🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章
| 大数据分析案例-基于随机森林算法预测人类预期寿命 |
| 大数据分析案例-基于随机森林算法的商品评价情感分析 |
| 大数据分析案例-用RFM模型对客户价值分析(聚类) |
| 大数据分析案例-对电信客户流失分析预警预测 |
| 大数据分析案例-基于随机森林模型对北京房价进行预测 |
| 大数据分析案例-基于RFM模型对电商客户价值分析 |
| 大数据分析案例-基于逻辑回归算法构建垃圾邮件分类器模型 |
| 大数据分析案例-基于决策树算法构建员工离职预测模型 |
| 大数据分析案例-基于KNN算法对茅台股票进行预测 |
| 大数据分析案例-基于多元线性回归算法构建广告投放收益模型 |
| 大数据分析案例-基于随机森林算法构建返乡人群预测模型 |
| 大数据分析案例-基于决策树算法构建金融反欺诈分类模型 |
目录
1.项目背景
2.项目简介
2.1项目说明
2.2数据说明
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2数据预处理
4.3探索性数据分析
4.3.1目标变量分析
4.3.2类别性变量分析
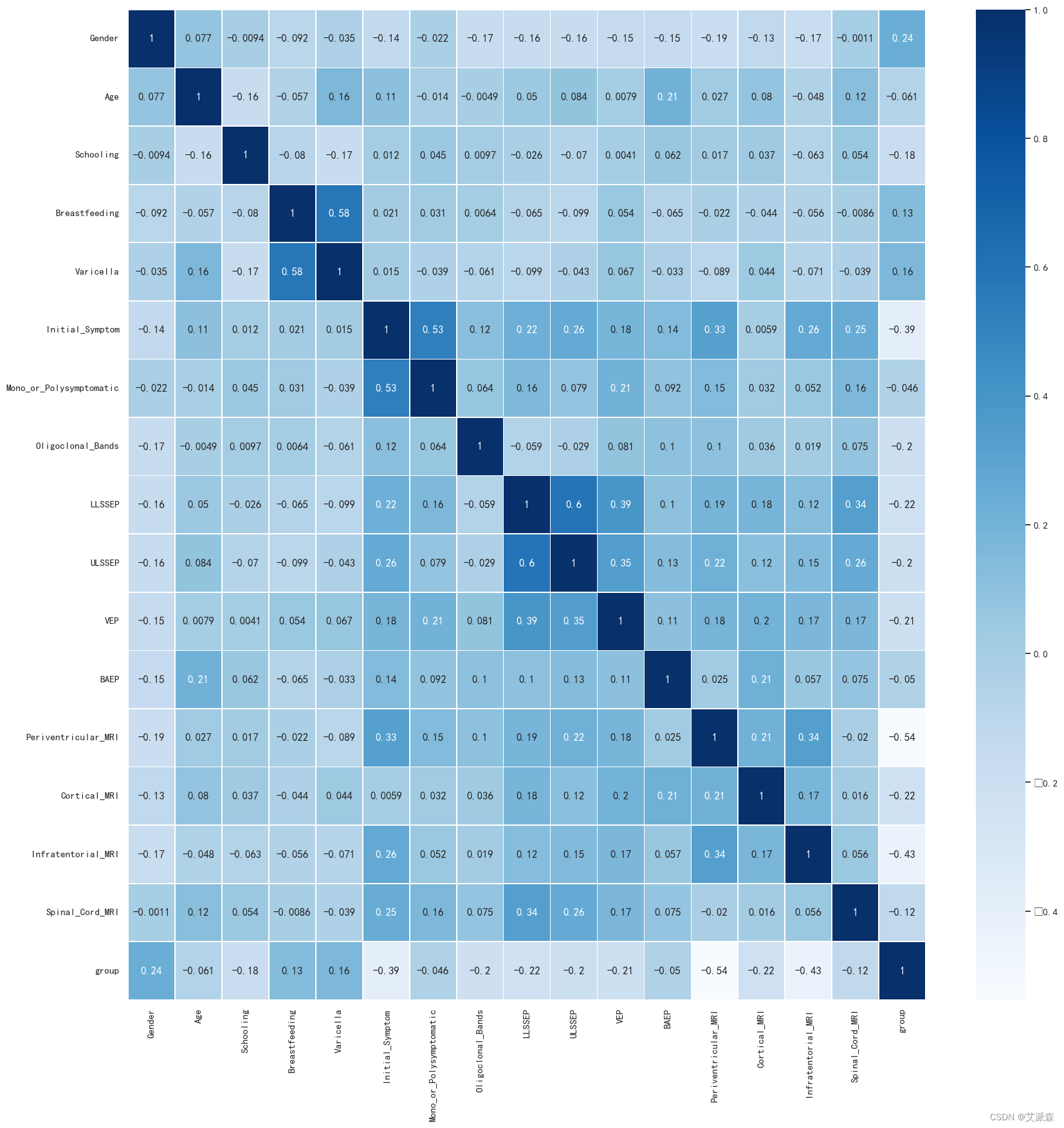
4.3.3相关性分析
4.4特征工程
4.5模型构建
4.6模型评估
4.7模型预测
5.实验总结
源代码
1.项目背景
多发性硬化症(Multiple Sclerosis,简称MS)是一种常见的中枢神经系统慢性炎症性疾病,通常表现为自身免疫攻击引起的神经髓鞘损害。这种损害会导致神经冲动传导障碍,进而导致一系列不同严重程度的神经功能缺陷,如肌无力、感觉异常、视觉障碍和平衡问题等。
MS的病因尚未完全明确,但据认为是由遗传和环境因素相互作用引起的。尽管已有许多研究对其病理生理学和发病机制进行了深入探究,但对于个体患病风险的预测仍然是一个具有挑战性的问题。
随机森林算法是一种强大的机器学习方法,它能够处理高维数据和复杂的关联关系。随机森林结合了多个决策树,通过随机特征选择和多样性集成的方式来提高模型的准确性和鲁棒性。因此,基于随机森林算法构建MS预测模型可以帮助我们识别患有MS风险较高的人群,为早期干预和治疗提供依据。
在现有研究中,已经有一些尝试使用机器学习算法构建MS预测模型。然而,许多早期的研究可能由于数据规模较小或特征选择不当而导致模型的准确性和泛化能力不足。因此,我们需要更大规模的数据集和更精确的特征选择,来构建更可靠的MS预测模型。
本实验旨在利用随机森林算法,结合临床数据和生物标志物信息,构建一种准确可靠的多发性硬化症预测模型。通过该模型,我们希望能够识别患有MS风险较高的人群,为早期干预、治疗和管理提供有效的辅助决策工具。同时,该实验也有望深化对多发性硬化症发病机制的认识,为进一步研究和治疗提供新的线索和方向。
2.项目简介
2.1项目说明
本项目旨在通过分析多发性硬化症数据集,找出影响发病确诊的因素,最后使用传统机器学习算法构建发病预测模型,通过该模型,我们希望能够识别患有MS风险较高的人群,为早期干预、治疗和管理提供有效的辅助决策工具。
2.2数据说明
本实验数据集来源于Kaggle,原始数据集中共有273条数据,19列变量,各变量具体含义如下:
Age:患者的年龄(岁)
Schooling:患者在学校的时间(以年为单位)
Gender:1=男,2=女
Breastfeeding:1=是,2=否,3=未知
Varicella:1=阳性,2=阴性,3=未知
Initial_Symptom:1=视觉,2=感觉,3=运动,4=其他,5=视觉和感觉,6=视觉和运动,7=视觉和其他,8=感觉和运动,9=感觉和其他,10=运动和其他, 11=视觉、感觉和运动, 12=视觉、感觉和其他, 13=视觉、运动和其他, 14=感觉、运动和其他, 15=视觉、感觉、运动和其他
Mono_or_Polysymptomatic:1=单症状,2=多症状,3=未知
Oligoclonal_Bands:0=阴性,1=阳性,2=未知
LLSSEP:0=负,1=正
ULSSEP:0=负,1=正
VEP:0=阴性,1=阳性
BAEP:0=阴性,1=阳性
Periventricular_MRI:0=阴性,1=阳性
Cortical_MRII:0=阴性,1=阳性
Infratentorial_MRI:0=阴性,1=阳性
Spinal_Cord_MRI:0=阴性,1=阳性
初始_EDSS:?
