目录
- 1、前言
- 2、我这儿已有的FPGA压缩算法方案
- 3、FPGA Gzip数据压缩功能和性能
- 4、FPGA Gzip数据压缩设计方案
- 输入输出接口描述
- 数据处理流程
- LZ77压缩器
- 哈夫曼编码
- 输出缓存
- 数据输出说明
- 特殊说明
- 5、vivado仿真
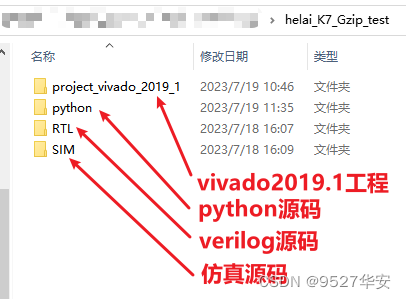
- 6、vivado工程
- 7、上板调试验证
- FPGA开发板测试
- 本zip算法对比于评估
- 8、福利:工程代码的获取
1、前言
说到FPGA的应用,数据压缩算法的硬件加速器无疑是经典应用之一,用FPGA压缩图片、视频、普通数据等都具有并行执行的独特优势,关于FPGA压缩图片和视频,我之前的博客有相关设计,今天讲讲用FPGA实现对普通数据进行Gzip压缩算法的实现;本工程源码的功能就是:基于 FPGA 的流式的 GZIP (deflate 算法) 压缩器,用于通用无损数据压缩:输入原始数据,输出标准的 GZIP 格式,即常见的 .gz / .tar.gz 文件的格式。
2、我这儿已有的FPGA压缩算法方案
我这里有图像的JPEG解压缩、JPEG-LS压缩、H264编解码、H265编解码以及其他方案,后续还会出更多方案,我把他们整合在一个专栏里面,会持续更新,专栏地址:
直接点击前往
3、FPGA Gzip数据压缩功能和性能
3.1:纯 RTL 设计,在各种 FPGA 型号上都可以部署;
3.2:极简流式接口 :AXI-stream 输入接口:
3.2.1:数据位宽 8-bit ,每周期可输入 1 字节的待压缩数据;
3.2.2:输入的长度 ≥32 字节的 AXI-stream 包 (packet) 会被压缩为一个独立的 GZIP 数据流;
3.2.3:输入的长度 <32 字节的 AXI-stream 包会被模块丢弃 (不值得压缩) ,不会产生任何输出;
3.3:AXI-stream 输出接口:
4.3.1:每个输出的 AXI-stream 包是一个独立的 GZIP 数据流 (包括GZIP文件头和文件尾);
3.4:性能:
如果输出接口无反压,也即 o_tready 始终=1,则输入接口也一定无反压,也即 o_tready 始终=1 (即使在最坏情况下) ;
这是我刻意设计的,好处是当外部带宽充足时,本模块可跑在确定且最高的性能下 (输入吞吐率=时钟频率);
