续:rv1109/1126 rknn 模型量化过程_CodingInCV的博客-CSDN博客
Yolov8简介
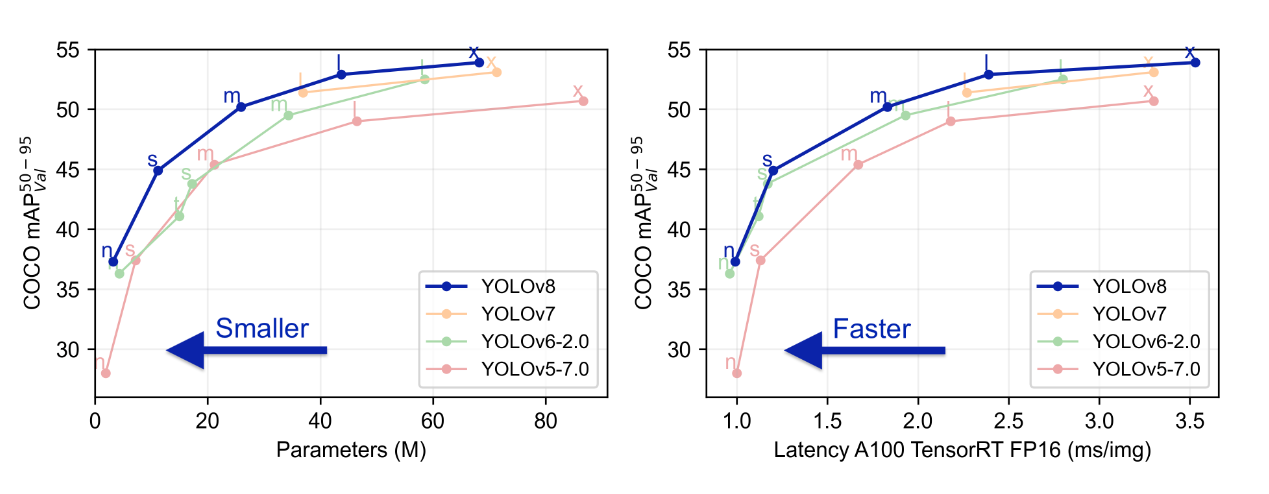
yolov8是比较新的目标检测模型,根据论文和开源项目的报告,相对使用比较广泛的yolov5提升还比较明显。
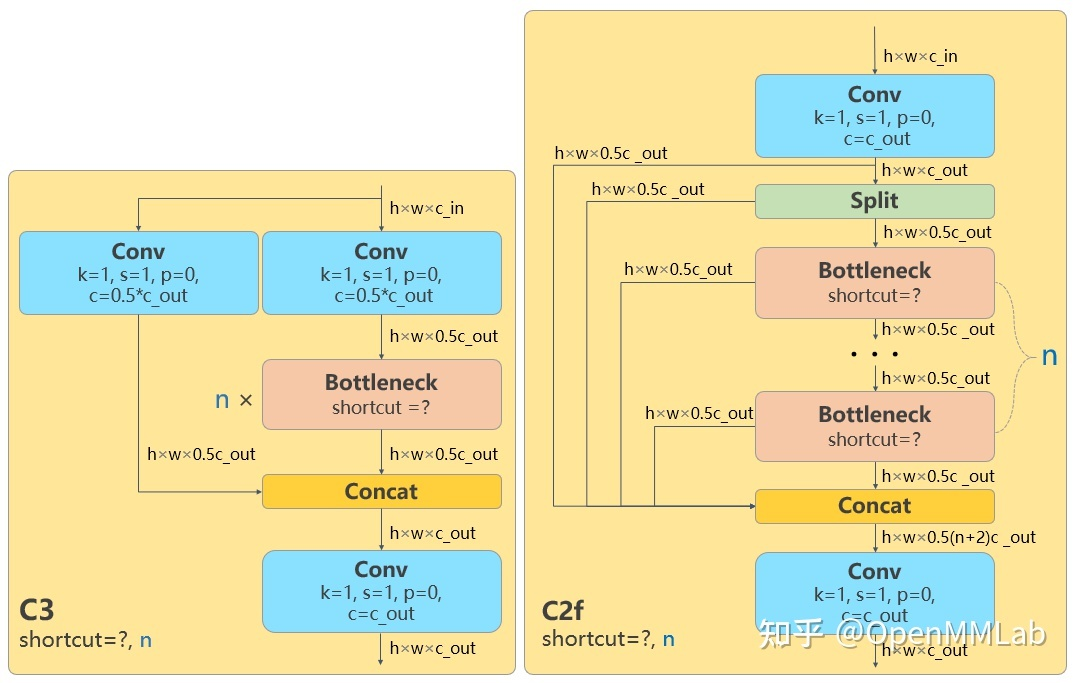
yolov8与yolov5相比,结构上的主要区别是将C3结构换成了C2f,检测头换成了anchor free检测头(详细见:YOLOv8 深度详解!一文看懂,快速上手 - 知乎 (zhihu.com))。
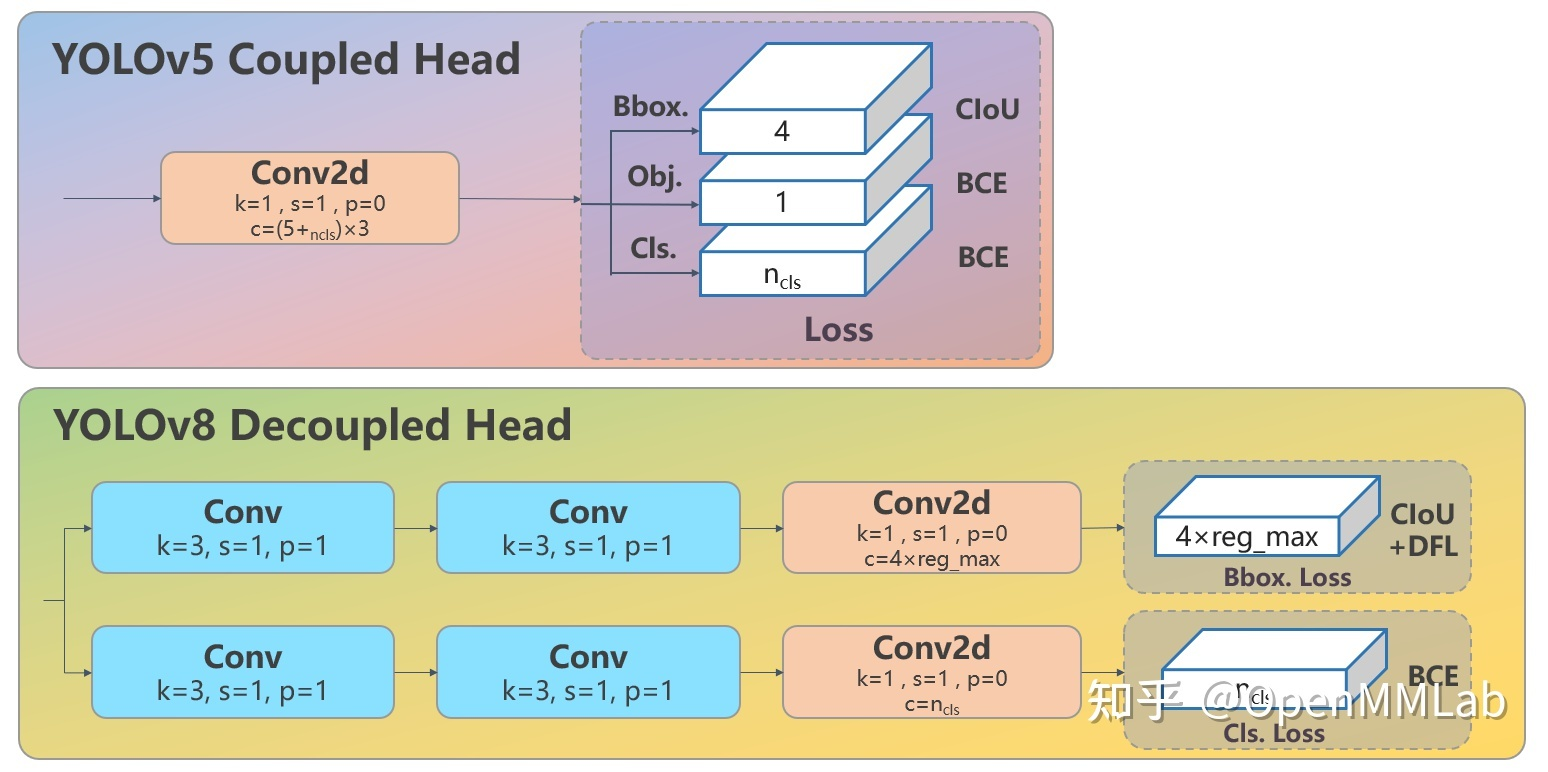
模型转换和量化
模型导出的修改
当我们直接将模型导出为onnx,然后进行量化,我们会发现整个过程是可以进行了,也就是从算子角度来说,rknn是支持yolov8的。但是如果拿量化好的模型进行仿真推理,会发现无法检测到目标(根据我的尝试,若有不同结论,欢迎分享)。