最终_EDSS:?
组别:1=CDMS,2=非 CDMS
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
随机森林是一种有监督学习算法。就像它的名字一样,它创建了一个森林,并使它拥有某种方式随机性。所构建的“森林”是决策树的集成,大部分时候都是用“bagging”方法训练的。bagging 方法,即 bootstrapaggregating,采用的是随机有放回的选择训练数据然后构造分类器,最后组合学习到的模型来增加整体的效果。简而言之,随机森林建立了多个决策树,并将它们合并在一起以获得更准确和稳定的预测。其一大优势在于它既可用于分类,也可用于回归问题,这两类问题恰好构成了当前的大多数机器学习系统所需要面对的。
随机森林分类器使用所有的决策树分类器以及 bagging 分类器的超参数来控制整体结构。与其先构建 bagging分类器,并将其传递给决策树分类器,我们可以直接使用随机森林分类器类,这样对于决策树而言,更加方便和优化。要注意的是,回归问题同样有一个随机森林回归器与之相对应。
随机森林算法中树的增长会给模型带来额外的随机性。与决策树不同的是,每个节点被分割成最小化误差的最佳指标,在随机森林中我们选择随机选择的指标来构建最佳分割。因此,在随机森林中,仅考虑用于分割节点的随机子集,甚至可以通过在每个指标上使用随机阈值来使树更加随机,而不是如正常的决策树一样搜索最佳阈值。这个过程产生了广泛的多样性,通常可以得到更好的模型。
4.项目实施步骤
4.1理解数据
首先导入数据挖掘基本必备的一些第三方库,接着导入数据集,查看前五行
查看数据大小
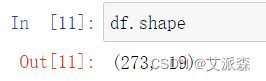
查看数据基本信息

查看数值型变量的描述性统计
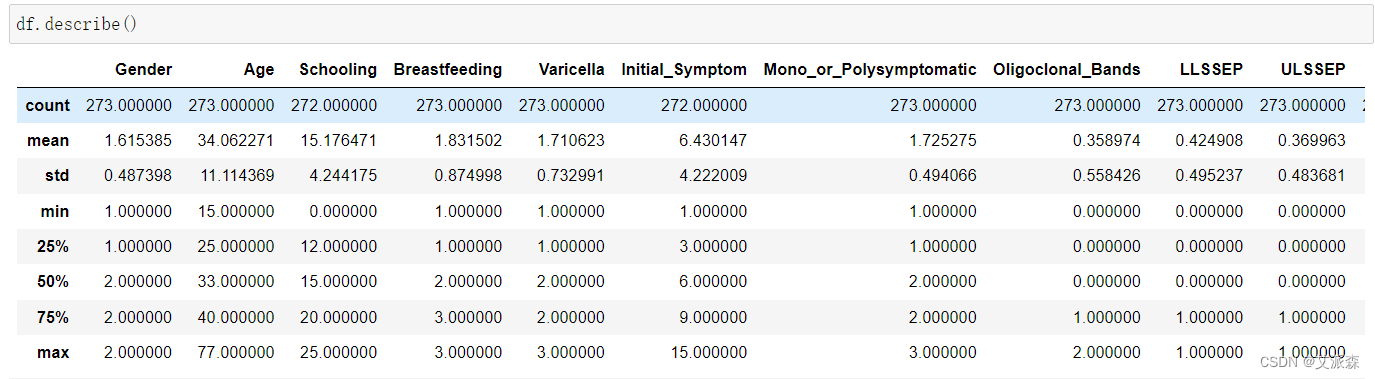
通过描述性统计,我们可以看出各变量的均值方差分位数等数值。
4.2数据预处理
统计数据集缺失值情况
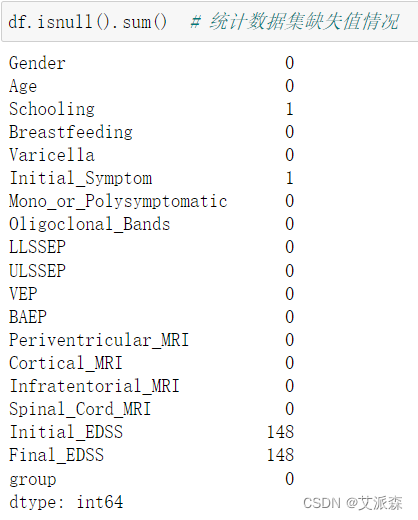
发现'Initial_EDSS'和'Final_EDSS'这两列变量缺失太多,所以我们直接删除列,然后再删除缺失值
 检测数据集中是否存在重复值,结果为False,说明不存在重复值
检测数据集中是否存在重复值,结果为False,说明不存在重复值

4.3探索性数据分析
4.3.1目标变量分析
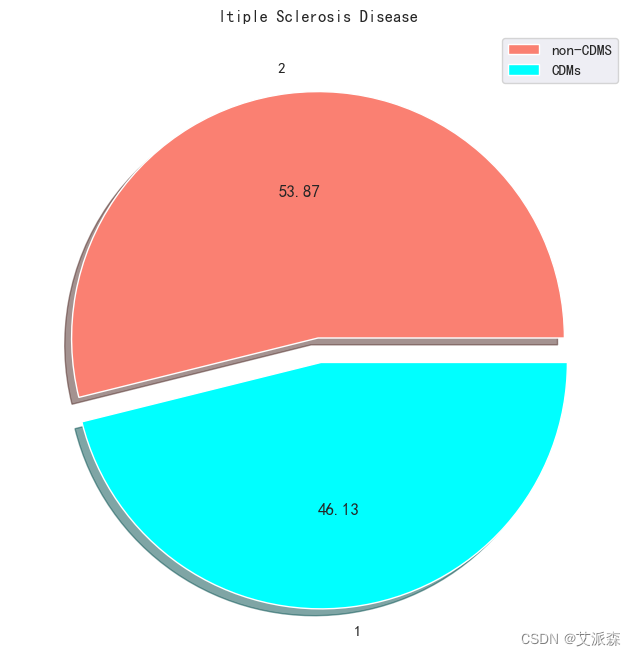
4.3.2类别性变量分析

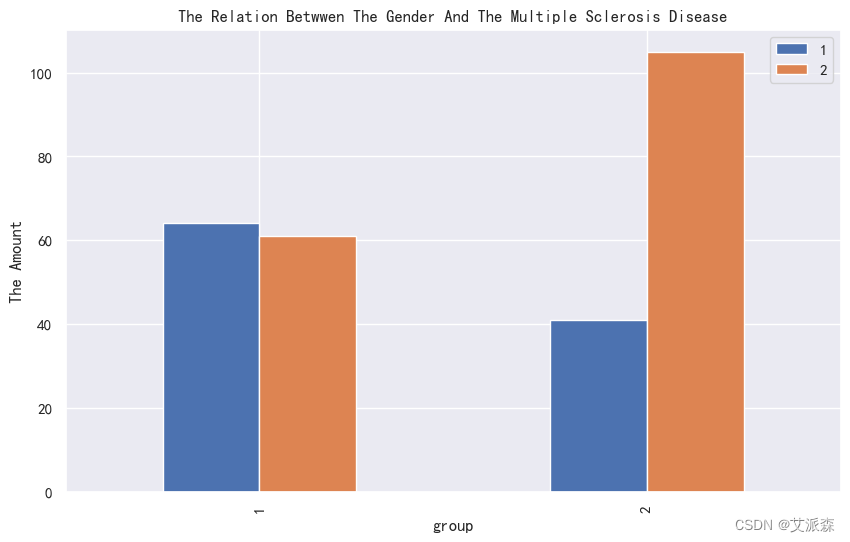
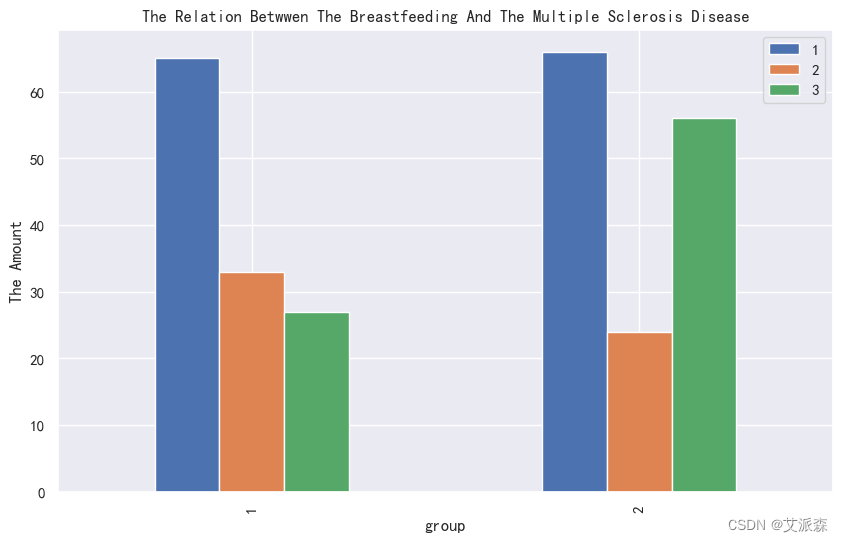
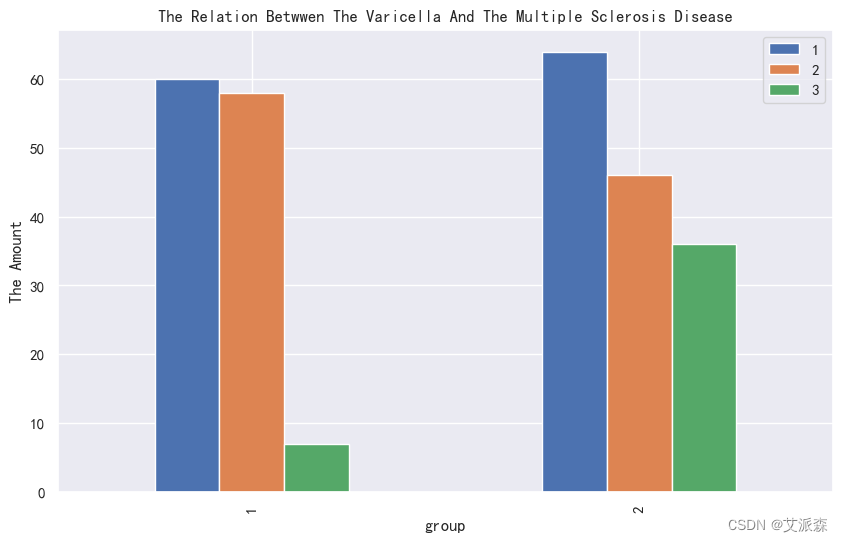

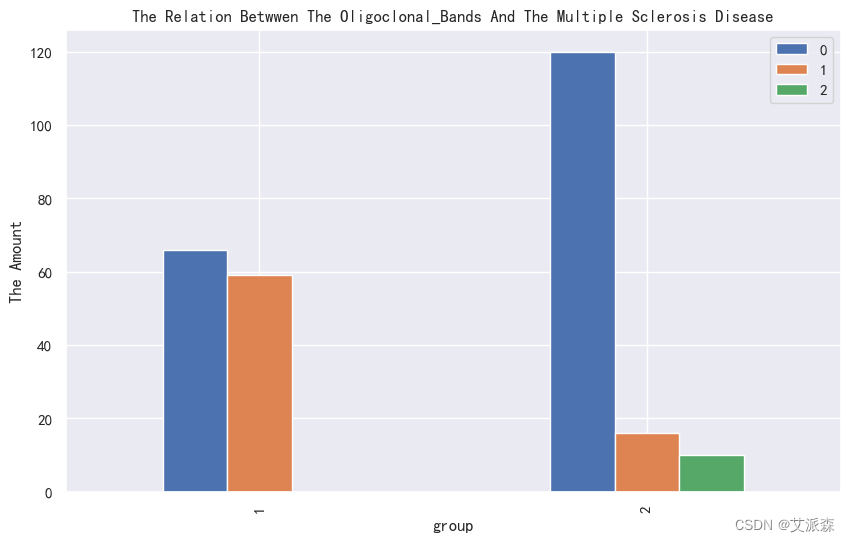
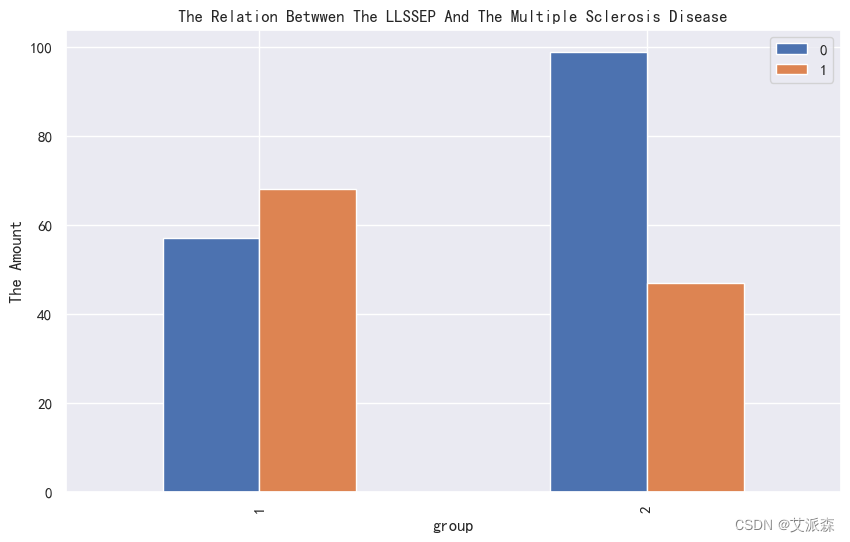
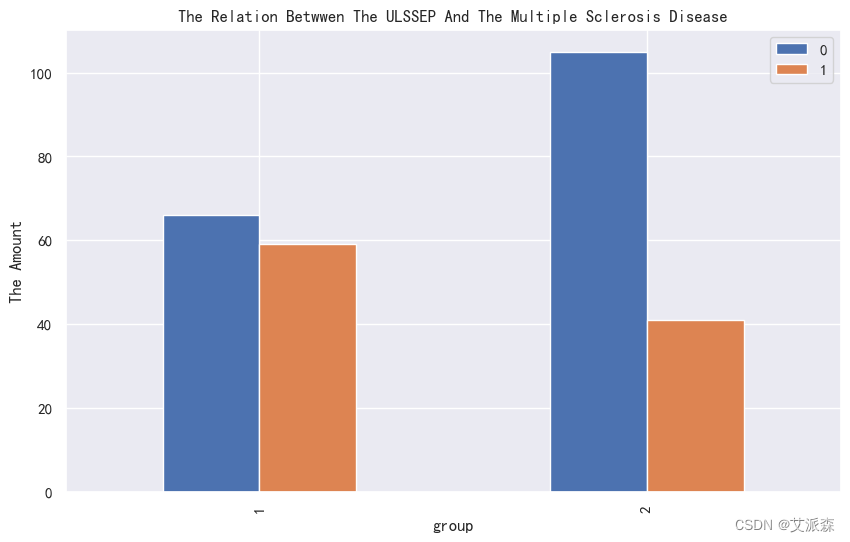