在 Xilinx Artix-7 xc7a35ticsg324-1L 上时钟频率跑到 128MHz (输入性能为 128MByte/s);
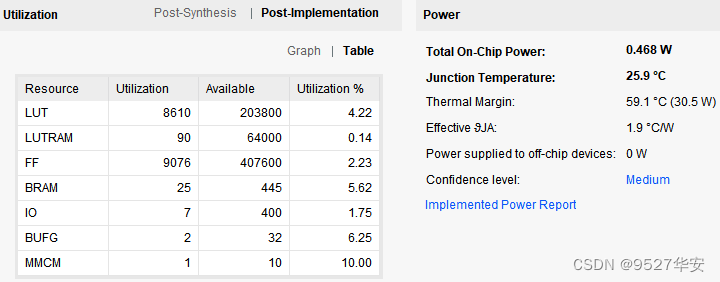
资源:在 Xilinx FPGA 上约占 8200×LUT 和 25×BRAM36K;
支持几乎完整的 deflate 算法 :
依照 deflate 算法规范 (RFC1951 [1]) 和 GZIP 格式规范 (RFC1952 [2]) 编写;
deflate block:
小于 16384 字节的输入 AXI-stream 包当作一个 deflate block;
大于 16384 字节的输入 AXI-stream 包分为多个 deflate block , 每个不超过 16384;
LZ77 游程压缩:
搜索距离为 16383 , 范围覆盖整个 deflate block;
使用哈希表匹配搜索,哈希表大小=4096;
动态 huffman 编码:
当 deflate block 较大时,建立动态 huffman tree ,包括 literal code tree 和 distance code tree;
当 deflate block 较小时,使用静态 huffman tree 进行编码;
由于支持了以上功能,本设计的压缩率:
接近 7ZIP 软件在“快速压缩”选项下生成的 .gz 文件;
显著大于其它现有的开源 deflate 压缩器。见 对比和评估;
依照 GZIP 的规定,生成原始数据的 CRC32 放在 GZIP 的末尾,用于校验;
不支持的特性:
不构建动态 code length tree , 而是使用固定 code length tree ,因为它的收益代价比不像动态 literal code tree 和 distance code tree 那么高;
不会为了提高压缩率而动态调整 deflate block 大小,目的是降低复杂度;
4、FPGA Gzip数据压缩设计方案
FPGA Gzip数据压缩设计方案框图如下:
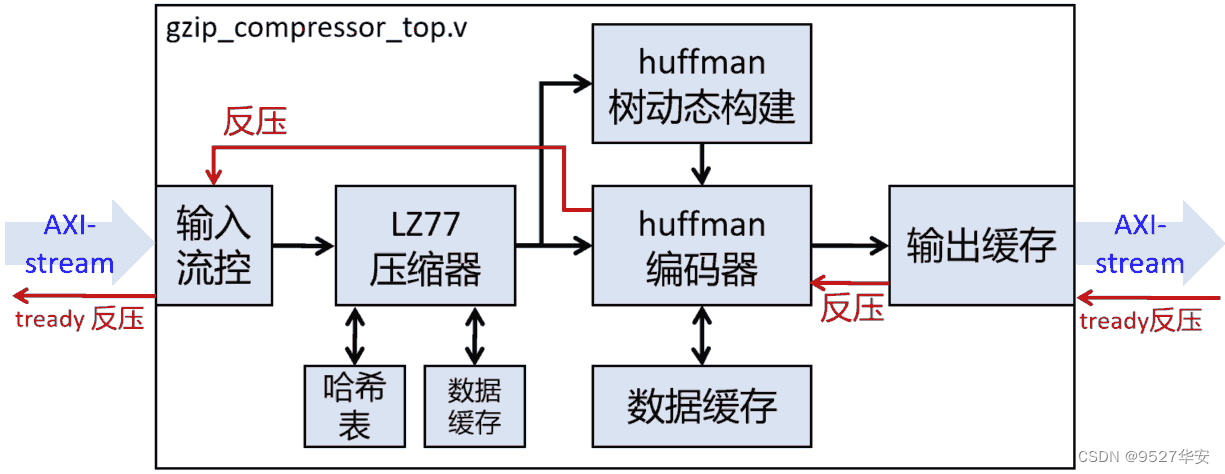
输入输出接口描述
输入接口是标准的 8-bit 位宽的 AXI-stream slave;
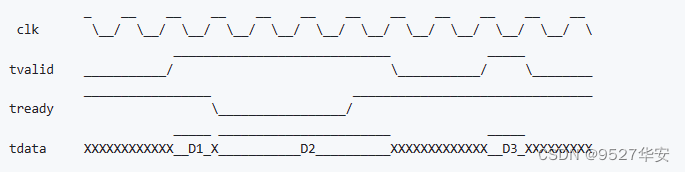
