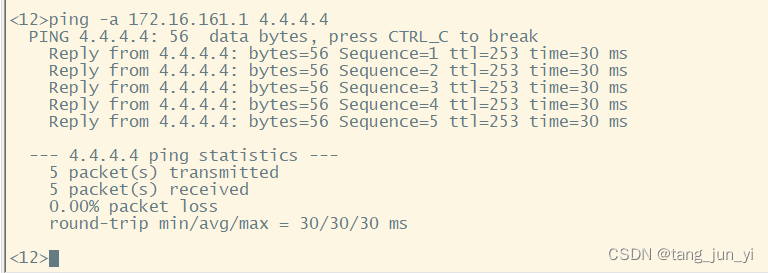
什么是聚集索引,非聚集索引,回表查询,覆盖索引
聚集索引就是将数据存储与索引放到了一起,索引结构的叶子节点保存了行数据,一张表必须有且只有一个聚集索引。
如果存在主键,主键就是聚集索引,如果不存在主键将使用第一个唯一索引作为聚集索引,如果既没有主键又找不到合适的唯一索引则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
非聚集索引将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键,可以存在多个。
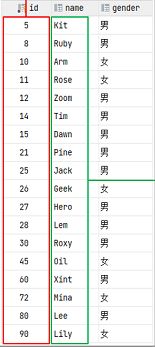
例如:在表中的主键id字段上建立聚集索引,name字段上建立非聚集索引(二级索引)
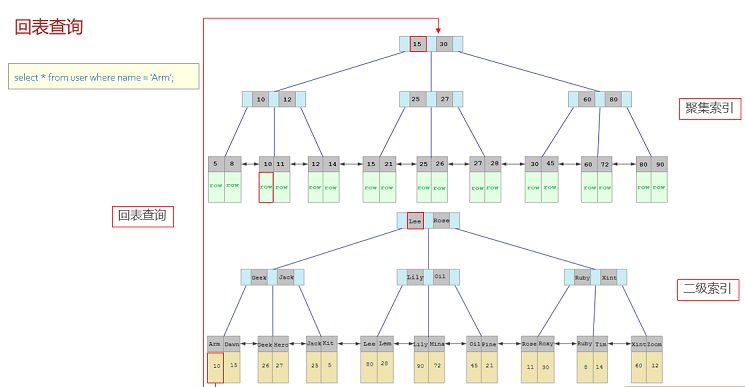
从上图可以看出聚集索引的叶子节点除了存储主键id的值以外还存储了行中的数据,只要定位到叶子节点就可以读出表中的任意数据。而非聚集索引的叶子节点存储的是主键id的值,在非聚集索引上定位到叶子节点以后只能得到主键id的值,如果想得到整行的值还需要在聚集索引上查找主键id的值。这就是回表查询。
那么什么是覆盖索引呢?
覆盖索引指的是查询使用了索引,并且需要返回的列在该索引中已经全部都能找到。
比如下面这张表:
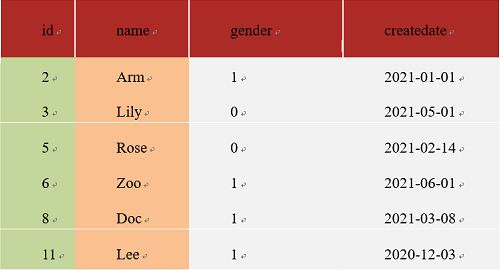
id为主键默认主键索引为聚集索引,在name字段上建立非聚集索引。
执行sql语句:select * from tb_user where id = 2
会在主键索引上查询id=2的数据,定位到叶子节点以后可以查询出所有的数据。在索引中就包含了需要查询的所有数据,因此是覆盖索引。
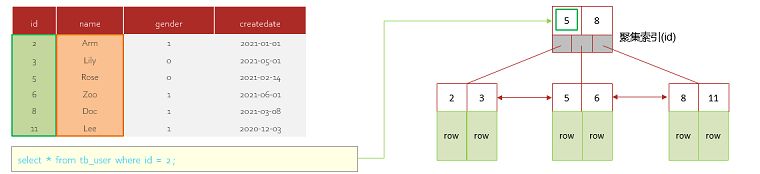
再来看一个sql语句:select id,name from tb_user where name = ‘Arm’
查询name为Arm的id和name这里用到了name上的非聚集索引,查询的id和name其中id为主键,name为索引列,都在该索引中,因此是覆盖索引。

再看一个sql语句:select id,name,gender from tb_user where name = ‘Arm’
这里在name的非聚集索引上要查询id,name,gender三个列的值。其中id,name在索引中包含,gender不在索引中需要通过回表查询,因此不是覆盖索引。
覆盖索引可以用来缓解超大分页的查询效率问题。
在数据量比较大时,如果进行limit分页查询,在查询时,越往后,分页查询效率越低
我们来看看limit分页查询耗时对比
Select * from stu limit 0,10
这条sql语句耗时0.00 sec
Select * from stu limit 9000000,10
这条sql语句耗时11.05 sec
为什么第二条sql语句比第一条sql语句耗时长了这么多呢?因为第二条sql语句需要对前9000010条数据进行排序只需要返回第9000000到900010的记录,其他记录丢弃,查询排序的代价非常大。
怎么样去优化呢?
可以通过覆盖索引加子查询来提高性能。
看下面的sql语句:
select *from stu t,
(select id from tb_sku order by id limit 9000000,10) a
where t.id = a.id;
该sql语句执行耗时7.13 sec性能明显提升
在子查询中使用了覆盖索引查询9000000到900010的id然后再和stu表关联查询。查询出其他字段内容。
另外我精心编写了两百道java面试题,攘括了java基础,数据库,java高级,多线程,jvm,ssm,spring cloud等内容的高频面试题,需要的私信“java面试题”