Gitlet
- 项目简介
- 整体结构
- 对象概念(object concept)
- 追踪文件(track file)
- 分支管理(branch management)
- 持久化目录结构(folder structure)
- 命令功能与具体实现
- init
- add
- commit
- rm
- log
- global-log
- find
- status
- checkout
- branch
- rm-branch
- reset
- merge
- add-remote
- rm-remote
- push
- fetch
- pull
- 总结
- github地址
项目简介
gitlet是一个版本控制系统,与git类似,但对git的一些功能做了一些简化,可以看作是低配版的git,支持大多数git支持的功能,比如add/commit等等。在本项目中,系统维护的文件仅考虑当前工作目录下(CWD, current working directory)的子文件,即不包括子文件夹。
该系统支持的功能主要有:
- 提交commit用于维护历史版本,即commit功能
- 将某个历史commit(也可以是某个branch的head)的某个文件(或整个commit’s tracked file set)提取到当前工作目录下,即checkout功能
- 查看历史上的commit信息,即log功能
- 维护多个不同的commit分支,即branch功能
- 把两个分支合并,即merge功能
整体结构
对象概念(object concept)
在gitlet中,两个重要的对象为:
commits: 由timestamp, log message, tracked files set(mapping from filename to blob reference), first parent commit reference, second parent commit reference(for merge)组成
blobs: 由文件名和文件内容组成,由于同一个文件可能有不同的版本,故文件名相同的blobs也可能是不同的对象(内容不同)
每一个对象(commit或blob)都有一个唯一的对象ID(称为UID或SHA-1ID),它由SHA-1哈希函数生成,同类型的不同对象出现哈希冲突的概率极小。于是可以使用UID作为blobs或者commits的文件名,以便于序列化与反序列化操作,也称为持久化(persistence)。当然由于blob对象和commit对象的哈希值可能冲突,于是分为两个文件夹存放。当对象实现持久化后,UID也可作为对象的引用(reference),上面commit中包含的许多reference可以理解为对象的UID。
追踪文件(track file)
与git类似,跟踪(track)一个文件首先需要将其添加进缓存区(staging area for addition),然后在进行commit提交缓存区的文件并清空缓存区。缓存区包含两个区域,for addition和for removal,为了一些命令的方便,addition缓存区个人采用Treemap维护文件名到blob reference的映射,removal缓存区使用文件名的set维护即可(在命令实现部分还会细讲)。
缓存区除了维护文件名到blob reference的映射之外,还需要保存一些临时的blob实体(不然哪来的blob reference),这里是个人理解,因为缓存区的文件状态并不稳定,而我们只关注最终commit时候的文件状态。
分支管理(branch management)
多个分支的维护的用途是方便用户管理多个不同版本的项目,比如项目的A版本作为一个分支,B版本作为另外一个分支,分支间可以来回切换。
系统需要维护分支的每一个头部(branch head),分支头部其实就是某个commit的reference(即UID);同时需要维护一个全局的当前分支头部,以支持某些命令的使用。这部分内容也需要持久化。
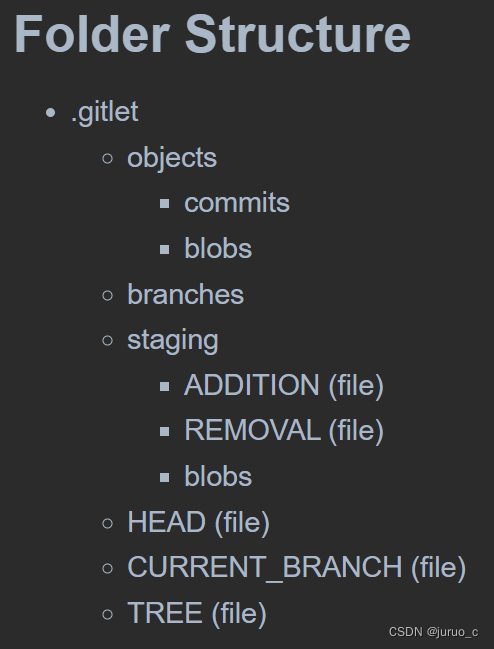
持久化目录结构(folder structure)
如下图所示,在当前工作目录下系统需要创建一个.gitlet文件夹用于存放持久化文件,包括以下子文件(或文件夹):
- objects: 保存commits和blobs两种对象文件
- branches: 保存分支头部文件(如默认的master分支)
- staging: 保存缓存区文件
- HEAD: 保存系统当前commit的UID
- CURRENT_BRANCH: 保存当前所在分支的名字
- TREE: 保存当前的commit集合(由于在写merge之前都以为commit是树形结构所以取名为TREE,后来懒得改了,其实是DAG结构)
命令功能与具体实现
init
命令: java gitlet.Main init
具体功能描述:
在当前工作目录下创建一个用于持久化对象的隐藏目录.gitlet,在该目录下按照上述文件目录结构初始化所有目录与文件。创建一个初始的commit,包含信息initial commit,将头指针HEAD指向该commit。创建一个默认分支master,将该分支的头部也指向该commit。
时间复杂度:
O
(
1
)
O(1)
O(1)
错误提示:
如果在当前目录下已经存在.gitlet目录,即已经在当前工作目录下初始化过,则提示A Gitlet version-control system already exists in the current diretory.
