学习说明:最近发现了一个宝藏仓库,将常见的文本分类方法做了一个介绍、及封装。现在将学习这仓库的一些笔记记录如下
参照资料
649453932/Chinese-Text-Classification-Pytorch: 中文文本分类,TextCNN,TextRNN,FastText,TextRCNN,BiLSTM_Attention,DPCNN,Transformer,基于pytorch,开箱即用。 (github.com)
中文文本分类 pytorch实现 - 知乎 (zhihu.com)
文章目录
- 参照资料
- TextRNN
- TextRNN + Attention
- TextCNN
- TextRCNN
- DPCNN
- FastText
- Transformers
TextRNN
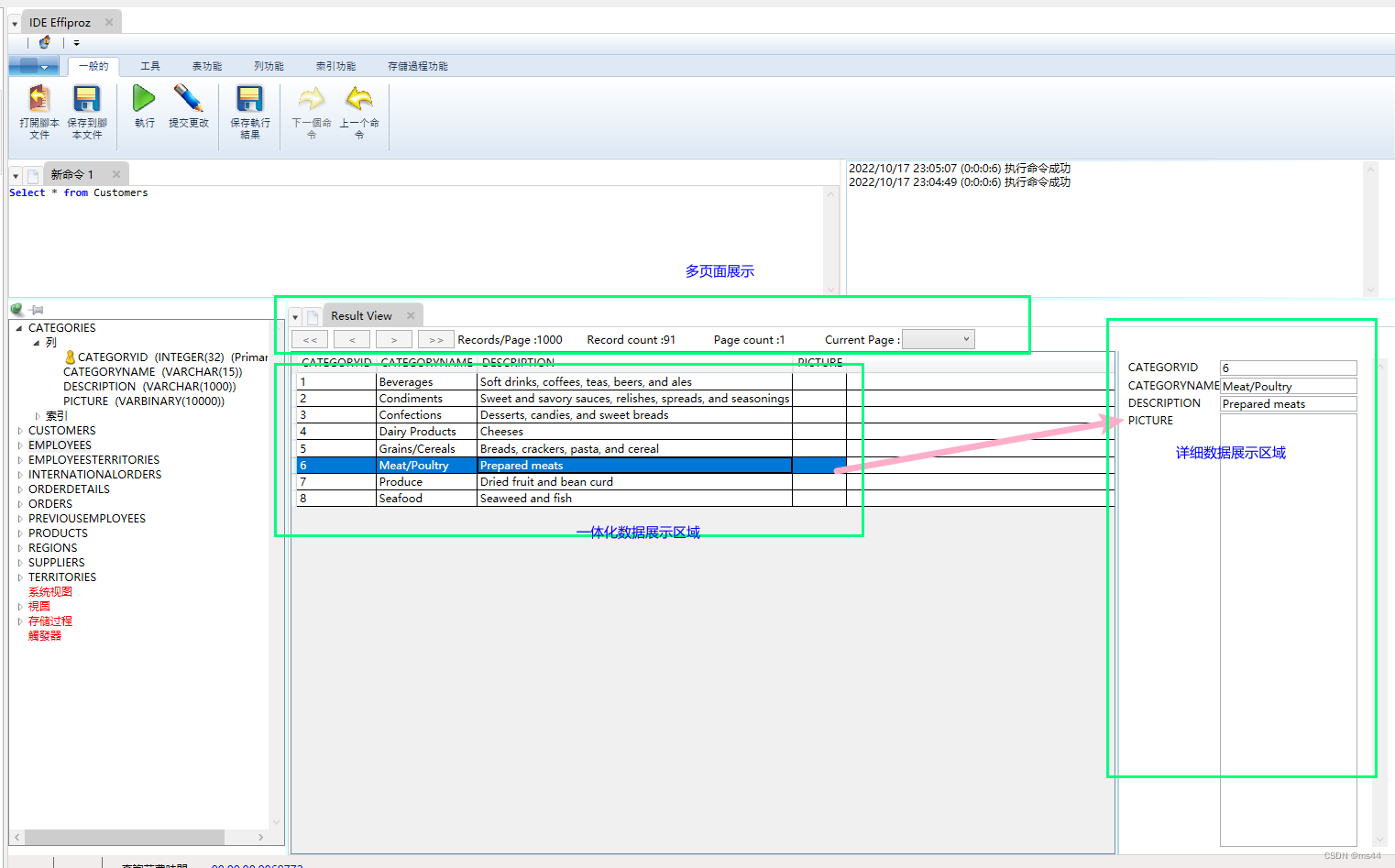
- 模型输入:[batch_size,seq_len]
- 经过embedding层:加载预训练的词向量或随机初始化,词向量维度为embed_size。[batch_size,seq_len,embed_size]
- 双向LSTM:隐层大小为hidden_size,得到所有时刻的隐层状态(前向隐层+后向隐层拼接)。[batch_size,seq_len,hidden_size * 2]
- 拿出最后时刻的隐层值:[batch_size,hidden_size * 2]
- 全连接:num_class是预测的类别数。[batch_size,num_class]
- 预测:sotfmax归一化,将num_class个数中概率最大的数对应的类作为最终预测。[batch_size,1]
分析:LSTM能比较好的捕捉长距离语义关系,但由于其递归结构,不能并行计算,速度慢
代码如下:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.fc = nn.Linear(config.hidden_size * 2, config.num_classes)
def forward(self, x): # x:{[batch_size,seq_len],batch_size}
x, _ = x # x:[batch_size,seq_len]
out = self.embedding(x) # out:[batch_size, seq_len, embeding]
out, _ = self.lstm(out) # out:[batch_size,seq_len,hidden_size * 2]
out = self.fc(out[:, -1, :]) # out:[batch_size,class_nums]
return out
TextRNN + Attention
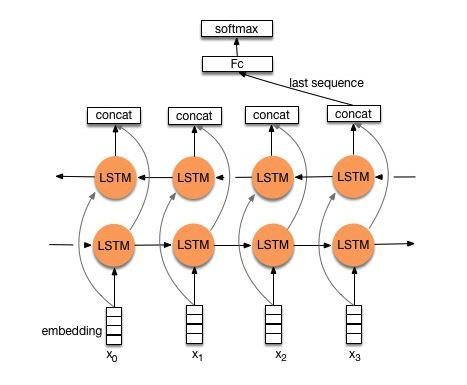
- 模型输入:[batch_size,seq_len]
- 经过embedding层:加载预训练词向量或随机初始化,词向量维度为embed_size。[batch_size,seq_len,embed_size]
- 双向LSTM:隐层大小为hidden_size,得到所有时刻的隐层状态(前向隐层+后向隐层拼接)。[batch_size,seq_len,hidden_size * 2]
- 初始化一个可学习的权重矩阵w。w = [hidden_size * 2,1]
- 对LSTM的输出进行非线性激活后与w进行矩阵相乘,并经softmax归一化,得到每时刻的分值。[batch_size,seq_len,1]
- 将LSTM的每一时刻的隐层状态乘对应的分值求和,得到加权平均后的终极隐层值。[batch_size,hidden_size * 2]
- 对终极隐层值进行非线性激活后送入两个连续的全连接层。[batch_size,num_class]
- 预测:sotfmax归一化,将num_class个数中概率最大的数对应的类作为最终预测。[batch_size,1]
分析:其中4~6步是attention机制计算过程,其实就是对lstm每刻的隐层进行加权平均。比如句长为4,首先算出4个时刻的归一化分值:[0.1, 0.3, 0.4, 0.2],然后
h
终极
=
0.1
h
1
+
0.3
h
2
+
0.4
h
3
+
0.2
h
4
h_{终极}=0.1h_1 + 0.3h_2 + 0.4h_3 + 0.2 h_4
h终极=0.1h1+0.3h2+0.4h3+0.2h4
代码如下
