系列文章目录
文章目录
- 系列文章目录
- 前言
- 打开文件
- 预备知识
- 回顾C文件IO操作
- C语言I/O库函数
- fopen/fclose
- perror
- fwrite/fread
- fgets/fputs
- printf/fprintf/sprintf/snprintf
- stdin/stdout/stderr
- 标志位
- 系统调用IO接口
- open/close
- umask
- write/read
- lseek
- 库函数IO操作与系统调用IO操作比较
- 库函数与系统调用
- 文件描述符
- linux下一切皆文件
- FILE 结构体
- 重定向
- 文件描述符的分配规则
- 深入理解重定向
- 输出重定向
- 输入重定向
- 追加重定向
- dup2
- 缓冲区
- C库缓冲区刷新策略
- 自主封装
- fsync
- 语言层封装
- 存储文件
- 预备知识
- 磁盘的物理结构
- 磁盘的具体物理存储结构
- 逻辑抽象
- 磁盘文件系统
- inode
- 软硬链接
- 软连接
- 硬链接
- 动态库和静态库
- 见一见库
- 为什么要有库
- 设计一个库
- 设计静态库
- 设计动态库
- 库的加载
前言
基础IO是操作系统的一个重要功能,其中涉及到操作系统的文件管理。
打开文件
预备知识
-
文件原理和操作不是语言问题而是系统问题。
-
C/C++有文件操作,其他语言是否也有呢?如何解释这种现象?有没有一种统一的视角来看待不同语言的文件操作?
-
操作文件的第一件事情是打开文件,打开文件是做什么?如何理解?
-
**文件是内容加属性,**那么针对文件的操作,是对内容和属性的操作。
-
当文件没被操作的时候,文件一般会在什么位置(磁盘)。
-
当我们对文件进行操作的时候,文件需要在哪里(内存),因为冯诺依曼体系!
-
当我们对文件进行操作的时候,文件需要提前被load到内存,load是内容还是属性?至少得有属性吧。
-
当我们对文件进行操作的时候,文件需要提前被load到内存,是不是只有你一个人在load呢?不是,内存中一定存在大量的不同文件的属性
-
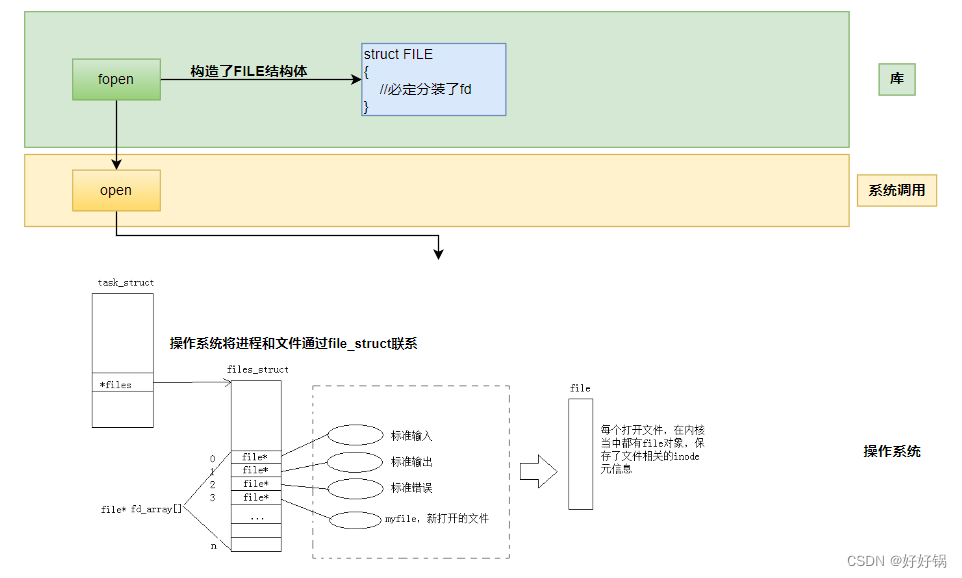
综上所述,打开文件本质就是将需要的文件属性加载到内存中,OS内部一定会同时存在大量的被打开的文件,那么操作系统要不要管理这些被打开的文件呢?先描述再组织!
-
文件被打开,是用户以进程为代表让OS打开的。
-
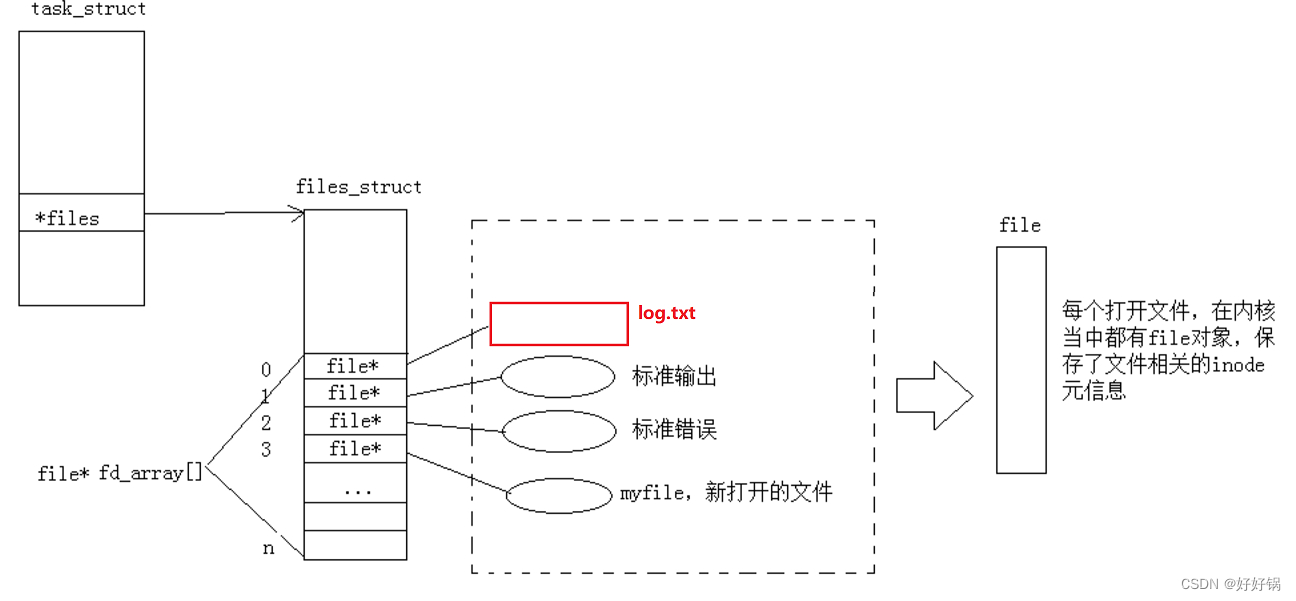
所有的文件操作,都是进程和被打开文件的关系,即 struct task_struct 和 struct file。
先描述再组织:构建在内存中的文件结构体 struct file(属性:就可以从磁盘来, struct file*next),通过指针进行链接管理。每一个被打开的文件,都要再OS内对应文件对象的struct结构体,可以将所有的struct file结构体用某种数据结构链接起来,在os内部,对被打开的文件进行管理,就转换成为对链表的增删改查。
struct file
{
//各种属性
//各种链接关系
}
结论:文件被打开,OS要为被打开的文件,创建对应的内核数据结构;文件其实可以被分为两大类:磁盘文件(没有被打开的文件)/内存文件(被打开的文件)
回顾C文件IO操作
C语言I/O库函数
fopen/fclose
man fopen/fclose
FILE *fopen(const char *path, const char *mode);
int fclose(FILE *fp);
int main()
{
FILE *fp = fopen(LOG, "w");
if(fp == NULL)
{
perror("fopen"); //fopen: XXXX
return 1;
}
const char *msg = "aaa\n";
int cnt = 5;
while(cnt)
{
fputs(msg, fp);
cnt--;
}
fclose(fp);
return 0;
}
w: 默认写方式打开文件,如果文件不存在,就创建它;默认如果只是打开,文件内容会自动被清空;每次进行写入的时候,都会从文件开头进行写入。
int main()
{
FILE *fp = fopen(LOG, "a");
if(fp == NULL)
{
perror("fopen"); //fopen: XXXX
return 1;
}
const char *msg = "aaa\n";
int cnt = 5;
while(cnt)
{
fputs(msg, fp);
cnt--;
}
fclose(fp);
return 0;
}
a: 不会清空文件而是每一次写入都是从文件结尾写入,即追加文件内容。
int main()
{
FILE *fp = fopen(LOG, "r");
if(fp == NULL)
{
perror("fopen"); //fopen: XXXX
return 1;
}
//正常进行文件操作
while(1)
{
char line[128];
if(fgets(line, sizeof(line), fp) == NULL) break;
else printf("%s", line);
}
fclose(fp);
return 0;
}
r: 默认读方式打开文件。
perror
man 3 perror
#include <stdio.h>
void perror(const char *s);
fwrite/fread
man fwrite/fread
#include <stdio.h>
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
//当前路径指的是每个进程,都有一个内置的属性cwd
//fwrite函数如果size_t count传入的数正好将字符串内容全部传入到指定文本中则返回count,否则返回与count不同的数
//fwrite函数传入内容的大小正好是size_t size,和size_t count的乘积
fgets/fputs
man fgets/fputs
#include <stdio.h>
char *fgets(char *s, int size, FILE *stream);
//从流中读取字符并将它们作为 C 字符串存储到 str 中,直到读取 (num-1) 个字符或到达换行符或文件结尾,以先发生者为准。
//换行符使 fgets 停止读取,但它被函数视为有效字符并包含在复制到 str 的字符串中。
//在复制到 str 的字符之后会自动附加一个终止空字符。
//fgets 与 get 完全不同:fgets 不仅接受流参数,还允许指定 str 的最大大小并在字符串中包含任何结束的换行符。
int fputs(const char *s, FILE *stream);
//fputs函数是将s所指向的数据往stream中所指向的文件中写
printf/fprintf/sprintf/snprintf
man snprintf/fprintf
#include <stdio.h>
int printf(const char *format, ...);
int fprintf(FILE *stream, const char *format, ...);
int sprintf(char *str, const char *format, ...);
int snprintf(char *str, size_t size, const char *format, ...);
int main()
{
FILE *fp = fopen(LOG, "w");
if(fp == NULL)
{
perror("fopen"); //fopen: XXXX
return 1;
}
const char *msg = "aaa\n";
int cnt = 5;
while(cnt)
{
fprintf(fp, "%s", msg);
cnt--;
}
fclose(fp);
return 0;
}
int main()
{
FILE *fp = fopen(LOG, "w");
if(fp == NULL)
{
perror("fopen"); //fopen: XXXX
return 1;
}
const char *msg = "aaa\n";
int cnt = 5;
while(cnt)
{
char buffer[256];
snprintf(buffer, sizeof(buffer), "%s:%d:whb\n", msg, cnt);
fputs(buffer, fp);
--cnt;
}
fclose(fp);
return 0;
}
stdin/stdout/stderr
man stdin/stdout/stderr|
#include <stdio.h>
extern FILE *stdin;
extern FILE *stdout;
extern FILE *stderr;
C默认会打开三个输入输出流,分别是标准输入(stdin)、标准输出(stdout)、标准错误(stderr) —— 语言层是FILE结构体指针
仔细观察发现,这三个流的类型都是FILE*, fopen返回值类型,FILE结构体指针 —— 文件在语言层的表现
C++默认会打开三个输入输出流,分别是cin,cout,cerr —— 语言层是类对象
标准输入(stdin)——设备文件——键盘文件
标准输出(stdout)——设备文件——显示器文件
标准错误(stderr)——设备文件——显示器文件
可以通过C接口,直接对stdin、stdout、stderr进行读写。
int main()
{
FILE *fp = fopen(LOG, "w");
if(fp == NULL)
{
perror("fopen"); //fopen: XXXX
return 1;
}
const char *msg = "aaa\n";
int cnt = 5;
while(cnt)
{
fprintf(stdout, "%s", msg);//linux下一切皆文件,显示器文件
cnt--;
}
fclose(fp);
return 0;
}
int main()
{
//因为Linux下一切皆文件,所以,向显示器打印,本质就是向文件中写入, 如何理解?TODO
//C
printf("hello printf->stdout\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stderr, "hello fprintf->stderr\n");
//C++
std::cout << "hello cout -> cout" << std::endl;
std::cerr << "hello cerr -> cerr" << std::endl;
}
//结果
[admin1@VM-4-17-centos demo]$ ./test
hello printf->stdout
hello fprintf->stdout
hello fprintf->stderr