根据分析pytorch的yolov8代码以及观察yolov8的模型结构,会发现,有一部分后处理操作被导出到了onnx模型中:
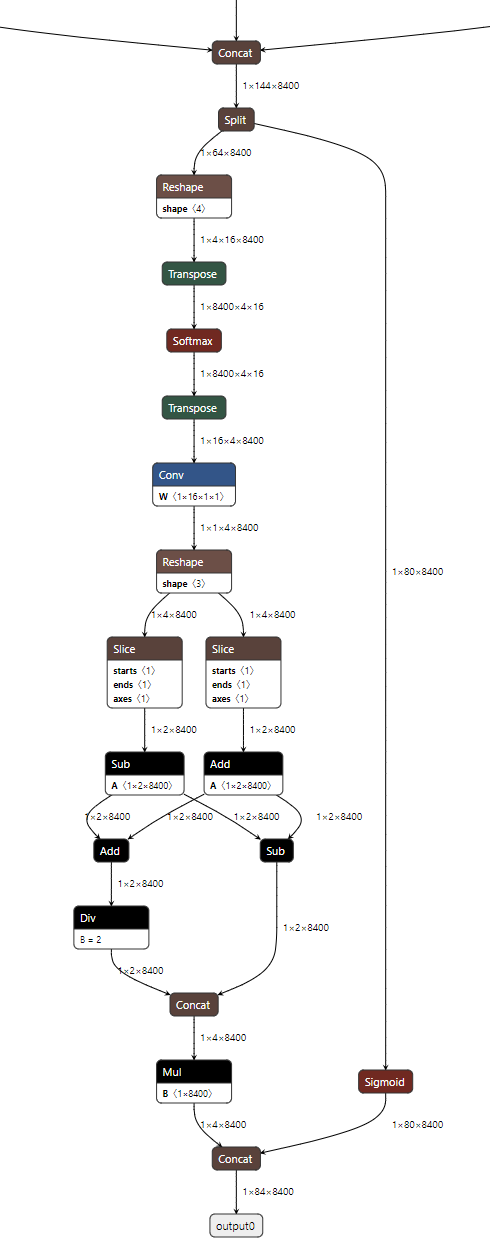
这一部分在训练中是忽略的,只会在推理中存在:
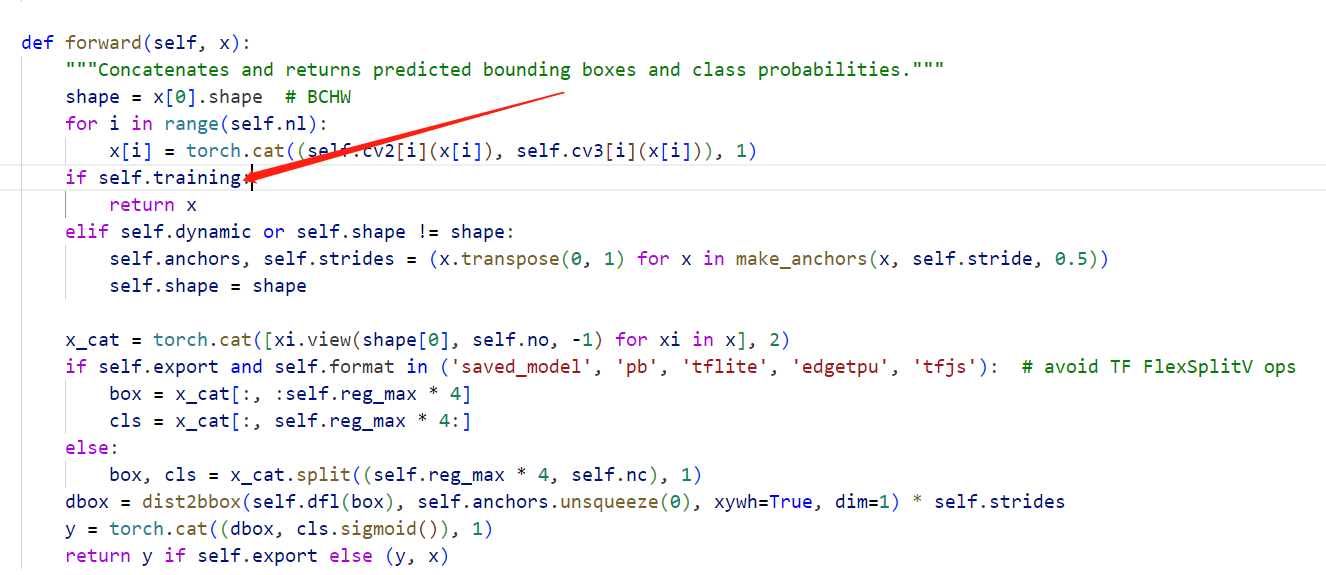
但若我们导出的onnx中包含了这一部分,会参与量化的过程,可能对结果造成了比较大的影响(也是猜测,博主也尝试了混合量化,仍旧没有解决)。既然这部分并没有包含参数信息,我们可以不导出这一部分,而将这一部分作为后处理的一部分自行实现。修改ultralytics/nn/modules/head.py中的条件:
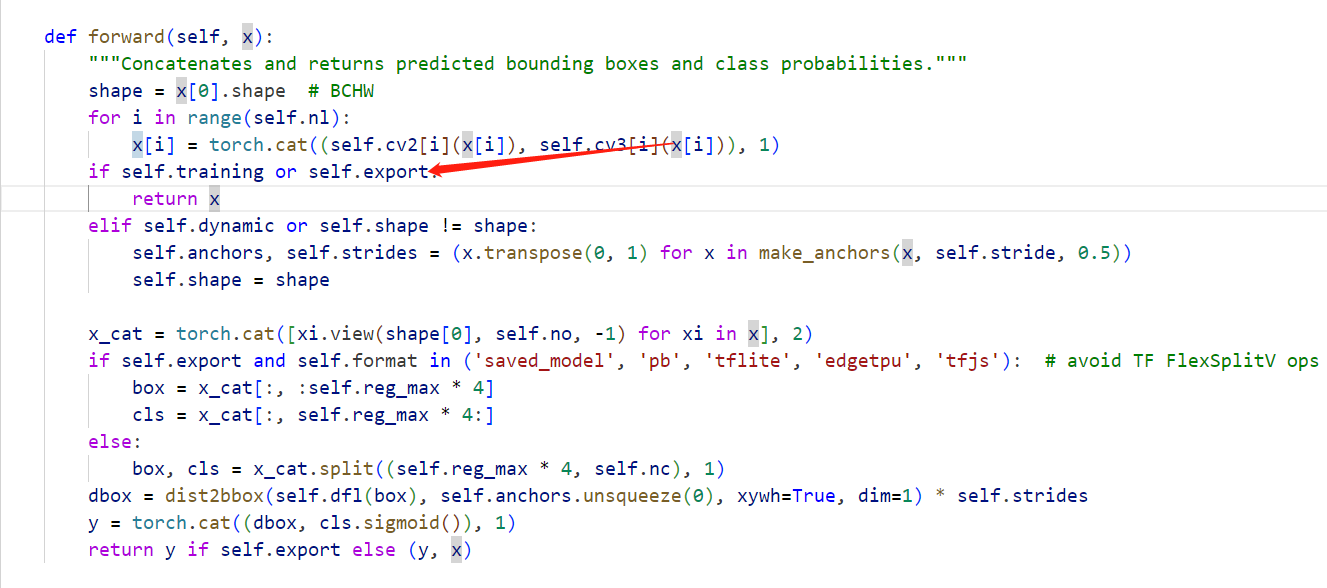