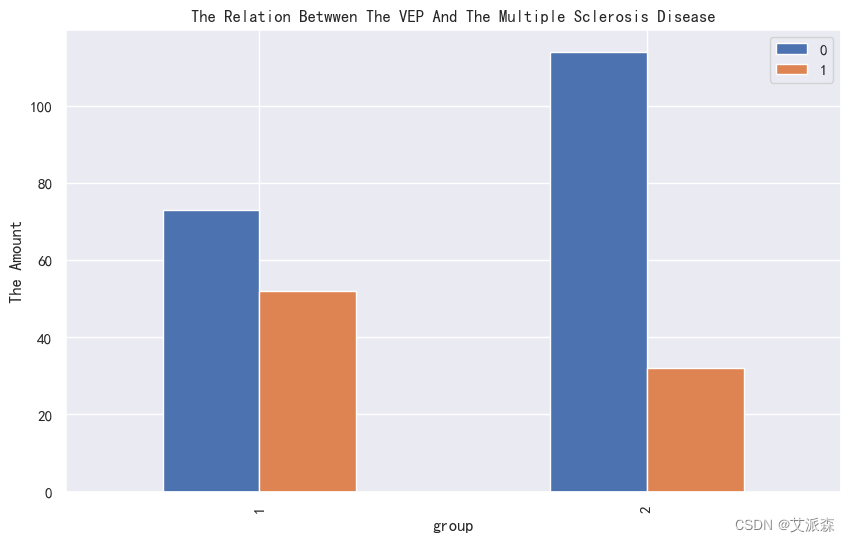
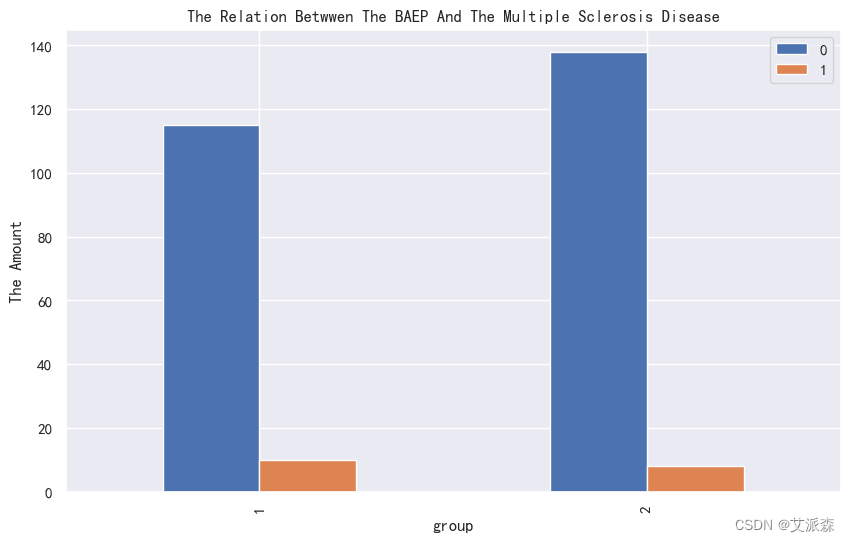
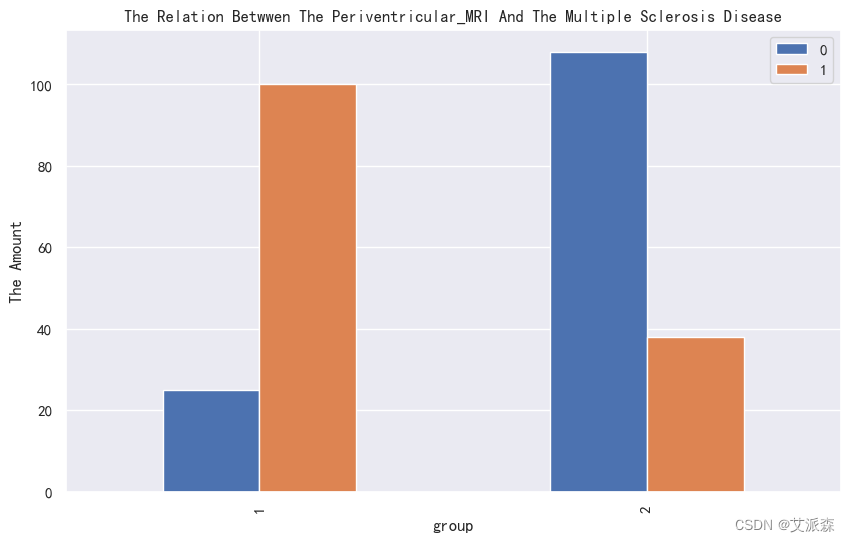
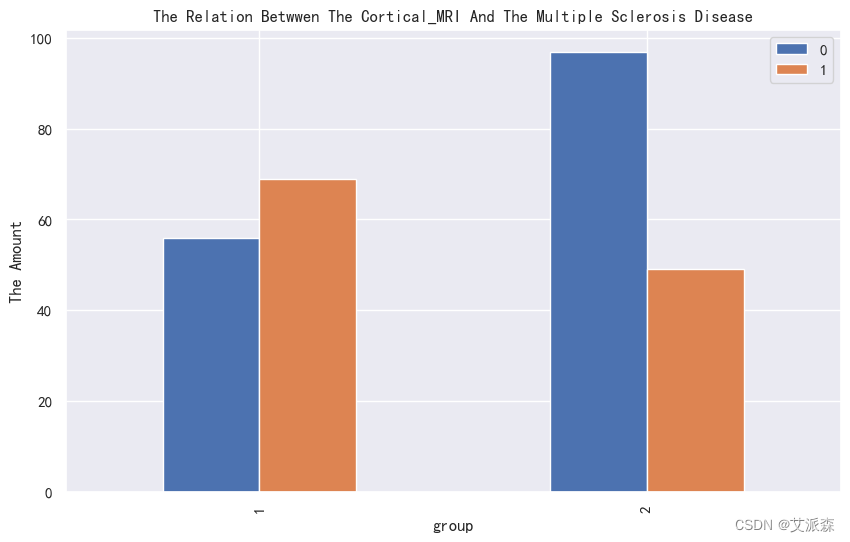
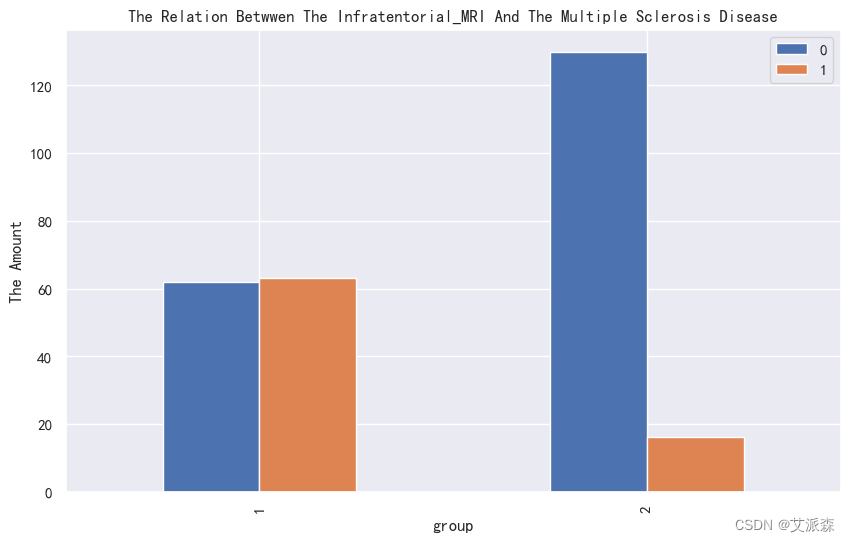
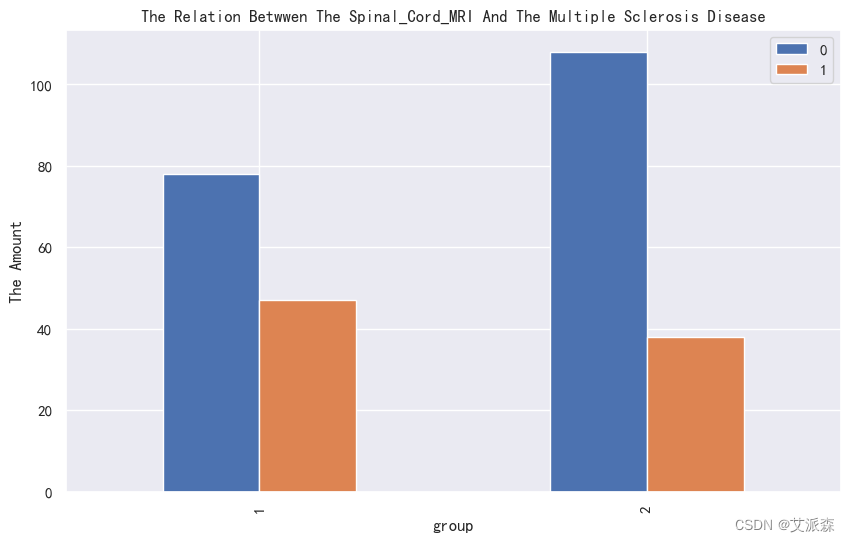
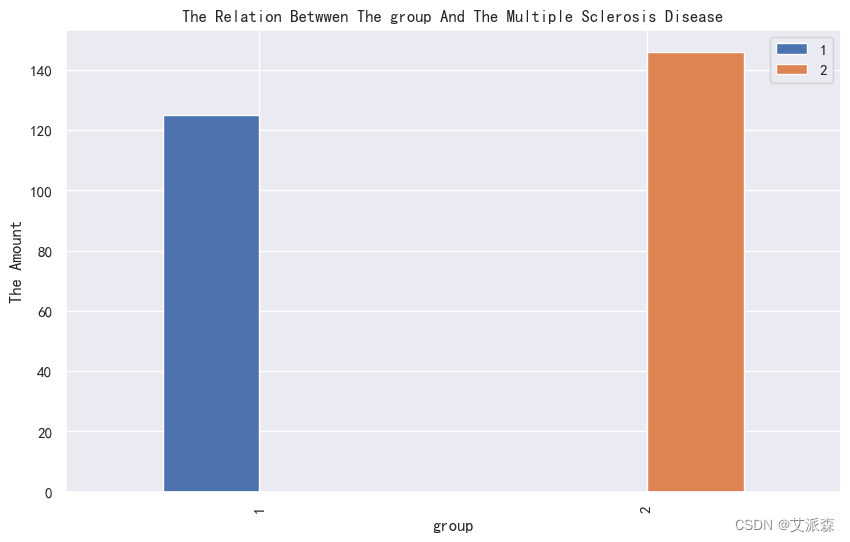

4.3.3相关性分析

4.4特征工程
首先需要准备建模需要对数据,接着拆分数据集为训练集和测试集

4.5模型构建
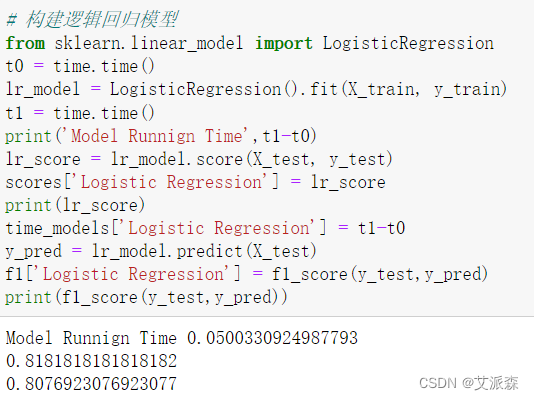
在构建模型之前,我们先用三个字典来存放模型的准确率、运行时间和F1值,最后用来对比。

接着开始构建模型
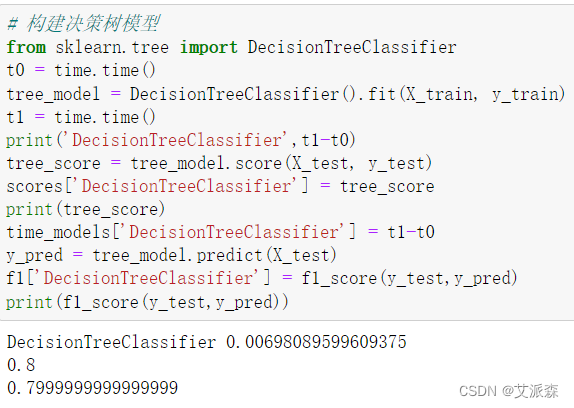
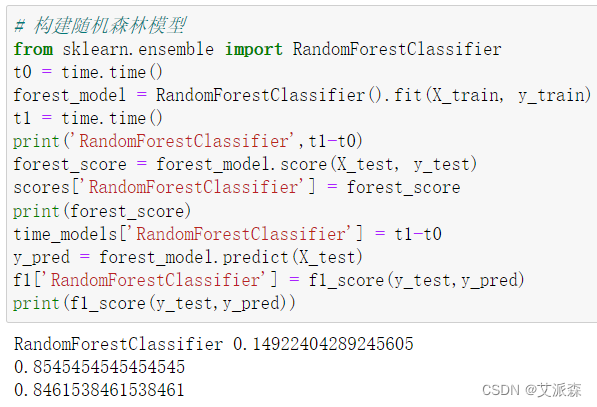
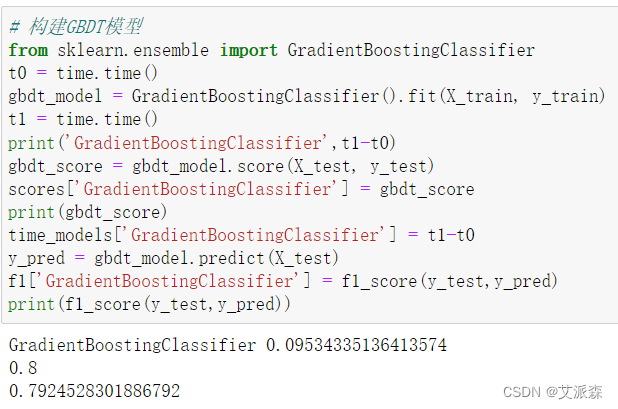
4.6模型评估
前面我们构建了6个模型,现在来评估各指标选择最适合的模型
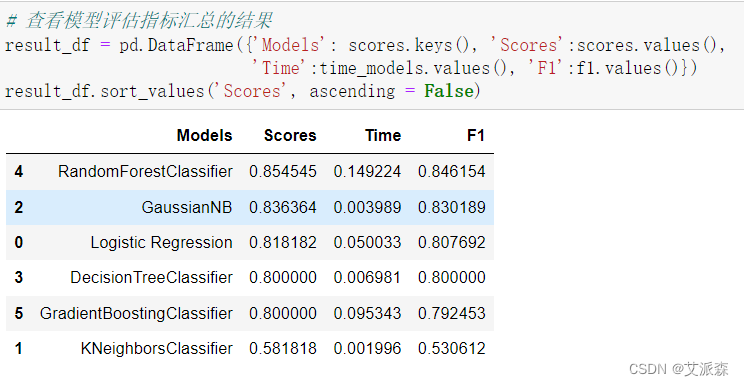
从结果看出,随机森林准确率和F1值 都是排在第一,唯一不足就是训练时间长,本次实验样本不多,可以选用随机森林,如果样本大的话,可以训练时间短的模型。
接着我们打印出随机森林模型的混淆矩阵和分类报告
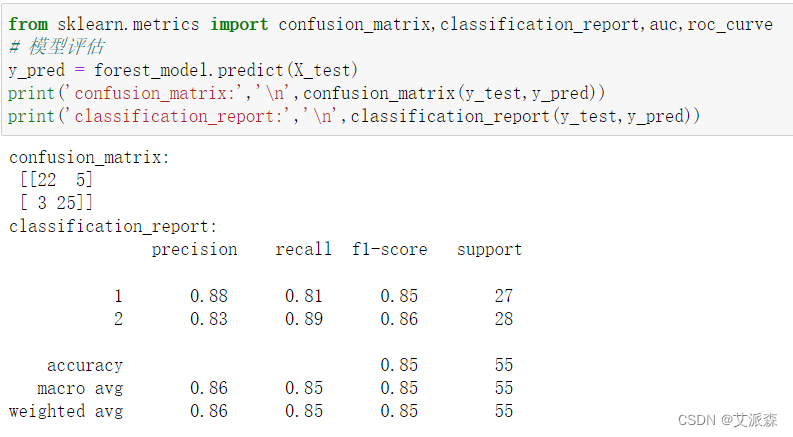
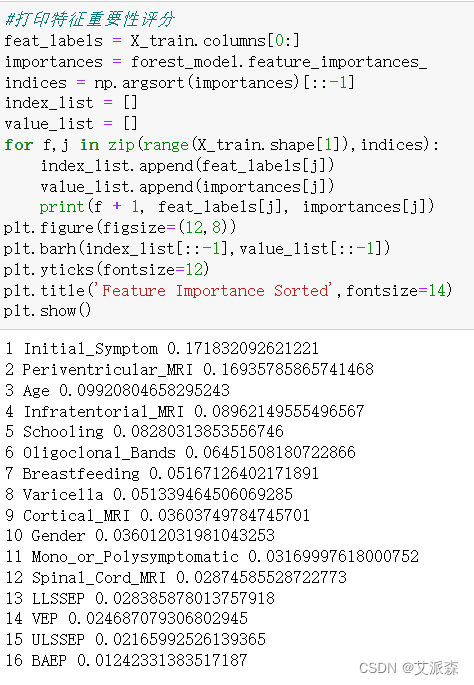
打印特征重要性评分

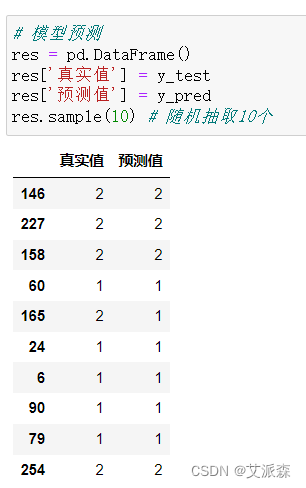
4.7模型预测
随机抽取10个预测结果来检验模型效果,发现10个错了一个,效果还不错。
5.实验总结
在本实验中,我们成功地利用随机森林算法构建了一种多发性硬化症(MS)预测模型,并通过大规模的临床数据和生物标志物信息进行了验证和评估。以下是本实验的主要总结:
-
数据收集与预处理:我们收集了包括临床数据、生物标志物信息和神经影像学数据在内的大量数据,并进行了数据清洗、处理缺失值和特征选择等预处理步骤,确保了数据的质量和可用性。
-
随机森林算法构建:我们选择了随机森林算法作为预测模型的建模工具。随机森林能够有效地处理高维数据和复杂的关联关系,并通过集成多个决策树来提高模型的准确性和鲁棒性。
-
模型评估:我们使用了多种指标对模型进行了评估,包括准确率、召回率、F1分数等。评估结果显示,该预测模型具有较高的分类性能和预测准确度。
-
特征重要性分析:通过对模型的特征重要性进行分析,我们深入了解了哪些因素对于多发性硬化症的预测起到了关键作用。这有助于增进我们对MS发病机制的认识,并为后续的研究提供新的线索和方向。
-
