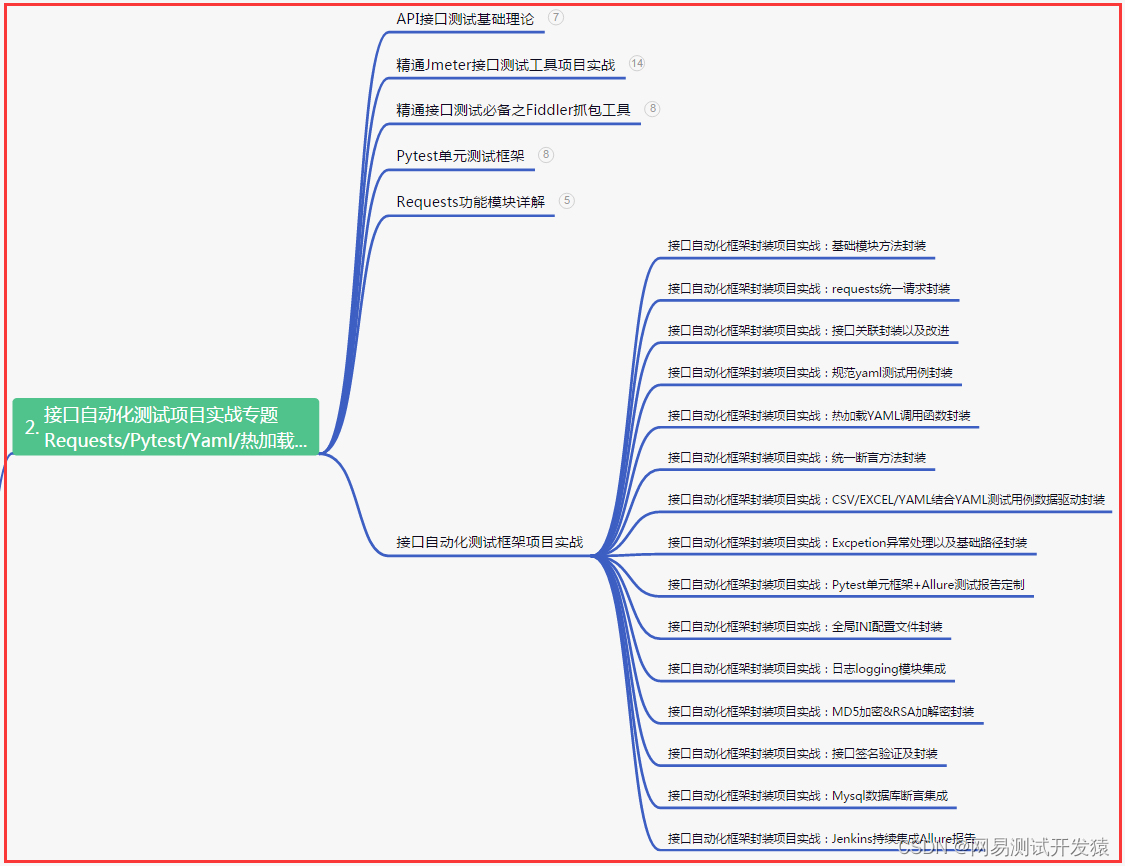
三、Web自动化项目实战
四、App自动化项目实战
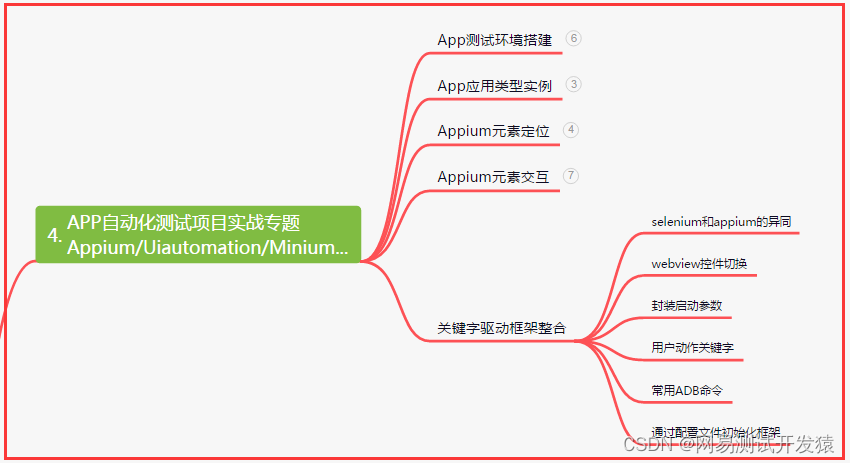
五、一线大厂简历
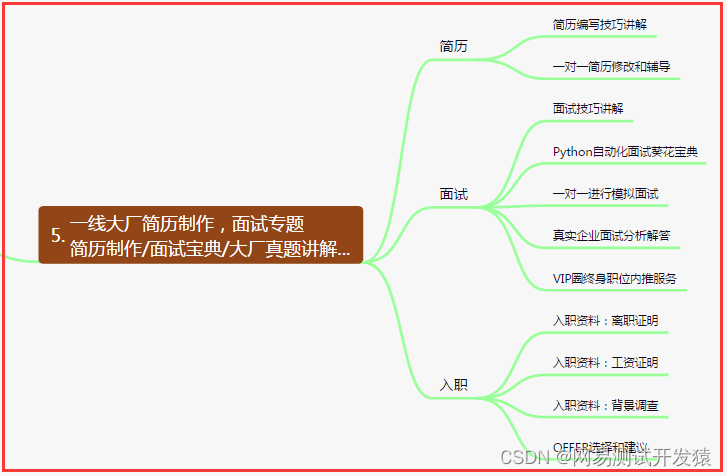
六、测试开发DevOps体系
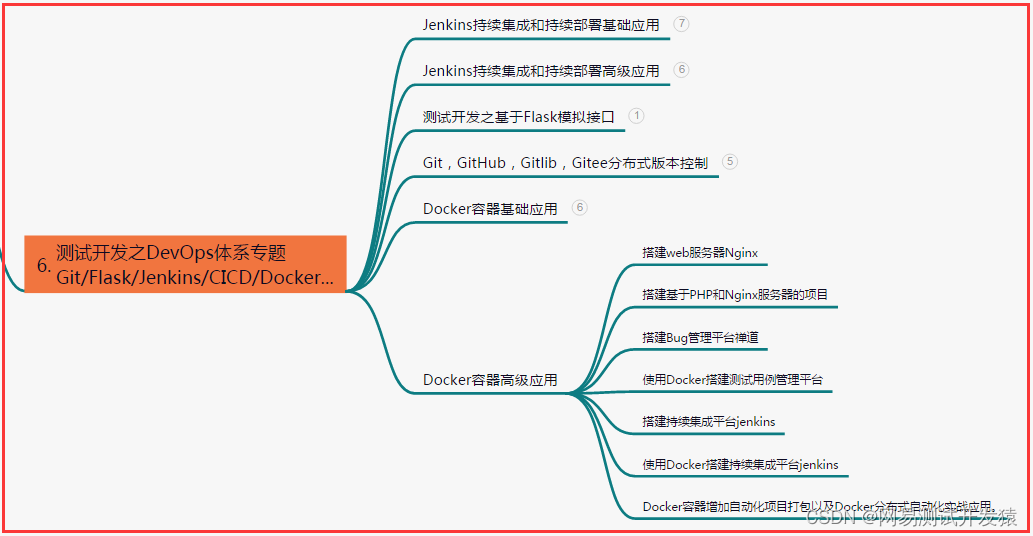
七、常用自动化测试工具

八、JMeter性能测试
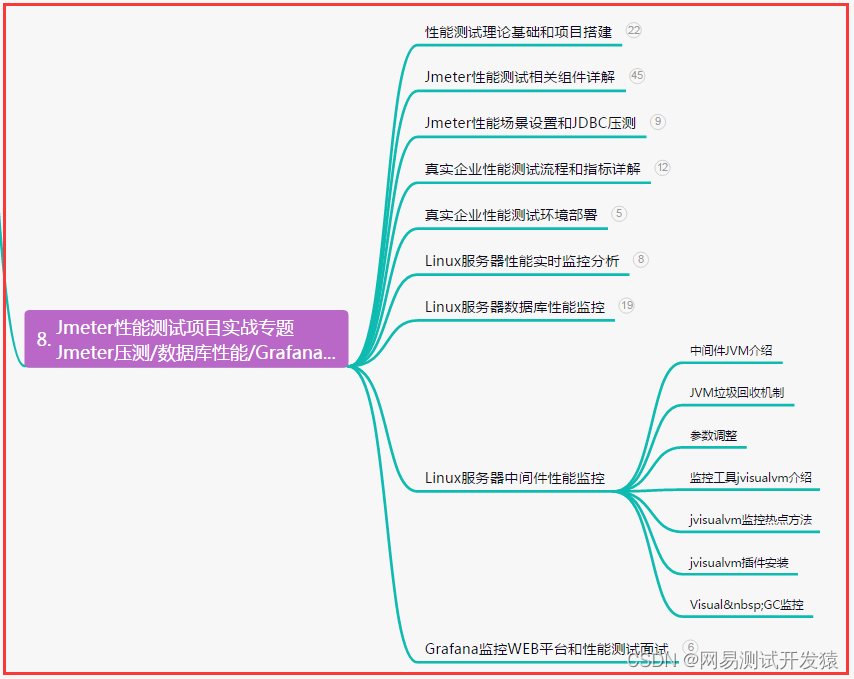
九、总结(尾部小惊喜)
不惧困难,不畏挑战,在每一次奋斗中磨砺自己,只有坚持不懈的努力,才能让梦想如雄鹰展翅,飞向辽阔的天空。勇敢地追逐,默默耕耘,你终将收获理想的果实,成就璀璨人生。
不管有多遥远,不管有多艰辛,只要心怀梦想,脚踏实地,努力奋斗,就能驶向成功的彼岸。每一次的坚持都是一次进步,每一次的努力都是一份成长,让我们勇敢地追逐,创造属于自己的辉煌人生。
在人生的征途上,只有燃烧自己的激情与勇气,才能谱写出无悔的篇章;不论身处何境,只有坚持奋斗,才能开辟通向成功的道路。相信自己,坚定前行,你将绽放出灿烂的光芒。




![[mongo]应用场景及选型](https://github.com/tutengdihuang/image/assets/31843331/0ac362e8-7916-4764-8c3d-c256fef60bcd)