Pod使用进阶

封面

写在前面
语雀上阅读效果更佳,请访问如下地址:
197 Pod使用进阶 · 语雀 《197 Pod使用进阶》
1、Pod 资源配置
实际上上面几个步骤就是影响一个 Pod 生命周期的大的部分,但是还有一些细节也会在 Pod 的启动过程进行设置,比如在容器启动之前还会为当前的容器设置分配的 CPU、内存等资源。我们知道我们可以通过 CGroup 来对容器的资源进行限制,同样的,在 Pod 中我们也可以直接配置某个容器的使用的 CPU 或者内存的上限。那么 Pod 是如何来使用和控制这些资源的分配的呢?
首先对于 CPU,我们知道计算机里 CPU 的资源是按“时间片”的方式来进行分配的,系统里的每一个操作都需要 CPU 的处理,所以,哪个任务要是申请的 CPU 时间片越多,那么它得到的 CPU 资源就越多,这个很容器理解。
CPU 资源是以 CPU 单位度量的,Kubernetes 中的而一个 CPU 等同于:
- 1 个 AWS vCPU
- 1 个 GCP 核心
- 1 个 Azure vCore
- 裸机上具有超线程能力的英特尔处理器上的 1 个超线程
小数值也是可以使用的,一个请求 0.5 CPU 的容器会获得请求 1 个 CPU 的容器的 CPU 的一半。我们也可以使用后缀m 表示毫,例如 100m CPU、 100 milliCPU 和 0.1 CPU 都相同,需要注意精度不能超过 1m。
然后还需要了解下 CGroup 里面对于 CPU 资源的单位换算:
100m CPU、 100 milliCPU 和 0.1 CPU 都相同 1 CPU = 1000 millicpu(1 Core = 1000m) 0.5 CPU = 500 millicpu (0.5 Core = 500m)
CPU 请求只能使用绝对数量,而不是相对数量。0.1 在单核、双核或 48 核计算机上的 CPU 数量值是一样的。
Kubernetes 集群中的每一个节点可以通过操作系统的命令来确认本节点的 CPU 内核数量,然后将这个数量乘以 1000,得到的就是节点总 CPU 总毫数。比如一个节点有四核,那么该节点的 CPU 总毫量为 4000m,如果你要使用一半的 CPU,则你要求的是 4000 * 0.5 = 2000m 。在 Pod 里面我们可以通过下面的两个参数来限制和请求 CPU 资源:
- spec.containers[].resources.limits.cpu:CPU 上限值,可以短暂超过,容器也不会被停止
- spec.containers[].resources.requests.cpu:CPU 请求值,Kubernetes 调度算法里的依据值,可以超过
这里需要明白的是,如果 resources.requests.cpu 设置的值大于集群里每个节点的最大可用 CPU 核心数,那么这个Pod 将无法调度,因为没有节点能满足它。
到这里应该明白了,requests 是用于集群调度使用的资源,而 limits 才是真正的用于资源限制的配置。如果你需要保证的你应用优先级很高,也就是资源吃紧的情况下最后再杀掉你的 Pod,那么可以将 requests 和 limits 的值设置成一致,在后面服务质量章节的时候会具体讲解。
注意:并不会实际吃掉这么多资源的:

💘 实战:pod资源限制-2022.12.11(成功测试)
- 实验环境
1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点 k8s version:v1.20 CONTAINER-RUNTIME:containerd:v1.6.10
- 实验软件(无)
- 比如,现在我们定义一个 Pod,给容器的配置如下的资源:
vim pod-resource-demo1.yaml
# pod-resource-demo1.yaml
apiVersion: v1
kind: Pod
metadata:
name: resource-demo1
spec:
containers:
- name: resource-demo1
image: nginx
ports:
- containerPort: 80
resources: #这个是给调度器使用的;
requests:
memory: 50Mi
cpu: 50m
limits:
memory: 100Mi
cpu: 100m
这里,CPU 我们给的是 50m,也就是 0.05core,这 0.05core 也就是占了 1 CPU 里的 5% 的资源时间。而限制资源是给的是 100m,但是需要注意的是 CPU 资源是可压缩资源,也就是容器达到了这个设定的上限后,容器性能会下降,但是不会终止或退出。
- 比如我们直接创建上面这个 Pod:
[root@master1 ~]#kubectl apply -f resource-demo1.yaml pod/resource-demo1 created
- 创建完成后,我们可以看到 Pod 被调度到 node2 这个节点上:
[root@master1 ~]#kubectl get po -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES resource-demo1 1/1 Running 0 42s 10.244.2.9 node2 <none> <none> [root@master1 ~]#
- 然后我们到 node2 节点上去查看 Pod 里面启动的
resource-demo1这个容器:
[root@node2 ~]#crictl ps #查看当前节点pod信息 CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID bcbbf88a9ac29 87a94228f133e 3 minutes ago Running resource-demo1 0 0f2511f4b7567
- 我们可以去查看下主容器的信息:
➜ ~ crictl inspect bcbbf88a9ac29 #哈哈,这个crictl命令也可以直接来看容器的详细信息的……
"status": {
"id": "bcbbf88a9ac29d84700525b4c898171889510b372b45a77f1c9757fdef3793a2",
"metadata": {
"attempt": 0,
"name": "resource-demo1"
},
"state": "CONTAINER_RUNNING",
"createdAt": "2021-11-07T16:46:37.069325484+08:00",
"startedAt": "2021-11-07T16:46:37.412557847+08:00",
"finishedAt": "0001-01-01T00:00:00Z",
"exitCode": 0,
"image": {
"annotations": {},
"image": "docker.io/library/nginx:latest"
},
......
"linux": {
"resources": {
"devices": [
{
"allow": false,
"access": "rwm"
}
],
"memory": {
"limit": 104857600 #注意
},
"cpu": {
"shares": 51,
"quota": 10000, #注意
"period": 100000
}
},
"cgroupsPath": "kubepods-burstable-pod7e80487d_24d7_44af_bf38_c43b6dfe4045.slice:cri-containerd:bcbbf88a9ac29d84700525b4c898171889510b372b45a77f1c9757fdef3793a2",
......
