一、说明
我将把这个系列分成 3 或 4 篇文章。在本系列的最后,您将了解使用flask构建 restful API 是多么容易。在本文中,我们将设置环境并创建将显示“Hello World”的终结点。
我假设你的电脑上安装了python 2.7和pip。我已经在python 2.7上测试了本文中介绍的代码,尽管在python 3.4或更高版本上可能没问题。
二、 安装flask
a. Installing flask
Flask是python的微框架。微框架中的“微”意味着Flask旨在保持核心简单但可扩展(http://flask.pocoo.org/docs/0.12/foreword/#what-does-micro-mean)。您可以使用以下命令安装flask:
$ pip install Flask
b.准备您的 IDE
实际上,您可以使用所有类型的文本编辑器来构建python应用程序,但是如果您使用IDE,则会容易得多。就我个人而言,我更喜欢使用jetbrains(PyCharm: the Python IDE for Professional Developers by JetBrains)的Pycharm。
c. 在flask中创造“你好世界”
首先,您需要创建项目文件夹,在本教程中,我将它命名为“flask_tutorial”。如果您使用的是 pycharm,您可以通过从菜单中选择文件和新项目来创建项目文件夹。
之后,您可以设置项目位置和解释器。无论如何,您的计算机都可以有一些python解释器。
设置项目后,在pycharm上右键单击您的项目文件夹,然后选择新建-> Python文件并将其命名为“app.py”。
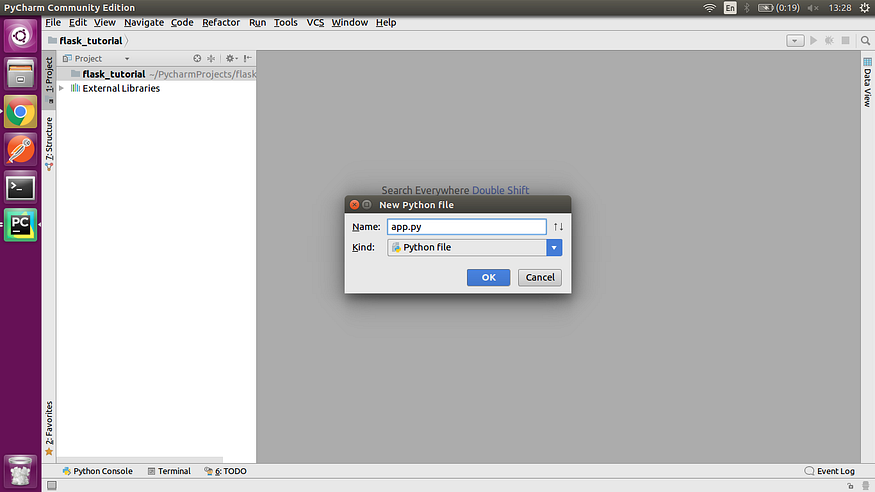
在 app.py 上写下下面的代码。
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!"
if __name__ == '__main__':
app.run(debug=True)从终端运行它。您可以使用命令行或从pycharm单击位于左下角的终端选项卡并在下面编写代码。
$ python app.py
打开浏览器并访问本地主机:5000。瞧,现在您有了第一个烧瓶应用:)

好的,现在让我们看一下代码。
from flask import Flask此行要求应用程序从烧瓶包导入烧瓶模块。用于创建 Web 应用程序实例的烧瓶。
app = Flask(__name__)此行创建 Web 应用程序的实例。__name__是 python 中的一个特殊变量,如果模块(python 文件)作为主程序执行,它将等于“__main__”。
@app.route("/")此行定义路由。例如,如果我们像上面一样将路由设置为“/”,如果我们访问 localhost:5000/,代码将被执行。您可以将路由设置为“/hello”,如果我们访问localhost:5000 / hello,将显示我们的“hello world”。
def hello():
return "Hello World!"这条线定义了如果我们访问路由时将执行的函数。
if __name__ == '__main__':
app.run(debug=True) 此行表示如果我们从 app.py 运行,您的烧瓶应用将运行。另请注意,我们将参数设置为 。这将在网页上打印出可能的 Python 错误,帮助我们跟踪错误。debug true
好的,这就是第 1 部分的全部内容,接下来我们将尝试使用 flask 在 SQLLite 上进行 CRUD 操作。
三、使用flask和SQLite构建简单的restful api
在本文中,我将向您展示如何使用flask和SQLite构建简单的restful api,这些api具有从数据库中创建,读取,更新和删除数据的功能。
3.1 安装 flask-sqlalchemy and flask-marshmallow
SQLAlchemy 是 python SQL 工具包和 ORM,可为开发人员提供 SQL 的全部功能和灵活性。其中 flask-sqlalchemy 是 flask 扩展,它添加了对 SQLAlchemy 的支持到 flask 应用程序 (Flask-SQLAlchemy — Flask-SQLAlchemy Documentation (2.x))。
