本文主要从我们为什么需要CR?CR面临哪些挑战?CR的最佳实践几个方面分析,希望可以给读者一些参考。为什么需要CR?
代码质量
定性来看,大家都认可Code Review(后文简称CR)能显著改善代码质量,但国内量化的研究结果比较少,以下引用业界比较知名的几个定量研究结果:
Capers Jones分析了超过12,000个软件开发项目,其中使用正式代码审查的项目,潜在缺陷发现率约在60-65%之间;大部分的测试,潜在缺陷发现率仅在30%左右。
Steve McConnel在《Code Complete》中提到:仅仅依靠软件测试效能有限–单测平均缺陷发现率只有25%,功能测试35%,集成测试45%,相反,设计和代码审查可以达到55%到60%。
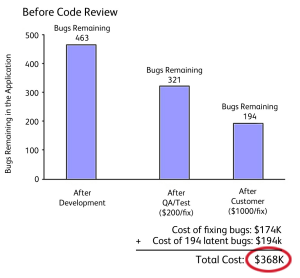
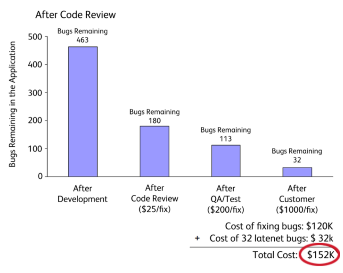
SmartBear研究了一个历时3月,包括10名开发人员完成的10,000行代码的工程,通过引入CR在接下来的6个月中可以节省近6成的bug修复成本。
技术交流
SmartBear研究报告中这段话比较能表达CR对技术交流的价值,引用如下:
Actually writing the source code, however, is a solitary activity. Since developers tend to create code in quiet places, collaboration is limited to occasional whiteboard drawings and a few shared interfaces. No one catches the obvious bugs; no one is making sure the documentation matches the code. Peer code review puts the collaborative element back into this phase of the software development process.
Google认为CR参与塑造了公司的工程师文化,CR也与笔者所在部门一贯倡导的「极致透明」的文化相契合,资深同学的CR,对团队内新人的快速成长也很有帮助。
卓越工程
Linux的创始人Linus Torvalds有句名言:Talk is cheap, Show me the code,代码是程序员的作品,CR只是一种提升代码质量的工具,敢于Show出自己的代码,并用开放的心态去优化完善,才是每个程序员审视自我,从优秀到卓越的关键所在。
既然CR好处这么多,大多团队也在实践,但为什么效果差强人意呢,主要是CR在大型项目实践中面临诸多挑战。
CR面临哪些挑战?
挑战1:CR的代码改动范围过大
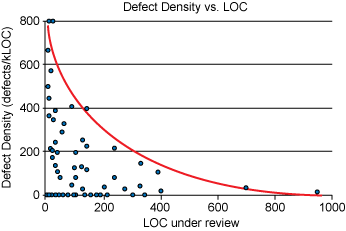
笔者观察,很多项目落实CR的最大挑战是项目进度压力很大,发布计划倒排根本没有给CR预留时间,所以大部分CR是在临近提测前(甚至有些是边测试边进行)集中进行,面对动辄上千行的代码变动,评审者需要花大量时间和代码提交者交流了解业务逻辑,迫于时间压力大多只会检查最基本的编码规范问题,而没有达到CR预期的效果。SmartBear公司对 CR 节奏的研究指出:每次大于400行的CR每千行代码缺陷发现率几乎为零。
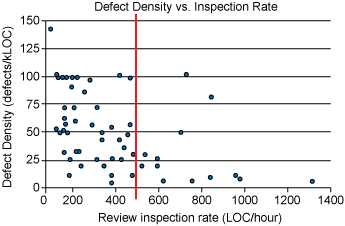
那么怎样的提交粒度比较合适呢?笔者的经验是和单元测试case匹配(这里问题来了,没时间写单元测试怎么办,本文姊妹篇再来聊聊单元测试),完成一个功能,跑一个单元测试验证逻辑,然后commit一次。如下图,Aone(阿里内部的研发平台)提供的功能内置支持按照提交版本分批DIFF,分批Review。
挑战2:CR对评审者全局知识要求很高
CR一般由团队内资深的技术同学进行,对于大型复杂项目的CR需要评审者对编码规范、分布式架构设计原则、业务知识有全面的了解,举个例子,下面是某服务提供的等级查询接口关键代码CR片段:
- public Level queryLevel(LevelQueryRequest request) {
+ public Level queryLevelWithExpireRefresh(LevelQueryRequest request) {
Level result = levelRepository.findLevelWithoutInit(request.getId());
if (null == result || isExpired(result.getEndTime())) {
// 如果等级为空,兜底返回L0;等级已过期,实时返回默认等级,并异步刷新
if (result == null) {
result = levelRepository.buildInitLevel(request.getId(), LevelEnum.L0);
}
//查询为空,或者已过期发送消息,刷新等级
- LevelRefreshRequest refreshRequest = buildRefreshRequest(request);