实际上我们就可以看到这个容器的一些资源情况,Pod 上的资源配置最终也还是通过底层的容器运行时去控制 CGroup 来实现的,我们可以进入如下目录查看 CGroup 的配置,该目录就是 CGroup 父级目录,而 CGroup 是通过文件系统来进行资源限制的,所以我们上面限制容器的资源就可以在该目录下面反映出来:

[root@node2 ~]#cd /sys/fs/cgroup/cpu/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod7e80487d_24d7_44af_bf38_c43b6dfe4045.slice/ [root@node2 kubepods-burstable-pod7e80487d_24d7_44af_bf38_c43b6dfe4045.slice]#ls cgroup.clone_children cpuacct.usage cpu.rt_period_us cri-containerd-0f2511f4b75676145584aa6379a933d65d0e531a500e6697a1998bfb1b0b7d9d.scope cgroup.event_control cpuacct.usage_percpu cpu.rt_runtime_us cri-containerd-bcbbf88a9ac29d84700525b4c898171889510b372b45a77f1c9757fdef3793a2.scope cgroup.procs cpu.cfs_period_us cpu.shares notify_on_release cpuacct.stat cpu.cfs_quota_us cpu.stat tasks [root@node2 kubepods-burstable-pod7e80487d_24d7_44af_bf38_c43b6dfe4045.slice]#cat cpu.cfs_quota_us 10000 #1/10的比例; [root@node2 kubepods-burstable-pod7e80487d_24d7_44af_bf38_c43b6dfe4045.slice]#cat cpu.cfs_period_us 100000 [root@node2 kubepods-burstable-pod7e80487d_24d7_44af_bf38_c43b6dfe4045.slice]#
注意这里的比值计算:
yaml文件里给的spec.containers.resources.limits.cpu=100m(100毫核=0.1c,即1c里面的0.1c,和cgroups里面的比值为:10000/100000=1/10的比值一致。而这个计算值就是spec.containers[].resources.limits.cpu的数值了。
其中 cpu.cfs_quota_us 就是 CPU 的限制值,如果要查看具体的容器的内存资源,我们也可以进入到容器目录下面去查看即可。
[root@node2 ~]#cat /sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod7e80487d_24d7_44af_bf38_c43b6dfe4045.slice/memory.limit_in_bytes #limits 104857600 [root@node2 ~]#
最后我们了解下内存这块的资源控制,内存的单位换算比较简单:
1 MiB = 1024 KiB,内存这块在 Kubernetes 里一般用的是Mi单位,当然你也可以使用Ki、Gi甚至Pi,看具体的业务需求和资源容量。
这里注意的是MiB ≠ MB,MB 是十进制单位,MiB 是二进制,平时我们以为 MB 等于 1024KB,其实1MB=1000KB,1MiB才等于1024KiB。中间带字母 i 的是国际电工协会(IEC)定的,走1024乘积;KB、MB、GB 是国际单位制,走1000乘积。
这里要注意的是,内存是不可压缩性资源,如果容器使用内存资源到达了上限,那么会OOM,造成内存溢出,容器就会终止和退出(然后kublet会根据pod的重启策略对pod进行重启),我们也可以通过上面的方式去通过查看 CGroup 文件的值来验证资源限制。
1.超过容器限制的内存
当节点拥有足够的可用内存时,容器可以使用其请求的内存。但是,容器不允许使用超过其限制的内存。如果容器分配的内存超过其限制,该容器会成为被终止的候选容器,如果容器继续消耗超出其限制的内存,则终止容器。如果终止的容器可以被重启,则 kubelet 会重新启动它,就像其他任何类型的运行时失败一样。
💘 实战:超过容器限制的内存-2022.12.12(成功测试)
- 实验环境
1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点 k8s version:v1.20 CONTAINER-RUNTIME:containerd:v1.6.10
- 实验软件(无)
如下所示我们创建一个 Pod,尝试分配超出其限制的内存,该容器的内存请求为 50 MiB ,内存限制为 100 MiB:
- 编写资源清单文件
# memory-request-limit-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-1
spec:
containers:
- name: memory-demo-1-ctr
image: polinux/stress
resources:
requests:
memory: "50Mi"
limits:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
在上面资源清单文件的 args 部分中的配置,表示该容器会尝试使用 250 MiB 的内存,这远高于我们声明的 100 MiB的限制。
- 我们直接应用上面的资源对象来查看下会出现什么状态:
[root@master1 ~]#kubectl apply -f memory-request-limit-1.yaml pod/memory-demo-1 created
- 创建后查看 Pod 的详细信息:
此时,容器可能正在运行或被杀死。重复前面的命令,直到容器被杀掉:
[root@master1 ~]#kubectl get pod memory-demo-1 -w NAME READY STATUS RESTARTS AGE memory-demo-1 0/1 ContainerCreating 0 11s memory-demo-1 1/1 Running 0 18s memory-demo-1 0/1 OOMKilled 0 19s memory-demo-1 0/1 OOMKilled 1 (16s ago) 35s memory-demo-1 0/1 CrashLoopBackOff 1 (1s ago) 36s memory-demo-1 0/1 OOMKilled 2 (28s ago) 63s memory-demo-1 0/1 CrashLoopBackOff 2 (14s ago) 77s ……
- 获取容器更详细的状态信息,可以看出由于内存溢出(OOM),容器已被杀掉:
^C[root@master1 ~]#kubectl describe po memory-demo-1
Name: memory-demo-1
Namespace: default
Priority: 0
Service Account: default
Node: node2/172.29.9.63
Start Time: Mon, 12 Dec 2022 06:50:26 +0800
Labels: <none>
Annotations: <none>
Status: Running
IP: 10.244.2.10
IPs:
IP: 10.244.2.10
Containers:
memory-demo-1-ctr:
Container ID: containerd://d31aa0f9aed33c4ed78475d0732f0d14d3e020fa4634936f972e676acab3457f
Image: polinux/stress
Image ID: docker.io/polinux/stress@sha256:b6144f84f9c15dac80deb48d3a646b55c7043ab1d83ea0a697c09097aaad21aa
Port: <none>
Host Port: <none>
Command:
stress
Args:
--vm
1
--vm-bytes
250M
--vm-hang
1
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: OOMKilled #注意。。
Exit Code: 1
Started: Mon, 12 Dec 2022 06:52:13 +0800
Finished: Mon, 12 Dec 2022 06:52:13 +0800
Ready: False
Restart Count: 3
Limits:
memory: 100Mi
Requests:
memory: 50Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-h7hqq (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
kube-api-access-h7hqq:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m11s default-scheduler Successfully assigned default/memory-demo-1 to node2
Normal Pulled 113s kubelet Successfully pulled image "polinux/stress" in 17.452971269s