hello cout -> cout
hello cerr -> cerr
[admin1@VM-4-17-centos demo]$ ./test > log.txt
hello fprintf->stderr
hello cerr -> cerr
标准输入和标准错误都会向显示器打印,但其实是不一样的。
标志位
我们一般用多个参数来同时传多个标志位。
系统一般通过位图(32个比特位)来传递多个标志位。
#include <stdio.h>
#define ONE 0x1
#define TWO 0x2
#define THREE 0x4
#define FOUR 0x8
#define FIVE 0x10
// 0000 0000 0000 0000 0000 0000 0000 0000
void Print(int flags)
{
if(flags & ONE) printf("hello 1\n"); //充当不同的行为
if(flags & TWO) printf("hello 2\n");
if(flags & THREE) printf("hello 3\n");
if(flags & FOUR) printf("hello 4\n");
if(flags & FIVE) printf("hello 5\n");
}
int main()
{
printf("--------------------------\n");
Print(ONE);
printf("--------------------------\n");
Print(TWO);
printf("--------------------------\n");
Print(FOUR);
printf("--------------------------\n");
Print(ONE|TWO);
printf("--------------------------\n");
Print(ONE|TWO|THREE);
printf("--------------------------\n");
Print(ONE|TWO|THREE|FOUR|FIVE);
printf("--------------------------\n");
return 0;
}
系统调用IO接口
open/close
man 2 open/close
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
// pathname: 要打开或创建的目标文件
// flags: 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags。
// 参数:
// O_RDONLY: 只读打开
// O_WRONLY: 只写打开
// O_RDWR : 读,写打开
// 这三个常量,必须指定一个且只能指定一个
// O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限
// O_APPEND: 追加写
// 返回值:
// 成功:新打开的文件描述符
// 失败:-1
#include <unistd.h>
int close(int fd);
-
open 函数具体使用哪个,和具体应用场景相关,如目标文件不存在,需要open创建,则第三个参数表示创建文件的默认权限,否则,使用两个参数的open。
-
O_RDONLY、O_WRONLY、O_RDWR……这些都是系统定义的宏,这些参数只占一个int整形中的一个比特位。
umask
man 2 umask
#include <sys/types.h>
#include <sys/stat.h>
mode_t umask(mode_t mask);
指定在建立文件时预设的权限掩码。
write/read
man 2 write/read
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
ssize_t read(int fd, void *buf, size_t count);
lseek
man 2 lseek
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
// 第一个参数是文件描述符;第二个参数是偏移量,int型的数,正数是向后偏移,负数向前偏移;第三个参数是有三个选项:
// 1.SEEK_SET:将文件指针偏移到传入字节数处(文件头开始偏移)
// 2.SEEK_CUR:将文件指针偏移到当前位置加上传入字节数处;((当前位置开始偏移)
// 3.SEEK_END:将文件指针偏移到文件末尾加上传入字节数处(作为拓展作用,必须再执行一次写操作)
#include <stdio.h>
#include <unistd.h>//是close, write这些接口的头文件
#include <string.h>
#include <fcntl.h>//是 O_CREAT 这些宏的头文件
#include <sys/stat.h>//umask接口头文件
int main()
{
//将当前进程的默认文件创建权限掩码设置为0--- 并不影响系统的掩码,仅在当前进程内生效
umask(0);
//int open(const char *pathname, int flags, mode_t mode);
int fd = open("./bite", O_CREAT|O_RDWR, 0664);
if(fd < 0) {
perror("open error");
return -1;
}
char *data = "i like linux!\n";
//ssize_t write(int fd, const void *buf, size_t count);
ssize_t ret = write(fd, data, strlen(data));
if (ret < 0) {
perror("write error");
return -1;
}
//off_t lseek(int fd, off_t offset, int whence);
lseek(fd, 0, SEEK_SET);
char buf[1024] = {0};
//ssize_t read(int fd, void *buf, size_t count);
ret = read(fd, buf, 1023);
if (ret < 0) {
perror("read error");
return -1;
}else if (ret == 0) {
printf("end of file!\n");
return -1;
}
printf("%s", buf);
close(fd);
return 0;
}
库函数IO操作与系统调用IO操作比较
//语言方案
#include <stdio.h>
#define LOG "log.txt"
int main()
{
// w: 默认写方式打开文件,如果文件不存在,就创建它
// 1. 默认如果只是打开,文件内容会自动被清空
// 2. 同时,每次进行写入的时候,都会从最开始进行写入
//FILE *fp = fopen(LOG, "w");
// a: 不会清空文件,而是每一次写入都是从文件结尾写入的, 追加
// FILE *fp = fopen(LOG, "a");
FILE *fp = fopen(LOG, "r");
if(fp == NULL)
{
perror("fopen"); //fopen: XXXX
return 1;
}
//正常进行文件操作
while(1)
{
char line[128];
if(fgets(line, sizeof(line), fp) == NULL) break;
else printf("%s", line);
}
const char *msg = "aaa\n";
int cnt = 5;
while(cnt)
{
//fputs(msg, fp);
char buffer[256];
snprintf(buffer, sizeof(buffer), "%s:%d:whb\n", msg, cnt);
fputs(buffer, fp);
//printf("%s", buffer);
//fprintf(fp, "%s: %d: whb\n", msg, cnt);
//fprintf(stdout, "%s: %d: whb\n", msg, cnt); // Linux一切皆文件,stdout也对应一个文件, 显示器文件
//fputs(msg, fp);
cnt--;
}
fclose(fp);
return 0;
}
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define LOG "log.txt"
int main()
{
//fopen(LOG, "w");
//fopen(LOG, "a");
// 系统方案
umask(0);
//int fd = open(LOG, O_WRONLY | O_CREAT, 0666);
//O_CREAT|O_WRONLY: 默认不会对原始文件内容做清空
//int fd = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
//O_TRUNC:默认会对原始文件做清空
//int fd = open(LOG, O_WRONLY | O_CREAT | O_APPEND, 0666);
//O_APPEND:默认追加写
int fd = open(LOG, O_RDONLY);
//O_RDONLY:默认只读文件
if(fd == -1)
{
printf("fd: %d, errno: %d, errstring: %s\n", fd, errno, strerror(errno));
}
else printf("fd: %d, errno: %d, errstring: %s\n", fd, errno, strerror(errno));
char buffer[1024];
// 这里我们无法做到按行读取,我们是整体读取的。
ssize_t n = read(fd, buffer, sizeof(buffer)-1); //使用系统接口来进行IO的时候,一定要注意,\0问题
if(n > 0)
{
buffer[n] = '\0';
printf("%s\n", buffer);
}
// const char *msg = "bbb";
// int cnt = 1;
// while(cnt)
// {
// char line[128];
// snprintf(line, sizeof(line), "%s, %d\n", msg, cnt);
// //如果格式化后的字符串长度超过了 size-1,则 snprintf() 只会写入 size-1 个字符,并在字符串
// //的末尾添加一个空字符(\0)以表示字符串的结束。
// write(fd, line, strlen(line)); //这里的strlen不要+1, \0是C语言的规定,不是文件的规定!