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.tanh1 = nn.Tanh()
# self.u = nn.Parameter(torch.Tensor(config.hidden_size * 2, config.hidden_size * 2))
self.w = nn.Parameter(torch.zeros(config.hidden_size * 2))
self.tanh2 = nn.Tanh()
self.fc1 = nn.Linear(config.hidden_size * 2, config.hidden_size2)
self.fc = nn.Linear(config.hidden_size2, config.num_classes)
def forward(self, x): # x:{[batch_size,seq_len],[batch_size]}
x, _ = x # x:[batch_size,seq_len]
emb = self.embedding(x) # emb:[batch_size,seq_len,embedding]
H, _ = self.lstm(emb) # H:[batch_size,seq_len,hidden_size * 2]
M = self.tanh1(H) # M:[batch_size,seq_len,hidden_size * 2]
# M = torch.tanh(torch.matmul(H, self.u))
alpha = F.softmax(torch.matmul(M, self.w), dim=1).unsqueeze(-1) # alpha:[batch_size,seq_len,1]
out = H * alpha # out:[batch_size,seq_len,hidden_size * 2]
out = torch.sum(out, 1) # out:[batch_size,hidden_size * 2]
out = F.relu(out) # out:[batch_size,hidden_size * 2]
out = self.fc1(out) # out:[batch_size,hidden_size2]
out = self.fc(out) # out:[batch_size,num_classes]
return out
TextCNN
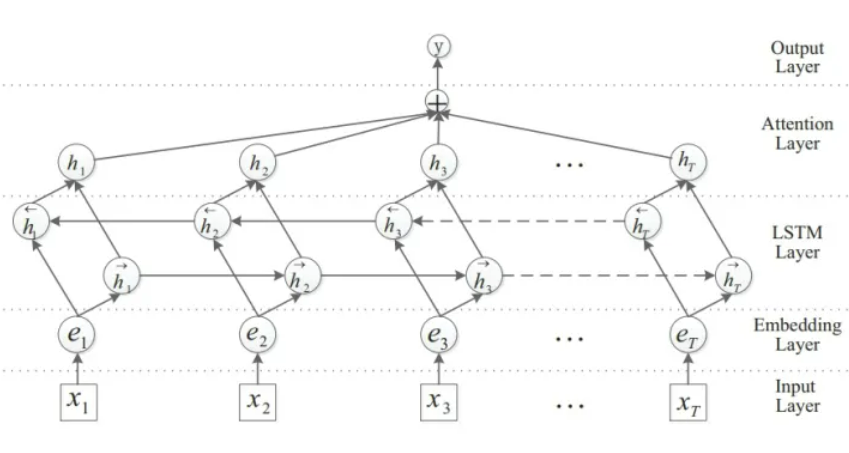
- 模型输入:[batch_size,seq_len]
- 经过embedding层:加载预训练词向量或随机初始化,词向量维度为embed_size。[batch_size,seq_len,embed_size]
- 卷积层:NLP中卷积核宽度与embed-size相同,相当于一维卷积。3个尺寸的filter_sizes卷积核(2,3,4),每个尺寸的卷积核num_filters有256个,卷积后得到三个特征图[batch_size,num_filters,seq_len - filter_sizes + 1]
- [batch_size,num_filters,seq_len-1]
- [batch_size,num_filters,seq_len-2]
- [batch_size,num_filters,seq_len-3]
- 池化层:对三个特征图做最大池化
- [batch_size,num_filters]
- [batch_size,num_filters]
- [batch_size,num_filters]
- 拼接:[batch_size,num_filters * 3]
- 全连接:num_class是预测的类别数。[batch_size,num_class]
- 预测:sotfmax归一化,将num_class个数中概率最大的数对应的类作为最终预测。[batch_size,1]
分析:卷积操作相当于提取了句中的2-gram,3-gram,4-gram信息,多个卷积是为了提取多种特征,最大池化将提取到最重要的信息保留
代码如下:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.convs = nn.ModuleList(
[nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv): # x:[batch_size,1,seq_len,embedding],conv:Conv2d(1,num_filters,kernerl_size=(filter_sizes,embedding),stride=(1,1))