应用前景:该预测模型为早期多发性硬化症的诊断和干预提供了重要的辅助决策工具。通过识别风险较高的患者群体,临床医生可以更早地采取治疗措施,有助于改善患者的预后和生活质量。
-
伦理与隐私保护:在整个实验过程中,我们始终遵守了伦理规范和隐私保护要求,确保患者数据的安全和保密,数据仅用于科学研究目的。
-
局限性与展望:尽管我们在实验中取得了显著的成果,但仍存在一些局限性。例如,模型的训练数据可能受到样本不平衡问题的影响,未来可以通过更多样本的采集和合成来解决这个问题。此外,随着科学技术的进步和数据的不断积累,我们有望进一步优化和改进预测模型,提高其准确性和泛化能力。
综上所述,本实验通过基于随机森林算法构建了一种准确可靠的多发性硬化症预测模型,为临床诊断和治疗提供了重要的支持和指导。该实验的成功展示了机器学习在医学领域的巨大潜力,为未来更深入的研究和应用提供了坚实的基础。通过我们的不懈努力,有望为多发性硬化症患者带来更好的医疗服务和健康福祉。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font='SimHei')
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('data.csv')
df.head()
df.shape
df.info()
df.describe()
df.isnull().sum() # 统计数据集缺失值情况
df.drop(['Initial_EDSS','Final_EDSS'],axis=1,inplace=True) # 删除缺失值太多的列
df.dropna(inplace=True) # 删除缺失值
df.shape
any(df.duplicated()) # 检测数据集中是否存在重复值
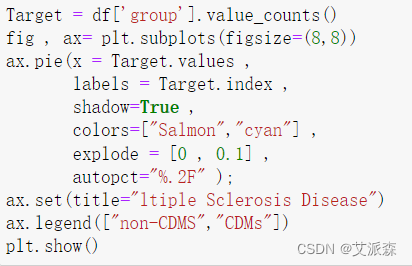
Target = df['group'].value_counts()
fig , ax= plt.subplots(figsize=(8,8))
ax.pie(x = Target.values ,
labels = Target.index ,
shadow=True ,
colors=["Salmon","cyan"] ,
explode = [0 , 0.1] ,
autopct="%.2F" );
ax.set(title="ltiple Sclerosis Disease")
ax.legend(["non-CDMS","CDMs"])
plt.show()
catogary = ['Gender','Breastfeeding', 'Varicella', 'Mono_or_Polysymptomatic', 'Oligoclonal_Bands',
'LLSSEP', 'ULSSEP', 'VEP', 'BAEP', 'Periventricular_MRI',
'Cortical_MRI', 'Infratentorial_MRI', 'Spinal_Cord_MRI', 'group']
for i in catogary :
cat= pd.crosstab(df["group"], df[i])
