目录
(1)为什么Gem是Python和C++混合使用编程?
(2)关于析构函数
创建类的时候一般都需要写上析构函数吗?
(3)关于HelloObject和GoodbyeObject的先后后创建关系
(1)为什么Gem是Python和C++混合使用编程?
Gem5使用Python和C++混合编程主要是为了利用两种语言的优势。由于Python是一种高级语言,它非常适合用于编写配置和控制模拟器运行参数的脚本。它具有易于阅读和理解的语法,可以快速开发和测试代码。另一方面,C ++是一种高性能的编程语言,比Python更快,因此适用于编写Gem5中的复杂模拟模型。使用Python和C++混合编程的方式,可以在满足性能要求的同时,充分利用两种语言的优势,实现更高效的模拟器开发。
在Gem5中,通常用Python编写用于配置模拟器运行参数和控制模拟过程的脚本。用C++编写SimObjects(即模拟中的对象)及其行为。在这种情况下,你可以在Python中编写一个类,它调用C ++中的构造函数来创建一个新的SimObject(通过类名+Pramas的方式传递对象指针)。然后,你可以使用Python脚本来配置这个SimObject的参数并控制它的行为。
举例来说,通过Python脚本,可以通过Root对象来创建处理器、存储器、I / O设备等模拟对象,并将它们连接到一起以完成模拟。你可以将Python的工作类比为将各个零件串起来并让它们协同工作,而C++的工作则类似于编写零件的具体功能,提供模拟的基础。因此,通过Python和C++的混合编程方式,Gem5可以实现更高效和更灵活的模拟器开发。
(2)关于析构函数
#ifndef __LEARNING_GEM5_GOODBYE_OBJECT_HH__
#define __LEARNING_GEM5_GOODBYE_OBJECT_HH__
#include <string>
#include "params/GoodbyeObject.hh"
#include "sim/sim_object.hh"
class GoodbyeObject : public SimObject
{
private:
void processEvent();
/**
* Fills the buffer for one iteration. If the buffer isn't full, this
* function will enqueue another event to continue filling.
*/
void fillBuffer();
EventWrapper<GoodbyeObject, &GoodbyeObject::processEvent> event;
/// The bytes processed per tick
float bandwidth;
/// The size of the buffer we are going to fill
int bufferSize;
/// The buffer we are putting our message in
char *buffer;
/// The message to put into the buffer.
std::string message;
/// The amount of the buffer we've used so far.
int bufferUsed;
public:
GoodbyeObject(GoodbyeObjectParams *p);
~GoodbyeObject();
void sayGoodbye(std::string name);
};
#endif // __LEARNING_GEM5_GOODBYE_OBJECT_HH__GoodbyeObject(GoodbyeObjectParams *p)和~GoodbyeObject()都是GoodbyeObject类的成员函数,但它们有一个重要的区别。GoodbyeObject(GoodbyeObjectParams *p)是一个构造函数,用来创建新的GoodbyeObject实例。它接受一个指向GoodbyeObjectParams类型的指针作为参数,并使用这个参数来初始化新创建的实例。
相反,~GoodbyeObject()是一个析构函数。它的作用是在销毁GoodbyeObject实例时释放实例所占用的资源。析构函数的名字是一个类名后面跟着一个波浪符号~。析构函数不能有参数,也不能有返回值。它在每个实例被销毁时自动调用,因此你不需要手动调用它。
创建类的时候一般都需要写上析构函数吗?
你可以不写析构函数,如果不写,编译器会自动为你生成一个默认的析构函数。但是,如果你的类包含了动态分配的内存或者其他需要释放的资源,那么就需要写一个析构函数来释放这些资源。例如,如果你的类包含了一个指向另一个对象的指针,那么在析构函数中就需要手动释放这个指针指向的对象。在官网GoodbyeObject这个例子中,是自动分配空间的,故需要析构函数,具体如下:
GoodbyeObject::GoodbyeObject(const GoodbyeObjectParams ¶ms) :
SimObject(params), event(*this), bandwidth(params.write_bandwidth),
bufferSize(params.buffer_size), buffer(nullptr), bufferUsed(0)
{
buffer = new char[bufferSize];
DPRINTF(Hello, "Created the goodbye object\n");
}
GoodbyeObject::~GoodbyeObject()
{
delete[] buffer;
}(3)关于HelloObject和GoodbyeObject的先后后创建关系
我看代码的时候一直没有看懂一个点,在这里记录一下,官网的控制脚本如下:
import m5
from m5.objects import *
root = Root(full_system = False)
root.hello = HelloObject(time_to_wait = '2us', number_of_fires = 5)
root.hello.goodbye_object = GoodbyeObject(buffer_size='100B')
m5.instantiate()
print("Beginning simulation!")