x = F.relu(conv(x)).squeeze(3) # x:[batch_size,num_filters,seq_len - filter_sizes + 1]
x = F.max_pool1d(x, x.size(2)).squeeze(2) # x:[batch_size,num_filters]
return x
def forward(self, x): # x:{[batch_size,seq_len],[batch_size,]}
x, _ = x # x:[batch_size,seq_len]
out = self.embedding(x) # out:[batch_size, seq_len, embedding]
out = out.unsqueeze(1) # out:[bacth_size,1,seq_len,embedding]
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1) # out:[batch_size,num_filters * len(filter_sizes)]
out = self.dropout(out) # out:[batch_size,num_filters * len(filter_sizes)]
out = self.fc(out) # out:[batch_size,num_classes]
return out
TextRCNN
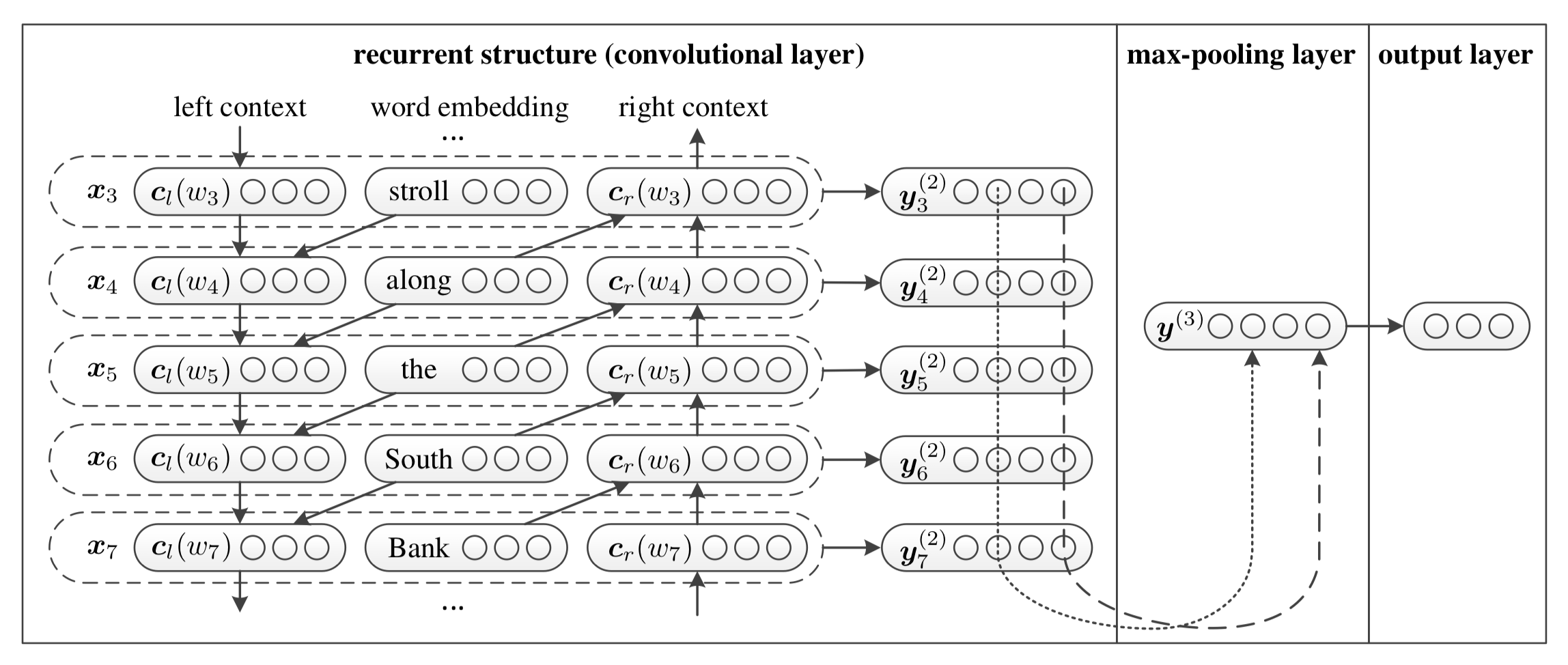
- 模型输入:[batch_size,seq_len]
- 经过embedding层:加载预训练的词向量或随机初始化,词向量维度为embed_size。[batch_size,seq_len,embed_size]
- 双向LSTM:隐层大小为hidden_size,得到所有时刻的隐层状态(前向隐层+后向隐层拼接)。[batch_size,seq_len,hidden_size * 2]
- 将embedding层与LSTM输出拼接,进行非线性激活。[batch_size, seq_len, hidden_size * 2 + embed_size]
- 池化层:seq_len个特征中取最大的。[batch_size, hidden_size * 2 + embed_size]
- 全连接:num_class是预测的类别数。[batch_size,num_class]
- 预测:sotfmax归一化,将num_class个数中概率最大的数对应的类作为最终预测。[batch_size,1]
分析:
双向LSTM每一时刻的隐层值(前向+后向)都可以表示当前词的前向和后向语义信息,将隐藏值与embedding值拼接来表示一个词;然后用最大池化层来筛选出有用的特征信息。就做了一个池化,所以被称之为RCNN
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed, config.num_classes)
def forward(self, x): # x:{[batch_size,seq_len],batch_size}
x, _ = x # x:[batch_size,seq_len]
emb = self.embedding(x) # emb:[batch_size, seq_len, embedding]
out, _ = self.lstm(emb) # out:[batch_size,seq_len,hidden_size * 2]
out = torch.cat((emb, out), 2) # out:[batch_size,seq_len,hidden_size * 2 + embedding]
out = F.relu(out) # out:[batch_size,seq_len,hidden_size * 2 + embedding]
out = out.permute(0, 2, 1) # out:[batch_size,hidden_size * 2 + embedding,seq_len]
out = self.maxpool(out).squeeze() # out:[batch_size,hidden_size * 2 + embedding]
out = self.fc(out) # out:[batch_size,num_classes]