Normal Pulled 97s kubelet Successfully pulled image "polinux/stress" in 15.195719394s
Normal Pulled 69s kubelet Successfully pulled image "polinux/stress" in 15.197205577s
Normal Pulling 40s (x4 over 2m11s) kubelet Pulling image "polinux/stress"
Normal Created 25s (x4 over 113s) kubelet Created container memory-demo-1-ctr
Normal Pulled 25s kubelet Successfully pulled image "polinux/stress" in 15.194856792s
Normal Started 24s (x4 over 113s) kubelet Started container memory-demo-1-ctr
Warning BackOff 11s (x6 over 96s) kubelet Back-off restarting failed container
[root@master1 ~]#
- 被 kill 掉后 kubelet 会重启它,所以当我们多次运行下面的命令,可以看到容器在反复的被杀死和重启:
[root@master1 ~]#kubectl get pod memory-demo-1 -w NAME READY STATUS RESTARTS AGE memory-demo-1 0/1 ContainerCreating 0 11s memory-demo-1 1/1 Running 0 18s memory-demo-1 0/1 OOMKilled 0 19s memory-demo-1 0/1 OOMKilled 1 (16s ago) 35s memory-demo-1 0/1 CrashLoopBackOff 1 (1s ago) 36s memory-demo-1 0/1 OOMKilled 2 (28s ago) 63s memory-demo-1 0/1 CrashLoopBackOff 2 (14s ago) 77s ……
这就是因为实际需要的内存已经大大超过 limit 限制的了,所以会被 OOMKill 掉,然后 kubelet 重启它又继续被Kill。
- 我们可以看下pod日志
[root@master1 ~]#kubectl logs memory-demo-1 --previous #加上--previous选项代表查看上一次的日志 stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd stress: FAIL: [1] (415) <-- worker 7 got signal 9 stress: WARN: [1] (417) now reaping child worker processes stress: FAIL: [1] (421) kill error: No such process stress: FAIL: [1] (451) failed run completed in 0s …… unable to retrieve container logs for containerd://ff2d1a7491d401f768be9ee2578129532877a9627aa620c36ba511b84265b542[root@master1 ~]#kubectl logs memory-demo-1 --previous unable to retrieve container logs for containerd://ff2d1a7491d401f768be9ee2578129532877a9627aa620c36ba511b84265b542[root@master1 ~]#kubectl logs memory-demo-1 --previous unable to retrieve container logs for containerd://ff2d1a7491d401f768be9ee2578129532877a9627aa620c36ba511b84265b542[root@master1 ~]#kubectl logs memory-demo-1 --previous unable to retrieve container logs for containerd://ff2d1a7491d401f768be9ee2578129532877a9627aa620c36ba511b84265b542[root@master1 ~]#kubectl logs memory-demo-1 --previous unable to retrieve container logs for containerd://ff2d1a7491d401f768be9ee2578129532877a9627aa620c36ba511b84265b542[root@master1 ~]#kubectl logs memory-demo-1 --previous stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd stress: FAIL: [1] (415) <-- worker 7 got signal 9 stress: WARN: [1] (417) now reaping child worker processes stress: FAIL: [1] (421) kill error: No such process stress: FAIL: [1] (451) failed run completed in 0s ……
测试结束。😘
2.超过整个节点容量的内存
内存请求和限制是与容器关联的,Pod 的内存请求是 Pod 中所有容器的内存请求之和。同理,Pod 的内存限制是 Pod 中所有容器的内存限制之和。
Pod 的调度是基于 requests 值的,只有当节点拥有足够满足 Pod 内存请求的内存时,才会将 Pod 调度至节点上运行。
💘 实战:超过整个节点容量的内存-2022.12.12(成功测试)
- 实验环境
1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点 k8s version:v1.20 CONTAINER-RUNTIME:containerd:v1.6.10
- 实验软件(无)
如下所示我们创建一个 Pod,其内存请求超过了你集群中的任意一个节点所拥有的内存。在该 Pod 的资源清单文件中,拥有一个请求 1000 GiB 内存的容器,这应该超过了你集群中任何节点的容量。
# memory-request-limit-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-2
spec:
containers:
- name: memory-demo-2-ctr
image: polinux/stress
resources:
requests:
memory: "1000Gi"
limits:
memory: "1000Gi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
- 同样直接创建该 Pod 即可:
[root@master1 ~]#kubectl apply -f memory-request-limit-2.yaml pod/memory-demo-2 created
- 查看 Pod 状态:
[root@master1 ~]#kubectl get po memory-demo-2 NAME READY STATUS RESTARTS AGE memory-demo-2 0/1 Pending 0 21s
输出结果显示:Pod 处于 PENDING 状态,这意味着,该 Pod 没有被调度至任何节点上运行,并且它会无限期的保持该状态:
- 查看关于 Pod 的详细信息,包括事件:
[root@master1 ~]#kubectl describe po memory-demo-2
Name: memory-demo-2
Namespace: default
Priority: 0
Service Account: default
Node: <none>
Labels: <none>
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Containers:
memory-demo-2-ctr:
Image: polinux/stress
Port: <none>
Host Port: <none>
Command:
stress
Args:
--vm
1
--vm-bytes
250M
--vm-hang
1
Limits:
memory: 1000Gi
Requests:
memory: 1000Gi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-s9g8q (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
kube-api-access-s9g8q:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 51s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/master: }, 3 Insufficient memory. preemption: 0/3 nodes are
available: 1 Preemption is not helpful for scheduling, 2 No preemption victims found for incoming pod.
