PyTorch深度学习实战(10)——过拟合及其解决方法
- 0. 前言
- 1. 过拟合基本概念
- 2. 添加 Dropout 解决过拟合
- 3. 使用正则化解决过拟合
- 3.1 L1 正则化
- 3.2 L2 正则化
- 4. 学习率衰减
- 小结
- 系列链接
0. 前言
过拟合 (Overfitting) 是指在机器学习中,模型过于复杂而导致在训练数据上表现良好,但在新的未见过的数据上表现不佳的现象。直观的讲,可能会在训练过程中出现模型的训练准确率约为 100%,而测试准确率仅有 80% 左右的情况。在本文中,我们直观地介绍训练与测试准确率之间的差异的原因以及解决方法。
1. 过拟合基本概念
在《神经网络性能优化技术》中,我们经常看到这样的现象——训练数据集的准确率通常超过 95%,而验证数据集的准确率大约只为 89%。从本质上讲,这表明该模型在未见过的数据上的泛化程度不高,也表明模型正在学习训练数据集的异常数据,这些情况并不适用于验证数据集。
当模型过度关注于训练数据中的细节和噪音时,会导致过拟合。过拟合通常发生在模型复杂度过高、训练数据量较少或训练数据不平衡的情况下。当模型太过复杂时,它可能在训练数据中学习到了噪声和随机性,并将其视为普遍规律。当训练数据量较少时,模型可能没有足够的样本来全面学习数据的特征分布,从而容易出现过拟合。过拟合现象使得模型对训练数据中的个别特征过于敏感,而无法正确地推广到新的数据。可以使用以下策略降低模型过拟合的影响:
- 增加训练数据的数量,确保数据集更加全面和多样化
- 减少模型的复杂度,例如减少参数数量或使用正则化方法
- 使用交叉验证等技术来评估模型的性能,并进行模型选择
- 提前停止训练,即在模型开始过拟合之前停止迭代
- 进行特征选择,删除不相关或冗余的特征
- 数据预处理,例如归一化/标准化数据,处理异常值等
2. 添加 Dropout 解决过拟合
Dropout 是一种用于减少神经网络过拟合的正则化技术。在训练过程中,Dropout 会随机地将一部分神经元的输出置为 0 (即丢弃),从而降低神经网络对特定神经元的依赖性。具体来说,在每次训练迭代中,Dropout 会以一定的概率随机选择部分神经元,并将其输出置为 0,这意味着每个神经元都有一定的概率被“关闭”,从而迫使网络学习到更加鲁棒和独立的特征表示。

通过引入 Dropout,神经网络无法过度依赖某些特定神经元,因为它们的输出可能随时被丢弃。这样可以有效地减少神经网络的复杂性,降低模型对训练数据的噪音和过拟合的敏感性,提高模型的泛化能力。在训练完成后,通常不再应用 Dropout,而是使用所有的神经元进行推理和预测。这是因为在测试阶段,我们希望模型能够充分利用所有可用的神经元来最大限度地提取特征和进行预测。
正常模型训练时,每次计算 loss.backward() 时,都更新模型权重。通常,神经网络中包含数以百万计的参数,因此可能虽然大多数参数有助于训练模型,但某些参数可能会针对训练图像进行微调,从而导致它们的值仅由训练数据集中的少数图像决定,这会导致模型在训练数据上具有较高精度,但在验证数据集上的泛化能力较差。
由于 Dropout 在训练和验证过程中具有不同操作,因此必须预先指定模型的模式为 model.train() (处于训练阶段)或 model.eval() (处于验证阶段)。
定义架构时,在 get_model() 函数中指定 Dropout 如下:
from torch.optim import SGD, Adam
def get_model():
model = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
在以上代码中,还在线性激活前添加了 Dropout,训练和验证数据集的损失和准确率变化如下所示:

使用相同的架构,未使用 Dropout 时训练和验证数据集的损失和准确率变化如下所示:

可以看出,训练数据集和验证数据集的准确率之间的差异没有之前模型差距那么大,有效的降低了模型的过拟合。
绘制两种情况下隐藏层的权重直方图,可以看到使用 Dropout 时训练和测试准确率之间的差距低于没有 Dropout 时模型训练和测试准确率的差距:


3. 使用正则化解决过拟合
除了训练准确率远高于验证准确率外,过拟合的另一个特征是网络中的某些权重值显著高于其他权重值,高权重值可能是模型为了拟合训练数据中异常值的表现。正则化是一种惩罚模型中具有较高值的权重的技术,因此,需要同时最小化训练数据的损失以及权重值。在本节中,我们将学习两类正则化:
- L1 正则化
- L2 正则化
3.1 L1 正则化
L1 正则化计算如下:
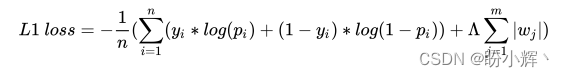
L
1
l
o
s
s
=
−
1
n
(
∑
i
=
1
n
(
y
i
∗
l
o
g
(
p
i
)
+
(
1
−
y
i
)
)
+
Λ
∑
j
=
1
m
∣
w
j
∣
)
L1\ loss=-\frac 1n(\sum_{i=1}^n(y_i*log(p_i)+(1-y_i))+\Lambda \sum_{j=1}^m|w_j|)
L1 loss=−n1(i=1∑n(yi∗log(pi)+(1−yi))+Λj=1∑m∣wj∣)
上述公式的第一部分是在以上模型中用于优化的分类交叉熵损失,而第二部分是指模型权重值的绝对值之和,
Λ
\Lambda
Λ 是用于平衡交叉熵损失和权重绝对值的权重系数。L1 正则化通过将权重的绝对值合并到损失值的计算中来确保它惩罚具有较高绝对值的权重,L1 正则化在训练模型的同时进行:
def train_batch(x, y, model, opt, loss_fn):
prediction = model(x)
l1_regularization = 0
for param in model.parameters():
l1_regularization += torch.norm(param,1)
batch_loss = loss_fn(prediction, y) + 0.0001*l1_regularization
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
return batch_loss.item()
在以上代码中,首先初始化 l1_regularization,并对所有层的权重和偏置进行了正则化。torch.norm(param,1) 提供了权重和偏置值的绝对值。此外,使用一个非常小的权重系数 (0.0001) 来平衡参数绝对值之和对损失函数的影响。
使用 L1 正则化后,训练和验证数据集上的损失和准确率的变化如下所示:

可以看到训练数据集和验证数据集的准确率差异相比没有 L1 正则化时更小。
3.2 L2 正则化
L2 正则化计算如下:
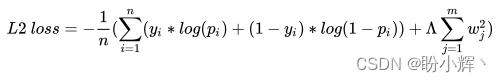
L
2
l
o
s
s
=
−
1
n
(
∑
i
=
1
n
(
y
i
∗
l
o
g
(
p
i
)
+
(
1
−
y
i
)
∗
l
o
g
(
1
−
p
i
)
)
+
Λ
∑
j
=
1
m
w
j
2
)
L2\ loss =-\frac 1n(\sum_{i=1}^n(y_i*log(p_i)+(1-y_i)*log(1-p_i))+\Lambda \sum_{j=1}^mw_j^2)
L2 loss=−n1(i=1∑n(yi∗log(pi)+(1−yi)∗log(1−pi))+Λj=1∑mwj2)
其中,第一部分是指分类交叉熵损失,而第二部分是指模型权重值的平方和,
Λ
\Lambda
Λ 是用于平衡交叉熵损失和权重平方和的权重系数。与 L1 正则化类似,通过将权重的平方和纳入损失计算来惩罚较高权重值。L2 正则化同样在训练模型的同时进行:
def train_batch(x, y, model, opt, loss_fn):
prediction = model(x)
l2_regularization = 0
for param in model.parameters():
l2_regularization += torch.norm(param,2)
batch_loss = loss_fn(prediction, y) + 0.01*l2_regularization
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
return batch_loss.item()
在以上代码中,正则化的权重参数 (0.01) 略高于 L1 正则化,因为权重通常在 -1 到 1 之间,并且执行平方后会得到更小的结果值,如果权重参数较小,将导致在整体损失计算第二项的影响非常小。
使用 L2 正则化后,训练和验证数据集上的损失和准确率的变化情况如下所示:

可以看到 L2 正则化同样可以令验证和训练数据集的准确率和损失更接近。
最后,我们比较没有进行正则化和使用 L1/L2 正则化的权重,观察网络层的权重分布,如下图所示:

可以看到,与不执行正则化相比,执行 L1/L2 正则化时参数的分布范围非常小,这可能会减少为异常数据更新权重的机会。
我们已经知道了较高的学习率在缩放和未缩放的数据集上均难以得到最佳结果,在下一节中,我们将学习如何在模型开始过拟合时自动降低学习率.
4. 学习率衰减
在以上模型中,我们在模型训练过程中使用恒定的学习率,但是,通常可以将权重快速更新到接近最佳状态,在模型训练后期可以进行缓慢的更新,因为模型训练初期的损失较高,而在后期损失较低。这就需要模型训练初期具有较高学习率,然后随着模型接近最佳的准确率,学习率也需要逐渐降低,因此我们这需要了解在何时降低学习率。
一种常用的方法是持续监控验证损失,如果验证损失在一段 epoch 内没有减少,就降低学习率。PyTorch 提供了调度方法 lr_scheduler,当验证损失在之前的 “x” 个 epoch 内没有减少时,降低学习率:
from torch import optim
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,
factor=0.5,patience=0,
threshold = 0.001,
verbose=True,
min_lr = 1e-5,
threshold_mode = 'abs')
在以上代码中,指定如果某个值在接下来的 n 个 epoch (使用 patience参数指定)没有提高指定阈值(使用 threshold 参数指定),则学习率衰减为原来的 0.5 倍(即变为原来的 1/2,使用 factor 参数指定),且使用参数 min_lr 指定学习率的最小值 (不低于 1e-5),并且使用参数 threshold_mode 指定阈值模式(此处使用 abs,以确保超过指定的最小阈值)。接下来,在训练模型时应用 lr_scheduler,并在模型训练时监测验证损失:
trn_dl, val_dl = get_data()
model, loss_fn, optimizer = get_model()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,
factor=0.5,
patience=0,
threshold = 0.001,
verbose=True,
min_lr = 1e-5,
threshold_mode = 'abs')
train_losses, train_accuracies = [], []
val_losses, val_accuracies = [], []
for epoch in range(30):
# print(epoch)
train_epoch_losses, train_epoch_accuracies = [], []
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
batch_loss = train_batch(x, y, model, optimizer, loss_fn)
train_epoch_losses.append(batch_loss)
train_epoch_loss = np.array(train_epoch_losses).mean()
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
is_correct = accuracy(x, y, model)
train_epoch_accuracies.extend(is_correct)
train_epoch_accuracy = np.mean(train_epoch_accuracies)
for ix, batch in enumerate(iter(val_dl)):
x, y = batch
val_is_correct = accuracy(x, y, model)
validation_loss = val_loss(x, y, model, loss_fn)
scheduler.step(validation_loss)
val_epoch_accuracy = np.mean(val_is_correct)
train_losses.append(train_epoch_loss)
train_accuracies.append(train_epoch_accuracy)
val_losses.append(validation_loss)
val_accuracies.append(val_epoch_accuracy)
在以上代码中,指定只要验证损失在连续的 epoch 内没有减少,就激活调度程序,学习率降低 0.5 倍,模型上执行调度程序输出如下:
Epoch 3: reducing learning rate of group 0 to 5.0000e-04.
Epoch 5: reducing learning rate of group 0 to 2.5000e-04.
Epoch 7: reducing learning rate of group 0 to 1.2500e-04.
Epoch 11: reducing learning rate of group 0 to 6.2500e-05.
Epoch 13: reducing learning rate of group 0 to 3.1250e-05.
Epoch 14: reducing learning rate of group 0 to 1.5625e-05.
Epoch 15: reducing learning rate of group 0 to 1.0000e-05.
训练和验证数据集的准确率和损失随时间变化如下:
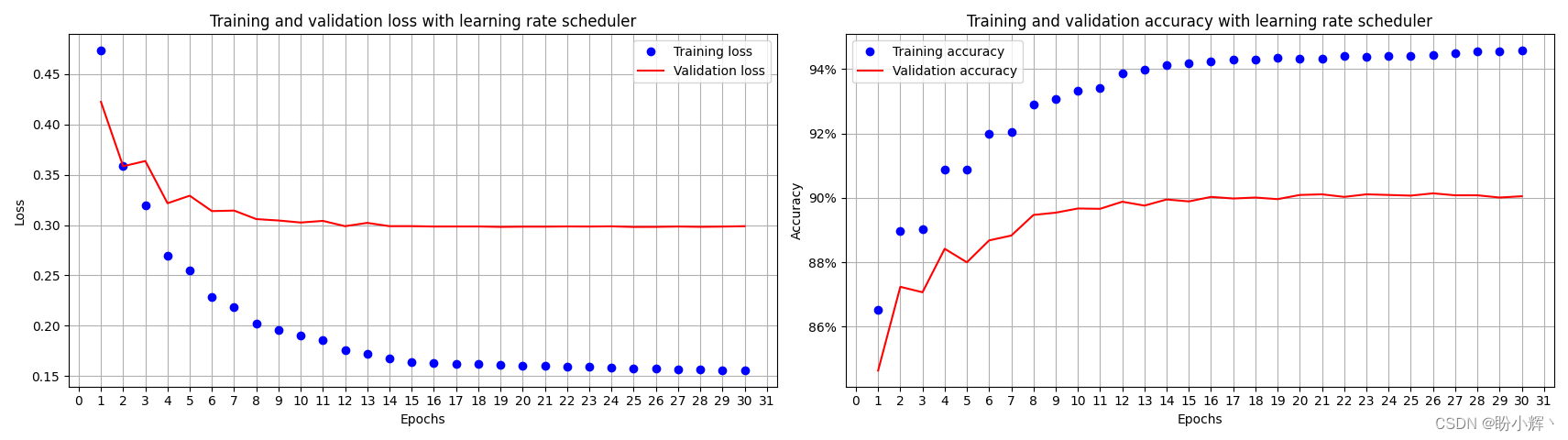
通过使用调度程序,即使对模型进行了 30 个(或更多) epoch 的训练,也没有严重的过拟合问题,这是因为当学习率衰减的极小时,权重的更新也变得非常小,因此训练和验证准确率之间的差距也非常小。
小结
过拟合是指机器学习模型在训练集上表现很好,但在测试集或未见过的数据上表现较差的现象。过拟合是由于模型在训练过程中过度拟合了训练数据的特点和噪声,导致了对训练样本的过度依赖和泛化能力不足。为了解决过拟合问题,选择适当的方法需要对具体问题和数据进行分析,并在模型构建和调优过程中进行实验和验证。在实践中,通常需要权衡模型的复杂度和泛化能力,以获得更好的结果。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化