另一方面,flask-marshmallow 是 Flask 扩展,用于将 Flask 与 Marshmallow(对象序列化/反序列化库)集成。在本文中,我们使用flask-marshmallow 来渲染json 响应。
您可以使用 pip 轻松安装 flask-sqlalchemy 和 flask-marshmallow,使用以下命令:
$ pip install flask_sqlalchemy
$ pip install flask_marshmallow
$ pip install marshmallow-sqlalchemy3.2.准备代码
在名为 crud.py 的文件夹上创建新的flask_tutorial python文件。在 crud.py 中记下以下代码。
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
from flask_marshmallow import Marshmallow
import os
app = Flask(__name__)
basedir = os.path.abspath(os.path.dirname(__file__))
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'crud.sqlite')
db = SQLAlchemy(app)
ma = Marshmallow(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True)
email = db.Column(db.String(120), unique=True)
def __init__(self, username, email):
self.username = username
self.email = email
class UserSchema(ma.Schema):
class Meta:
# Fields to expose
fields = ('username', 'email')
user_schema = UserSchema()
users_schema = UserSchema(many=True)
# endpoint to create new user
@app.route("/user", methods=["POST"])
def add_user():
username = request.json['username']
email = request.json['email']
new_user = User(username, email)
db.session.add(new_user)
db.session.commit()
return jsonify(new_user)
# endpoint to show all users
@app.route("/user", methods=["GET"])
def get_user():
all_users = User.query.all()
result = users_schema.dump(all_users)
return jsonify(result.data)
# endpoint to get user detail by id
@app.route("/user/<id>", methods=["GET"])
def user_detail(id):
user = User.query.get(id)
return user_schema.jsonify(user)
# endpoint to update user
@app.route("/user/<id>", methods=["PUT"])
def user_update(id):
user = User.query.get(id)
username = request.json['username']
email = request.json['email']
user.email = email
user.username = username
db.session.commit()
return user_schema.jsonify(user)
# endpoint to delete user
@app.route("/user/<id>", methods=["DELETE"])
def user_delete(id):
user = User.query.get(id)
db.session.delete(user)