return out
DPCNN

- 模型输入:[batch_size,seq_len]
- 经过embedding层:加载预训练的词向量或随机初始化,词向量维度为embed_size。[batch_size,seq_len,embed_size]
- 进行卷积:尺寸为3的卷积核num_filters为250,论文中称这层为region embedding。[batch_size, num_filters, seq_len - 3 + 1]
- 接两层卷积(+relu),每层都是num_filters为250,尺寸为3的卷积核(等长卷积,先padding再卷积,保证卷积前后序列的长度不变)。[batch_size,num_filters,seq-len-3+1]
- 接下来进行上图中小框的操作
- 进行大小为3,步长为2的最大池化,将序列长度压缩为原来的1/2(进行采样)
- 接两层等长卷积(+relu),每层都是num_filters为250,尺寸为3的卷积核
- 上述两结果相加,残差连接
- 重复以上步骤,直至序列长度等于1。[batch_size,num_filters,1,1]
- 全连接:num_class是预测的类别数。[batch_size,num_class]
- 预测:sotfmax归一化,将num_class个数中概率最大的数对应的类作为最终预测。[batch_size,1]
分析:TextCNN的过程类似于提取N-Gram信息,而且只有一层,难以捕捉长距离特征。反观DPCNN,可以看出它的region embedding就是一个去掉池化层的TextCNN,再将卷积层叠加
每层序列长度都减半,可以这么理解:相当于再N-Gram上在再做N-Gram。越往后的层,每个位置融合的信息越多,最后一层提取的就是整个序列的语义信息
代码如下:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.conv_region = nn.Conv2d(1, config.num_filters, (3, config.embed), stride=1)
self.conv = nn.Conv2d(config.num_filters, config.num_filters, (3, 1), stride=1)
self.max_pool = nn.MaxPool2d(kernel_size=(3, 1), stride=2)
self.padding1 = nn.ZeroPad2d((0, 0, 1, 1)) # top bottom
self.padding2 = nn.ZeroPad2d((0, 0, 0, 1)) # bottom
self.relu = nn.ReLU()
self.fc = nn.Linear(config.num_filters, config.num_classes)
def forward(self, x): # x:{[batch_size,seq_len],[batch_size,]}
x, _ = x # x:[batch_size,seq_len]
x = self.embedding(x) # x:[batch_size,seq_len,embedding]
x = x.unsqueeze(1) # x:[batch_size,1,seq_len,embedding]
x = self.conv_region(x) # x:[batch_size, num_filters, seq_len-3+1, 1]
x = self.padding1(x) # x:[batch_size, num_filters, seq_len, 1]
x = self.relu(x) # x:[batch_size, num_filters, seq_len, 1]
x = self.conv(x) # x:[batch_size, num_filters, seq_len-3+1, 1]
x = self.padding1(x) # x:[batch_size, num_filters, seq_len, 1]
x = self.relu(x) # x:[batch_size, num_filters, seq_len, 1]
x = self.conv(x) # x:[batch_size, num_filters, seq_len-3+1, 1]
while x.size()[2] > 2:
x = self._block(x) # x:[batch_size,num_filters,1,1]