[root@master1 ~]#
输出结果显示由于节点内存不足,该容器无法被调度。
测试结束。😘
3.给 Pod 分配扩展资源
除了我们经常使用的 CPU 和内存之外,其实我们也可以自己定制扩展资源,要请求扩展资源,需要在你的容器清单中包括resources.requests 字段。扩展资源可以使用任何完全限定名称,只是不能使用 *.kubernetes.io/ ,比如example.com/foo 就是有效的格式,其中 example.com 可以被替换为你组织的域名,而 foo 则是描述性的资源名称。
扩展资源类似于内存和 CPU 资源。一个节点拥有一定数量的内存和 CPU 资源,它们被节点上运行的所有组件共享,该节点也可以拥有一定数量的 foo 资源,这些资源同样被节点上运行的所有组件共享。此外我们也可以创建请求一定数量 foo
资源的 Pod。
假设一个节点拥有一种特殊类型的磁盘存储,其容量为 800 GiB,那么我们就可以为该特殊存储创建一个名称,如example.com/special-storage,然后你就可以按照一定规格的块(如 100 GiB)对其进行发布。在这种情况下,你的节点将会通知它拥有八个 example.com/special-storage 类型的资源。
Capacity: …… example.com/special-storage: 8
如果你想要允许针对特殊存储任意(数量)的请求,你可以按照 1 字节大小的块来发布特殊存储。在这种情况下,你将会发布 800Gi 数量的 example.com/special-storage 类型的资源。
Capacity: …… example.com/special-storage: 800Gi
然后,容器就能够请求任意数量(多达 800Gi)字节的特殊存储。
扩展资源对 Kubernetes 是不透明的。Kubernetes 不知道扩展资源含义相关的任何信息。 Kubernetes 只了解一个节点拥有一定数量的扩展资源。 扩展资源必须以整形数量进行发布。 例如,一个节点可以发布 4 个 dongle 资源,但是不能发布 4.5 个。
💘 实战:超过容器限制的内存-2022.12.12(成功测试)
- 实验环境
1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点 k8s version:v1.20 CONTAINER-RUNTIME:containerd:v1.6.10
- 实验软件(无)
在 Pod 中分配扩展资源之前,我们还需要将该扩展资源发布到节点上去,我们可以直接发送一个 HTTP PATCH 请求到Kubernetes API server 来完成该操作,假设你的一个节点上带有四个 course 资源,下面是一个 PATCH 请求的示例,该请求为你的节点发布四个 course 资源。
PATCH /api/v1/nodes/<your-node-name>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "add",
"path": "/status/capacity/ydzs.io~1course",
"value": "4"
}
]
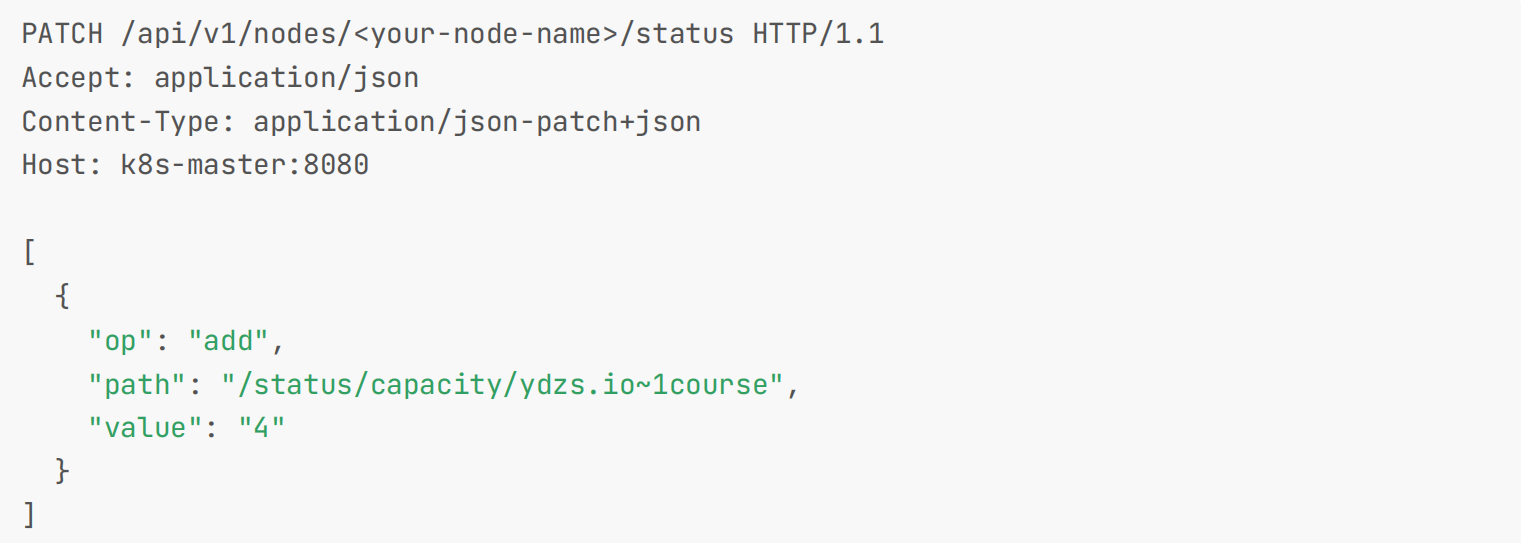
注意:Kubernetes 不需要了解 course 资源的含义和用途,前面的 PATCH 请求告诉 Kubernetes 你的节点拥有四个你称之为 course 的东西。
- 启动一个代理,然后就可以很容易地向 Kubernetes API server 发送请求:
[root@master1 ~]#kubectl proxy Starting to serve on 127.0.0.1:8001
- 在另一个命令窗口中,发送 HTTP PATCH 请求,用你的节点名称替换 <your-node-name>:
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/ydzs.io~1course", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/ydzs.io~1course", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/node1/status
在前面的请求中,~1 为 patch 路径中 / 符号的编码,输出显示该节点的 course 资源容量(capacity)为 4:
"status": {
"capacity": {
"cpu": "2",
"ephemeral-storage": "17394Mi",
"hugepages-1Gi": "0",
"hugepages-2Mi": "0",
"memory": "1863248Ki",
"pods": "110",
"ydzs.io/course": "4"
},
"allocatable": {
"cpu": "2",
"ephemeral-storage": "16415037823",
"hugepages-1Gi": "0",
"hugepages-2Mi": "0",
"memory": "1760848Ki",
"pods": "110"
},
- 描述你的节点也可以看到对应的资源数据:
[root@master1 ~]#kubectl describe nodes node1 …… Capacity: cpu: 2 ephemeral-storage: 17394Mi hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 1863248Ki pods: 110 ydzs.io/course: 4 Allocatable: cpu: 2 ephemeral-storage: 16415037823 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 1760848Ki pods: 110 ydzs.io/course: 4
- 请求扩展资源
现在我们就可以创建请求一定数量 course 资源的 Pod 了。比如我们这里有一个如下所示的资源清单文件:
# resource-extended-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: extended-resource-demo
spec:
containers:
- name: extended-resource-demo-ctr
image: nginx
resources:
requests:
ydzs.io/course: 3
limits:
ydzs.io/course: 3
在该资源清单文件中我们配置请求了 3 个名为 ydzs.io/course 的扩展资源.