add
命令: java gitlet.Main add [file name]
具体功能描述:
将给定的工作目录文件添加到暂存区中(staging area),由于我将暂存区分为两部分(addition与removal),于是添加到addition中。
如果当前工作目录中该文件的版本与当前HEAD指针指向的commit中该文件的版本一致,则不需要添加至addition;且如果addition中存在该文件,则移除它。(当文件修改之后执行add,又修改回原始版本之后再执行add,则会产生这个情况)。
如果给定文件存在于removal中,则将其从removal中移除。
时间复杂度:
由于我使用TreeMap维护每个commit的tracked files,于是找到commit中该文件的版本需要O(logN)的复杂度(N是该commit的tracked files数量)。
错误提示:
如果所指定的文件在工作目录中并不存在,则提示File does not exist.并退出程序。
commit
命令: java gitlet.Main commit [message]
具体功能描述:
使用message与当前date新创建一个commit,继承HEAD指向的当前commit的所有文件信息。
根据当前addition与removal中的文件,修改新commit中的tracked files。
修改HEAD指针与BRANCH头指针指向的commit。
清空staging area。
时间复杂度:
继承文件信息的复杂度为N(N为HEAD指向commit的tracked files数量);修改tracked files的复杂度为MlogN(M为addition与removal中的文件数量总和);故总复杂度为
O
(
N
+
M
l
o
g
N
)
O(N+MlogN)
O(N+MlogN)
错误提示:
如果staging area(addition与removal)中没有文件,则报错No changes added to the commit.;如果所输入信息为空,则报错Please enter a commit message.。
rm
命令: java gitlet.Main rm [file name]
具体功能描述:
如果所指定文件存在于addition中,则将其从addition中移除。
如果当前文件在当前的commit的tracked files中,则将其添加进removal中,且如果当前文件存在于工作目录中,则将其删除。
时间复杂度:
O
(
l
o
g
N
)
O(logN)
O(logN),
N
N
N为当前commit中文件数量
错误提示:
如果所指定文件不存在于addition中且不存在于当前commit的tracked files中,则报错No reason to remove the file.
log
命令: java gitlet.Main log
具体功能描述:
从HEAD指针指向的commit开始,沿着parent往根走(根就是initial commit),按照一定格式输出commit的信息,忽略second parent(在merge的时候会说到)。
时间复杂度:
O
(
N
)
O(N)
O(N),
N
N
N为路径上的commit数量
global-log
命令: java gitlet.Main global-log
具体功能描述: 与log类似,但是需要输出所有commit的信息,不关心输出的前后顺序。
时间复杂度要求:
O
(
N
)
O(N)
O(N),
N
N
N为当前系统中所有的commit数量
find
命令: java gitlet.Main find [commit message]
具体功能描述:
根据给出的commit message,输出拥有该信息的所有commit id。
时间复杂度要求:
O
(
N
)
O(N)
O(N),
N
N
N为当前系统中所有的commit数量
错误提示:
所有未找到满足条件的commit,则报错Found no commit with that message.
status
命令: java gitlet.Main status
具体功能描述:
按照指定格式输出当前的几个信息,包括Branches,Staged Files,Removed Files,Modifications Not Staged For Commit和Untracked Files(均按照字典序升序排序)。
其中,Branches中当前分支前面需要加个*,Staged Files和Removed Files分别表示暂存区中标志添加或删除的文件名(即addition和removal中的文件)。
具体实现起来也不复杂,由于已经持久化了Branch、addition和removal的集合,直接遍历输出即可。
剩下两个信息虽然是extra的,但是比较容易实现就顺便讲一讲。
一个文件是modified but not staged当且仅当它满足一下任意一个条件:
- 在当前的commit中被追踪(tracked),且在当前的工作目录下被修改但为添加到addition中;
- 在当前的commit中被追踪(tracked),且在当前工作目录下被删除但未添加到removal中;
- 已经添加到addition中,但是addition中该文件的内容与当前工作目录下的不同;
- 已经添加到addition中,但是在当前工作目录下被用户删除。
如果一个文件存在于当前工作目录中,但是既没有被当前的commit所追踪(tracked),又没有被添加到addition中,那么它属于Untracked Files。
extra的实现,个人是遍历了工作目录、addition还有当前commit的tracked files中的所有文件,判断是否满足上述条件。
时间复杂度要求:
O
(
N
+
M
+
K
)
O(N+M+K)
O(N+M+K),其中
N
N
N为分支数,
M
M
M为当前工作目录下的文件数,
K
K
K为addition和removal中的文件数量。(该复杂度未考虑extra的内容)
错误提示: 无错误
checkout
命令:
1.java gitlet.Main checkout -- [file name]
2.java gitlet.Main checkout [commit id] -- [file name]
3.java gitlet.Main checkout [branch name]
具体功能描述:
时间复杂度要求:
错误提示:
branch
命令: java gitlet.Main status
具体功能描述:
时间复杂度要求:
错误提示:
rm-branch
命令: java gitlet.Main status
具体功能描述:
时间复杂度要求:
错误提示:
reset
命令: java gitlet.Main status
具体功能描述:
时间复杂度要求:
错误提示:
merge
命令: java gitlet.Main status
具体功能描述:
时间复杂度要求:
错误提示:
add-remote
待更
rm-remote
待更
push
待更
fetch
待更
pull
待更
总结
基本熟悉了git的使用方法以及实现原理;其实总体实现起来并不是特别的困难,跟着文档走基本上都没啥太大问题,主要是一开始不知道从何入手,主要是不知如何设计.gitlet文件夹的结构,参考了git的设计之后其实也就解决了这个问题,万事开头难,开始写代码就容易起来了。
这个项目应该是我写代码以来注释写的最多的项目了,因为怕写着写着忘了(虽然说最后注释对我而言也没啥用处),之后其实不用写太多注释。
github地址
CS61B Spring 2021 GitLet