db.session.commit()
return user_schema.jsonify(user)
if __name__ == '__main__':
app.run(debug=True)对于短代码,上面的代码将具有 5 个端点,具有创建新记录、从数据库中获取所有记录、按 id 获取记录详细信息、更新所选记录和删除所选记录的功能。同样在此代码中,我们为数据库定义模型。
让我们逐部分看一下代码
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
from flask_marshmallow import Marshmallow
import os 在这一部分,我们导入应用程序所需的所有模块。我们导入 Flask 来创建 Web 应用程序的实例,请求获取请求数据,jsonify 将 JSON 输出转换为具有应用程序/json mimetype 的对象,从 flask_sqlalchemy 到 访问数据库的 SQAlchemy,以及从flask_marshmallow到序列化对象的 Marshmallow。Response
app = Flask(__name__)
basedir = os.path.abspath(os.path.dirname(__file__))
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'crud.sqlite')这部分创建我们的 Web 应用程序的实例并设置我们的 SQLite uri 的路径。
db = SQLAlchemy(app)
ma = Marshmallow(app)在这一部分,我们将SQLAlchemy和棉花糖绑定到我们的烧瓶应用程序中。
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True)
email = db.Column(db.String(120), unique=True)
def __init__(self, username, email):
self.username = username
self.email = email导入 SQLAlchemy 并将其绑定到我们的烧瓶应用程序后,我们可以声明我们的模型。在这里,我们声明名为 User 的模型,并用它的属性定义它的字段。
class UserSchema(ma.Schema):
class Meta:
# Fields to expose
fields = ('username', 'email')
user_schema = UserSchema()
users_schema = UserSchema(many=True)这部分定义了端点的响应结构。我们希望所有终结点都具有 JSON 响应。在这里,我们定义我们的 JSON 响应将有两个键(用户名和电子邮件)。此外,我们将user_schema定义为UserSchema的实例,user_schemas定义为UserSchema列表的实例。
# endpoint to create new user
@app.route("/user", methods=["POST"])
def add_user():
username = request.json['username']
email = request.json['email']
new_user = User(username, email)
db.session.add(new_user)
db.session.commit()
return jsonify(new_user)在这一部分,我们定义端点以创建新用户。首先,我们将路由设置为“/user”,并将HTTP方法设置为POST。设置路由和方法后,我们定义在访问此端点时将执行的函数。在此函数中,我们首先从请求数据中获取用户名和电子邮件。之后,我们使用请求数据中的数据创建新用户。最后,我们将新用户添加到数据库中,并以JSON形式显示新用户作为响应。
# endpoint to show all users
@app.route("/user", methods=["GET"])
def get_user():
all_users = User.query.all()
result = users_schema.dump(all_users)
return jsonify(result.data)在这一部分中,我们定义端点以获取所有用户的列表,并将结果显示为JSON响应。