x = x.squeeze() # x:[batch_size,num_filters]
x = self.fc(x) # x:[batch_size,num_class]
return x
def _block(self, x): # x:[batch_size, num_filters, seq_len-3+1, 1]
x = self.padding2(x)
px = self.max_pool(x)
x = self.padding1(px)
x = F.relu(x)
x = self.conv(x)
x = self.padding1(x)
x = F.relu(x)
x = self.conv(x)
# Short Cut
x = x + px
return x
FastText
- 用哈希算法将2-gram、3-gram信息分别映射到两张表内
- 模型输入:[batch_size,seq_len]
- 经过embedding层:加载预训练的词向量或随机初始化,词向量维度为embed_size。[batch_size,seq_len,embed_size],同理:
- 2-gram:[batch_size, seq_len, embed_size]
- 3-gram:[batch_size, seq_len, embed_size]
- 拼接embedding层:batch_size, seq_len, embed_size * 3]
- 求所有seq_len个词的均值:[batch_size, embed_size * 3]
- 全连接+非线性激活:隐层大小hidden_size。[batch_size,hidden_size]
- 全连接:num_class是预测的类别数。[batch_size,num_class]
- 预测:sotfmax归一化,将num_class个数中概率最大的数对应的类作为最终预测。[batch_size,1]
分析:不加N-Gram信息,就是词袋模型。对于N-Gram,我们设定一个词表,这个词表大小自己设定大小,理论上越大效果越好,但N-Gram词表大小太大,机器会承受不了,不同的N-Gram用哈希算法可能会映射到词表同一位置,这是一个弊端,但影响不是很大。对于N-Gram词表大小对效果的影响,可以描述为:一分价钱1分货,十分价钱1.1分货
代码如下:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.embedding_ngram2 = nn.Embedding(config.n_gram_vocab, config.embed)
self.embedding_ngram3 = nn.Embedding(config.n_gram_vocab, config.embed)
self.dropout = nn.Dropout(config.dropout)
self.fc1 = nn.Linear(config.embed * 3, config.hidden_size)
# self.dropout2 = nn.Dropout(config.dropout)
self.fc2 = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x): # x:{[batch_size,seq_len],[batch_size,],[batch_size,seq_len],[batch_size,seq_len]}
out_word = self.embedding(x[0]) # out_word:[batch_size,seq_len,embedding]
out_bigram = self.embedding_ngram2(x[2]) # out_bigram:[batch_size,seq_len,embedding]
out_trigram = self.embedding_ngram3(x[3]) # out_trigram:[batch_size,seq_len,embedding]
out = torch.cat((out_word, out_bigram, out_trigram), -1) # out:[batch_size,seq_len,embedding * 3]
out = out.mean(dim=1) # out:[batch_size,embedding * 3]
out = self.dropout(out)
out = self.fc1(out) # out:[batch_size,hidden_size]
out = F.relu(out)
out = self.fc2(out) # out:[batch_size,num_class]
return out
Transformers
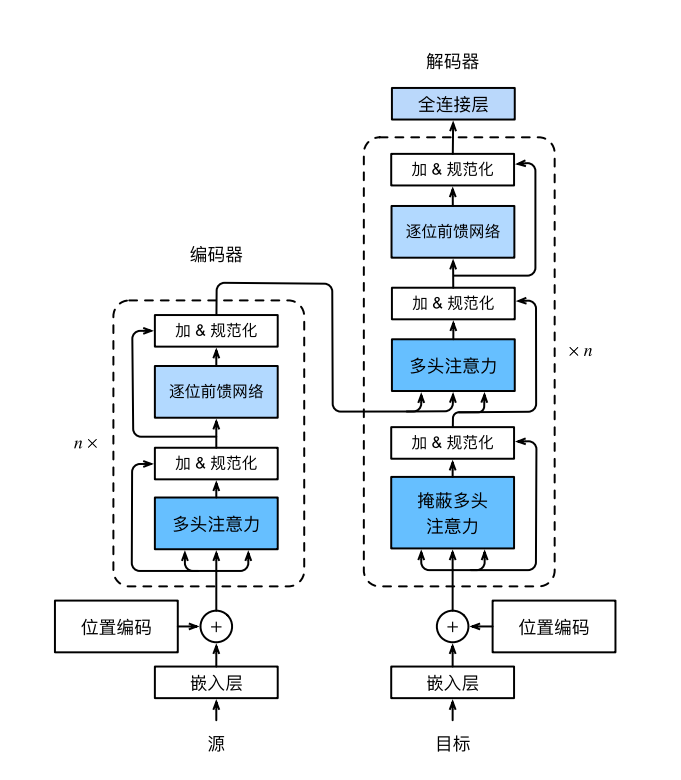
详细说明:(203条消息) Transformer原理以及文本分类实战_五月的echo的博客-CSDN博客_transformer文本分类
代码如下:
class ConfigTrans(object):
"""配置参数"""
def __init__(self):
self.model_name = 'Transformer'
self.dropout = 0.5
self.num_classes = cfg.classes # 类别数
self.num_epochs = 100 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = cfg.nV # 每句话处理成的长度(短填长切),这个根据自己的数据集而定
self.learning_rate = 0.001 # 学习率
self.embed = 50 # 字向量维度
self.dim_model = 50 # 需要与embed一样
self.hidden = 1024
self.last_hidden = 512
self.num_head = 5 # 多头注意力,注意需要整除
self.num_encoder = 2 # 使用两个Encoder,尝试6个encoder发现存在过拟合,毕竟数据集量比较少(10000左右),可能性能还是比不过LSTM
config = ConfigTrans()
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.postion_embedding = Positional_Encoding(config.embed, config.pad_size, config.dropout, config.device)
self.encoder = Encoder(config.dim_model, config.num_head, config.hidden, config.dropout)
self.encoders = nn.ModuleList([
copy.deepcopy(self.encoder)
# Encoder(config.dim_model, config.num_head, config.hidden, config.dropout)
for _ in range(config.num_encoder)])
self.fc1 = nn.Linear(config.pad_size * config.dim_model, config.num_classes)
# self.fc2 = nn.Linear(config.last_hidden, config.num_classes)
# self.fc1 = nn.Linear(config.dim_model, config.num_classes)
def forward(self, x): # x:{[batch_size,seq_len],[batch_size,]}
out = self.embedding(x[0]) # out:[batch_size,seq_len,embedding]
out = self.postion_embedding(out) # out:{batch_size,seq_len,embedding}
for encoder in self.encoders:
out = encoder(out) # out:[batch_size,seq_len,dim_model]
out = out.view(out.size(0), -1) # out:[batch_size,seq_len * dim_model]
# out = torch.mean(out, 1)
out = self.fc1(out) # out:[batch_size,num_class]
return out
class Encoder(nn.Module):
def __init__(self, dim_model, num_head, hidden, dropout):
super(Encoder, self).__init__()
self.attention = Multi_Head_Attention(dim_model, num_head, dropout)
self.feed_forward = Position_wise_Feed_Forward(dim_model, hidden, dropout)
def forward(self, x): # x:[batch_size,seq_len,dim_model]
out = self.attention(x) # out:[batch_size,seq_len,dim_model]
out = self.feed_forward(out) # out:[batch_size,seq_len,dim_model]
return out
class Positional_Encoding(nn.Module):
def __init__(self, embed, pad_size, dropout, device):
super(Positional_Encoding, self).__init__()
self.device = device
self.pe = torch.tensor([[pos / (10000.0 ** (i // 2 * 2.0 / embed)) for i in range(embed)] for pos in range(pad_size)])
self.pe[:, 0::2] = np.sin(self.pe[:, 0::2])
self.pe[:, 1::2] = np.cos(self.pe[:, 1::2])
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = x + nn.Parameter(self.pe, requires_grad=False).to(self.device)
out = self.dropout(out)
return out
class Scaled_Dot_Product_Attention(nn.Module):
'''Scaled Dot-Product Attention '''
def __init__(self):
super(Scaled_Dot_Product_Attention, self).__init__()
def forward(self, Q, K, V, scale=None):
'''
Args:
Q: [batch_size, len_Q, dim_Q]
K: [batch_size, len_K, dim_K]
V: [batch_size, len_V, dim_V]
scale: 缩放因子 论文为根号dim_K
Return:
self-attention后的张量,以及attention张量
'''
attention = torch.matmul(Q, K.permute(0, 2, 1)) # Q*K^T,attention:[batch_size * num_head,seq_len,seq_len]
if scale:
attention = attention * scale
# if mask: # TODO change this
# attention = attention.masked_fill_(mask == 0, -1e9)
attention = F.softmax(attention, dim=-1) # attention:[batch_size * num_head,seq_len,seq_len]
context = torch.matmul(attention, V) # context:[batch_size * num_head,seq_len,dim_head]
return context
class Multi_Head_Attention(nn.Module):
def __init__(self, dim_model, num_head, dropout=0.0):
super(Multi_Head_Attention, self).__init__()
self.num_head = num_head
assert dim_model % num_head == 0 # head数必须能够整除隐层大小
self.dim_head = dim_model // self.num_head # 按照head数量进行张量均分
self.fc_Q = nn.Linear(dim_model, num_head * self.dim_head) # Q,通过Linear实现张量之间的乘法,等同手动定义参数W与之相乘
self.fc_K = nn.Linear(dim_model, num_head * self.dim_head)
self.fc_V = nn.Linear(dim_model, num_head * self.dim_head)
self.attention = Scaled_Dot_Product_Attention()
self.fc = nn.Linear(num_head * self.dim_head, dim_model)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(dim_model)
def forward(self, x): # x:[batch_size,seq_len,embedding]
batch_size = x.size(0)
Q = self.fc_Q(x) # Q:[batch_size,seq_len,dim_model]
K = self.fc_K(x) # K:[batch_size,seq_len,dim_model]
V = self.fc_V(x) # V:[batch_size,seq_len,dim_model]
Q = Q.view(batch_size * self.num_head, -1, self.dim_head) # Q:[batch_size * num_head,seq_len,dim_head] 注意:dim_head = dim_model / num_head
K = K.view(batch_size * self.num_head, -1, self.dim_head) # K:[batch_size * num_head,seq_len,dim_head]
V = V.view(batch_size * self.num_head, -1, self.dim_head) # V:[batch_size * num_head,seq_len,dim_head]
# if mask: # TODO
# mask = mask.repeat(self.num_head, 1, 1) # TODO change this
scale = K.size(-1) ** -0.5 # sqrt(1/dim_head),根号dk分之一,对应Scaled操作,缩放因子
context = self.attention(Q, K, V, scale)# Scaled_Dot_Product_Attention计算,context:[batch_size * num_head,seq_len,dim_head]
context = context.view(batch_size, -1, self.dim_head * self.num_head) # context:[batch_size,seq_len,num_head * dim_head]
out = self.fc(context) # out:[batch_size,seq_len,dim_model]
out = self.dropout(out)
out = out + x # 残差连接
out = self.layer_norm(out)
return out
class Position_wise_Feed_Forward(nn.Module):
def __init__(self, dim_model, hidden, dropout=0.0):
super(Position_wise_Feed_Forward, self).__init__()
self.fc1 = nn.Linear(dim_model, hidden)
self.fc2 = nn.Linear(hidden, dim_model)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(dim_model)
def forward(self, x): # x:[batch_size,seq_len,dim_model]
out = self.fc1(x) # out:[batch_size,seq_len,hidden]
out = F.relu(out)
out = self.fc2(out) # out:[batch_size,seq_len,dim_model]
out = self.dropout(out)
out = out + x # 残差连接
out = self.layer_norm(out)
return out