// cnt--;
// }
close(fd);
return 0;
}
库函数与系统调用
任何一种编程语言的文件操作相关的函数(库函数)底层都会调用系统调用接口(open、close、write、read,这些在Linux系统下有,但这些接口不具备可移植性)。语言上相关文件操作的库函数兼容自身语法特征,系统调用使用成本较高,而且不具备可移植性。
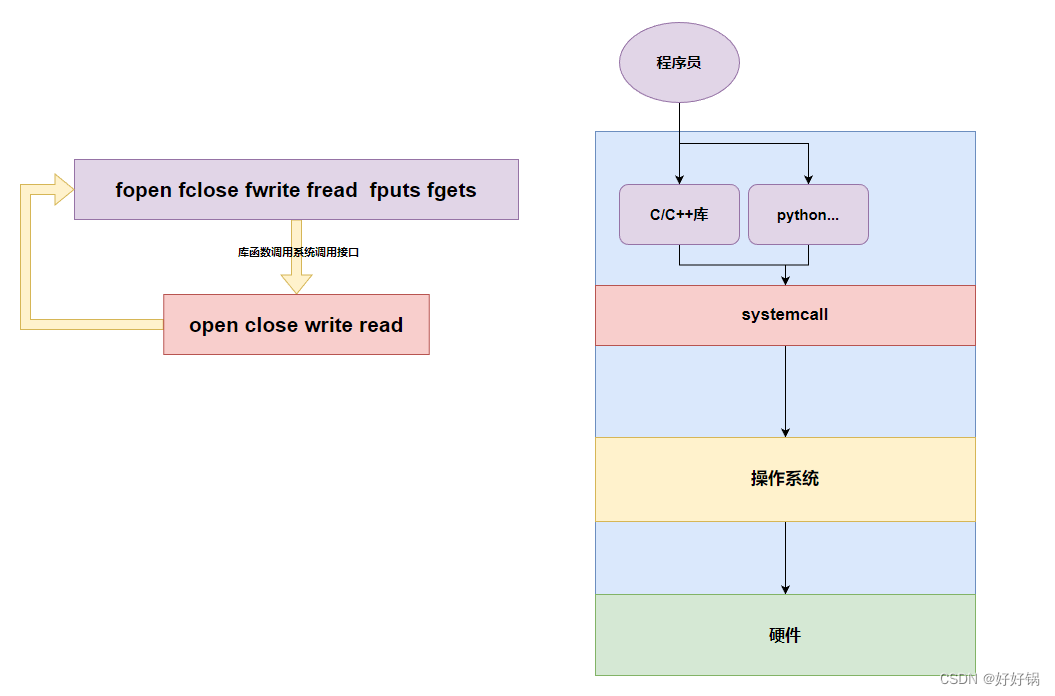
只要是访问到硬件或操作系统内的资源绝对要调用系统调用(自上而下)。
文件描述符
-
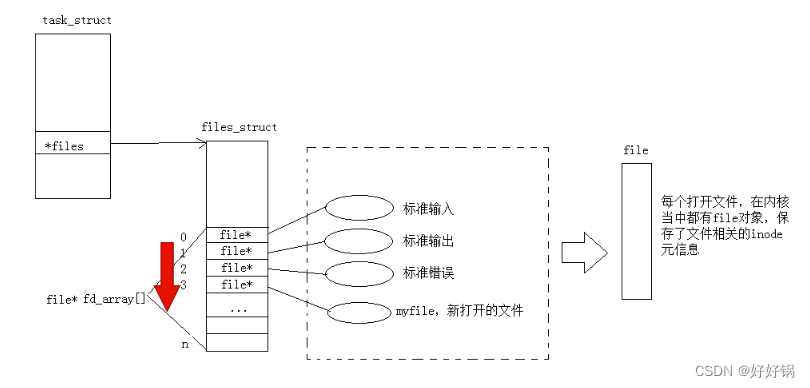
文件描述符(open对应的返回值)本质就是:数组下标。用户层看到的fd本质是系统中维护进程和文件对应关系的数组的下标。
-
所谓的默认打开文件,标准输入,标准输出,标准错误,其实是由底层系统支持的,默认一个进程在运行的时候,就打开了0,1,2。
-
对于进程来讲,对所有的文件进行操作,统一使用一套接口(一组函数指针),因此在OS看来一切皆文件。
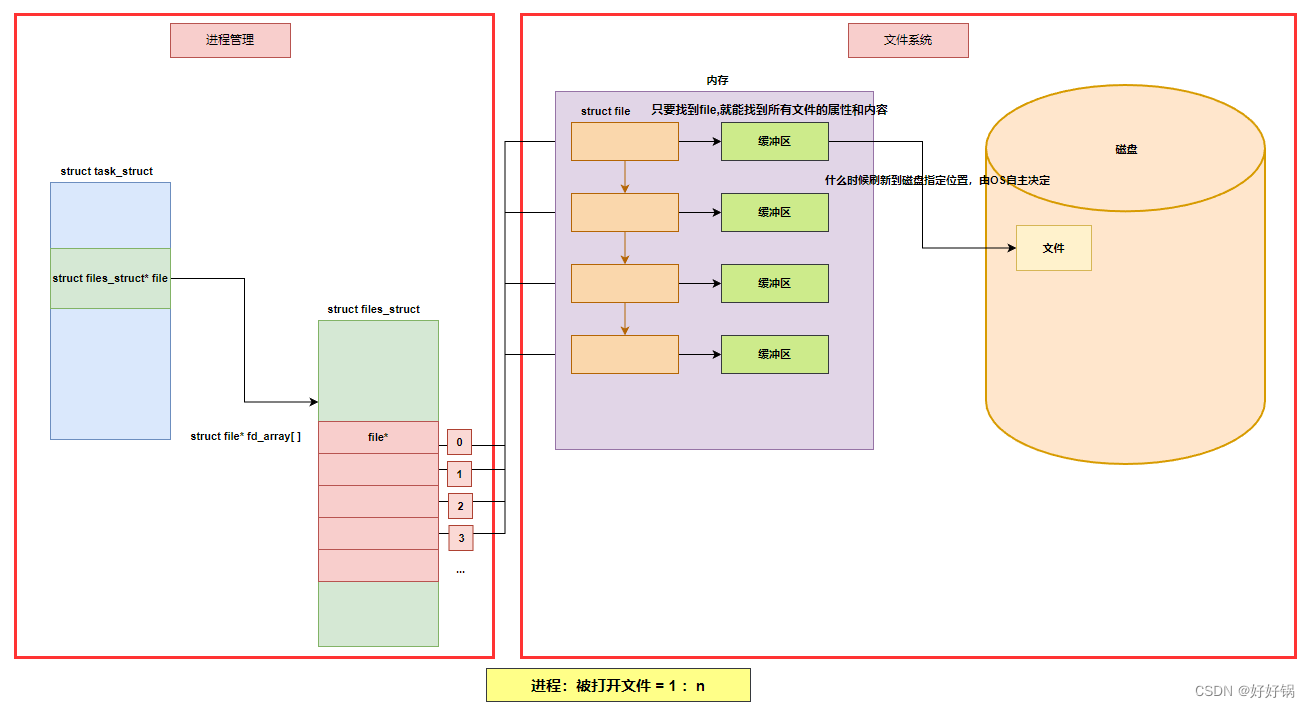
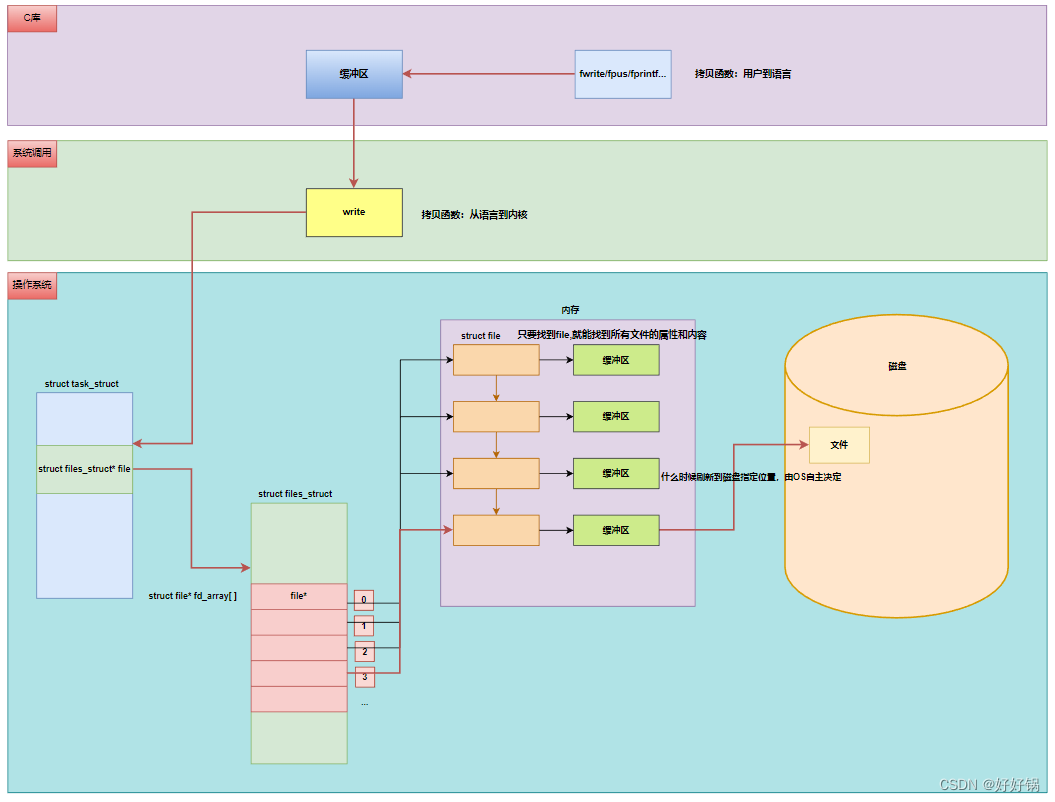
文件描述符就是从0开始的小整数。当打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针files_struct*, 指向一张表files_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。只要拿着文件描述符,就可以找到对应的文件。
【补充】:
-
所有文件,如果要被使用时,首先必须被打开。
-
一个进程可以打开多个文件,系统中被打开的文件一定有多个,多个被打开的文件,一定要被操作系统管理起来的。
-
打开文件的过程:先在fd_array数组中找一个最小的没有被使用的数组下标位置,然后把新open出的文件的结构体地址填入到数组中去,对应该地址的下标返回给对应的进程。
系统调用read/write函数,本质上是拷贝函数,用户空间和内核空间进行数据的来回拷贝!
linux下一切皆文件
所有的外设硬件本质的核心操作是读或写,不同的硬件对应的读写方式不一样。在OS看来,这些file由链表链接管理,想对哪个硬件进行读写只需打开该硬件对应的读写方式,因此在linux看来一切皆文件。

我们使用OS的本质:都是通过进程的方式进行文件的访问,即I/O外设都会以文件的方式来访问。
FILE 结构体
typedef struct _IO_FILE FILE; 在/usr/include/stdio.h
在/usr/include/libio.h
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; //封装的文件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};
FILE是C语言库提供的结构体,与系统内核的struct file是上下层的关系。
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的,所以C库当中的FILE结构体内部,必定封装了fd。
标准输入、标准输出、标准错误在对应的文件描述符为0,1,2,对应C语言层上的是stdin、stdout、stderr结构体对象。
int main()
{
printf("%d\n", stdin->_fileno);
printf("%d\n", stdout->_fileno);
printf("%d\n", stderr->_fileno);
FILE *fp = fopen(LOG, "w");
printf("%d\n", fp->_fileno);
}
//结果
[admin1@VM-4-17-centos file]$ ./myfile
0
1
2
3
重定向
文件描述符的分配规则
int main()
{
fclose(stdin);
//close(0);
int fd1 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd2 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd3 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd4 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd5 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd6 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("%d\n", fd1);
printf("%d\n", fd2);
printf("%d\n", fd3);
printf("%d\n", fd4);
printf("%d\n", fd5);
printf("%d\n", fd6);
}
//结果
[admin1@VM-4-17-centos file]$ ./myfile
0
3
4
5
6
7
在文件描述符中,最小的、没有被使用的数组元素分配给新文件。
深入理解重定向
输出重定向
int main()
{
close(1);
int fd = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("you can see me !\n"); //stdout -> 1
printf("you can see me !\n");
printf("you can see me !\n");
printf("you can see me !\n");
printf("you can see me !\n");
printf("you can see me !\n");
printf("you can see me !\n");
}
//结果
[admin1@VM-4-17-centos file]$ ./myfile
[admin1@VM-4-17-centos file]$ cat log.txt
you can see me !
you can see me !
you can see me !
you can see me !
you can see me !
you can see me !
you can see me !
本来应该写入到stdout的内容,现在写入到文件中。
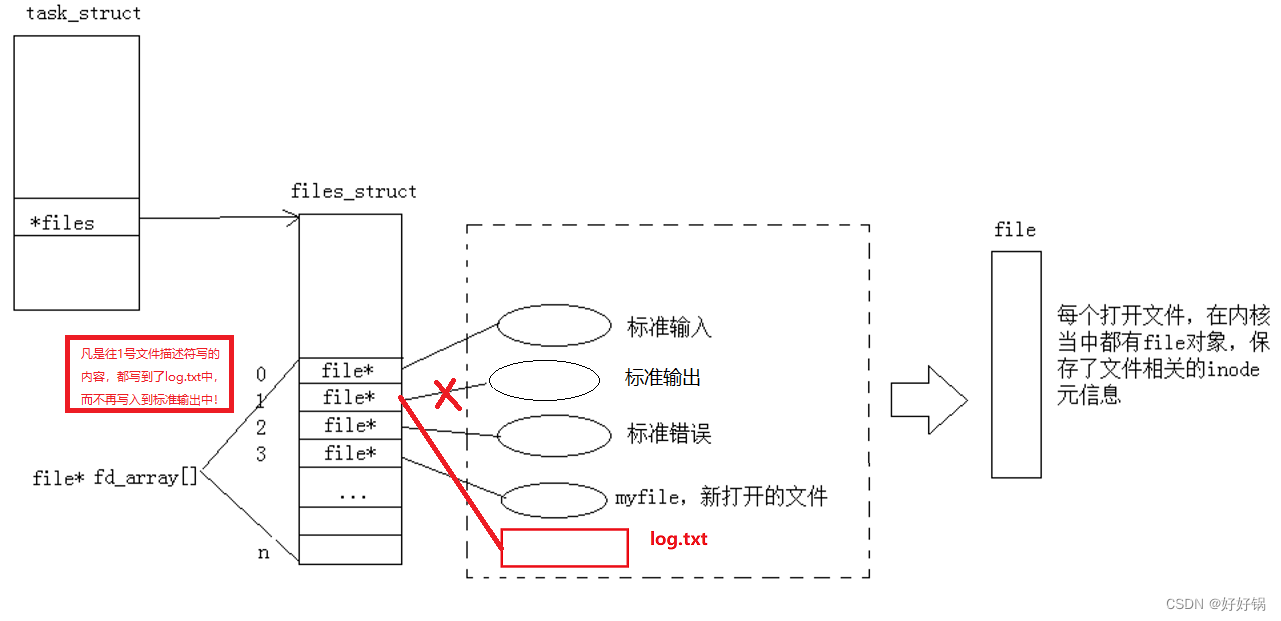
输出重定向:在上层无法感知的情况下,在os内部,更改进程对应的文件描述符表中的特定下标(stdout)的指向!