# endpoint to get user detail by id
@app.route("/user/<id>", methods=["GET"])
def user_detail(id):
user = User.query.get(id)
return user_schema.jsonify(user)就像这部分的前一部分一样,我们定义了端点来获取用户数据,但不是在这里获取所有用户,我们只是根据 id 从一个用户那里获取数据。如果仔细查看路由,可以看到此终结点的路由上有不同的模式。像“<id>”这样的父亲是参数,所以你可以用你想要的一切来改变它。这个参数应该放在函数参数上(在本例中为 def user_detail(id)),这样我们就可以在函数中获取这个参数值。
# endpoint to update user
@app.route("/user/<id>", methods=["PUT"])
def user_update(id):
user = User.query.get(id)
username = request.json['username']
email = request.json['email']
user.email = email
user.username = username
db.session.commit()
return user_schema.jsonify(user)在这一部分中,我们定义端点以更新用户。首先,我们调用与参数上的给定 id 相关的用户。然后,我们使用请求数据中的值更新此用户的用户名和电子邮件值。
# endpoint to delete user
@app.route("/user/<id>", methods=["DELETE"])
def user_delete(id):
user = User.query.get(id)
db.session.delete(user)
db.session.commit()
return user_schema.jsonify(user)最后,我们定义要删除用户的端点。首先,我们调用与参数上的给定 id 相关的用户。然后我们删除它。
四、 生成 SQLite 数据库
在上一步中,您已经编写了代码来处理SQLite的CRUD操作,但是如果您运行此python文件并尝试访问端点(您可以尝试访问localhost:5000 /user),您将收到类似于以下内容的错误消息
操作错误: (sqlite3.操作错误) 没有这样的表: 用户 [SQL: u'SELECT user.id AS user_id, user.username AS user_username, user.email AS user_email \nFROM user']
出现此错误消息的原因是您尝试从 SQLite 获取数据,但您还没有 SQLite 数据库。因此,在此步骤中,我们将在运行应用程序之前先生成SQLite数据库。您可以使用以下步骤在 crud.py 中基于您的模型生成 SQLite 数据库。
- 进入 Python 交互式外壳
首先,您需要在终端中使用以下命令进入python交互式shell:
$ 蟒蛇
2. 导入数据库对象并生成SQLite数据库
在 python 交互式 shell 中使用以下代码
从原油导入数据库
>>> db.create_all()>>>
crud.sqlite将在您的flask_tutorial文件夹中生成。
五、 运行flask应用
现在,在生成 sqlite 数据库后,我们就可以运行我们的烧瓶应用程序了。从终端运行以下命令以运行应用程序。
$ python crud.py
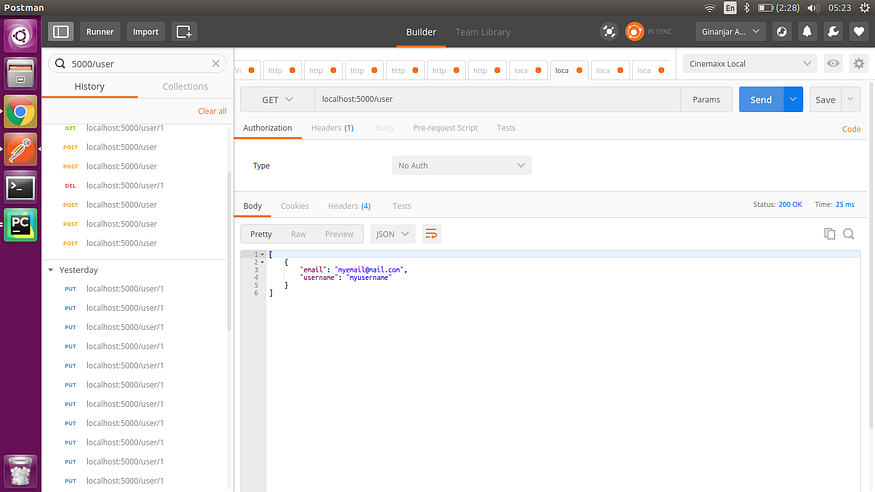
我们已经准备好尝试我们的烧瓶应用。要在我们的烧瓶应用程序中尝试端点,我们可以使用 API 开发工具,例如 curl 或 postman。就我个人而言,我喜欢 api 开发的邮递员(Postman)。在本文中,我将使用邮递员来访问端点。
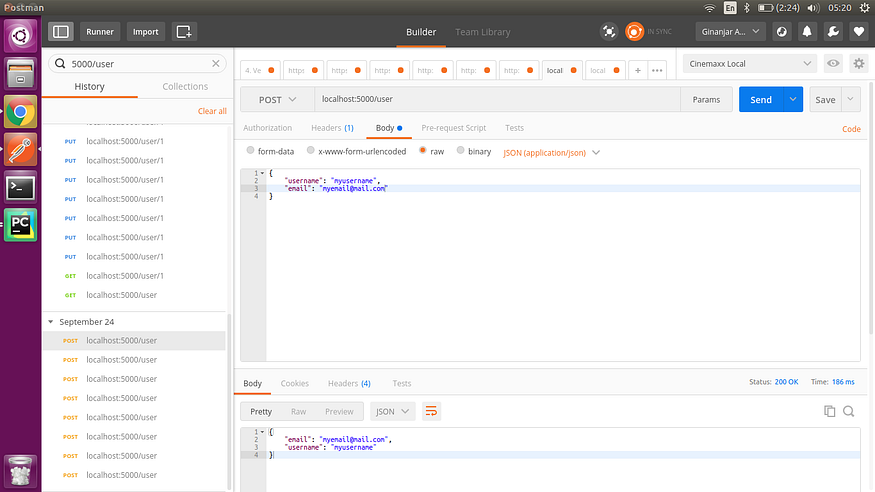
- 创建新用户
2. 获取所有用户

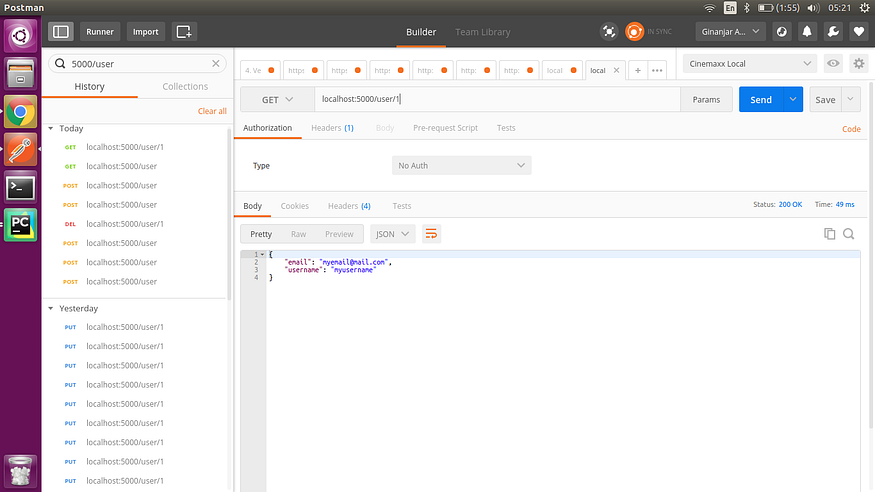
3. 通过 id 获取用户
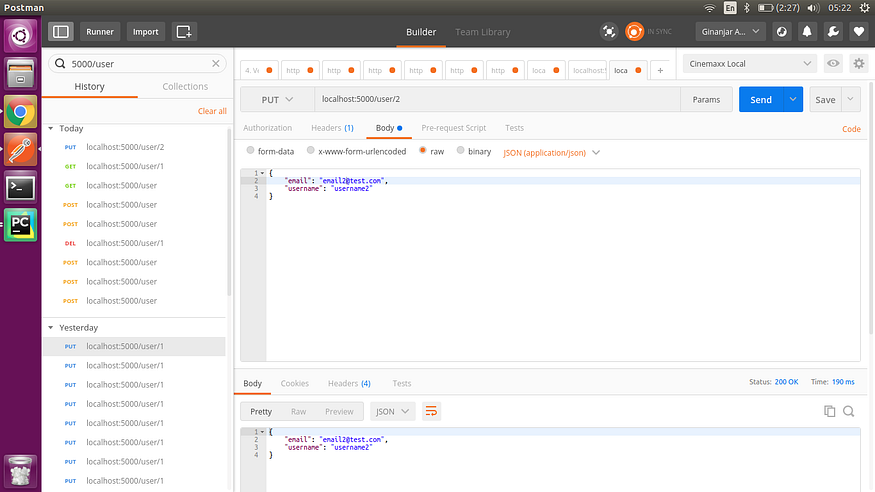
4. 更新用户

5. 删除用户

六、后记
这就是本文的全部内容。接下来,我计划使用 pytest 编写小型测试。