- levelWriteService.refreshLevel(message.getId(), refreshRequest);
+ RefreshMessage refreshMessage = buildRefreshMessage(request);
+ refreshMessageProducer.sendMessage(refreshMessage);
}
return result;
}- public class RefreshMessageListener extends AbstractMessageListener {
+ public class RefreshMessageListener extends AbstractOrderlyMessageListener {
@Autowired
- private LevelWriteService levelWriteService;
+ private LevelWriteRegionalService levelWriteRegionalService;
@Override
protected boolean process(String tags, String msgId, String receivedMsg) {
RefreshMessage message = JSON.parseObject(receivedMsg, RefreshMessage.class);
if (message == null || message.getId() == null) {
log.warn("message is invalid, ignored, src={}", receivedMsg);
return true;
}
LevelRefreshRequest refreshRequest = buildRefreshRequest(message);
- levelWriteService.refreshLevel(message.getId(), refreshRequest);
+ levelWriteRegionalService.refreshLevel(message.getId(), refreshRequest);
return true;
}
}面对上面代码改动,要进行富有成效的CR,下面是代码评审者必须掌握的业务和技术知识:
-
为什么存在等级为空的情况?
-
为什么要设计成读时写?
-
为什么不是直接计算等级,而需要用消息队列?
-
为什么要用Regional(区域化)接口和有序消息刷新等级?
挑战3:CR价值最大化需要团队具备卓越工程基因
前文提到CR有助于团队内的技术交流,下面是几个笔者亲历的Case,通过对典型CR问题的广泛讨论不仅提升了业务代码的质量,而且探索到了技术创新点,逐步建立起团队追求技术卓越的氛围:
CASE1:一个业务使用3个时间穿越开关
背景
时间穿越是营销类业务系统最常使用的工具之一,通过全局控制,可以提前测试某个在未来开始的业务功能。笔者接触到的一个业务由2个服务A、B组成,A是一个老应用,使用了一个开关,后来B又在不同业务场景中使用了2个新的开关,在一次CR中发现了一个业务重复使用3个不同开关的问题,由此展开了一次讨论。
private static final String CODE = "BENEFIT_TIME_THROUGH";
public Date driftedNow(String userId) {
try {
TimeMockResult<Long> result = timeThroughService.getFutureTime(CODE, userId);
if (result.isSuccess()) {
return new Date(result.getData());
}
} catch (Throwable t) {
log.error("timeThroughService error. userId={}", userId, t);
}
return new Date();
}观点1:彻底服务化
按照DRY(Don't Repeat Yourself)原则,最理想的方案是把该业务用到的时间穿越开关统一由一个服务提供,因为时间穿越工具是借助动态配置中心推送开关到本地,然后做内存计算;如果统一成服务后,A和B都需要依赖远程服务调用,而B是一个高并发的使用场景,会有较大性能损耗。
观点2:富客户端
把统一开关包装成一个三方库,独立提供jar包供A、B服务分别依赖,这样解决了前面方案的性能消耗问题。但两个应用需要同步做更新和升级。
观点3:配置统一,重复代码三处收拢为两处
该观点认为彻底服务化和富客户端属于两种极端,可以采取折中方案容忍部分代码重复,但使用相同的时间穿越开关。
总结:
这个Case的讨论涉及到一个公共逻辑抽取的方案权衡问题,进程内调用的富客户端性能损耗低,但后期维护和升级困难,而且过于复杂的客户端逻辑容易引发依赖方包冲突、启动耗时增加等问题;彻底服务化只需要保持接口契约一致可以实现较快迭代,但对服务提供者SLA要求高;为了平衡前两者的问题,微服务架构中的SideCar模式则是在功能性的应用容器旁部署另一个非功能性容器,使得开发团队可以对主应用和SideCar进行独立管理。关于这个问题网上有很多讨论内容读者可以进一步了解学习。