exit_event = m5.simulate()
print('Exiting @ tick %i because %s' % (m5.curTick(), exit_event.getCause()))按照我之前的理解,明明HelloObject对象比GodbyeObject先创建,为什么输出长这样?
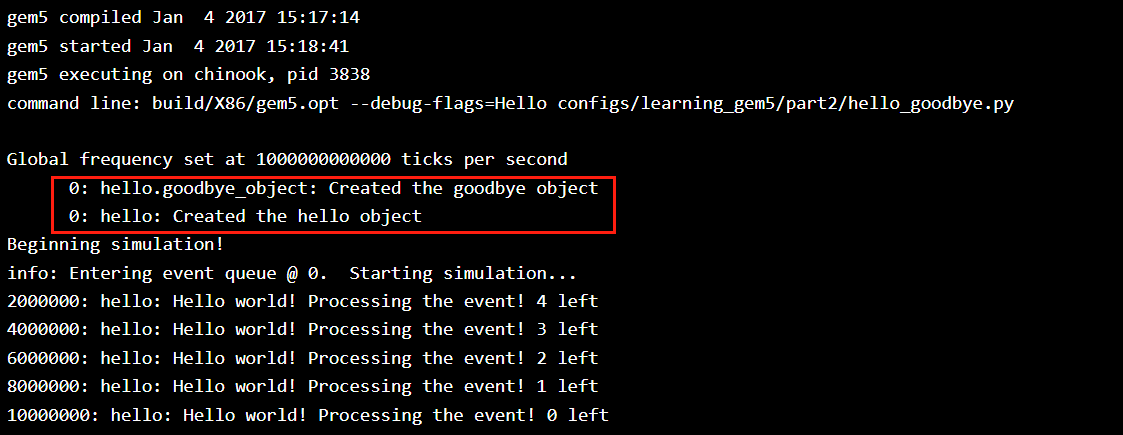
从输出看,GoogbyeObject比HelloObject先构建,why?
实际上,实例化对象是在调用 m5.instantiate() 函数时进行的。在这之前,代码只是创建了一些对象的定义,但是它们还没有真正被实例化。实例化对象意味着在内存中为这些对象分配空间,并初始化它们的状态。这意味着实例化对象后,这些对象才能真正被使用,并开始执行它们的逻辑。
在这段代码中,可以看到 HelloObject的构造函数中包含一行 goodbye(params.goodbye_object),这行代码使用了一个 GoogbyeObject对象的参数来创建一个新的 GoogbyeObject对象。这就表明,在实例化一个 HelloObject对象时,它的构造函数会创建一个 GoogbyeObject对象。所以,实际上,在实例化 HelloObject对象之前,会先实例化一个 GoogbyeObject对象。这也就是为什么在你的输出中先出现了 GoogbyeObject对象的原因。
HelloObject::HelloObject(HelloObjectParams ¶ms) :
SimObject(params),
event(*this),
goodbye(params.goodbye_object),
myName(params.name),
latency(params.time_to_wait),
timesLeft(params.number_of_fires)
{
DPRINTF(Hello, "Created the hello object with the name %s\n", myName);
panic_if(!goodbye, "HelloObject must have a non-null GoodbyeObject");
}







![[附源码]计算机毕业设计高校实验室仪器设备管理系统Springboot程序](https://img-blog.csdnimg.cn/8210a349a7264df78c15ac9e589c3507.png)


![[附源码]Node.js计算机毕业设计大学校园二手教材与书籍Express](https://img-blog.csdnimg.cn/3a2ab7308b65488088dfdebbb1335bc9.png)