[Manticore Search](https://github.com/manticoresoftware/manticoresearch/) 是一个使用 C++ 开发的高性能搜索引擎,创建于 2017 年,其前身是 Sphinx Search 。Manticore Search 充分利用了 Sphinx,显着改进了它的功能,修复了数百个错误,几乎完全重写了代码并保持开源。这一切使 Manticore Search 成为一个现代,快速,轻量级和功能齐全的数据库,具有出色的全文搜索功能。
官网
Manticore Search – easy-to-use open-source fast database for search
介绍
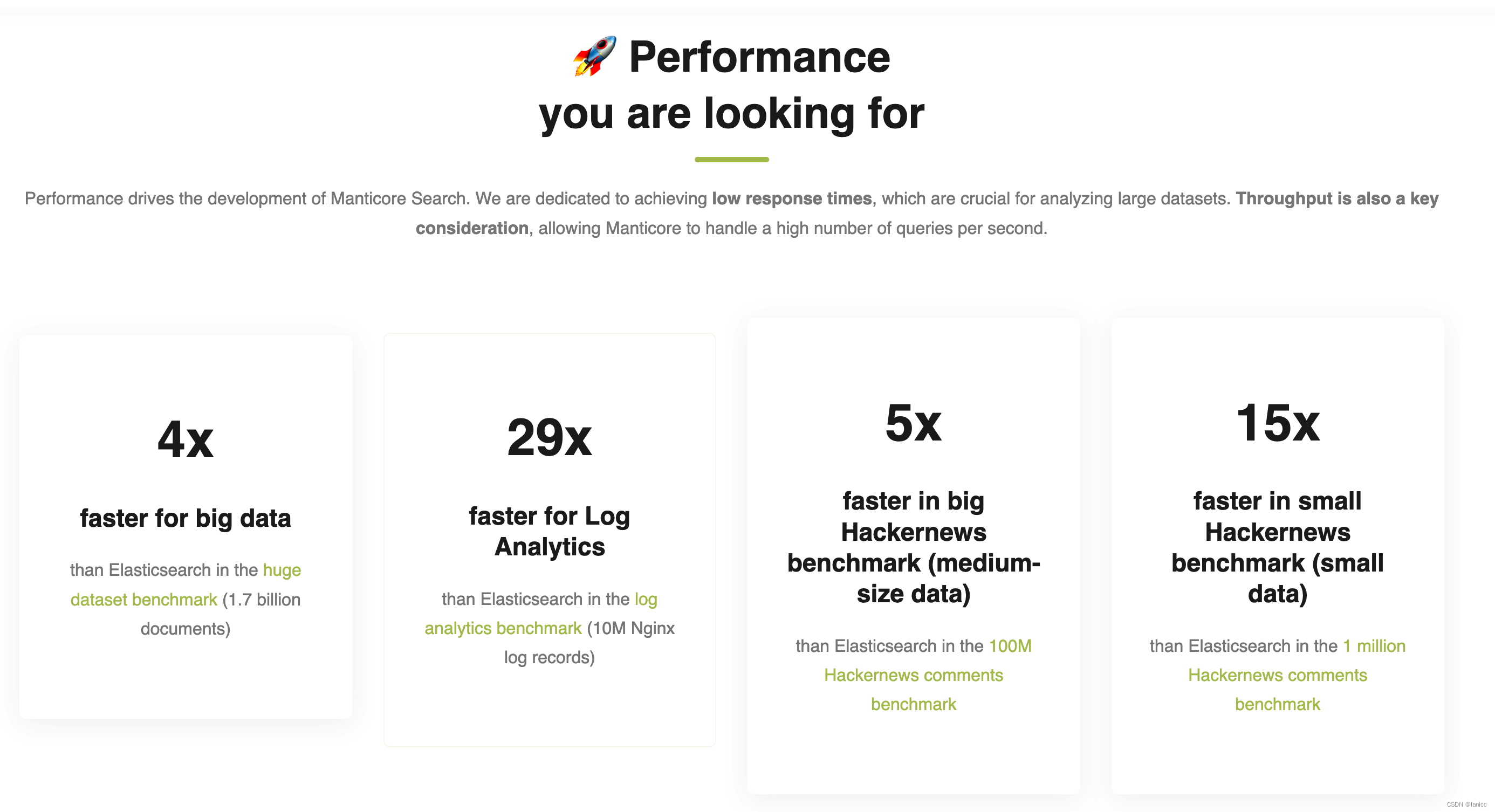
- 对于小型数据集,比Elasticsearch快15倍
- 对于中等大小的数据,比Elasticsearch快5倍
- 对于大型数据,比Elasticsearch快4倍
- 在单个服务器上进行数据导入时,最大吞吐量比Elasticsearch快最多2倍
主要特点
强大而快速的全文搜索,适用于小型和大型数据集
超过20个全文运算符和超过20个排名要素
- 自定义排名
- 词干提取
- 词形还原
- 停用词
- 同义词
- 词形
- 字符和单词级别的高级标记化
- 正确的中文分词
- 文本突出显示
多线程
Manticore Search 利用智能查询并行化来缩短响应时间并在需要时充分利用所有 CPU 核心。
基于成本的查询优化器
基于成本的查询优化器使用有关索引数据的统计数据来评估给定查询的不同执行计划的相对成本。这使得优化器能够确定检索所需结果的最有效计划,同时考虑索引数据的大小、查询的复杂性和可用资源等因素。
存储选项
Manticore 提供行式和列式存储选项,以适应各种大小的数据集。传统和默认的行存储选项适用于所有大小的数据集(小型、中型和大型),而列式存储选项则通过 Manticore 列式库提供,适用于更大的数据集。这些存储选项之间的主要区别在于,行式存储需要将所有属性(不包括全文字段)保留在 RAM 中以获得最佳性能,而列式存储则不需要,因此 RAM 消耗较低,但有可能会稍微降低性能。性能较慢(如https://db-benchmarks.com/上的统计数据所示)。
自动二级索引