i_tvalid 和 i_tready 构成握手信号,只有同时=1时才成功输入了1个数据 (如上图);
i_tdata 是1字节的输入数据;
i_tlast 是包 (packet) 的分界标志,i_tlast=1 意味着当前传输的是一个包的末尾字节,而下一个传输的字节就是下一包的首字节。每个包会被压缩为一个独立的 GZIP 数据流;
输出接口是标准的 32-bit (4字节) 位宽的 AXI-stream master;
o_tvalid 和 o_tready 构成握手信号,只有同时=1时才成功输出了1个数据 (类似输入接口) ;
o_tdata 是4字节的输出数据。按照 AXI-stream 的规定,o_tdata 是小端序,o_tdata[7:0] 是最靠前的字节,o_data[31:24] 是最靠后的字节;
o_tlast 是包的分界标志。每个包是一个独立的 GZIP 数据流;
o_tkeep 是字节有效信号,具体如下:
o_tkeep[0]=1 意为 o_tdata[7:0] 有效,否则无效;
o_tkeep[1]=1 意为 o_tdata[15:8] 有效,否则无效;
o_tkeep[2]=1 意为 o_tdata[23:16] 有效,否则无效;
o_tkeep[3]=1 意为 o_tdata[31:24] 有效,否则无效;
当输出包的字节数量不能整除4时,只有在包的末尾 (o_tlast=1 时) ,o_tkeep 才可能为 4’b0001, 4’b0011, 4’b0111;
其余情况下 o_tkeep=4’b1111;
数据处理流程
LZ77压缩器
详见计方案框图;
输入数据首先给到LZ77压缩器进行数据处理;
关于LZ77压缩器原理,推荐参考阅读下面这篇博客:
点击直接阅读LZ77压缩器
LZ77压缩器在代码中的位置如下:可以看到,由纯verilog代码实现;

哈夫曼编码
输入数据经过LZ77压缩器后,分两路给到哈夫曼树动态构建和哈夫曼编码模块,哈夫曼编码模块内部定义了一个二维数组作为缓存使用,关于哈夫曼编码原理,推荐参考阅读下面这篇博客:
点击直接阅读哈夫曼编码
哈夫曼树动态构建和哈夫曼编码模块在代码中的位置如下:可以看到,由纯verilog代码实现;
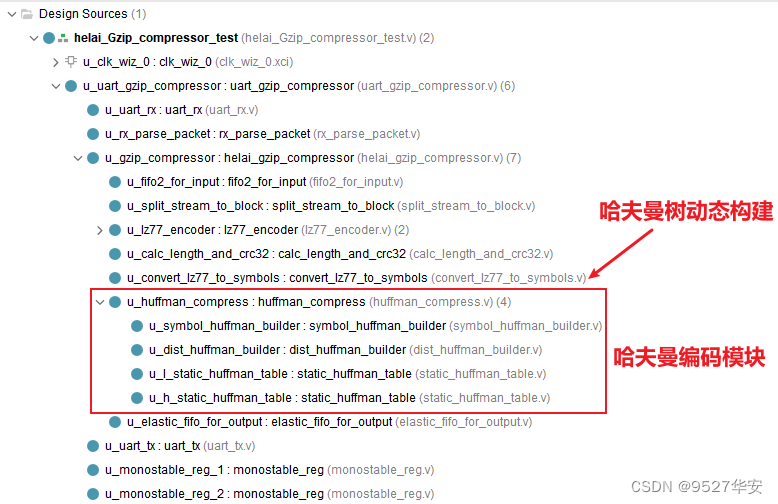
哈夫曼编码模块内部定义的二维数组作为缓存使用代码位置如下:
输出缓存
输出缓存其实质就是一个AXIS接口的FIFO,将输出数据缓存以作AXIS格式输出,这个很简单,在代码中的位置如下:可以看到,由纯verilog代码实现;
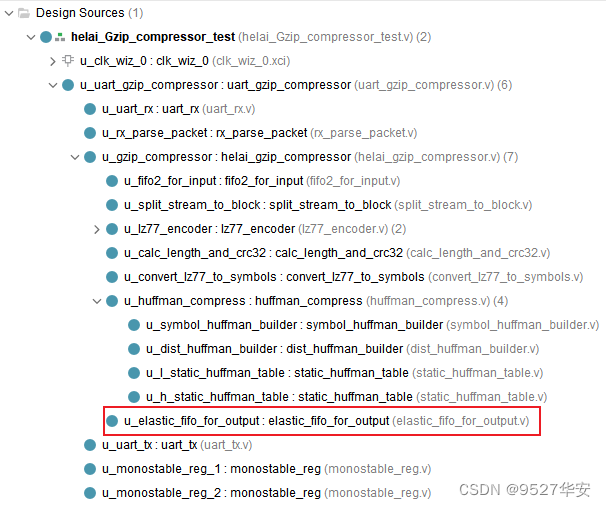
数据输出说明
AXI-stream 接口输出的是满足 GZIP 格式标准的数据,将每个 AXI-stream 包的数据独立存入一个 .gz 文件后,这个文件就可以被众多压缩软件 (7ZIP, WinRAR 等) 解压。
需要提示的是: .gz 是 GZIP 压缩文件的概念。更为人熟知的是 .tar.gz 。实际上 TAR 是把多个文件打包成一个 .tar 文件,然后再对这一个 .tar 文件进行 GZIP 压缩得到 .tar.gz 文件。如果对单个文件进行压缩,则可以不用 TAR 打包,直接压缩为一个 .gz 。例如 data.txt 压缩为 data.txt.gz;例如,AXI-stream 接口上一共成功握手了 987 次,最后一次握手时 o_tlast=1 ,说明这 987 拍数据是一个独立的 GZIP 流。假设最后一次握手时 o_tkeep=4’b0001 ,则最后一拍只携带1字节的数据,则该 GZIP 流一共包含 986×4+1=3949 字节。如果将这些字节存入 .gz 文件,则应该:
.gz 文件的第1字节 对应 第1拍的 o_tdata[7:0]
.gz 文件的第2字节 对应 第1拍的 o_tdata[15:8]
.gz 文件的第3字节 对应 第1拍的 o_tdata[23:16]
.gz 文件的第4字节 对应 第1拍的 o_tdata[31:24]
.gz 文件的第5字节 对应 第2拍的 o_tdata[7:0]
.gz 文件的第6字节 对应 第2拍的 o_tdata[15:8]
.gz 文件的第7字节 对应 第2拍的 o_tdata[23:16]
.gz 文件的第8字节 对应 第2拍的 o_tdata[31:24]
......
.gz 文件的第3945字节 对应 第986拍的 o_tdata[7:0]
.gz 文件的第3946字节 对应 第986拍的 o_tdata[15:8]
.gz 文件的第3947字节 对应 第986拍的 o_tdata[23:16]
.gz 文件的第3948字节 对应 第986拍的 o_tdata[31:24]