cat.plot(kind="bar" ,
figsize=(10,6),
title=f"The Relation Betwwen The {i} And The Multiple Sclerosis Disease")
plt.ylabel("The Amount")
plt.legend()
fig,axes = plt.subplots(nrows = 2,ncols = 3,figsize=(20,10))
sns.boxplot(ax=axes[0,0],x='Initial_Symptom',data = df[df['group']==1])
sns.boxplot(ax = axes[0,1],x='Gender',y='Schooling',data = df,hue = 'group', palette='Set2');
sns.countplot(ax = axes[0,2],x='Varicella',data = df[df['Varicella']!=3],hue = 'group', palette='Set1');
sns.countplot(ax = axes[1,0],x='LLSSEP',data = df,hue = 'group', palette='deep');
sns.countplot(ax = axes[1,1],x='ULSSEP',data = df,hue = 'group', palette='YlOrRd');
sns.countplot(ax= axes[1,2],x='BAEP',data = df,hue = 'group',palette='RdYlGn_r');
axes[0,0].title.set_text('Initial_Symptom')
axes[0,1].title.set_text('Relationship between Gender and Schooling')
axes[0,2].title.set_text('Relationship between Varicella and group')
axes[1,0].title.set_text('Relationship between LLSSEP and group')
axes[1,1].title.set_text('Relationship between ULSSEP and group')
axes[1,2].title.set_text('Relationship between BAEP and group')
fig, ax = plt.subplots(figsize=(20,20))
dataplot=sns.heatmap(df.corr() ,
annot=True ,
linewidths=0.5 ,
cmap = "Blues")
plt.show()
from sklearn.model_selection import train_test_split
# 准备数据
X = df.drop('group',axis=1)
y = df['group']