int main()
{
printf("hello printf->stdout\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stderr, "hello fprintf->stderr\n");
//C++
std::cout << "hello cout -> cout" << std::endl;
std::cerr << "hello cerr -> cerr" << std::endl;
}
//结果
[admin1@VM-4-17-centos demo]$ ./test > log.txt
hello fprintf->stderr
hello cerr -> cerr
[admin1@VM-4-17-centos demo]$ cat log.txt
hello printf->stdout
hello fprintf->stdout
hello cout -> cout
stdout、cout→1,他们都是向1号文件描述符对应的文件打印;stderr、cerr→2,他们都是向2号文件描述符对应的文件打印。
int main()
{
close(1);
open(LOG_NORMAL, O_WRONLY | O_CREAT | O_APPEND, 0666);
close(2);
open(LOG_ERROR, O_WRONLY | O_CREAT | O_APPEND, 0666);
printf("hello printf->stdout\n");
printf("hello printf->stdout\n");
printf("hello printf->stdout\n");
printf("hello printf->stdout\n");
perror("hello perror->stderr\n");
perror("hello perror->stderr\n");
perror("hello perror->stderr\n");
perror("hello perror->stderr\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stderr, "hello fprintf->stderr\n");
fprintf(stderr, "hello fprintf->stderr\n");
fprintf(stderr, "hello fprintf->stderr\n");
fprintf(stderr, "hello fprintf->stderr\n");
fprintf(stderr, "hello fprintf->stderr\n");
fprintf(stderr, "hello fprintf->stderr\n");
fprintf(stderr, "hello fprintf->stderr\n");
fprintf(stderr, "hello fprintf->stderr\n");
}
//结果
[admin1@VM-4-17-centos file]$ cat logNormal.txt
hello printf->stdout
hello printf->stdout
hello printf->stdout
hello printf->stdout
hello fprintf->stdout
hello fprintf->stdout
hello fprintf->stdout
hello fprintf->stdout
hello fprintf->stdout
hello fprintf->stdout
hello fprintf->stdout
hello fprintf->stdout
[admin1@VM-4-17-centos file]$ cat logError.txt
hello fprintf->stderr
hello fprintf->stderr
hello fprintf->stderr
hello fprintf->stderr
hello fprintf->stderr
hello fprintf->stderr
hello fprintf->stderr
hello fprintf->stderr
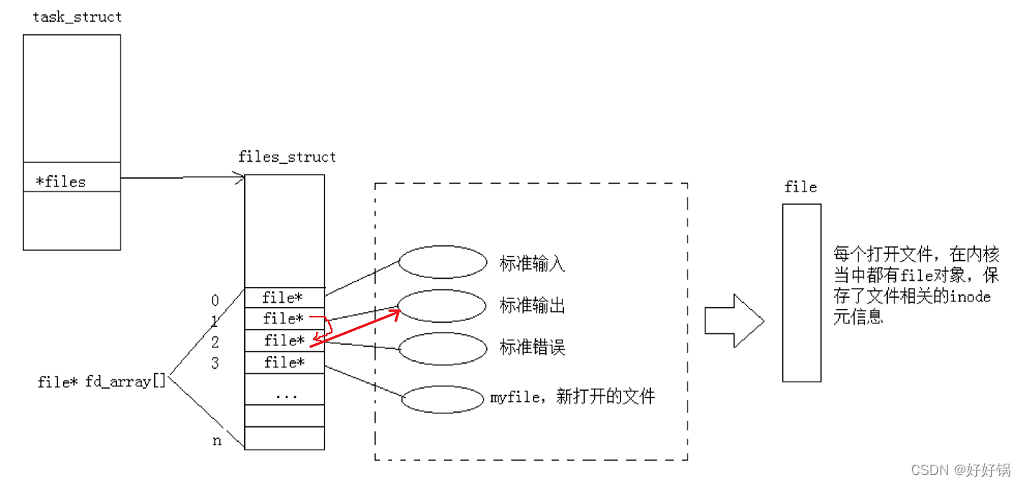
printf、stdout都是向文件标识符1的文件输出;perror、stderr都是向文件标识符2的文件输出。
int main()
{
//c
printf("hello printf->stdout\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stderr, "hello fprintf->stderr\n");
//C++
std::cout << "hello cout -> cout" << std::endl;
std::cerr << "hello cerr -> cerr" << std::endl;
}
//结果
[admin1@VM-4-17-centos demo]$ ./test 1>log.txt 2>err.txt
[admin1@VM-4-17-centos demo]$ cat log.txt
hello printf->stdout
hello fprintf->stdout
hello cout -> cout
[admin1@VM-4-17-centos demo]$ cat err.txt
hello fprintf->stderr
hello cerr -> cerr
将1号文件描述符的文件内容重定向到log.txt,将2号文件描述符的内容重定向到err.txt。
int main()
{
//C
printf("hello printf->stdout\n");
fprintf(stdout, "hello fprintf->stdout\n");
fprintf(stderr, "hello fprintf->stderr\n");
//C++
std::cout << "hello cout -> cout" << std::endl;
std::cerr << "hello cerr -> cerr" << std::endl;
}
//结果
[admin1@VM-4-17-centos demo]$ ./test > log.txt 2>&1
[admin1@VM-4-17-centos demo]$ cat log.txt
hello fprintf->stderr
hello printf->stdout
hello fprintf->stdout
hello cout -> cout
hello cerr -> cerr
输入重定向
int main()
{
close(0);
int fd = open(LOG, O_RDONLY); //fd = 0;
int a, b;
scanf("%d %d", &a, &b);
printf("a = %d, b = %d\n", a, b);
}
//结果
[admin1@VM-4-17-centos file]$ ./myfile
a = 123, b = 456
输入重定向:在上层无法感知的情况下,在os内部,更改进程对应的文件描述符表中的特定下标(stdin)的指向!
追加重定向
int main()
{
close(1);
int fd = open(LOG, O_WRONLY | O_CREAT | O_APPEND, 0666);
printf("you can see me !\n"); //stdout -> 1
printf("you can see me !\n");
printf("you can see me !\n");
printf("you can see me !\n");
printf("you can see me !\n");
printf("you can see me !\n");
printf("you can see me !\n");
}
追加重定向:比起输出重定向对文件是追加内容,本质上是改变了文件描述符表中的特定下标的指向!
dup2
man dup2
#include <unistd.h>
int dup2(int oldfd, int newfd)
将newfd文件标识符指向oldfd文件标识符指向的文件。
int main()
{
int fd = open(LOG_NORMAL, O_CREAT|O_WRONLY|O_APPEND, 0666);
if(fd < 0)
{
perror("open");
return 1;
}
dup2(fd, 1);
printf("hello world, hello bit!\n");
close(fd);
}
//结果
[admin1@VM-4-17-centos file]$ > logNormal.txt //清空logNormal.txt
[admin1@VM-4-17-centos file]$ ./myfile
[admin1@VM-4-17-centos file]$ cat logNormal.txt
hello world, hello bit!

缓冲区
int main()
{
//C库
fprintf(stdout, "hello fprintf\n");
//系统调用
const char *msg = "hello write\n";
write(1, msg, strlen(msg)); //+1?
fork(); //????
return 0;
}
//结果
[admin1@VM-4-17-centos file]$ ./myfile
hello fprintf
hello write
[admin1@VM-4-17-centos file]$ ./myfile > log.txt
[admin1@VM-4-17-centos file]$ cat log.txt
hello write
hello fprintf
hello fprintf
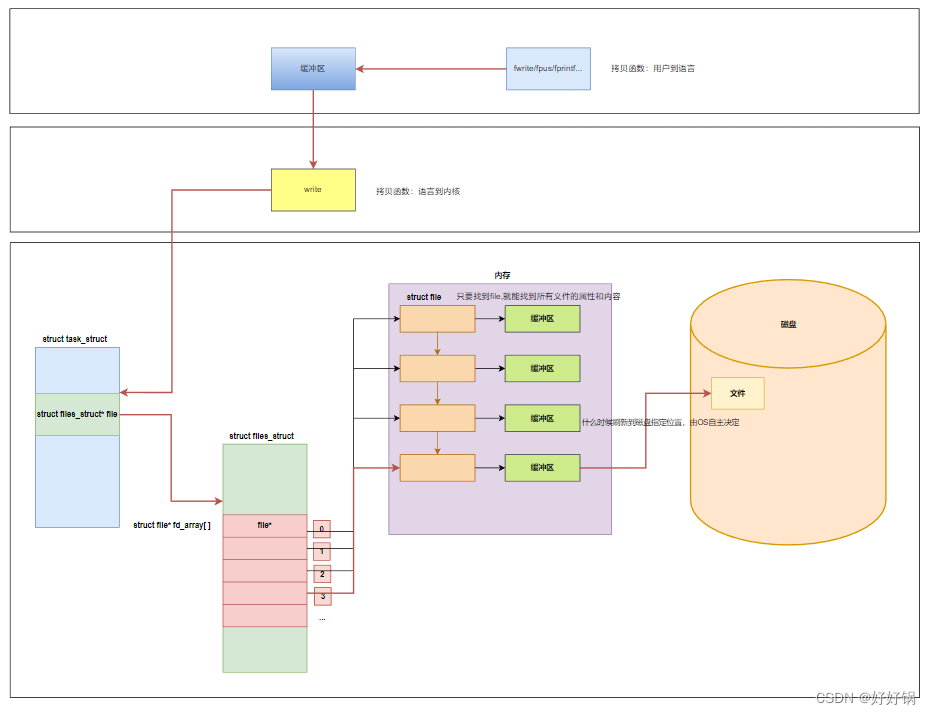
printf fputs等 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区,都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区。 printf fprintf 是库函数, write 是系统调用,库函数在系统调用的“上层”, 是对系统调用的“封装”,但是 write 有内核级缓冲区,而 printf fwrite fputs等缓冲区是用户级缓冲区,由C标准库提供。
除了OS内核有自己的缓冲区外,C库也有缓冲区。缓冲区是为了减少系统调用的次数,缓冲区就在FILE结构体中。
C库缓冲区刷新策略
C库会结合一定的刷新策略,将缓冲区的数据写入OS(write/read):
-
无缓冲(直接刷新)。
-
行缓冲(遇到\n刷新)。
-
全缓冲(写满了刷新)。
显示器采用行缓冲,普通文件采用全缓冲。
上面的fprintf重定向了普通文件,普通文件是全缓冲;fork后产生了两个进程即两个缓冲区,最后fprintf刷新出两个。
自主封装
fsync
man fsync
#include <unistd.h>
int fsync(int fd);
将文件内核缓冲区的数据刷新到磁盘。
语言层封装
#pragma once
#include <stdio.h>
#define NUM 1024
#define BUFF_NONE 0x1
#define BUFF_LINE 0x2
#define BUFF_ALL 0x4
typedef struct _MY_FILE
{
int fd;//文件描述符
int flags; // flush method
char outputbuffer[NUM];
int current;
} MY_FILE;
MY_FILE *my_fopen(const char *path, const char *mode);
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb,MY_FILE *stream);
int my_fclose(MY_FILE *fp);
int my_fflush(MY_FILE *fp);
#include "mystdio.h"
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <malloc.h>
#include <unistd.h>
#include <assert.h>
// fopen("/a/b/c.txt", "a");
// fopen("/a/b/c.txt", "r");
// fopen("/a/b/c.txt", "w");
MY_FILE *my_fopen(const char *path, const char *mode)
{
//1. 识别标志位
int flag = 0;
if(strcmp(mode, "r") == 0) flag |= O_RDONLY;
else if(strcmp(mode, "w") == 0) flag |= (O_CREAT | O_WRONLY | O_TRUNC);
else if(strcmp(mode, "a") == 0) flag |= (O_CREAT | O_WRONLY | O_APPEND);
else {
//other operator...