- 同样直接创建该资源对象即可:
[root@master1 ~]# kubectl apply -f resource-extended-demo.yaml pod/extended-resource-demo created
- 检查 Pod 是否运行正常:
[root@master1 ~]#kubectl get po NAME READY STATUS RESTARTS AGE extended-resource-demo 1/1 Running 0 7s
可以看到该 Pod 可以正常运行,因为目前的扩展资源是满足调度条件的,所以可以正常调度。
- 同样的我们再创建一个类似的新的 Pod,资源清单文件如下所示:
# resource-extended-demo2.yaml
apiVersion: v1
kind: Pod
metadata:
name: extended-resource-demo-2
spec:
containers:
- name: extended-resource-demo-2-ctr
image: nginx
resources:
requests:
ydzs.io/course: 2
limits:
ydzs.io/course: 2
该 Pod 的容器请求了 2 个 course 扩展资源,Kubernetes 将不能满足该资源的请求,因为上面的 Pod 已经使用了 4 个可用 course 中的 3 个。
- 我们可以尝试创建该 Pod:
[root@master1 ~]#kubectl apply -f resource-extended-demo2.yaml pod/extended-resource-demo-2 created
创建后查看 Pod 的状态:
[root@master1 ~]# kubectl get pod extended-resource-demo-2 NAME READY STATUS RESTARTS AGE extended-resource-demo-2 0/1 Pending 0 2m6s
可以看到当前 Pod 是处于 Pending 状态的,描述下 Pod:
[root@master1 ~]#kubectl describe pod extended-resource-demo-2
……
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 2m31s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/master: }, 3 Insufficient ydzs.io/course. preemption: 0/3 nodes are available: 1 Preemption is not helpful for scheduling, 2 No preemption victims found for incoming pod.
输出结果表明 Pod 不能被调度,因为没有一个节点上存在两个可用的 course 资源了。
- 同样如果要移出该扩展资源,则发布如下所示的 PATCH 请求即可。
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "remove", "path": "/status/capacity/ydzs.io~1course", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "remove", "path": "/status/capacity/ydzs.io~1course", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/master1/status
验证 course 资源的发布已经被移除:
kubectl describe node <your-node-name> | grep course
正常应该看不到任何输出了。
测试完成。😘
2、静态 Pod
在 Kubernetes 集群中除了我们经常使用到的普通的 Pod 外,还有一种特殊的 Pod,叫做Static Pod,也就是我们说的静态 Pod,静态 Pod 有什么特殊的地方呢?
静态 Pod 直接由节点上的 kubelet 进程来管理,不通过 master 节点上的 apiserver。无法与我们常用的控制器 Deployment 或者 DaemonSet 进行关联,它由 kubelet 进程自己来监控,当 pod 崩溃时会重启该 pod,kubelet 也无法对他们进行健康检查。静态 pod 始终绑定在某一个 kubelet 上,并且始终运行在同一个节点上。kubelet 会自动为每一个静态 pod 在 Kubernetes 的 apiserver 上创建一个镜像 Pod,因此我们可以在 apiserver 中查询到该 pod,但是不能通过 apiserver 进行控制(例如不能删除)。
创建静态 Pod 有两种方式:配置文件和 HTTP 两种方式。
1.配置文件
配置文件就是放在特定目录下的标准的 JSON 或 YAML 格式的 pod 定义文件。用 kubelet --pod-manifest-path=<the directory>来启动 kubelet 进程,kubelet 定期的去扫描这个目录,根据这个目录下出现或消失的YAML/JSON 文件来创建或删除静态 pod。
比如我们在 node1 这个节点上用静态 pod 的方式来启动一个 nginx 的服务,配置文件路径为:
[root@master1 ~]#cat /var/lib/kubelet/config.yaml|grep staticPodPath
staticPodPath: /etc/kubernetes/manifests # 和命令行的 pod-manifest-path 参数一致
[root@master1 ~]#kubelet --help|grep manifest
manifest can be provided to the Kubelet.
(underspec'd currently) to submit a new manifest.
--manifest-url string URL for accessing additional Pod specifications to run (DEPRECATED: This parameter should be set via the config file specified by the Kubelet's --config flag. See https://kubernetes.io/docs/tasks/administer-cluster/kubelet-config-file/ for more information.)
--manifest-url-header colonSeparatedMultimapStringString Comma-separated list of HTTP headers to use when accessing the url provided to --manifest-url. Multiple headers with the same name will be added in the same order provided. This flag can be repeatedly invoked. For example: --manifest-url-header 'a:hello,b:again,c:world' --manifest-url-header 'b:beautiful' (DEPRECATED: This parameter should be set via the config file specified by the Kubelet's --config flag. See https://kubernetes.io/docs/tasks/administer-cluster/kubelet-config-file/ for more information.)