.gz 文件的第3949字节 对应 第987拍的 o_tdata[7:0]
特殊说明
如果输出接口无反压,也即 o_tready 始终=1,则输入接口也一定无反压,也即 o_tready 始终=1 (即使在最坏情况下) ;借助这个特性,如果外部带宽充足稳定,以至于可以保证 o_tready 始终=1 ,则可忽略 i_tready 信号,任何时候都可以让 i_tvalid=1 来输入一个字节。
deflate 算法需要用整个 deflate block 来构建动态 huffman 树,因此本模块的端到端延迟较高:
当输入 AXI-stream 包长度为 32~16384 时,只有在输入完完整的包 (并还需要过一段时间后) ,才能在输出 AXI-stream 接口上拿到对应的压缩包的第一个数据。
当输入 AXI-stream 包长度 >16384 时,每完整地输入完 16384 字节 (并还需要过一段时间后),才能在输出 AXI-stream 接口上拿到对应的有关这部分数据的压缩数据,当输入 AXI-stream 包长度为 <32 时,模块内部会丢弃该包,并且不会针对它产生任何输出数据。
要想获得高压缩率,尽量让包长度 >7000 字节,否则模块很可能不会选择使用动态 huffman ,且 LZ77 的搜索范围也会很受限。如果需要压缩的数据在逻辑上是很多很小的 AXI-stream 包,可以在前面加一个预处理器,把它们合并为一个几千或几万字节的大包来送入gzip_compressor_top;
5、vivado仿真
vivado仿真设计框图如下:

vivado仿真代码架构如下:
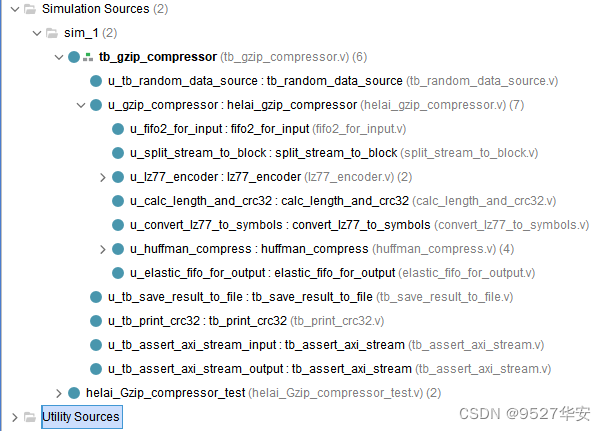
其中随机数据包生成器 (tb_random_data_source.v) 会4种生成特性不同的数据包 (字节概率均匀分布的随机数据、字节概率非均匀分布的随机数据、随机连续变化的数据、稀疏数据) ,送入待测模块 (helai_gzip_compressor) 进行压缩,然后 tb_save_result_to_file 模块会把压缩结果存入文件,每个独立的数据包存入一个独立的 .gz 文件。
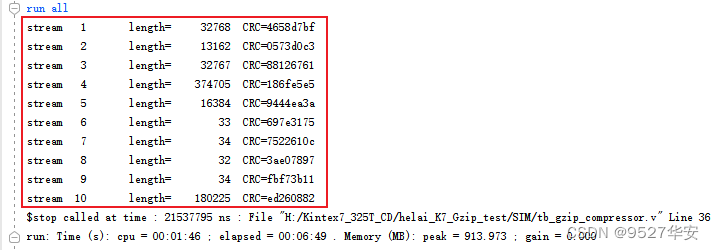