//"r+", "w+", "a+"
}
//2. 尝试打开文件
mode_t m = 0666;
int fd = 0;
if(flag & O_CREAT) fd = open(path, flag, m);
else fd = open(path, flag);
if(fd < 0) return NULL;
//3. 给用户返回MY_FILE对象,需要先进行构建
MY_FILE *mf = (MY_FILE*)malloc(sizeof(MY_FILE));
if(mf == NULL)
{
close(fd);
return NULL;
}
//4. 初始化MY_FILE对象
mf->fd = fd;
mf->flags = 0;
mf->flags |= BUFF_LINE;
memset(mf->outputbuffer, '\0',sizeof(mf->outputbuffer));
mf->current = 0;
//mf->outputbuffer[0] = 0; //初始化缓冲区
//5. 返回打开的文件
return mf;
}
int my_fflush(MY_FILE *fp)
{
assert(fp);
//将用户缓冲区中的数据,通过系统调用接口,冲刷给OS
write(fp->fd, fp->outputbuffer, fp->current);
fp->current = 0;
fsync(fp->fd);
return 0;
}
// 我们今天返回的就是一次实际写入的字节数,我就不返回个数了
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb,MY_FILE *stream)
{
// 1. 缓冲区如果已经满了,就直接写入
if(stream->current == NUM) my_fflush(stream);
// 2. 根据缓冲区剩余情况,进行数据拷贝即可
size_t user_size = size * nmemb;
size_t my_size = NUM - stream->current; // 100 - 10 = 90
size_t writen = 0;
if(my_size >= user_size)
{
memcpy(stream->outputbuffer+stream->current, ptr, user_size);
//3. 更新计数器字段
stream->current += user_size;
writen = user_size;
}
else
{
memcpy(stream->outputbuffer+stream->current, ptr, my_size);
//3. 更新计数器字段
stream->current += my_size;
writen = my_size;
}
// 4. 开始计划刷新, 他们高效体现在哪里 -- TODO
// 不发生刷新的本质,不进行写入,就是不进行IO,不进行调用系统调用,所以my_fwrite函数调用会非常快,数据会暂时保存在缓冲区中
// 可以在缓冲区中积压多份数据,统一进行刷新写入,本质:就是一次IO可以IO更多的数据,提高IO效率
if(stream->flags & BUFF_ALL)
{//全刷新
if(stream->current == NUM) my_fflush(stream);
}
else if(stream->flags & BUFF_LINE)
{//行刷新
if(stream->outputbuffer[stream->current-1] == '\n') my_fflush(stream);
}
else
{
//TODO
}
return writen;
}
int my_fclose(MY_FILE *fp)
{
assert(fp);
//1. 冲刷缓冲区
if(fp->current > 0) my_fflush(fp);
//2. 关闭文件
close(fp->fd);
//3. 释放堆空间
free(fp);
//4. 指针置NULL -- 可以设置
fp = NULL;
return 0;
}
//int my_scanf(); stdin->buffer -> 对buffer内容进行格式化,写到对应的变量中
//int a,b; scanf("%d %d", &a, &b);read(0, stdin->buffer, num); -> 123 456 -> 输入的本质: 输入的也是字符
//扫描字符串,碰到空格,字符串分割成为两个子串,*ap = atoi(str1); *bp = atoi(str2);
//int my_printf(const char *format, ...)
//{
// //1. 先获取对应的变量 a
// //2. 定义缓冲区,对a转成字符串
// //2.1 fwrite(stdout, str);
// //3. 将字符串拷贝的stdout->buffer,即可
// //4. 结合刷新策略显示即可
//}
//
#include "mystdio.h"
#include <string.h>
#include <unistd.h>
#define MYFILE "log.txt"
int main()
{
int a = 123456; //是一个整数
printf("%d\n", a); // 123456 打印成为了一个字符串,数据格式转换的问题,谁做的?在哪里做的呢??
// MY_FILE *fp = my_fopen(MYFILE, "w");
// if(fp == NULL) return 1;
// const char *str = "hello my fwrite";
// int cnt = 500;
// //操作文件
// while(cnt)
// {
// char buffer[1024];
// snprintf(buffer, sizeof(buffer), "%s:%d", str, cnt--);
// //snprintf(buffer, sizeof(buffer), "%s:%d\n", str, cnt--);
// size_t size = my_fwrite(buffer, strlen(buffer), 1, fp);
// sleep(1);
// printf("当前成功写入: %lu个字节\n", size);
// //my_fflush(fp);
// if(cnt % 5 == 0)
// my_fwrite("\n", strlen("\n"), 1, fp);
// }
// my_fclose(fp);
return 0;
}
计算机高级语言中的流或缓冲区概念都是在语言层上的。
存储文件
文件:打开的文件、普通未打开的文件。
打开的文件:属性与操作方法的表现就是struct file{} 属于内存级文件。
普通未打开的文件:磁盘上面未被加载到内存的。
文件系统功能:将上述的这些文件管理起来。
预备知识
-
如果文件没有被打开,那么文件一定存储在磁盘等外设中。
-
如何合理存储文件决定了快速定位、读取和写入。
磁盘的物理结构
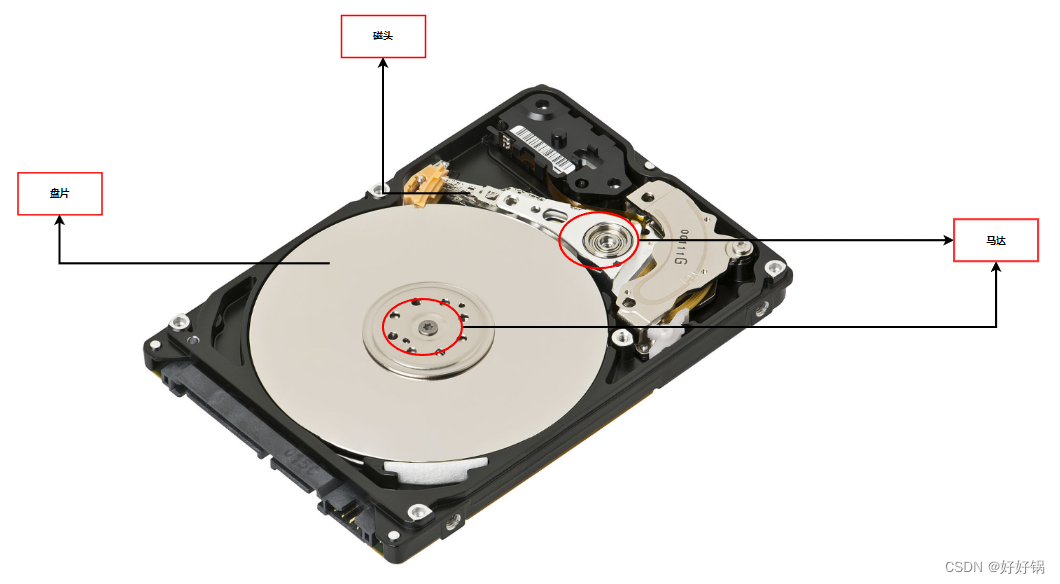
磁盘是我们计算机上唯一的一个机械设备!同时它也是外设!
-
盘片是两面的,机械磁盘有一摞盘片。
-
每个盘面一个磁头,磁头与盘面是没有挨着的。
-
盘面有许多个磁极,用磁极来表示0/1信号。
-
磁盘由伺服电路接收信号和控制磁盘转动读写。
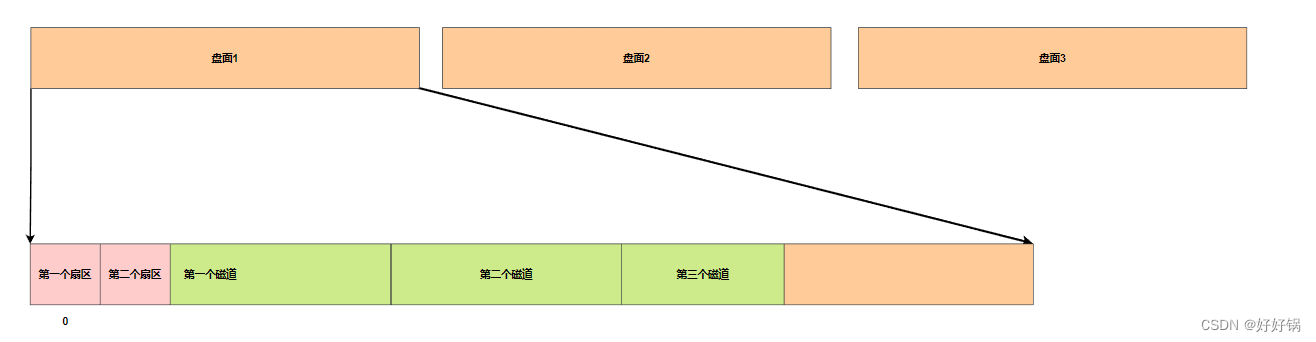
磁盘的具体物理存储结构

-
磁盘中存储的基本单元:扇区,一般512字节。
-
同半径的所有的扇区:磁道。
-
同半径的磁道构成一个面:柱面。
CHS定位法:定位扇区要先确定磁头(head)在哪个面上,然后找磁道(cylinder),最后确定扇区(sector)。所以我们可以用CHS定位任意一个扇区,将文件从硬件角度进行读取或写入!
一个普通文件(属性+数据),数据就是01序列,就是占用一个或多个扇区来进行存储!
逻辑抽象
CHS是硬件定位的一个地址,OS是软件,两者要做好解耦工作!
OS进行IO基本单位是4KB(可以调整),而磁盘外设的IO基本单位是512字节,所以OS要有一套新的地址进行块级别的访问!
我们可以将磁盘想象成磁带(线性结构),将磁盘看成一个线性空间(数组),类型为扇区的数组、数组个数为10亿多。

这样划分就不用让OS读取数据时在哪个盘面、哪个磁道、哪个扇区找了,OS与磁盘映射关系可以通过磁盘驱动来完成,这样也就做到强解耦性。无论换机械硬盘还是固态硬盘,OS都不用改变读取磁盘数据的数据结构,只需改变磁盘的驱动程序即可。
-
初步完成一个从物理逻辑到线性逻辑的抽象过程,定位一个扇区就只需要一个数组下标。
-
其中OS是以4KB为单位进行IO的,所以一个OS级别的文件块要包括8个扇区,但在OS角度它不关心扇区。
-
计算机常规的访问方式:起始地址+偏移量。只需要知道数据块(连续的扇区)的起始地址(第一个扇区的地址)+4KB(块的类型) 我们把数据块看作一种类型!