这样我们导出的模型就不包含后处理这部分了,模型输出变成了3个:
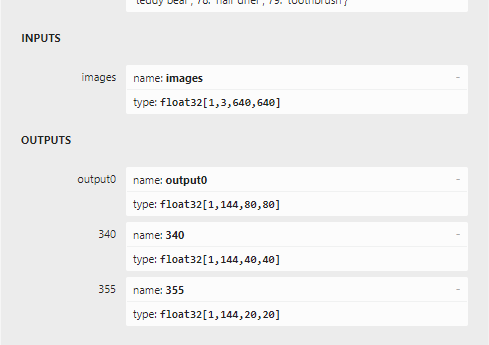
分别是三个特征层的输出(每个都是box层和class层拼接后的结果)。通道数144=16*4(框的4个坐标)+80(coco类别数)。
后处理的实现
改变了模型的输出,就需要我们自己实现这部分后处理了,这部分我们可以参考ultralytics/nn/modules/head.py中的实现,主要的过程:
1.将三个特征层输出拼接得到1x144x8400的特征图,8400=80*80+40*40+20*20
2.将特征图切分为1x64x8400(对于框)和1x80x8400(对于类别)的2个特征图
3.对于框的特征图进行softmax操作后,与1x16x1x1的矩阵进行一个卷积,然后转换为原图上的xywh坐标(1x4x8400),对于类别特征图进行sigmoid操作
4.将2个特征图拼接得到1x84x8400的特征图(与未修改导出前的模型输出一致了)
5.阈值过滤以及nms得到最终的输出。
对于1~4,python(numpy)实现如下:
def xywh2xyxy(x: np.ndarray):
"""
Convert bounding box coordinates from (x, y, width, height) format to (x1, y1, x2, y2) format where (x1, y1) is the
top-left corner and (x2, y2) is the bottom-right corner.
Args:
x (np.ndarray) or (torch.Tensor): The input bounding box coordinates in (x, y, width, height) format.
Returns:
y (np.ndarray) or (torch.Tensor): The bounding box coordinates in (x1, y1, x2, y2) format.
"""
y = np.copy(x)
y[..., 0] = x[..., 0] - x[..., 2] / 2 # top left x
y[..., 1] = x[..., 1] - x[..., 3] / 2 # top left y
y[..., 2] = x[..., 0] + x[..., 2] / 2 # bottom right x
y[..., 3] = x[..., 1] + x[..., 3] / 2 # bottom right y
return y
def make_anchors(feats: np.ndarray, strides, grid_cell_offset=0.5):
"""Generate anchors from features."""