tb_print_crc32 负责计算原始数据的 CRC32 并打印,注意:待测模块内部也会计算 CRC32 并封装入 GZIP 数据流,这两个 CRC32 计算器是独立的 (前者仅用于仿真,用来验证待测模块生成的 CRC32 是否正确)。你可以自行将仿真打印的 CRC32 与 生成的 GZIP 文件中的 CRC32 进行对比。
vivado仿真打印结果如下:
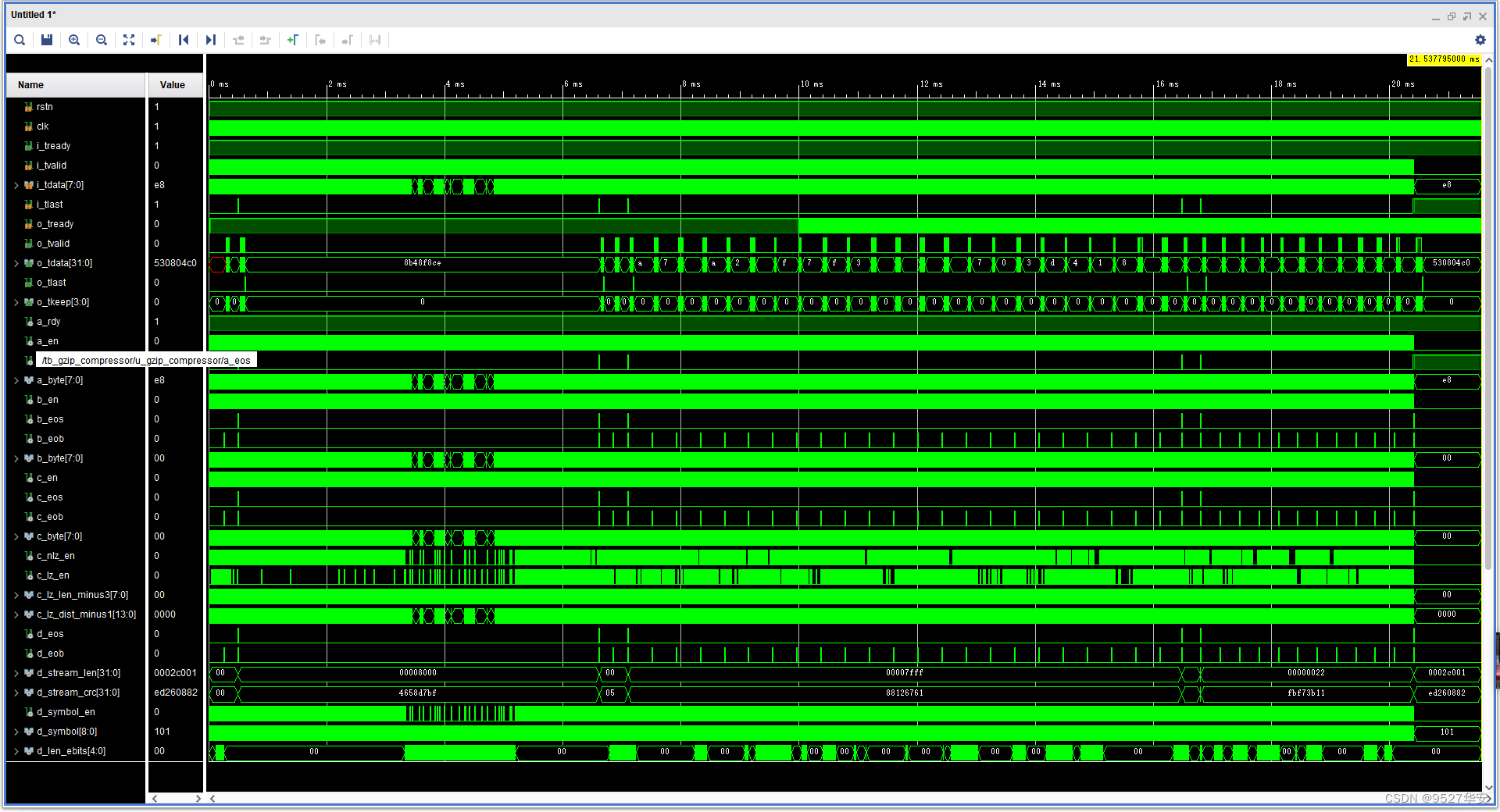
仿真波形如下:
仿真后生成的zip压缩文件保存的路径如下:
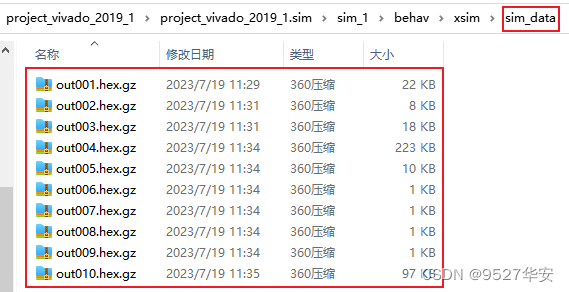
然后可以将其解压打开看。。。
6、vivado工程
开发板FPGA型号:Xilinx–>xc7k325tffg676-2;
输入:python测试数据,串口输入;
输入:zip压缩后的数据,串口输出;
应用:zip数据压缩应用;
vivado工程设计框图如下:

该 FPGA 工程接收串口数据,将数据送入 GZIP 压缩器,并将得到的 GZIP 压缩数据流用串口发出去 (串口格式: 波特率115200, 无校验位)。
在电脑 (上位机) 上,编写了一个 python 程序,该程序的执行步骤是:
从电脑的磁盘中读入一个文件 (用户通过命令行指定文件名);
列出电脑上的所有串口,用户需要选择 FPGA 对应的串口 (如果只发现一个串口,则直接选择这个串口);
将该文件的所有字节通过串口发给 FPGA;同时接收 FPGA 发来的数据;
将接收到的数据存入一个 .gz 文件,相当于调用 FPGA 进行了文件压缩;
最终,调用 python 的 gzip 库解压该 .gz 文件,并与原始数据相比,看是否相等。如果不相等则报错;
由于串口速度远小于 gzip_compressor_top 能达到的最高性能,因此该工程仅仅用于展示。要想让Gzip数据压缩模块发挥更高性能,需要用其它高速通信接口。
python代码放置目录如下:
工程代码架构如下:
FPGA资源消耗如下:
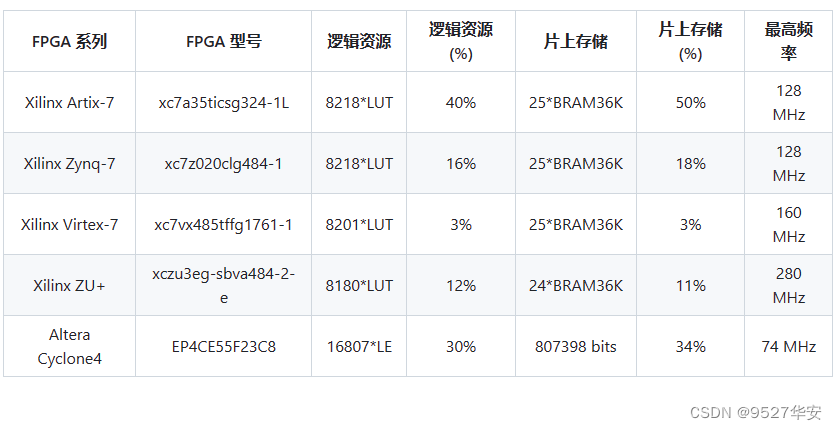
在其他FPGA上移植后的资源消耗如下:
7、上板调试验证
FPGA开发板测试
FPGA 工程烧录后,在python 目录下打开命令行,运行以下命令:
python fpga_uart_gz_file.py <需要压缩的文件名>
例如,运行以下命令来压缩 raw.hex :
python fpga_uart_gz_file.py raw.hex