# 拆分数据
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
print(f'训练集大小:',X_train.shape[0])
print(f'测试集大小:',X_test.shape[0])
import time
from sklearn.metrics import f1_score
scores = dict()
time_models = dict()
f1 = dict()
# 构建逻辑回归模型
from sklearn.linear_model import LogisticRegression
t0 = time.time()
lr_model = LogisticRegression().fit(X_train, y_train)
t1 = time.time()
print('Model Runnign Time',t1-t0)
lr_score = lr_model.score(X_test, y_test)
scores['Logistic Regression'] = lr_score
print(lr_score)
time_models['Logistic Regression'] = t1-t0
y_pred = lr_model.predict(X_test)
f1['Logistic Regression'] = f1_score(y_test,y_pred)
print(f1_score(y_test,y_pred))
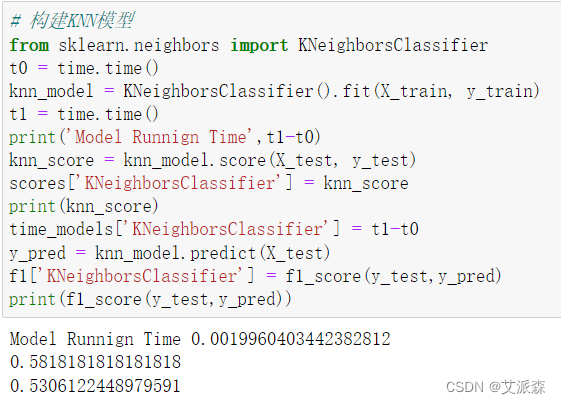
# 构建KNN模型
from sklearn.neighbors import KNeighborsClassifier
t0 = time.time()
knn_model = KNeighborsClassifier().fit(X_train, y_train)
t1 = time.time()
print('Model Runnign Time',t1-t0)
knn_score = knn_model.score(X_test, y_test)
scores['KNeighborsClassifier'] = knn_score
print(knn_score)
time_models['KNeighborsClassifier'] = t1-t0
y_pred = knn_model.predict(X_test)
f1['KNeighborsClassifier'] = f1_score(y_test,y_pred)
print(f1_score(y_test,y_pred))
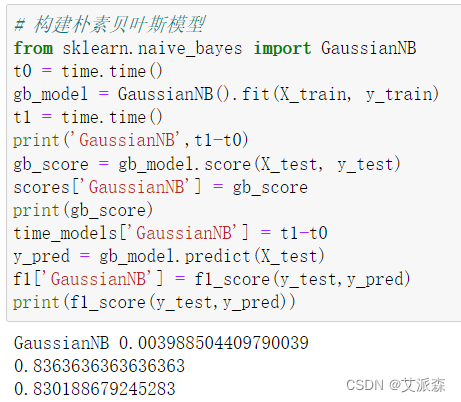
# 构建朴素贝叶斯模型
from sklearn.naive_bayes import GaussianNB
t0 = time.time()
gb_model = GaussianNB().fit(X_train, y_train)
t1 = time.time()
print('GaussianNB',t1-t0)