所以块地址本质就是数组的一个下标N,表示一个块可以用线性下标N的方式。OS中逻辑块地址就是N,操作系统读取磁盘数据时的下标——LBA。
OS要管理磁盘,就是将磁盘看作一个大数组,对磁盘的管理变成了对数组的管理!
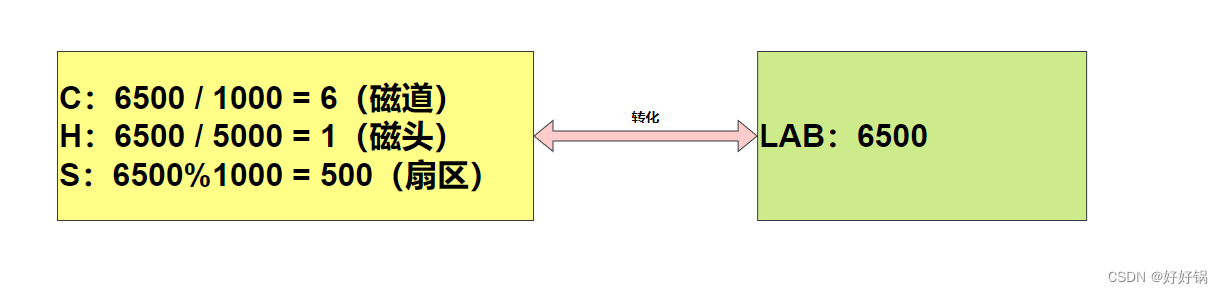
【LBA地址与CHA地址的转化】:
磁盘文件系统

Linux ext2文件系统,上图为磁盘文件系统图(内核内存映像肯定有所不同),磁盘是典型的块设备,硬盘分区被划分为一个个的block。一个block的大小是由格式化的时候确定的,并且不可以更改。例如mke2fs的-b选项可以设定block大小为1024、2048或4096字节。而启动块(Boot Block)的大小是确定的。
-
超级块(Super Block):文件系统的所有属性信息(文件系统的类型、分组的情况),SB在各个分组里都可能会存在,而且统一更新,为了防止SB区域坏掉,如果出现故障,整个分区不可以被使用,相当于做好备份。
-
GDT(Group Descriptor Table):块组描述符,描述块组属性信息。
-
块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。每一个bit表示一个datablock是否空闲可用。
-
inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。
-
i节点表(inode Tabale):一个文件的所有属性会保存在一个inode节点(128字节),一个分区内会存在大量的文件即会存在大量的inode节点,所以一个group用inode Table来专门保存该group内的所有文件的inode节点。每一个inode节点都会有自己的inode编号!inode编号也属于对应文件的属性id。
-
数据区(Data blocks):文件的内容是变化的。我们是用数据块来进行文件内容的保存的,所有一个文件要用到1~n个数据块。
inode
struct inode
{
int number;
//...
int block[NUM];
}
linux查找一个文件是根据inode编号读取对应的inode,其中inode属性中有对应的数据块号,就可以找数据区中对应的数据块读取内容。即一个文件的inode属性与文件的数据块是有映射关系的。通过inode可实现文件的逻辑结构和物理结构的转换。
ls -i -l
//查看文件的inode编号
【indeo编号 vs 文件名】:
Linux系统只认inode编号,文件的inode属性中,并不存在文件名,文件名是给用户用的。
用户是通过路径定位的(目录)来定位一个文件,而操作系统是通过目录的Data blocks来确定文件名和inode的映射关系。
【重新认识目录】:
目录是文件,目录也有inode,也有数据块,数据块里面保存的是文件名和文件inode编号对应的映射关系,而且在目录中文件名和inode互为key值。
【文件的增删查改】:
查看:
-
先在当前目录下找到log.txt的inode编号。
-
一个目录是一个文件,也一定隶属于一个分区,在该分区中找到分组,在该分组中inode table中找到文件的inode节点。
-
通过inode和对应的datablock的映射关系,找到文件的数据块,并加载到OS,并完成显示到显示器!
删除:
-
根据文件名找到inode编号。
-
inode number 结合 inode 属性中的映射关系,设置 block bitmap 对应的比特位,置0即可。
-
inode number 设置 inode bitmap 对应的比特设置为0。
创建:
-
在当前目录所处的分组中,扫描 inode bitmap 分配一个 inode number。
-
将文件属性填充到对应的inode节点当中,并且在目录的数据块中追加文件名和inode number的映射关系。
-
扫描 Block Bitmap 分配一个或多个数据块,将数据块编号填入inode里的数组里。
-
将数据写入inode对应的数据块里。
【补充细节】:
-
如果文件被误删了,不会要清空该文件占据的所有的空间数据,只需将该文件的inode和对应的数据块无效化即可,文件对应inode和Block位图中的数字1设置为0,并将该文件所对应的目录中的数据块的关于该文件内容清空即可。
-
Linux下属性和内容是分离的,属性inode保存的(在同一块块组inode编号是不同的,但是跨组的inode编号可能相同),内容Data blocks保存的。
-
inode 确定分组(每个组里有inode的范围),inode number 是在一个分区内唯一有效,不能跨分区。
-
分区、分组、填写系统属性是OS做的,是在分区完成之后,要让分区能正常使用,需要对分区进行格式化。格式化的过程,其实是OS向分区写入文件系统的管理属性信息。
-
如果inode只是单单的用数组建立和datablock的映射关系 ,15*4KB是不是意味着一个文件内容最多60KB?并不是。

- 有没有可能,一个分组,数据块没用完,inode没了,或者inode没用完,datablock用完了?是可能的因为inode节点和数据块数量固定。
软硬链接
软连接
[admin1@VM-4-17-centos lesson18]$ ln -s myfile.txt my-soft
[admin1@VM-4-17-centos lesson18]$ ll
total 4
-rw-rw-r-- 1 admin1 admin1 32 Jul 30 19:23 myfile.txt
lrwxrwxrwx 1 admin1 admin1 10 Jul 30 19:25 my-soft -> myfile.txt
[admin1@VM-4-17-centos lesson18]$ ls -il
total 4
1572867 -rw-rw-r-- 1 admin1 admin1 32 Jul 30 19:23 myfile.txt
1572871 lrwxrwxrwx 1 admin1 admin1 10 Jul 30 19:25 my-soft -> myfile.txt
软连接是一个独立的连接文件,有自己的inode number,必有自己的inode属性和内容。
软连接内部放的是自己所指向的文件的路径!类似于windows的快捷方式。
硬链接
[admin1@VM-4-17-centos lesson18]$ ln myfile.txt my-hard
[admin1@VM-4-17-centos lesson18]$ ll
total 8
-rw-rw-r-- 2 admin1 admin1 32 Jul 30 19:23 myfile.txt
-rw-rw-r-- 2 admin1 admin1 32 Jul 30 19:23 my-hard
lrwxrwxrwx 1 admin1 admin1 10 Jul 30 19:25 my-soft -> myfile.txt
[admin1@VM-4-17-centos lesson18]$ ls -li
total 8
1572867 -rw-rw-r-- 2 admin1 admin1 32 Jul 30 19:23 myfile.txt
1572867 -rw-rw-r-- 2 admin1 admin1 32 Jul 30 19:23 my-hard
1572871 lrwxrwxrwx 1 admin1 admin1 10 Jul 30 19:25 my-soft -> myfile.txt
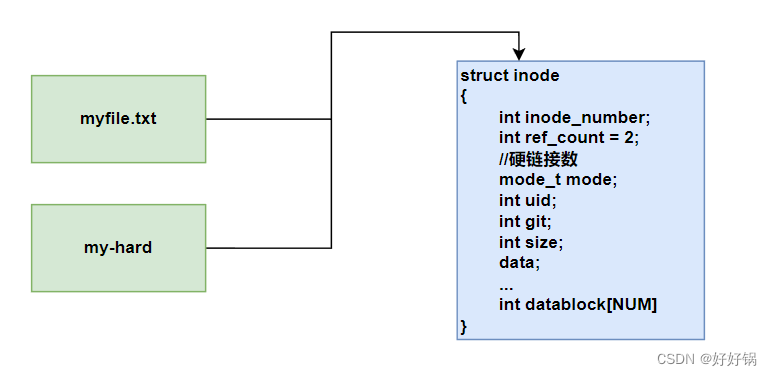
硬链接和目标文件公用一个inode number,所以硬链接一定是和目标文件使用同一个inode节点的。
硬链接建立了新的文件名和老的inode的映射关系! 本质是一种引用计数!
引用计数:有多少指向。当引用计数为0是才会删除 inode bitmap 对应比特位。
[admin1@VM-4-17-centos lesson19]$ ln hard-link hard-llink
[admin1@VM-4-17-centos lesson19]$ ls -al
total 20
drwxrwxr-x 2 admin1 admin1 4096 Jul 30 21:13 .
drwxrwxr-x 17 admin1 admin1 4096 Jul 30 21:06 ..
-rw-rw-r-- 3 admin1 admin1 12 Jul 30 21:12 bite.txt
-rw-rw-r-- 3 admin1 admin1 12 Jul 30 21:12 hard-link
-rw-rw-r-- 3 admin1 admin1 12 Jul 30 21:12 hard-llink
[admin1@VM-4-17-centos lesson19]$ unlink hard-llink
[admin1@VM-4-17-centos lesson19]$ ls -al
total 16
drwxrwxr-x 2 admin1 admin1 4096 Jul 30 21:14 .
drwxrwxr-x 17 admin1 admin1 4096 Jul 30 21:06 ..
-rw-rw-r-- 2 admin1 admin1 12 Jul 30 21:12 bite.txt
-rw-rw-r-- 2 admin1 admin1 12 Jul 30 21:12 hard-link
1572887 -rw-rw-r-- 1 admin1 admin1 12 Jul 30 21:12 bite.txt
1572888 drwxrwxr-x 2 admin1 admin1 4096 Jul 30 21:24 dir
1572889 -rw-rw-r-- 1 admin1 admin1 0 Jul 30 21:25 file1.txt
1572890 -rw-rw-r-- 1 admin1 admin1 0 Jul 30 21:25 file2.txt
//创建一个新文件硬链接数为1,但创建一个目录硬链接数为2,肯定有个文件与该目录指向同一个inode。
[admin1@VM-4-17-centos lesson19]$ cd dir
[admin1@VM-4-17-centos dir]$ ls -ail
total 8
1572888 drwxrwxr-x 2 admin1 admin1 4096 Jul 30 21:24 .
1572886 drwxrwxr-x 3 admin1 admin1 4096 Jul 30 21:25 ..
//.就是dir的硬链接
[admin1@VM-4-17-centos dir]$ ls -di /home/admin1/linux_code/lesson19
1572886 /home/admin1/linux_code/lesson19
[admin1@VM-4-17-centos dir]$ ls -di ..
1572886 ..
//..就是dir的上级目录lesson19的硬链接
[admin1@VM-4-17-centos lesson19]$ ln dir hard-link
ln: ‘dir’: hard link not allowed for directory
//用户不能给目录建立硬链接,因为容易造成环路路径问题!