Manticore Columnar Library使用分段几何模型索引,它利用了索引键与其在内存中的位置之间的学习映射。这种映射的简洁性,加上独特的递归构造算法,使得 PGM 索引成为一种在空间上以数量级优势统治传统索引的数据结构,同时仍然提供最佳的查询和更新时间性能。默认情况下,所有数字字段的二级索引均处于开启状态。
SQL优先
Manticore 的原生语法是 SQL,它支持 SQL over HTTP 和 MySQL 协议,允许通过任何编程语言的流行 mysql 客户端进行连接。
基于 HTTP 的 JSON
为了采用更具编程性的方法来管理数据和模式,Manticore 提供了HTTP JSON协议,类似于 Elasticsearch 的协议。
与 Elasticsearch 兼容的写入
您可以执行与 Elasticsearch 兼容的插入和替换JSON 查询,从而可以将 Manticore 与 Logstash(版本 < 7.13)、Filebeat 和 Beats 系列的其他工具等工具一起使用。
声明式和命令式模式管理
在线或通过配置文件轻松创建、更新和删除表。
C++ 的优点和 PHP 的便利
Manticore Search 守护进程是用 C++ 开发的,提供快速的启动时间和高效的内存利用率。低级优化的利用进一步提高了性能。另一个关键组件称为Manticore Buddy,它是用 PHP 编写的,用于实现不需要快速响应时间或极高处理能力的高级功能。尽管贡献 C++ 代码可能会带来挑战,但使用 Manticore Buddy 添加新的 SQL/JSON 命令应该是一个简单的过程。
实时插入
新添加或更新的文档可以立即阅读。
内置复制和负载平衡Built-In replication and load balancing
数据可以跨服务器和数据中心分布,任何 Manticore 搜索节点既充当负载均衡器又充当数据节点。Manticore使用Galera库实现虚拟同步多主,确保所有节点之间的数据一致性,防止数据丢失,并提供卓越的复制性能。
内置备份功能Built-in backup capabilities
Manticore 配备了外部工具和 SQL 命令来简化备份和恢复数据的过程。
开箱即用的数据同步Out-of-the-box data sync
Manticore 的工具和全面的配置语法可以轻松同步来自 MySQL、PostgreSQL、兼容 ODBC 的数据库、XML 和 CSV 等源的数据。