gb_score = gb_model.score(X_test, y_test)
scores['GaussianNB'] = gb_score
print(gb_score)
time_models['GaussianNB'] = t1-t0
y_pred = gb_model.predict(X_test)
f1['GaussianNB'] = f1_score(y_test,y_pred)
print(f1_score(y_test,y_pred))
# 构建决策树模型
from sklearn.tree import DecisionTreeClassifier
t0 = time.time()
tree_model = DecisionTreeClassifier().fit(X_train, y_train)
t1 = time.time()
print('DecisionTreeClassifier',t1-t0)
tree_score = tree_model.score(X_test, y_test)
scores['DecisionTreeClassifier'] = tree_score
print(tree_score)
time_models['DecisionTreeClassifier'] = t1-t0
y_pred = tree_model.predict(X_test)
f1['DecisionTreeClassifier'] = f1_score(y_test,y_pred)
print(f1_score(y_test,y_pred))
# 构建随机森林模型
from sklearn.ensemble import RandomForestClassifier
t0 = time.time()
forest_model = RandomForestClassifier().fit(X_train, y_train)
t1 = time.time()
print('RandomForestClassifier',t1-t0)
forest_score = forest_model.score(X_test, y_test)
scores['RandomForestClassifier'] = forest_score
print(forest_score)
time_models['RandomForestClassifier'] = t1-t0
y_pred = forest_model.predict(X_test)
f1['RandomForestClassifier'] = f1_score(y_test,y_pred)
print(f1_score(y_test,y_pred))
# 构建GBDT模型
from sklearn.ensemble import GradientBoostingClassifier
t0 = time.time()
gbdt_model = GradientBoostingClassifier().fit(X_train, y_train)
t1 = time.time()