anchor_points, stride_tensor = [], []
assert feats is not None
dtype = feats[0].dtype
for i, stride in enumerate(strides):
_, _, h, w = feats[i].shape
sx = np.arange(stop=w, dtype=dtype) + grid_cell_offset # shift x
sy = np.arange(stop=h, dtype=dtype) + grid_cell_offset # shift y
sx, sy = np.meshgrid(sx, sy)
anchor_points.append(np.stack((sx, sy), -1).reshape(-1, 2))
stride_tensor.append(np.full((h * w, 1), stride, dtype=dtype))
return np.concatenate(anchor_points), np.concatenate(stride_tensor)
def dist2bbox(distance: np.ndarray, anchor_points, xywh=True, dim=-1):
"""Transform distance(ltrb) to box(xywh or xyxy)."""
lt, rb = np.array_split(distance, 2, dim)
x1y1 = anchor_points - lt
x2y2 = anchor_points + rb
if xywh:
c_xy = (x1y1 + x2y2) / 2
wh = x2y2 - x1y1
return np.concatenate((c_xy, wh), dim) # xywh bbox
return np.concatenate((x1y1, x2y2), dim) # xyxy bbox
def softmax(x, axis=-1):
# 计算指数
exp_x = np.exp(x - np.max(x, axis=axis, keepdims=True))
# 计算分母
sum_exp_x = np.sum(exp_x, axis=axis, keepdims=True)
# 计算 softmax
softmax_x = exp_x / sum_exp_x
return softmax_x
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def dfl(x: np.ndarray):
c1 = 16
b, c, a = x.shape
conv = np.arange(0, c1, dtype=np.float32)
conv = conv.reshape(1, 16,1,1)
softmax_x = softmax(x.reshape(b, 4, c1, a).transpose(0,2, 1,3), 1)
return np.sum(softmax_x * conv, 1,keepdims=True).reshape(b, 4, a)
def yolov8_head(x, anchors, nc): # prediction head
strides = [8, 16, 32] # P3, P4, P5 strides
shape = x[0].shape
reg_max = 16
no = nc + reg_max*4 # number of outputs per anchor
anchors, strides = (x.transpose(1, 0) for x in make_anchors(x, strides, 0.5))
x_cat = np.concatenate([xi.reshape(shape[0], no, -1) for xi in x], 2)
box, cls = np.split(x_cat,(reg_max*4,), 1)
dbox = dist2bbox(dfl(box), anchors[np.newaxis,:], xywh=True, dim=1) * strides
y = np.concatenate((dbox, sigmoid(cls)), 1)
return y
对于5:
def yolov8_postprocess(prediction: np.ndarray,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
max_det=300,
nc=0, # number of classes (optional)
max_time_img=0.05,
max_nms=30000,
max_wh=7680,):
assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
if isinstance(prediction, (list, tuple)): # YOLOv8 model in validation model, output = (inference_out, loss_out)
prediction = prediction[0] # select only inference output
bs = prediction.shape[0] # batch size
nc = nc or (prediction.shape[1] - 4) # number of classes
nm = prediction.shape[1] - nc - 4
mi = 4 + nc # mask start index
xc = np.amax(prediction[:, 4:mi], 1) > conf_thres # scores per image
# Settings
# min_wh = 2 # (pixels) minimum box width and height
time_limit = 0.5 + max_time_img * bs # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
output = [np.zeros((0, 6 + nm))] * bs
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[:, 2:4] < min_wh) | (x[:, 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x.transpose(1, 0)[xc[xi]] # confidence
# If none remain process next image
if not x.shape[0]:
continue
# Detections matrix nx6 (xyxy, conf, cls)
box, cls, mask = np.split(x,(4, nc+4,), 1)
box = xywh2xyxy(box) # center_x, center_y, width, height) to (x1, y1, x2, y2)
if multi_label:
i, j = (cls > conf_thres).nonzero(as_tuple=False).T
x = np.concatenate((box[i], x[i, 4 + j, None], j[:, None].float(), mask[i]), 1)
else: # best class only
conf = cls.max(1, keepdims=True)