--pod-manifest-path string Path to the directory containing static pod files to run, or the path to a single static pod file. Files starting with dots will be ignored. (DEPRECATED: This parameter should be set via the config file specified by the Kubelet's --config flag. See https://kubernetes.io/docs/tasks/administer-cluster/kubelet-config-file/ for more information.)
[root@master1 ~]#
打开这个文件我们可以看到其中有一个属性为 staticPodPath 的配置,其实和命令行的 --pod-manifest-path 配置是一致的,所以如果我们通过 kubeadm 的方式来安装的集群环境,对应的 kubelet 已经配置了我们的静态 Pod 文件的路径,默认地址为 /etc/kubernetes/manifests 。所以我们只需要在该目录下面创建一个标准的 Pod 的 JSON 或者 YAML 文件即可,如果你的 kubelet 启动参数中没有配置上面的--pod-manifest-path 参数的话,那么添加上这个参数然后重启 kubelet 即可:
cat <<EOF >/etc/kubernetes/manifests/static-web.yaml
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
app: static
spec:
containers:
- name: web
image: nginx
ports:
- name: web #这个容器端口也是可以指定name的,因为一个容器可以有不同的端口来提供不同的服务;
containerPort: 80
EOF
#查看运行的pod
[root@master1 ~]#kubectl get po static-web-master1
NAME READY STATUS RESTARTS AGE
static-web-master1 1/1 Running 0 3m12s
2.通过 HTTP 创建静态 Pods
kubelet 周期地从 –manifest-url= 参数指定的地址下载文件,并且把它翻译成 JSON/YAML 格式的 pod 定义。此后的操作方式与–pod-manifest-path= 相同,kubelet 会不时地重新下载该文件,当文件变化时对应地终止或启动静态 pod。
kubelet 启动时,由 --pod-manifest-path= 或 --manifest-url= 参数指定的目录下定义的所有 pod 都会自动创建,例如,我们示例中的 static-web:
➜ ~ nerdctl -n k8s.io ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 6add7aa53969 docker.io/library/nginx:latest "/docker-entrypoint.…" 43 seconds ago Up ......
现在我们通过kubectl工具可以看到这里创建了一个新的镜像 Pod:
[root@master1 ~]#kubectl get pod NAME READY STATUS RESTARTS AGE static-web-master1 1/1 Running 0 2m29s
静态 pod 的标签会传递给镜像 Pod,可以用来过滤或筛选。需要注意的是,我们不能通过 API 服务器来删除静态 pod(例如,通过kubectl命令),kubelet 不会删除它。
[root@master1 ~]#kubectl get pod NAME READY STATUS RESTARTS AGE resource-demo1 1/1 Running 0 72m static-web-master1 1/1 Running 0 7m20s [root@master1 ~]#kubectl delete pod static-web-master1 pod "static-web-master1" deleted [root@master1 ~]#kubectl get pod NAME READY STATUS RESTARTS AGE resource-demo1 1/1 Running 0 72m static-web-master1 0/1 Pending 0 1s [root@master1 ~]#kubectl get pod NAME READY STATUS RESTARTS AGE resource-demo1 1/1 Running 0 73m static-web-master1 1/1 Running 0 5s [root@master1 ~]#
3.静态 Pod 的动态增加和删除
运行中的 kubelet 周期扫描配置的目录(我们这个例子中就是 /etc/kubernetes/manifests)下文件的变化,当这个目录中有文件出现或消失时创建或删除 pods:
[root@master1 ~]#kubectl get pod NAME READY STATUS RESTARTS AGE resource-demo1 1/1 Running 0 73m static-web-master1 1/1 Running 0 48s [root@master1 ~]#mv /etc/kubernetes/manifests/static-web.yaml /tmp/ [root@master1 ~]#kubectl get pod NAME READY STATUS RESTARTS AGE resource-demo1 1/1 Running 0 73m [root@master1 ~]#mv /tmp/static-web.yaml /etc/kubernetes/manifests/ [root@master1 ~]#kubectl get pod NAME READY STATUS RESTARTS AGE resource-demo1 1/1 Running 0 74m static-web-master1 0/1 Pending 0 2s [root@master1 ~]#kubectl get pod NAME READY STATUS RESTARTS AGE resource-demo1 1/1 Running 0 74m static-web-master1 1/1 Running 1 (28s ago) 5s [root@master1 ~]#
其实我们用 kubeadm 安装的集群,master 节点上面的几个重要组件都是用静态 Pod 的方式运行的,我们登录到 master 节点上查看/etc/kubernetes/manifests目录:
➜ ~ ls /etc/kubernetes/manifests/ etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
现在明白了吧,这种方式也为我们将集群的一些组件容器化提供了可能,因为这些 Pod 都不会受到 apiserver 的控制,不然我们这里kube-apiserver怎么自己去控制自己呢?万一不小心把这个 Pod 删掉了呢?所以只能有kubelet自己来进行控制,这就是我们所说的静态 Pod。
3、Downward API
前面我们从 Pod 的原理到生命周期介绍了 Pod 的一些使用,作为 Kubernetes 中最核心的资源对象、最基本的调度单元,我们可以发现 Pod 中的属性还是非常繁多的。
前面我们使用过一个 volumes 的属性,表示声明一个数据卷,我们可以通过命令kubectl explain pod.spec.volumes去查看该对象下面的属性非常多。前面我们只是简单使用了 hostPath 和 emptyDir{} 这两种模式,其中还有一种模式叫做downwardAPI。这个模式和其他模式不一样的地方在于它不是为了存放容器的数据,也不是用来进行容器和宿主机的数据交换的,而是让 Pod 里的容器能够直接获取到这个 Pod 对象本身的一些信息。
目前 Downward API 提供了两种方式用于将 Pod 的信息注入到容器内部:
- 环境变量:用于单个变量,可以将 Pod 信息和容器信息直接注入容器内部
- Volume 挂载:将 Pod 信息生成为文件,直接挂载到容器内部中去
1.环境变量
应用场景:
• 容器内应用程序获取Pod信息
• 容器内应用程序通过用户定义的变量改变默认行为
变量值几种定义方式:
• 自定义变量值
• 变量值从Pod属性获取
• 变量值从Secret、ConfigMap获取
⚠️ 注意:
我们给容器传变量,无非就是给应用使用。如果应用不接收,那给它传任何变量也没有任何意义;
自定义变量值:应用程序要接收什么值,你就去定义什么变量;
这些变量在创建容器中都会被注入到容器中的,在容器中就可以像在shell中引用这个变量了;
自定义变量值用法:
# pod-env.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-envars
spec:
containers:
- name: c1
image: busybox
command: [ "sh", "-c"]
args:
- while true; do
echo -en '\n';
printenv MY_NODE_NAME MY_POD_NAME MY_POD_NAMESPACE;
printenv MY_POD_IP MY_POD_SERVICE_ACCOUNT;
sleep 10;
done;
env:
- name: ABC #自定义变量
value: "123456" #这里需要注意,这里变量的值是不分数字的,全部当字符串处理。因此这里要加上双引号:
restartPolicy: Never
💘 实战:Downward API环境变量-2022.12.12(成功测试)
- 实验环境
1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点 k8s version:v1.20 CONTAINER-RUNTIME:containerd:v1.6.10
- 实验软件(无)
我们通过 Downward API 来将 Pod 的 IP、名称以及所对应的 namespace 注入到容器的环境变量中去,然后在容器中打印全部的环境变量来进行验证,对应资源清单文件如下:
- 创建pod.yaml
[root@master1 ~]#vim env-pod.yaml
# env-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: env-pod
namespace: kube-system
spec:
containers:
- name: env-pod
image: busybox
command: ["/bin/sh", "-c", "env"] #注意,这个pod执行完这个命令就退出了,没有进程可以hold住容器,可以通过查看日志来确认一些信息;
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
我们可以看到上面我们使用了一种新的方式来设置 env 的值:valueFrom,由于 Pod 的 name 和 namespace 属于元数据,是在 Pod 创建之前就已经定下来了的,所以我们可以使用 metata 就可以获取到了。但是对于 Pod 的 IP 则不一样,因为我们知道 Pod IP 是不固定的,Pod 重建了就变了,它属于状态数据,所以我们使用 status 这个属性去获取。另外除了使用 fieldRef获取 Pod 的基本信息外,还可以通过 resourceFieldRef 去获取容器的资源请求和资源限制信息。
- 部署
我们直接创建上面的 Pod:
[root@master1 ~]#kubectl apply -f env-pod.yaml pod/env-pod created
- 测试
Pod 创建成功后,我们可以查看日志:
[root@master1 ~]# kubectl logs env-pod -nkube-system POD_IP=10.244.2.10 KUBERNETES_SERVICE_PORT=443 KUBERNETES_PORT=tcp://10.96.0.1:443 KUBE_DNS_SERVICE_PORT_DNS_TCP=53 HOSTNAME=env-pod SHLVL=1 HOME=/root KUBE_DNS_SERVICE_HOST=10.96.0.10 KUBE_DNS_PORT_9153_TCP_ADDR=10.96.0.10 KUBE_DNS_PORT_9153_TCP_PORT=9153 KUBE_DNS_PORT_9153_TCP_PROTO=tcp KUBE_DNS_SERVICE_PORT=53 KUBE_DNS_PORT=udp://10.96.0.10:53 POD_NAME=env-pod KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1 PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin KUBERNETES_PORT_443_TCP_PORT=443 KUBE_DNS_SERVICE_PORT_METRICS=9153 KUBE_DNS_PORT_53_TCP_ADDR=10.96.0.10 KUBERNETES_PORT_443_TCP_PROTO=tcp KUBE_DNS_PORT_9153_TCP=tcp://10.96.0.10:9153 KUBE_DNS_PORT_53_UDP_ADDR=10.96.0.10 KUBE_DNS_PORT_53_TCP_PORT=53 KUBE_DNS_PORT_53_TCP_PROTO=tcp KUBE_DNS_PORT_53_UDP_PORT=53 KUBE_DNS_SERVICE_PORT_DNS=53 KUBE_DNS_PORT_53_UDP_PROTO=udp KUBERNETES_SERVICE_PORT_HTTPS=443 KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443 POD_NAMESPACE=kube-system KUBERNETES_SERVICE_HOST=10.96.0.1 PWD=/ KUBE_DNS_PORT_53_TCP=tcp://10.96.0.10:53 KUBE_DNS_PORT_53_UDP=udp://10.96.0.10:53 [root@master1 ~]# [root@master1 ~]# kubectl logs env-pod -nkube-system|grep POD POD_IP=10.244.2.10 POD_NAME=env-pod POD_NAMESPACE=kube-system [root@master1 ~]#
我们可以看到 Pod 的 IP、NAME、NAMESPACE 都通过环境变量打印出来了。
上面打印 Pod 的环境变量可以看到有很多内置的变量,其中大部分是系统自动为我们添加的,Kubernetes 会把当前命名空间下面的 Service 信息通过环境变量的形式注入到 Pod 中去:
[root@master1 ~]#kubectl get svc -nkube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 7d14h
测试结束😘。
2.Volume 挂载
Downward API除了提供环境变量的方式外,还提供了通过 Volume 挂载的方式去获取 Pod 的基本信息。接下来我们通过Downward API将 Pod 的 Label、Annotation 等信息通过 Volume 挂载到容器的某个文件中去,然后在容器中打印出该文件的值来验证,对应的资源清单文件如下所示:
💘 实战:Downward API Volume挂载测试-2022.12.12(成功测试)
- 实验环境
1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点 k8s version:v1.20 CONTAINER-RUNTIME:containerd:v1.6.10
- 实验软件(无)
- 创建pod.yaml
[root@master1 ~]#vim volume-pod.yaml
# volume-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: volume-pod
namespace: kube-system
