目录
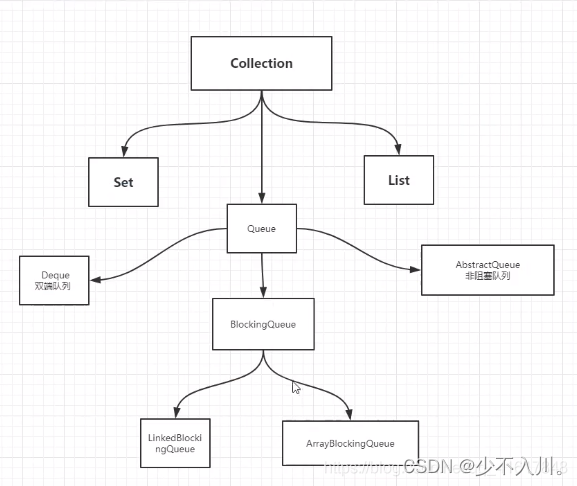
数据结构
什么是数据结构
链表
数组
栈
队列
哈希表
堆
数据结构
什么是数据结构
「数据结构」决定了数据的顺序和位置关系.数据存储于内存时,决定了数据顺序和位置关系的便是「数据结构」
链表
「链表」中的数据呈线性排列。链表中添加删除数据比较方便,访问数据只能从第一个数据开始,顺着指针指向一一往下访问「顺序访问」。
「双向链表」把数据的指针设定为两个,让它们分别指向前后数据。缺点:指针数的增加会导致存储空间需求增加;二是添加和删除数据时需要改变更多指针的指向。
「循环链表」在链表尾部使用指针,并且让它指向链表头部的数据,将链表变成环形。这就是"循环链表",也称为"环形链表"。使用这种链表,不仅可以从前往后,还可以从后往前遍历数据,十分方便。
「内存分布」数据一般都是分散存储于内存中的,无须存储在连续的空间内。
「添加&删除元素」改变添加位置前后的指针指向就可以。删除元素改变删除元素前一个元素的指针指向即可。删除的元素本身还存在于内存中,但是无法访问到这个数据,所以没有删除它的必要。下次需要用到删除元素所在的存储空间时,只需要用新数据覆盖掉就可以了。
「运行时间」把链表中的数据量记成 n。访问数据时,我们需要从链表头部开始查找(线性查找),如果目标数据在链表最后位置的话,需要的时间是O(n)。
添加数据只需要改变两个指针的指向,所以耗费的时间与 n 无关。如果已经达到了添加数据的位置,那么添加操作只需花费*O(1)*的时间,删除数据亦是如此。
数组
「数组」中的数据呈线性排列,访问数据十分简单,添加删除数据比较麻烦。
「内存分布」数据是存储在连续空间内的,所以每个数据的内存地址可以通过数组下标算出,我们也就可以借此直接访问目标数据,称为「随机访问」。
「添加&删除元素」首先需要在数组的末尾确保需要增加的存储空间,为了给新数据腾出位置,需要把已有的数据一个一个移开。最后在空出来的位置上写入 Green,添加数据的操作就完成了。反过来,如果要删除数据,需要把删除的元素后面的数据一个个往空位移,最后再删除多余的空间。
「运行时间」假设数组中有 n 个数据,由于访问数据时使用的是随机访问(通过下标可以计算出内存地址),所以需要的运行时间仅为恒定的O(1)
栈
「栈」中的数据呈线性排列,在这种数据结构中,我们只能访问最新添加的数据。
「内存分布」数据是存储在连续空间内的,具有后进先出的特点。
「添加&删除元素」往栈中添加数据的操作叫作"入栈"(push),从栈中取出数据的操作叫作"出栈"(pop)。操作只能在一端进行,访问数据只能访问到顶端的数据,访问中间的数据的话,需要通过出栈操作将目标数据移到栈顶。
队列
「队列」中的数据呈线性排列。在队列中,添加和删除数据的操作分别是在两端进行的。队列具有"先进先出的特点"。
「添加&删除元素」往队列中添加数据的操作叫作"入队"。从队列中删除数据的操作叫做"出队"。从队列中取出(删除)数据时,是从最下面也就是最早入队的数据开始的。队列不能直接访问位于中间的数据,必须通过出队操作将目标数据变成首位后才能访问。
哈希表
「哈希表」可以使数据的查询效率得到显著提升。哈希表存储的是由键(Key)和值(value)组成的数据。一般来说,可以把键当成数据的标识符,把值当成数据的内容。
存储数据,尝试把 Joe 存进长度为 5 的数组,使用哈希函数(Hash)计算 Joe 的键,也就是字符串"Joe"的哈希值,得到结果为 4928。将得到的哈希值除以数组的长度 5,求得其余数。这样的运算叫做mod 运算,此处的 mod 运算结果为 3。因此,将 Joe 的数据存进数组的 3 号箱子中。如果 mod 运算后,仍有数据需要存放在 3 号箱子中(哈希冲突),可使用链表在已有数据的后面继续存储新的数据。这种方法称为"链地址法"
「解决哈希冲突的方法」
如果数组空间太小,使用哈希表的时候就很容易发生冲突,线性查找的使用频率也会更高。如果数组空间太大,就会出现很多空箱子,造成内存的浪费。因此,给数组设定合适的空间很重要。
开放地址法:当有冲突发生时,立即算出一个候补地址(数组上的位置)并将数据存进去。如果仍有冲突。继续计算下一个候补地址知道有空地址为止。
堆
「堆」是一种图的树形结构,被用于实现"优先队列"。优先队列是一种数据结构,可以自由添加数据,但取出数据时候要从最小值开始按顺序取出。在堆的树型结构中,各个顶点被称为"结点"(node),数据就存储在这些结点中。「存储数据」子结点必须大于父结点。最小值被存储在顶端的根结点中。往堆中添加数据时,一般会把新数据放在最下面一行靠左的位置。当最下面一行里没有多余的空间时,就再往下另起一行,把数据加在这一行的最左端。例如添加数字5。如果子结点的数小于父结点,则交换位置。
「取出数据」取出堆中最上面的数据,因此堆的结构需要调整。将最后的数据6移动到最顶端。如果子结点的数字小于父结点的,就将父结点与其左右两个子节点中较小的一个进行交换。此时父节点6大于右边的5且大于子节点中的3,所以将左边的子节点中的3与父结点进行交换。重复这个操作直到数据都符合规则。这样,从堆中取出数据的操作便完成了。
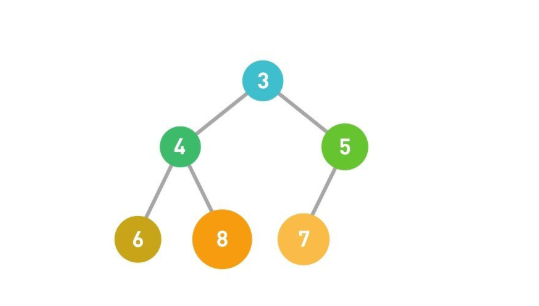
「时间复杂度」取出最顶端的数据始终最小,时间复杂度为O(1)。取出数据后需要将最后的数据移到最顶端,然后一边比较它与子结点数据的大小,一边往下移动,所以取出数据需要的运行时间和树的高度成正比。假设数据量为n,根据堆的形状特点可知树的高度为log2n,那么重构树的时间复杂度便为O(logn)