如果压缩成功,会得到 raw.hex.gz 文件,且不会打印报错信息。
本zip算法对比于评估
为了评估本设计的综合表现,我们将本设计与以下 3 种 deflate 压缩方案进行对比:
1:软件压缩:在电脑上运行 7ZIP 压缩软件
配置:压缩格式=gzip,压缩等级=极速压缩,压缩方法=Deflate,字典大小=32KB,单词大小=32;
2:HDL-deflate算法:
一个基于 FPGA 的 deflate 压缩器/解压器,它的压缩器只使用了 LZ77 + 静态 huffman,而没有使用动态 huffman 。在 LZ77 中,它没有使用哈希表来搜索。
在本测试中,使用了它的压缩器的最高配置 (也是默认配置) : LOWLUT=False, COMPRESS=True , DECOMPRESS=False , MATCH10=True ,FAST=True;
3:HT-Deflate-FPGA算法:
一个基于 FPGA 的多核的 deflate 压缩器,它也只使用了 LZ77 + 静态 huffman ,而没有使用动态 huffman 。在 LZ77 中,它使用了哈希表来搜索,这与本设计相同。
这个设计是面向 Xilinx-AWS 云平台的多核并行的 deflate 压缩,性能很高,但占用的资源较多。相比之下,HDL-deflate 和本设计都是单核的压缩,面向嵌入式应用设计。
由于这个设计并没有提供上手仿真的工程,很难快速run起来,因此这里没有让它参与实际测试对比,只对它进行定性对比。
4:对比平台:
软件压缩运行在个人电脑 (Intel Core i7-12700H, 16GB DDR4) 上;
本设计和 HDL-deflate 都部署在Xilinx Artix-7 开发板 上;
5:测试数据
用于对比的待压缩数据是 python 目录下的 raw.hex ,它的大小是 512kB;
6:对比结果
下表展示对比结果:在指标中,↑代表越大越好, ↓代表越小越好;
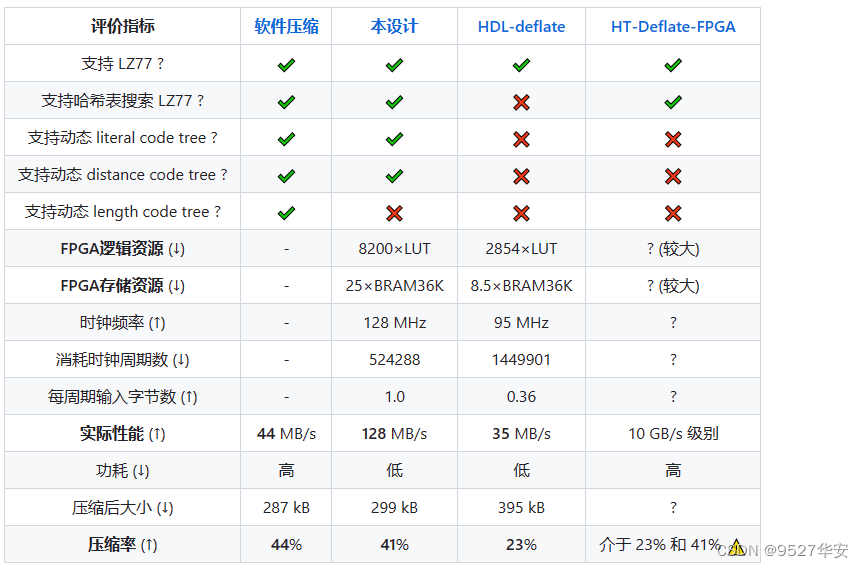
HT-Deflate-FPGA 的压缩率应该高于 HDL-deflate ,但低于本设计。这是根据它所支持的算法特性分析出来的。
8、福利:工程代码的获取
福利:工程代码的获取
代码太大,无法邮箱发送,以某度网盘链接方式发送,
资料获取方式:文章末尾的V名片。
网盘资料如下: