文章目录
- 前言
- 一、内存模型
- 二、(N)UMA
- 2.1 简介
- 2.2 节点
- 2.3 UMA节点与Flat Memory Model
- 2.4 zone
- 2.4.1 zone
- 2.4.2 zone_type
- 参考资料
前言
一、内存模型
所谓memory model,其实就是从cpu的角度看,其物理内存的分布情况,在linux kernel中,使用什么的方式来管理这些物理内存。某些体系架构支持多种内存模型,但在内核编译构建时只能选择使用一种内存模型。
Linux内核目前支持三种内存模型(物理内存分布情况):Flat Memory Model,Discontiguous Memory Model和Sparse Memory Model。
我的x86_64架构下的Linux内核配置选项:
CONFIG_SPARSEMEM_MANUAL=y
CONFIG_SPARSEMEM=y
CONFIG_NEED_MULTIPLE_NODES=y
CONFIG_HAVE_MEMORY_PRESENT=y
CONFIG_SPARSEMEM_EXTREME=y
CONFIG_SPARSEMEM_VMEMMAP_ENABLE=y
CONFIG_SPARSEMEM_ALLOC_MEM_MAP_TOGETHER=y
CONFIG_SPARSEMEM_VMEMMAP=y
可以看到其内存模型是Sparse Memory Model,支持热插拔。
请参考:
http://www.wowotech.net/memory_management/memory_model.html
https://blog.csdn.net/u012489236/article/details/106323088
https://zhuanlan.zhihu.com/p/452891440
二、(N)UMA
2.1 简介
x86 的工作模式的时候,讲过 CPU 是通过总线去访问内存,
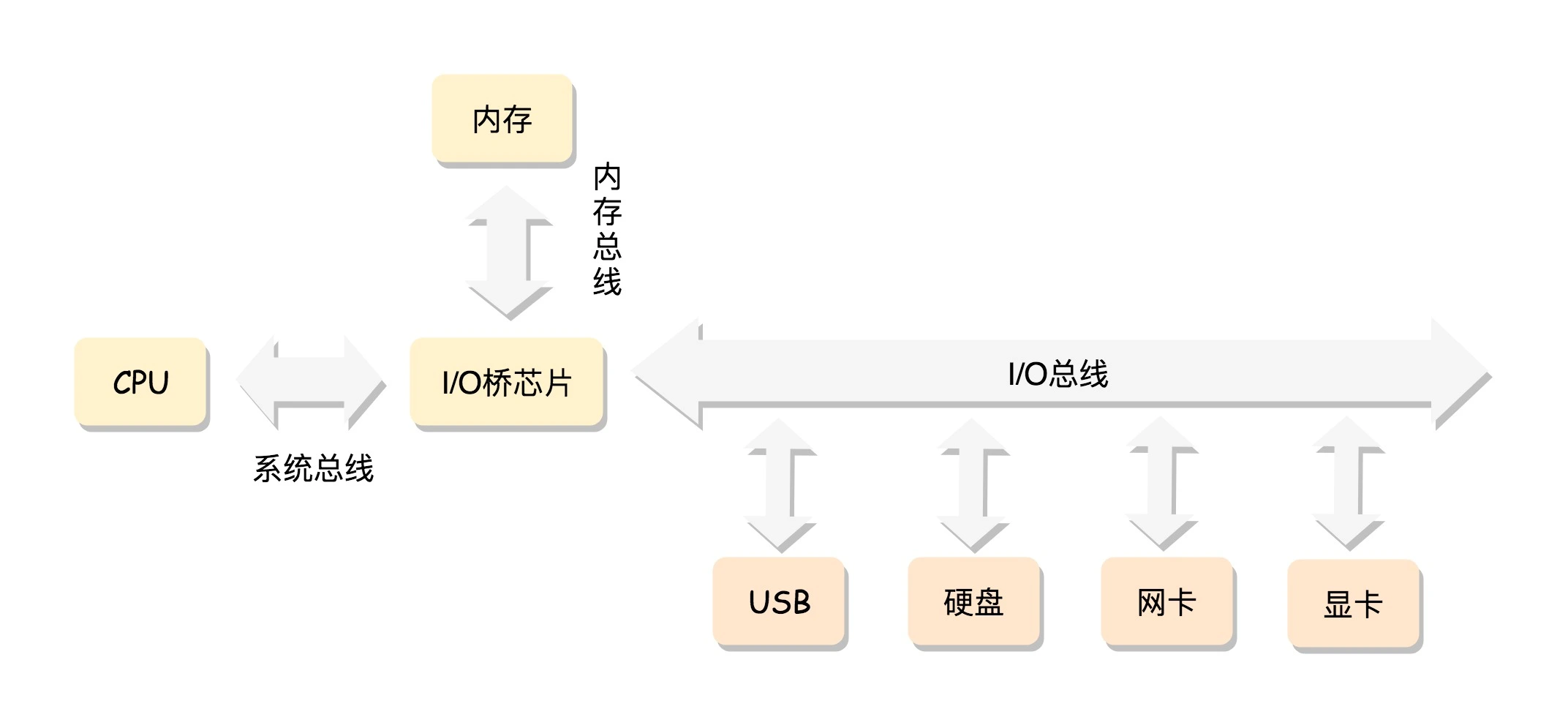
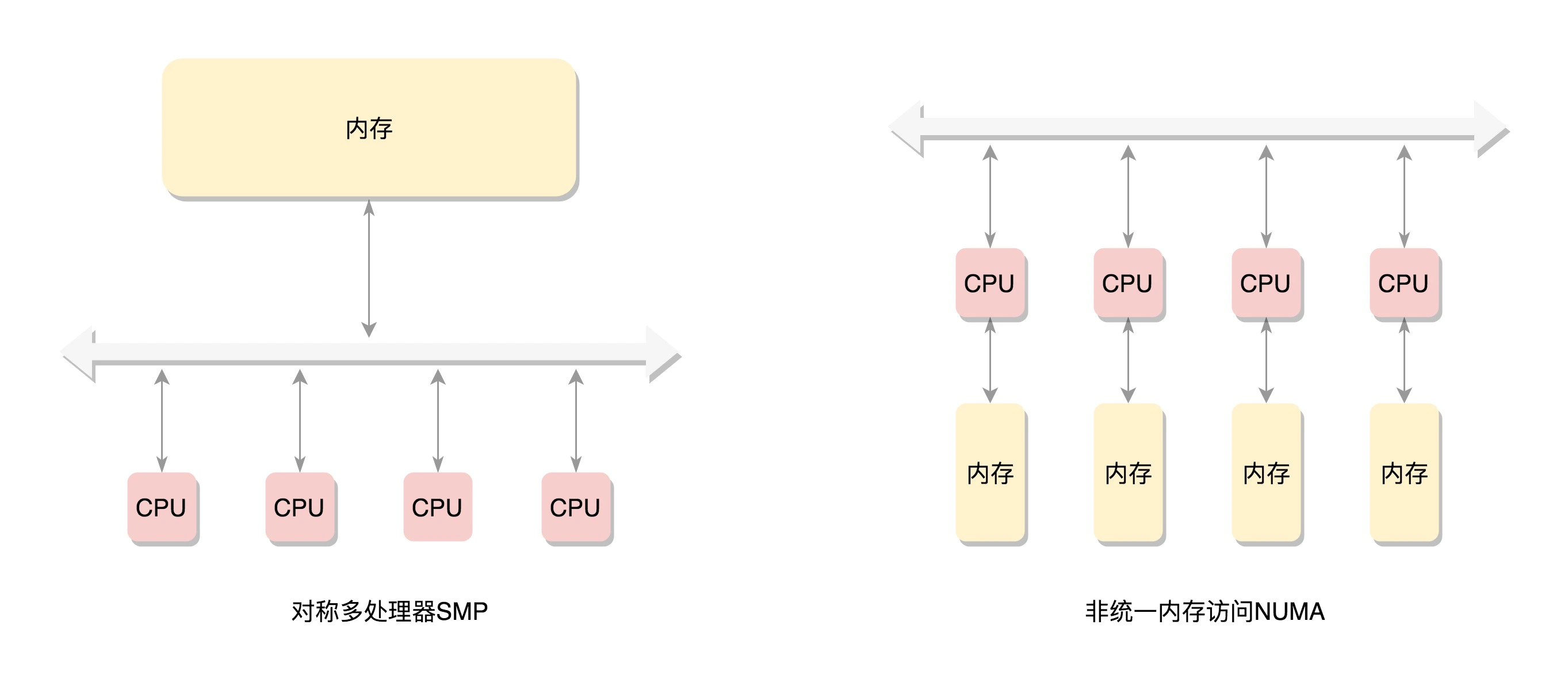
在这种模式下,CPU 也会有多个,在总线的一侧。所有的内存条组成一大片内存,在总线的另一侧,所有的 CPU 访问内存都要过总线,而且距离都是一样的,这种模式称为 SMP(Symmetric multiprocessing),即对称多处理器。当然,它也有一个显著的缺点,就是总线会成为瓶颈,因为数据都要走它。
为了提高性能和可扩展性,后来有了一种更高级的模式,NUMA(Non-uniform memory access),非一致内存访问。在这种模式下,内存不是一整块。每个 CPU 都有自己的本地内存,CPU 访问本地内存不用过总线,因而速度要快很多,每个 CPU 和内存在一起,称为一个 NUMA 节点。但是,在本地内存不足的情况下,每个 CPU 都可以去另外的 NUMA 节点申请内存,这个时候访问延时就会比较长。
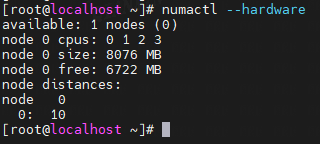
我的x86_64架构下的Linux内核配置选项:
CONFIG_NUMA=y
CONFIG_AMD_NUMA=y
CONFIG_X86_64_ACPI_NUMA=y
CONFIG_NODES_SPAN_OTHER_NODES=y
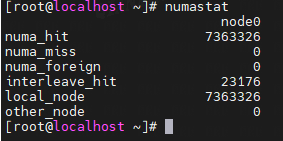
虽然配置了NUMA,但通常也只有一个节点:
2.2 节点
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
......
#if defined(CONFIG_MEMORY_HOTPLUG) || defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT)
/*
* Must be held any time you expect node_start_pfn, node_present_pages
* or node_spanned_pages stay constant. Holding this will also
* guarantee that any pfn_valid() stays that way.
*
* pgdat_resize_lock() and pgdat_resize_unlock() are provided to
* manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG
* or CONFIG_DEFERRED_STRUCT_PAGE_INIT.
*
* Nests above zone->lock and zone->span_seqlock
*/
spinlock_t node_size_lock;
#endif
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd; /* Protected by
mem_hotplug_begin/end() */
int kswapd_order;
enum zone_type kswapd_classzone_idx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
#ifdef CONFIG_COMPACTION
int kcompactd_max_order;
enum zone_type kcompactd_classzone_idx;
wait_queue_head_t kcompactd_wait;
struct task_struct *kcompactd;
#endif
#ifdef CONFIG_NUMA_BALANCING
/* Lock serializing the migrate rate limiting window */
spinlock_t numabalancing_migrate_lock;
/* Rate limiting time interval */
unsigned long numabalancing_migrate_next_window;
/* Number of pages migrated during the rate limiting time interval */
unsigned long numabalancing_migrate_nr_pages;
#endif
/*
* This is a per-node reserve of pages that are not available
* to userspace allocations.
*/
unsigned long totalreserve_pages;
#ifdef CONFIG_NUMA
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* If memory initialisation on large machines is deferred then this
* is the first PFN that needs to be initialised.
*/
unsigned long first_deferred_pfn;
/* Number of non-deferred pages */
unsigned long static_init_pgcnt;
#endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
spinlock_t split_queue_lock;
struct list_head split_queue;
unsigned long split_queue_len;
#endif
/* Fields commonly accessed by the page reclaim scanner */
struct lruvec lruvec;
unsigned long flags;
ZONE_PADDING(_pad2_)
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
} pg_data_t;
每个NUMA节点都有一个pg_data_t来描述它的内存布局(在UMA机器上有一个单独的pglist_data,它描述了整个内存)。
node_zones是一个数组,包含了该节点中各个内存zones的数据结构。
node_zonelists指定了备用节点及其内存zones的列表,以便在当前节点没有可用空间时,在备用节点分配内存。
node_start_pfn 是这个节点的起始页号;
node_spanned_pages 是这个节点中包含不连续的物理内存地址的页面数,可能节点中会有空洞。
node_present_pages 是真正可用的物理页面的数目。
node_id 每一个节点都有自己的 ID,是一个全局的节点ID,系统中NUMA节点中都从0开始编号。
// linux-4.18/arch/x86/include/asm/mmzone_64.h
#ifdef CONFIG_NUMA
#include <linux/mmdebug.h>
#include <asm/smp.h>
extern struct pglist_data *node_data[];
#define NODE_DATA(nid) (node_data[nid])
2.3 UMA节点与Flat Memory Model
该节内容可以跳过,目前x86_64都没有以下的配置。
(1)
虽然Linux在x86_64机器通常只有一个节点,但是配置了CONFIG_NUMA选项。
// linux-4.18/linux-4.18/mm/memory.c
#ifndef CONFIG_NEED_MULTIPLE_NODES
/* use the per-pgdat data instead for discontigmem - mbligh */
unsigned long max_mapnr;
EXPORT_SYMBOL(max_mapnr);
struct page *mem_map;
EXPORT_SYMBOL(mem_map);
#endif
mem_map是一个struct page类型的数组,用来存放系统中所有的struct page。
// linux-4.18/linux-4.18/include/linux/mmzone.h
#ifndef CONFIG_NEED_MULTIPLE_NODES
extern struct pglist_data contig_page_data;
#define NODE_DATA(nid) (&contig_page_data)
#define NODE_MEM_MAP(nid) mem_map
#else /* CONFIG_NEED_MULTIPLE_NODES */
在UMA结构的机器中, 只有一个node结点即contig_page_data,
(2)
typedef struct pglist_data {
......
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
struct page *node_mem_map;
......
}
node_mem_map 就是这个节点的 struct page 数组,用于描述这个节点里面的所有的页;
对于UMA系统中node_mem_map等于全局的mem_map。
Linux x86_64目前是Sparse Memory Model,因此没有配置CONFIG_FLAT_NODE_MEM_MAP,所以struct page *node_mem_map可以忽略。
2.4 zone
2.4.1 zone
每一个节点分成一个个区域 zone,放在数组 node_zones 里面。这个数组的大小为 MAX_NR_ZONES。
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
unsigned long nr_reserved_highatomic;
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
*/
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*
* Read access to managed_pages should be safe because it's unsigned
* long. Write access to zone->managed_pages and totalram_pages are
* protected by managed_page_count_lock at runtime. Idealy only
* adjust_managed_page_count() should be used instead of directly
* touching zone->managed_pages and totalram_pages.
*/
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
int initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where async and sync compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[2];
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* Set to true when the PG_migrate_skip bits should be cleared */
bool compact_blockskip_flush;
#endif
bool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;
watermark:每个zone在系统启动时会计算三个水位,分别是最低水位线,低水位线,高水位线。在页面分配器和kswapd页面回收中用到。
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
#define min_wmark_pages(z) (z->watermark[WMARK_MIN])
#define low_wmark_pages(z) (z->watermark[WMARK_LOW])
#define high_wmark_pages(z) (z->watermark[WMARK_HIGH])
lowmem_reserve:该数组为各个内存区制定了若干页,用于一些无论如何都不能失败的关键性内存分配。各个内存区域的份额根据重要性确定。
防止页面分配器过度使用低端zone的内存。我们不知道我们将要分配的内存是可释放的还是它最终会被释放,所以为了避免完全浪费几个GB的内存,我们必须保留一些较低区域的内存(否则我们就有在较低区域运行OOM的风险,尽管在较高区域有大量的可释放内存)。如果sysctl_lowmem_reserve_ratio sysctl发生变化,则在运行时重新计算该数组。
zone_pgdat:指向内存节点。
pageset:用于维护每个CPU上的一系列页面,以减少自旋锁的争用。用于区分冷热页。如果一个页被加载到 CPU 高速缓存里面,这就是一个热页(Hot Page),CPU 读起来速度会快很多,如果没有就是冷页(Cold Page)。由于每个 CPU 都有自己的高速缓存,因而 per_cpu_pageset 也是每个 CPU 一个。
struct per_cpu_pages {
int count; /* number of pages in the list */
int high; /* high watermark, emptying needed */
int batch; /* chunk size for buddy add/remove */
/* Lists of pages, one per migrate type stored on the pcp-lists */
struct list_head lists[MIGRATE_PCPTYPES];
};
struct per_cpu_pageset {
struct per_cpu_pages pcp;
......