j = np.argmax(cls, 1, keepdims=True)
x = np.concatenate((box, conf, j.astype(float), mask), 1)[np.squeeze(conf > conf_thres)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
x = x[x[:, 4].argsort()[::-1][:max_nms]] # sort by confidence and remove excess boxes
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes,如果是agnostic,那么就是0,否则就是max_wh,为了对每种类别的框进行NMS
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
# i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
i = cv2.dnn.NMSBoxes(boxes.tolist(), scores.tolist(), conf_thres,
iou_thres).flatten()
i = i[:max_det] # limit detections
output[xi] = x[i]
if (time.time() - t) > time_limit:
break # time limit exceeded
return output
onnx模型推理验证
为了验证我们实现的后处理的正确性,先使用onnx模型推理测试。
import os
import cv2
import onnxruntime
import numpy as np
model = onnxruntime.InferenceSession("weights/yolov8n.onnx",providers=['CUDAExecutionProvider'])
input_name = model.get_inputs()[0].name
image_name="0.jpg"
image = cv2.imread(image_name)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (640,640))
image = image.transpose(2,0,1)
image = image.astype('float32')
image = image/255.0
image = image[np.newaxis,:]
outputs = model.run(None, {input_name: image})
outputs = yolov8_head(outputs, anchors=None, nc=80)
outputs = yolov8_postprocess(outputs, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, multi_label=False, labels=(), max_det=300, nc=0, max_time_img=0.05, max_nms=30000, max_wh=7680)
result = outputs[0]
image = cv2.imread(image_path)
for box in result:
box = box.tolist()
cls = int(box[5])
box[0:4] = [int(i) for i in box[0:4]]
x1 = box[0]
y1 = box[1]
x2 = box[2]
y2 = box[3]
score = box[4]
cv2.rectangle(image, (x1,y1), (x2,y2), (0,0,255), 2)
cv2.putText(image, "{}_{}".format(cls,str(score)), (x1,y1), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 2)
# cv2.imwrite(os.path.join(save_dir, str(not_zeor_cls[0]), image_name), image)
cv2.imshow("image", image)
cv2.waitKey(0)

结果与pytorch执行结果完全一致。
模型量化
步骤参考 rv1109/1126 rknn 模型量化过程_CodingInCV的博客-CSDN博客 采用默认量化方式。
rknn推理
if __name__ == "__main__":
# Create RKNN object
rknn = RKNN()
# Direct load rknn model
print('--> Loading RKNN model')
ret = rknn.load_rknn('/mnt/pai-storage-8/jieshen/code/yolov8/weights/yolov8n_nohead.rknn')
rknn.eval_perf()
if ret != 0:
print('Load failed!')
exit(ret)
rknn.init_runtime()
image = cv2.imread("../coco_resize/0.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
outputs = rknn.inference(inputs=[image])
outputs = yolov8_head(outputs, None, 80)
# print(outputs.shape)
outputs = yolov8_postprocess(outputs, conf_thres=0.25, iou_thres=0.45, max_det=300)
result = outputs[0]
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
for box in result:
box = box.tolist()
cls = int(box[5])
box[0:4] = [int(i) for i in box[0:4]]
x1 = box[0]
y1 = box[1]
x2 = box[2]
y2 = box[3]
score = box[4]
cv2.rectangle(image, (x1,y1), (x2,y2), (0,0,255), 2)
cv2.putText(image, "{}_{}".format(cls,str(score)), (x1,y1), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 2)
# cv2.imwrite(os.path.join(save_dir, str(not_zeor_cls[0]), image_name), image)
cv2.imshow("image", image)
cv2.waitKey(0)
rknn.release()

可以看到检测结果和原模型还是差异挺大的(15是猫,66是键盘),不过结果还是正确的。总体的量化精度有待评估。
结语
通过对导出的模型进行一定的修改,1109上可以实现yolov8的运行并得到检测框,不过最终的运行速度和精度还有待验证。后处理的方式目前也是完全按照pytorch中的实现,过多的concat和split,可能对于C++并不太友好,后续尝试用更好的实现方式。
Todo: 量化精度的测试以及C++部署