CASE2:SSR(服务端渲染)API稳定性优化
背景

上图是一个典型的服务端渲染服务架构,SSR服务通过加载配置,对每个模块进行独立数据组装,并整体返回结果到端侧。一般应用在电商系统复杂只读页面的动态搭建,如首页、商品详情页、导购频道等。下面是组装数据部分的待评审代码片段。
// 提交任务
ioTaskList.stream().forEach(t -> futures.add(pool.submit(() -> t.service.invoke())));
// 阻塞获取任务结果
futures.stream().forEach(f -> {
try {
result.add(f.get());
} catch (Exception e) {
log.error(e.getMessage(), e);
}
});Step1:增加固定超时控制
// 提交任务
ioTaskList.stream().forEach(t -> futures.add(pool.submit(() -> t.service.invoke())));
// 阻塞获取任务结果
futures.stream().forEach(f -> {
try {
- result.add(f.get());
+ result.add(f.get(1000, TimeUnit.MICROSECONDS));
} catch (Exception e) {
log.error(e.getMessage(), e);
}
});Step2:自适应超时控制
public abstract class BaseService<T> implements Service {
@Override
public T invoke(ServiceContext context) {
Entry entry = null;
try {
// 根据service类别构造降级资源
String resourceName = "RESOURCE_" + name();
entry = SphU.entry(resourceName);
try {
// 未触发降级,正常调用后端服务
return realInvoke(context);
} catch (Exception e) {
// 业务异常,记录错误日志,返回出错信息
return failureResult(context);
}
} catch (BlockException e) {
// 被降级,可以fail fast或返回兜底数据
return degradeResult(context);
} finally {
entry.exit();
}
}
public abstract T realInvoke();
}Step3:自适应超时控制+自定义资源key
public abstract class BaseService<T> implements Service {
@Override
public T invoke(ServiceContext context) {
Entry entry = null;
try {
// 这里的key由service实现,融合了服务类型和自定义key构造降级资源
String resourceName = "RESOURCE_" + key(context);
entry = SphU.entry(resourceName);
try {
// 未触发降级,正常调用后端服务
return realInvoke(context);
} catch (Exception e) {
// 业务异常,记录错误日志,返回出错信息
return failureResult(context);
}
} catch (BlockException e) {
// 被降级,可以fail fast或返回兜底数据
return degradeResult(context);
} finally {
entry.exit();
}
}
public abstract String key(ServiceContext context);
public abstract T realInvoke();
}总结:
Step1很容易理解,增加1000ms超时设置可以避免某个数据源严重超时导致整个渲染API不稳定,做到fail fast,但核心挑战在于多长的超时时间算合理;Step2通过依赖降级组件,根据不同数据源服务设置不同超时时间,实现了自适应超时控制;Step3相比Step2改动非常小,不了解业务背景可能不清楚它们的区别,Step2的降级控制作用在服务类别上,比如营销服务、推荐服务各自触发降级,但还有一类数据源服务其实是网关类型,内部耗时会根据某个或某些参数不同有较大差异,例如TPP(阿里内部的算法平台,不同算法逻辑共享一个网关API,但不同算法复杂度耗时差异巨大)服务就是一个典型,所以Step3允许自定义key()实现更精细的超时控制。
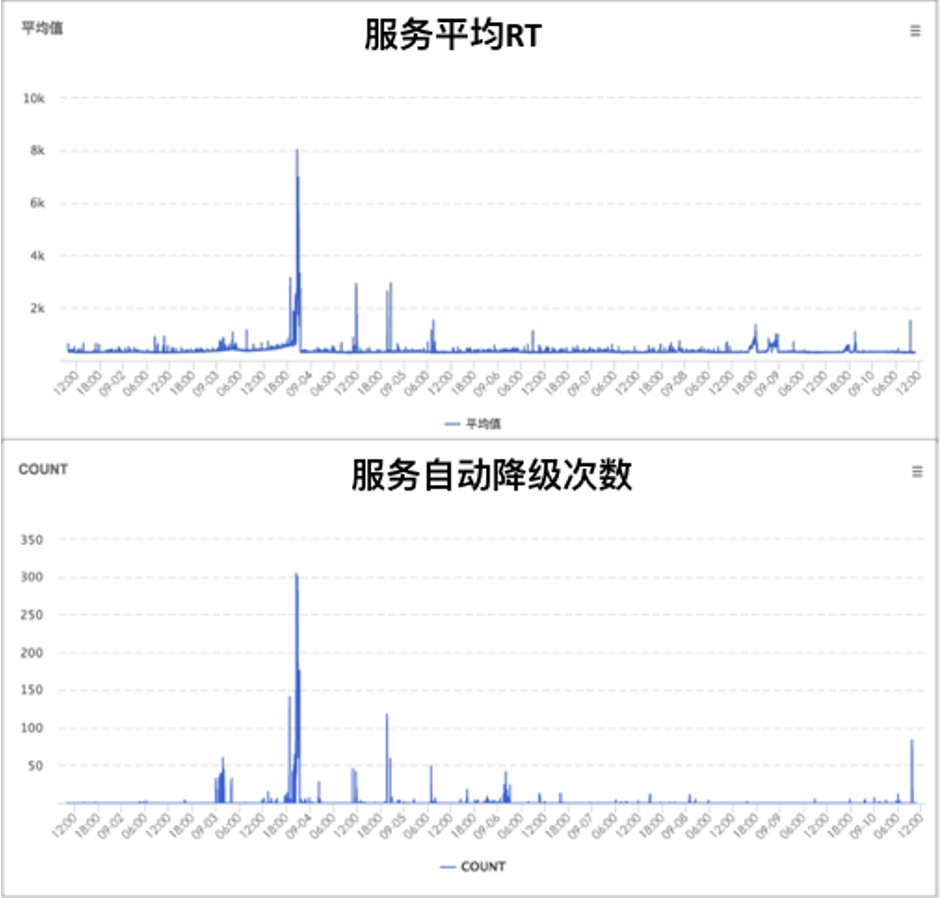
团队由CR引发的技术深入讨论和持续优化形成了这套自动化降级能力,上图是实际线上运行效果,可以看到系统随着依赖数据源服务RT的抖动实现了自动化自适应降级和恢复。
CR有没有最佳实践?
Code Review的边界
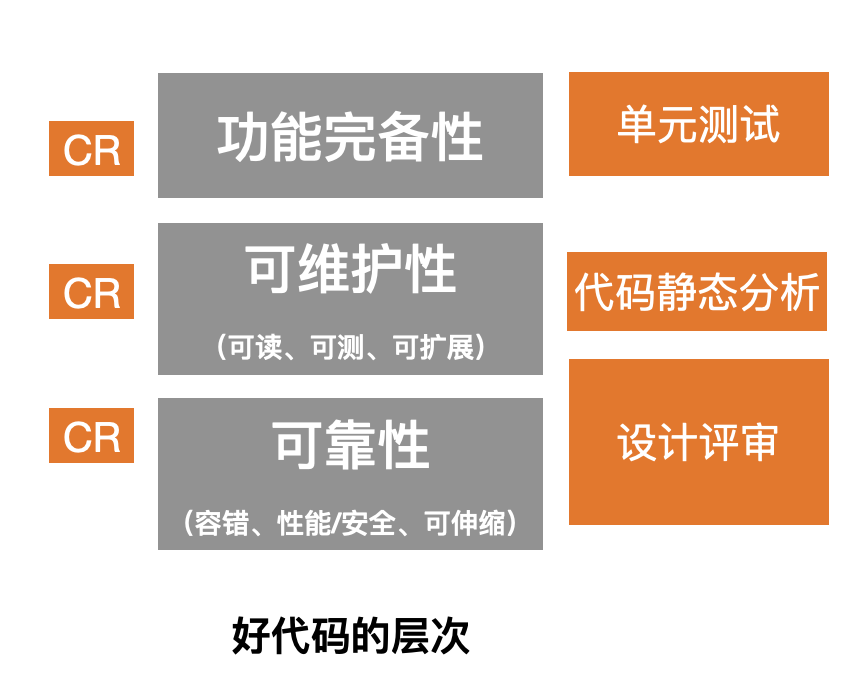
对于什么是一个好代码,上图从可靠、可维护和功能完备做了划分。笔者认为CR并非包治百病的银弹,它也有它的能力边界。把设计方案交给设计评审,把业务逻辑验证交给单测;把编码规范交给静态代码扫描(Static Code Analysis),剩下部分再由Peer Review做最后一道把关。CR引发的技术传承、技术交流以及由此形成的追求卓越的团队文化,才是它的最大价值。
出发点:程序员的初心
归根结底,程序员的好奇心和匠心才是提升代码质量的根本,目前笔者所在部门已经在晋升考核中增加了CR环节,烂代码会被一票否决,这就需要日常工作中不断追求技术卓越,在平时多下功夫。
看不见的手:自动代码扫描
之前在某社区看到有个热帖讨论程序员的工作是不是劳动密集型,某个回帖比较形象「我们的工作本应是CPU密集型,结果却成了IO密集型」。基本的编码规范完全可以借助代码自动化扫描识别,而这个占比也是比较高,可以有效降低CR成本。业界的CheckStyle、FindBug都有完善的CI/CD插件支持,阿里云也提供了IDE智能编码插件,内置了编码规范支持。
看得见的手:Team Leader的重视
喊口号没有用,只有躬身入局。身边几位参加晋升同学CR的评审官普遍感受是:代码质量分布通常会团队化,不要指望个别优秀的同学带动团队的整体水平提升。确实如此,代码质量需要Team Leader高频参与CR,技术文化的形成需要主管以身作则。
以下是我收集到的比较好的学习教程资源,虽然不是什么很值钱的东西,如果你刚好需要,可以评论区,留言【777】直接拿走就好了


各位想获取资料的朋友请点赞 + 评论 + 收藏,三连!
三连之后我会在评论区挨个私信发给你们~