[admin1@VM-4-17-centos lesson19]$ stat bite.txt
File: ‘bite.txt’
Size: 12 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 1572887 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ admin1) Gid: ( 1001/ admin1)
Access: 2023-07-30 21:12:44.224090777 +0800
Modify: 2023-07-30 21:12:43.097089772 +0800
Change: 2023-07-30 21:25:28.625796360 +0800
Birth: -
//ACM
//Access:文件最后查看的时间,不一定每次查看都会修改
//Modify:文件内容最后修改的时间
//Change:文件属性最后修改的时间
动态库和静态库
见一见库
-
系统已经预装了C/C++的头文件和库文件,头文件提供方法说明,库提供方法的实现,头和库是对应关系的,是要组合在一起使用的。
-
头文件是在预处理阶段就引入的,链接的本质其实就是加载库!
[admin1@VM-4-17-centos lesson19]$ ls /usr/include/
aio.h ctype.h FlexLexer.h gssapi.h libgen.h mft netrose profile.h sepol systemd utmp.h
aliases.h db_185.h fmtmsg.h gssrpc libintl.h misc nfs protocols setjmp.h tar.h utmpx.h
alloca.h db.h fnmatch.h iconv.h libio.h mntent.h nlist.h pthread.h sgtty.h termio.h valgrind
a.out.h dirent.h fpu_control.h ieee754.h libiptc monetary.h nl_types.h pty.h shadow.h termios.h values.h
argp.h dlfcn.h fstab.h ifaddrs.h libipulog mqueue.h nss.h pwd.h signal.h tgmath.h verto.h
argz.h drm fts.h inttypes.h libmnl mstflint numacompat1.h python2.7 sound thread_db.h verto-module.h
ar.h dwarf.h ftw.h ip6tables.h libnl3 mtcr_ul numa.h python3.6m spawn.h time.h video
arpa elf.h _G_config.h iptables libudev.h mtd numaif.h rdma stab.h ttyent.h wait.h
asm elfutils gconv.h iptables.h limits.h net obstack.h re_comp.h stdc-predef.h uapi wchar.h
asm-generic endian.h gelf.h kadm5 link.h netash openssl regex.h stdint.h uchar.h wctype.h
assert.h envz.h getopt.h kdb.h linux netatalk paths.h regexp.h stdio_ext.h ucm wordexp.h
bits err.h gio-unix-2.0 keyutils.h locale.h netax25 pcrecpparg.h resolv.h stdio.h ucontext.h xen
byteswap.h errno.h glib-2.0 krad.h lzma netdb.h pcrecpp.h rpc stdlib.h ucp xlocale.h
c++ error.h glob.h krb5 lzma.h neteconet pcre.h rpcsvc string.h ucs xtables.h
com_err.h et gnu krb5.h malloc.h netinet pcreposix.h sched.h strings.h uct xtables-version.h
complex.h execinfo.h gnu-versions.h langinfo.h math.h netipx pcre_scanner.h scsi sys ulimit.h zconf.h
cpio.h fcntl.h grp.h lastlog.h mcheck.h netiucv pcre_stringpiece.h search.h syscall.h unistd.h zlib.h
cpufreq.h features.h gshadow.h libdb mellanox netpacket poll.h selinux sysexits.h ustat.h
crypt.h fenv.h gssapi libelf.h memory.h netrom printf.h semaphore.h syslog.h utime.h
[admin1@VM-4-17-centos lesson19]$ ls /usr/lib64/libc*
/usr/lib64/libc-2.17.so /usr/lib64/libcmdif.a /usr/lib64/libcroco-0.6.so.3 /usr/lib64/libc.so
/usr/lib64/libc.a /usr/lib64/libc_nonshared.a /usr/lib64/libcroco-0.6.so.3.0.1 /usr/lib64/libc.so.6
/usr/lib64/libcairo-script-interpreter.so.2 /usr/lib64/libcom_err.so /usr/lib64/libcrypt-2.17.so /usr/lib64/libc_stubs.a
/usr/lib64/libcairo-script-interpreter.so.2.11512.0 /usr/lib64/libcom_err.so.2 /usr/lib64/libcrypt.a /usr/lib64/libcupscgi.so.1
/usr/lib64/libcairo.so.2 /usr/lib64/libcom_err.so.2.1 /usr/lib64/libcrypto.so /usr/lib64/libcupsimage.so.2
/usr/lib64/libcairo.so.2.11512.0 /usr/lib64/libconfig.so.9 /usr/lib64/libcrypto.so.10 /usr/lib64/libcupsmime.so.1
/usr/lib64/libcap-ng.so.0 /usr/lib64/libconfig++.so.9 /usr/lib64/libcrypto.so.1.0.2k /usr/lib64/libcupsppdc.so.1
/usr/lib64/libcap-ng.so.0.0.0 /usr/lib64/libconfig.so.9.1.3 /usr/lib64/libcryptsetup.so.12 /usr/lib64/libcups.so.2
/usr/lib64/libcap.so.2 /usr/lib64/libconfig++.so.9.1.3 /usr/lib64/libcryptsetup.so.12.3.0 /usr/lib64/libcurl.so.4
/usr/lib64/libcap.so.2.22 /usr/lib64/libcpupower.so.0 /usr/lib64/libcryptsetup.so.4 /usr/lib64/libcurl.so.4.3.0
/usr/lib64/libcidn-2.17.so /usr/lib64/libcpupower.so.0.0.0 /usr/lib64/libcryptsetup.so.4.7.0
/usr/lib64/libcidn.so /usr/lib64/libcrack.so.2 /usr/lib64/libcrypt.so
/usr/lib64/libcidn.so.1 /usr/lib64/libcrack.so.2.9.0 /usr/lib64/libcrypt.so.1
【理解现象】:
-
所以在vs2019、2022下安装环境开发环境 – 安装编译器软件,安装要开发的语言配套的库和头文件。
-
在使用编译器,都会有语法的自动提醒功能,需要先包含头文件的。语法提醒本质:编译器或者编辑器,它会自动的将用户输入的内容,不断的在被包含的头文件中进行搜索,自动提醒功能是依赖头文件来的。
-
我们在写代码的时候,我们环境怎么知道我们的代码中有哪些地方有语法报错,那些地方定义变量有问题?编译器有命令行模式,还有其他自动化的模式帮我们不断进行语法检查。
为什么要有库
-
提高开发效率。
-
学习阶段——造轮子,开发阶段——用轮子。
设计一个库
静态库(.a/.lib)/动态库(.so.dll)。
库的名称:libstdc++.so.6 libc-2.17.so
一般云服务器,默认只存在动态库,不存在静态库,静态库需要单独安装。
设计静态库
[admin1@VM-4-17-centos mylib]$ ll
total 24
-rw-rw-r-- 1 admin1 admin1 70 Jul 31 09:03 myadd.c
-rw-rw-r-- 1 admin1 admin1 40 Jul 31 09:03 myadd.h
-rw-rw-r-- 1 admin1 admin1 1240 Jul 31 09:12 myadd.o
-rw-rw-r-- 1 admin1 admin1 71 Jul 31 09:04 mysub.c
-rw-rw-r-- 1 admin1 admin1 40 Jul 31 09:04 mysub.h
-rw-rw-r-- 1 admin1 admin1 1240 Jul 31 09:12 mysub.o
[admin1@VM-4-17-centos mylib]$ ar -rc libmymath.a *.o //生成静态库
[admin1@VM-4-17-centos mylib]$ ll
total 28
-rw-rw-r-- 1 admin1 admin1 2692 Jul 31 09:17 libmymath.a
-rw-rw-r-- 1 admin1 admin1 70 Jul 31 09:03 myadd.c
-rw-rw-r-- 1 admin1 admin1 40 Jul 31 09:03 myadd.h
-rw-rw-r-- 1 admin1 admin1 1240 Jul 31 09:12 myadd.o
-rw-rw-r-- 1 admin1 admin1 71 Jul 31 09:04 mysub.c
-rw-rw-r-- 1 admin1 admin1 40 Jul 31 09:04 mysub.h
-rw-rw-r-- 1 admin1 admin1 1240 Jul 31 09:12 mysub.o
当有了一个库,要将库引入我们的项目,必须要让编译器找到头文件+库文件。
[admin1@VM-4-17-centos otherPerson]$ ll
total 16
-rw-rw-r-- 1 admin1 admin1 2692 Jul 31 09:19 libmymath.a
-rw-rw-r-- 1 admin1 admin1 219 Jul 31 09:05 main.c
-rw-rw-r-- 1 admin1 admin1 40 Jul 31 09:19 myadd.h
-rw-rw-r-- 1 admin1 admin1 40 Jul 31 09:19 mysub.h
[admin1@VM-4-17-centos otherPerson]$ gcc -o mytest main.c -L. -lmymath//-L库的路径,-l库的名称
[admin1@VM-4-17-centos otherPerson]$
drwxrwxr-x 2 admin1 admin1 4096 Jul 31 09:34 include//头文件目录
drwxrwxr-x 2 admin1 admin1 4096 Jul 31 09:34 lib//库文件目录
-rw-rw-r-- 1 admin1 admin1 219 Jul 31 09:05 main.c
[admin1@VM-4-17-centos otherPerson]$ gcc -o mytest main.c -I./include -L./lib -lmymath //头文件路径 库文件路径 库文件名
[admin1@VM-4-17-centos otherPerson]$
【第三方库的使用】:
-
需要指定的头文件和库文件。
-
如果没有默认安装到gcc、g++默认的搜索路径下,用户必须指明对应的选项,告知编译器:头文件在哪里、库文件在哪里、库文件的名称。
-
将下载下来的库和头文件,拷贝到系统默认路径下——在linux下安装库!对于任何软件而言,安装和卸载的本质就是拷贝到系统特定的路径!
-
如果我们安装的库是第三方的(除了语言、操作系统系统接口)库,我们要正常使用,即便是已经全部安装到系统中,gcc/g++必须用 -l 指明具体库的名称!
【理解现象】:
无论你是从网络中未来直接下好的库,或者是源代码(需要编译),安装的命令等价于cp,复制到到系统的特定路径下。
所以我们安装大部分指令,库等等都是需要sudo的或者超级用户操作!