};
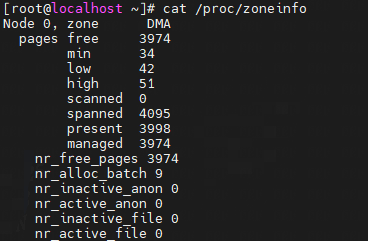
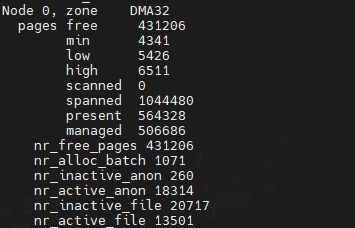
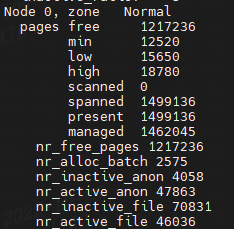
cat /proc/zoneinfo
Node 0, zone DMA
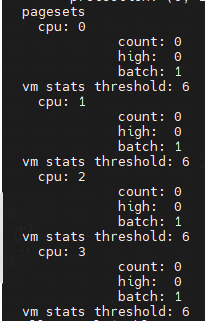
Node 0, zone Normal
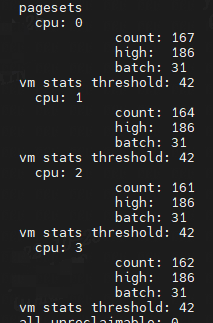
zone_start_pfn: 表示属于这个 zone 的起始页帧号。
spanned_pages = zone_end_pfn - zone_start_pfn,也即 spanned_pages 指的是不管中间有没有物理内存空洞,反正就是最后的页号减去起始的页号,即spanned_pages包含内存空洞区域页。
present_pages = spanned_pages - absent_pages(pages in holes),也即 present_pages 是这个 zone 在物理内存中真实存在的所有 page 数目。
managed_pages = present_pages - reserved_pages,也即 managed_pages 是这个 zone 被伙伴系统管理的所有的 page 数目。
memory hotplug or memory power management logic可以使用present_pages来通过检查(present_pages - managed_pages)找出unmanaged pages。
而页面分配器和vm扫描程序应该使用managed_pages来计算各种 watermarks and thresholds。
free_area:伙伴系统的核心数据结构,管理空闲页块链表的数组。
lock:主要是用来保护free_area数组的自旋锁。
2.4.2 zone_type
enum zone_type {
#ifdef CONFIG_ZONE_DMA
/*
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* Architecture Limit
* ---------------------------
* parisc, ia64, sparc <4G
* s390 <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/*
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
我的x86_64配置:
CONFIG_ZONE_DMA=y
CONFIG_ZONE_DMA32=y
CONFIG_ZONE_DEVICE=y
对于区域的划分,都是针对物理内存的:
ZONE_DMA 是指可用于作 DMA(Direct Memory Access,直接内存存取)的内存。DMA 是这样一种机制:要把外设的数据读入内存或把内存的数据传送到外设,原来都要通过 CPU 控制完成,但是这会占用 CPU,影响 CPU 处理其他事情,所以有了 DMA 模式。CPU 只需向 DMA 控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,这样就可以解放 CPU。对于 64 位系统,有两个 DMA 区域。除了上面说的 ZONE_DMA,还有 ZONE_DMA32
ZONE_NORMAL 是直接映射区,从物理内存到虚拟内存的内核区域,通过加上一个常量直接映射。
ZONE_HIGHMEM 是高端内存区,对于 32 位系统来说超过 896M 的地方,对于 64 位没有该内存区域。
ZONE_MOVABLE 是可移动区域,通过将物理内存划分为可移动分配区域和不可移动分配区域来避免内存碎片。
CONFIG_ZONE_DEVICE是为了支持热插拔设备而分配的非易失性内存区域。
可以通过/proc/zoneinfo文件查看区域信息:
参考资料
Linux 4.18
深入Linux内核架构
极客时间:趣谈操作系统
奔跑吧Linux内核
https://www.cnblogs.com/LoyenWang/p/11523678.html
http://www.wowotech.net/memory_management/memory_model.html
https://blog.csdn.net/gatieme/article/details/52384075


![[时间序列预测]基于BP、LSTM、CNN-LSTM神经网络算法的单特征用电负荷预测[保姆级手把手教学]](https://img-blog.csdnimg.cn/8a58536f277e4b40a793f0e63982e12f.png#pic_center)