print('GradientBoostingClassifier',t1-t0)
gbdt_score = gbdt_model.score(X_test, y_test)
scores['GradientBoostingClassifier'] = gbdt_score
print(gbdt_score)
time_models['GradientBoostingClassifier'] = t1-t0
y_pred = gbdt_model.predict(X_test)
f1['GradientBoostingClassifier'] = f1_score(y_test,y_pred)
print(f1_score(y_test,y_pred))
# 查看模型评估指标汇总的结果
result_df = pd.DataFrame({'Models': scores.keys(), 'Scores':scores.values(),
'Time':time_models.values(), 'F1':f1.values()})
result_df.sort_values('Scores', ascending = False)
from sklearn.metrics import confusion_matrix,classification_report,auc,roc_curve
# 模型评估
y_pred = forest_model.predict(X_test)
print('confusion_matrix:','\n',confusion_matrix(y_test,y_pred))
print('classification_report:','\n',classification_report(y_test,y_pred))
#打印特征重要性评分
feat_labels = X_train.columns[0:]
importances = forest_model.feature_importances_
indices = np.argsort(importances)[::-1]
index_list = []
value_list = []
for f,j in zip(range(X_train.shape[1]),indices):
index_list.append(feat_labels[j])
value_list.append(importances[j])
print(f + 1, feat_labels[j], importances[j])
plt.figure(figsize=(12,8))
plt.barh(index_list[::-1],value_list[::-1])
plt.yticks(fontsize=12)
plt.title('Feature Importance Sorted',fontsize=14)
plt.show()
# 模型预测
res = pd.DataFrame()
res['真实值'] = y_test
res['预测值'] = y_pred
res.sample(10) # 随机抽取10个