labels:
k8s-app: test-volume
node-env: test
annotations:
own: youdianzhishi
build: test
spec:
volumes:
- name: podinfo
downwardAPI:
items:
- path: labels
fieldRef:
fieldPath: metadata.labels
- path: annotations
fieldRef:
fieldPath: metadata.annotations
containers:
- name: volume-pod
image: busybox
args:
- sleep
- "3600"
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
我们将元数据 labels 和 annotaions 以文件的形式挂载到了 /etc/podinfo 目录下。
- 部署
创建上面的 Pod:
[root@master1 ~]#kubectl apply -f volume-pod.yaml pod/volume-pod created
- 测试
创建成功后,我们可以进入到容器中查看元信息是不是已经存入到文件中了:
[root@master1 ~]#kubectl exec -it volume-pod -nkube-system -- sh
/ # cd /etc/podinfo/
/etc/podinfo # ls -l
total 0
lrwxrwxrwx 1 root root 18 Nov 7 14:41 annotations -> ..data/annotations
lrwxrwxrwx 1 root root 13 Nov 7 14:41 labels -> ..data/labels
/etc/podinfo # cat labels
k8s-app="test-volume"
node-env="test"/etc/podinfo #
/etc/podinfo # cat annotations
build="test"
kubectl.kubernetes.io/last-applied-configuration="{\"apiVersion\":\"v1\",\"kind\":\"Pod\",\"metadata\":{\"annotations\":{\"build\":\"test\",\"own\":\"youdianzhishi\"},\"labels\":{\"k8s-app\":\"test-volume\",\"node-env\":\"test\"},\"name\":\"volume-pod\",\"namespace\":\"kube-system\"},\"spec\":{\"containers\":[{\"args\":[\"sleep\",\"3600\"],\"image\":\"busybox\",\"name\":\"volume-pod\",\"volumeMounts\":[{\"mountPath\":\"/etc/podinfo\",\"name\":\"podinfo\"}]}],\"volumes\":[{\"downwardAPI\":{\"items\":[{\"fieldRef\":{\"fieldPath\":\"metadata.labels\"},\"path\":\"labels\"},{\"fieldRef\":{\"fieldPath\":\"metadata.annotations\"},\"path\":\"annotations\"}]},\"name\":\"podinfo\"}]}}\n"
kubernetes.io/config.seen="2021-11-07T22:41:51.934064864+08:00"
kubernetes.io/config.source="api"
own="youdianzhishi"/etc/podinfo #
我们可以看到 Pod 的 Labels 和 Annotations 信息都被挂载到 /etc/podinfo 目录下面的 lables 和 annotations 文件了。
注意:我们可以看到annotations里面还有一些其他的信息,这个是pod启动自动生成的一些信息(last-applied-configuration);
测试结束。😘
目前,Downward API 支持的字段已经非常丰富了,比如:
1. 使用 fieldRef 可以声明使用:
spec.nodeName - 宿主机名字 status.hostIP - 宿主机IP metadata.name - Pod的名字 metadata.namespace - Pod的Namespace status.podIP - Pod的IP spec.serviceAccountName - Pod的Service Account的名字 metadata.uid - Pod的UID metadata.labels['<KEY>'] - 指定<KEY>的Label值 metadata.annotations['<KEY>'] - 指定<KEY>的Annotation值 metadata.labels - Pod的所有Label metadata.annotations - Pod的所有Annotation
2. 使用 resourceFieldRef 可以声明使用:
容器的 CPU limit 容器的 CPU request 容器的 memory limit 容器的 memory request
需要注意的是,Downward API 能够获取到的信息,一定是 Pod 里的容器进程启动之前就能够确定下来的信息。而如果你想要获取 Pod 容器运行后才会出现的信息,比如,容器进程的 PID,那就肯定不能使用 Downward API 了,而应该考虑在 Pod 里定义一个 sidecar 容器来获取了。
在实际应用中,如果你的应用有获取 Pod 的基本信息的需求,一般我们就可以利用Downward API来获取基本信息,然后编写一个启动脚本或者利用initContainer将 Pod 的信息注入到我们容器中去,然后在我们自己的应用中就可以正常的处理相关逻辑了。
除了通过 Downward API 可以获取到 Pod 本身的信息之外,其实我们还可以通过映射其他资源对象来获取对应的信息,比如 Secret、ConfigMap 资源对象,同样我们可以通过环境变量和挂载 Volume 的方式来获取他们的信息。但是,通过环境变量获取这些信息的方式,不具备自动更新的能力。所以,一般情况下,都建议使用 Volume 文件的方式获取这些信息,因为通过 Volume 的方式挂载的文件在 Pod 中会进行热更新。
⚠️ 注意:downwars API的应用场景
比如说你的一个pod,把你的日志输出到一个文件中去,然后你要去采集日志的时候,如果你的多个pod都给他输出,都给他挂载到同一个地方的话,那么它挂载的同样一个日志是不是有可能冲突啊。
这个时候,最好的方式,是不是就是把每一个pod给他输出到不同的文件或文件夹当中去,那么这个时候,我们就可以获取到pod本身的名称,然后根据pod名称去创建一个日志文件,给他们区分开,这个方式是不是很可以的。
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 语雀
彦 · 语雀
语雀博客 · 语雀 《语雀博客》
🍀 博客
www.onlyyou520.com


🍀 csdn
一念一生~one的博客_CSDN博客-k8s,Linux,git领域博主

🍀 知乎
一个人 - 知乎

最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!


![[附源码]Node.js计算机毕业设计大学校园二手教材与书籍Express](https://img-blog.csdnimg.cn/3a2ab7308b65488088dfdebbb1335bc9.png)
![[附源码]Python计算机毕业设计Django的连锁药店销售管理系统](https://img-blog.csdnimg.cn/1f589cd1de8e4ed09eb0eb58871b9562.png)
![[附源码]Nodejs计算机毕业设计基于java旅游信息分享网站Express(程序+LW)](https://img-blog.csdnimg.cn/d0ab6759358043e49ec712731aa3a299.png)