设计动态库
[admin1@VM-4-17-centos mylib]$ gcc -fPIC -c myadd.c
[admin1@VM-4-17-centos mylib]$ gcc -fPIC -c mysub.c // -fPIC 形成的.o:与位置无关码
[admin1@VM-4-17-centos mylib]$ ll
total 24
-rw-rw-r-- 1 admin1 admin1 70 Jul 31 09:03 myadd.c
-rw-rw-r-- 1 admin1 admin1 40 Jul 31 09:03 myadd.h
-rw-rw-r-- 1 admin1 admin1 1240 Jul 31 10:01 myadd.o
-rw-rw-r-- 1 admin1 admin1 71 Jul 31 09:04 mysub.c
-rw-rw-r-- 1 admin1 admin1 40 Jul 31 09:19 mysub.h
-rw-rw-r-- 1 admin1 admin1 1240 Jul 31 10:01 mysub.o
[admin1@VM-4-17-centos mylib]$ gcc -shared -o libmymath.so *.o
[admin1@VM-4-17-centos mylib]$ ll
total 32
-rwxrwxr-x 1 admin1 admin1 7944 Jul 31 10:18 libmymath.so
-rw-rw-r-- 1 admin1 admin1 70 Jul 31 09:03 myadd.c
-rw-rw-r-- 1 admin1 admin1 40 Jul 31 09:03 myadd.h
-rw-rw-r-- 1 admin1 admin1 1240 Jul 31 10:01 myadd.o
-rw-rw-r-- 1 admin1 admin1 71 Jul 31 09:04 mysub.c
-rw-rw-r-- 1 admin1 admin1 40 Jul 31 09:19 mysub.h
-rw-rw-r-- 1 admin1 admin1 1240 Jul 31 10:01 mysub.o
[admin1@VM-4-17-centos mylib]$
[admin1@VM-4-17-centos mylib]$ tar czf mymath.tgz include lib
[admin1@VM-4-17-centos mylib]$ cp mymath.tgz ../otherPerson/
[admin1@VM-4-17-centos otherPerson]$ tar xzf mymath.tgz
[admin1@VM-4-17-centos otherPerson]$ ll
total 16
drwxrwxr-x 2 admin1 admin1 4096 Jul 31 10:19 include
drwxrwxr-x 2 admin1 admin1 4096 Jul 31 10:19 lib
-rw-rw-r-- 1 admin1 admin1 219 Jul 31 09:05 main.c
-rw-rw-r-- 1 admin1 admin1 2325 Jul 31 10:20 mymath.tgz
[admin1@VM-4-17-centos otherPerson]$ gcc -o mytest main.c -I include/ -L lib/ -l mymath
[admin1@VM-4-17-centos otherPerson]$ ./mytest
./mytest: error while loading shared libraries: libmymath.so: cannot open shared object file: No such file or directory
告诉了编译器库在哪里,但没有告诉操作系统!运行时.so并没有在系统默认的路径下,所以os依旧找不到!为什么静态库能找到呢?
静态库链接原则:将用户使用的二进制代码直接拷贝到目标可执行程序中,但动态库不会!
【运行时OS如何查找动态库】:
-
环境变量:LD_LIBRARY_PATH(临时方案)。
-
软连接方案(/lib64)。
-
配置文件方案(/etc/ld.so.conf)。
库的加载
静态库链接形成的可执行程序,本身就有静态库中对方法的实现。非常占用资源!(磁盘中可执行程序体积变大,加载占用内存,下载周期变长,占用网络资源)。
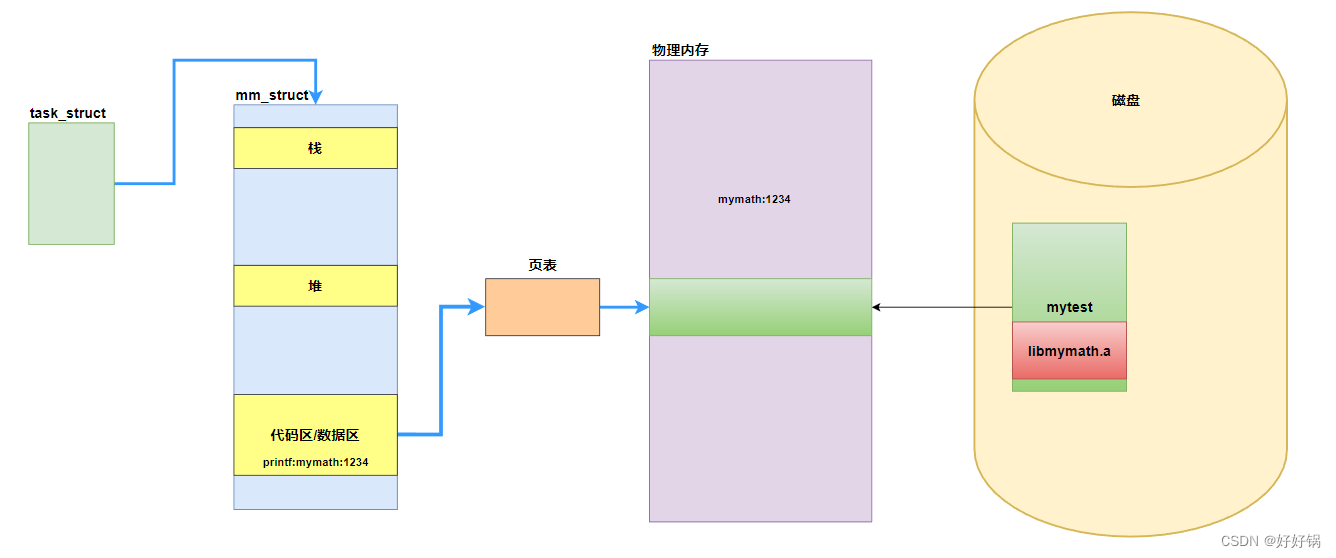
动态库链接将可执行程序中的外部符号替换成库中的具体的地址。
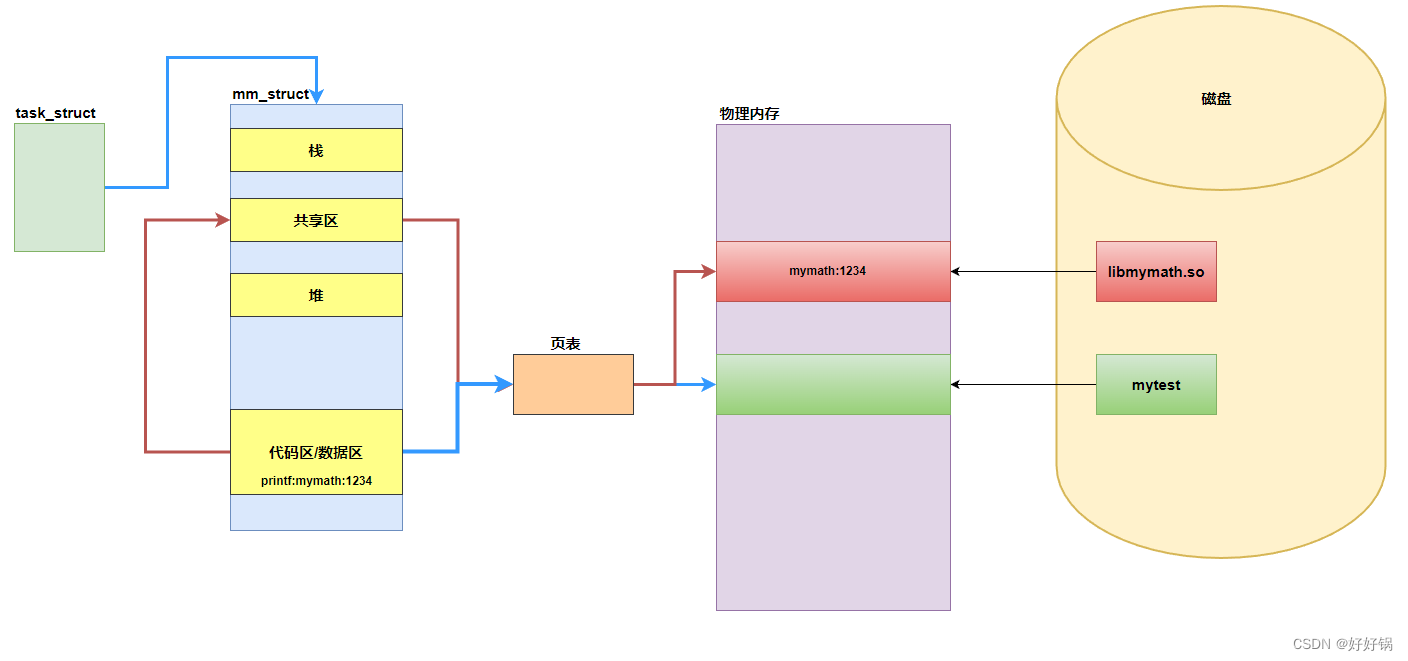
【库中地址的理解】:
在程序翻译链接形成可执行程序的时候,可执行程序内部有地址。
【地址】
地址就两类:绝对编址和相对编址。
静态库链接到程序中是用绝对编址,静态库就是可执行程序编制的一部分。
动态库链接必定面临一个问题:不同的进程,运行程度不同,需要是用的第三方库是不同,注定了每一个进程的共享空间中空闲位置是不确定的!动态库中的地址,绝对不能确定,要使用相对编址!动态库中的所有地址,都是偏移量,默认从0地址开始。当一个动态库真正被映射进地址空间的时候,它的起始地址才能真正确定!
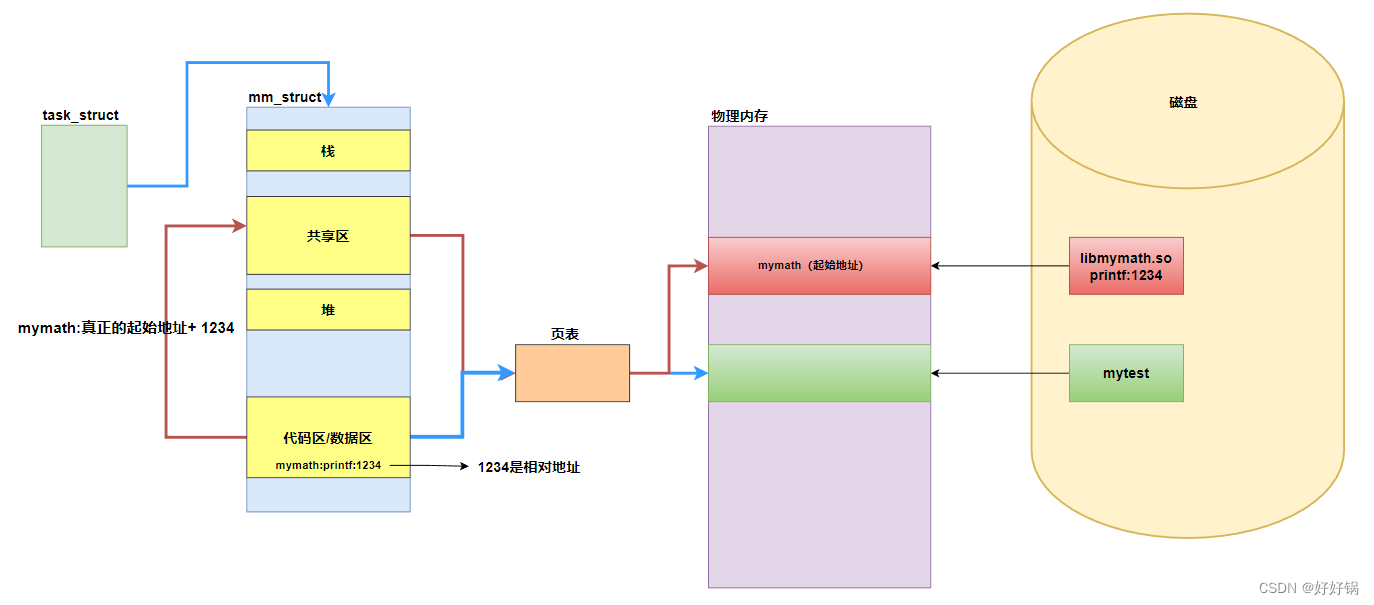
【其他实验】:
-
动态库和静态库同时存在,系统默认采用动态链接。
-
编译器在进行链接的时候,如果提供的库既有动态库又有静态库,优先动态链接;没有动态库,只有静态库,那就静态链接。
-
一般都是动态库和静态库都有,除非编译时带上-static,则只有静态链接。
-
在同一个可执行文件中,不能同时包含静态链接和动态链接的代码。
【云服务器】:
一般只会提供动态库。
sudo yum install -y libstdc++-static //c++静态库
sudo yum install -y glibc-static //c静态库