一,安装 Cuda 驱动
可参考笔者之前写过的文章: 升级 GPU 服务器 cuda 驱动版本指南
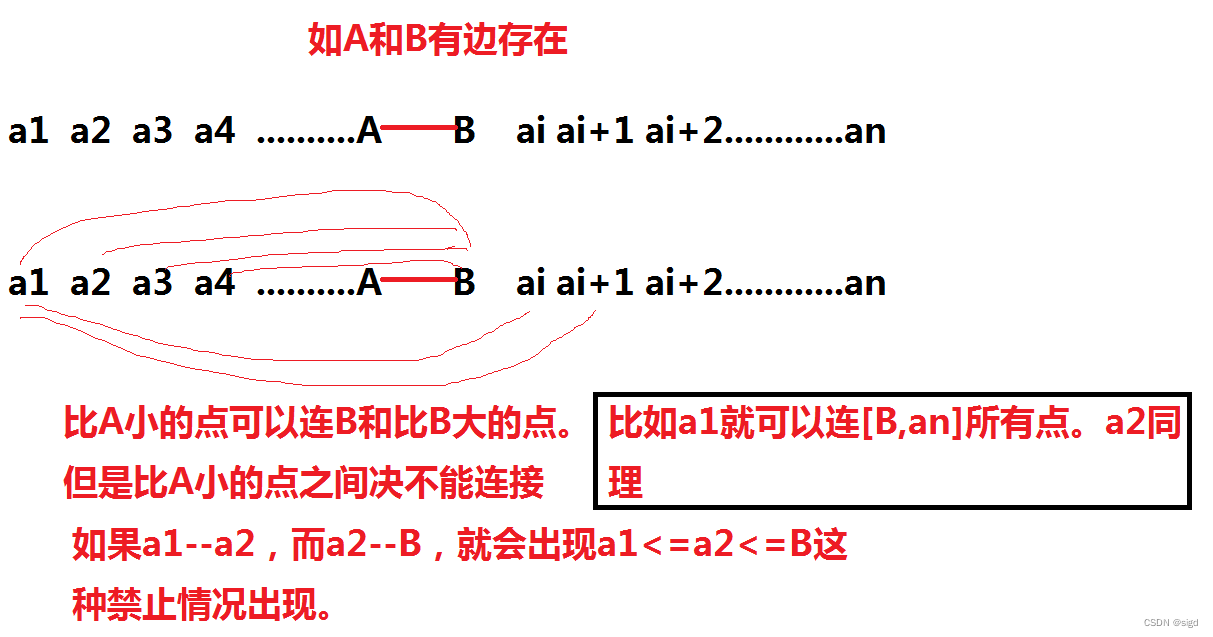
如果出现如下报错,则需安装 gcc、kernel-devel,请参考下面第二步安装 gcc、kernel-devel。

二,安装 gcc、kernel-devel
1, 安装 gcc 和 kernel-devel
若直接执行如下命令安装,如果默认版本不一致,则会遇到如下图报错:
yum -y install gcc kernel-devel
./NVIDIA-Linux-x86_64-515.86.01.run

2, 报错原因
使用如下命令查看内核版本是否一致
uname -r
rpm -q kernel-devel
正常结果应该是如下图所示,内核版一致,若不一致则通过下一步解决此问题。

3, 解决内核版本不一致问题
卸载 kernel-devel,执行如下命令:
yum remove kernel-devel
4, 安装版本匹配的 kernel-devel
1)查看内核版本号
uname -a
红框圈出来的则是内核版本号:

kernel-devel-3.10.0-1160.el7.x86_64.rpm
2)下载版本匹配的 kernel-devel
kernel-devel 下载地址: https://ftp.sjtu.edu.cn/sites/ftp.scientificlinux.org/linux/scientific/7.9/x86_64/os/Packages/
找到与内核版本号对应的 kernel-devel 版本: kernel-devel-3.10.0-1160.el7.x86_64.rpm
# 在终端 使用 wget 下载 kernel-devel
wget https://ftp.sjtu.edu.cn/sites/ftp.scientificlinux.org/linux/scientific/7.9/x86_64/os/Packages/kernel-devel-3.10.0-1160.el7.x86_64.rpm
2)安装 kernel-devel
rpm -ivh kernel-devel-3.10.0-1160.el7.x86_64.rpm
3)查看是否成功安装内核开发环境包 kernel-devel
uname -a ; rpm -qa kernel\* | sort
若成功安装,如下图所示:

三,gcc和g++
yum install gcc
yum install gcc-c++
四,安装 Cuda 驱动
./NVIDIA-Linux-x86_64-515.86.01.run
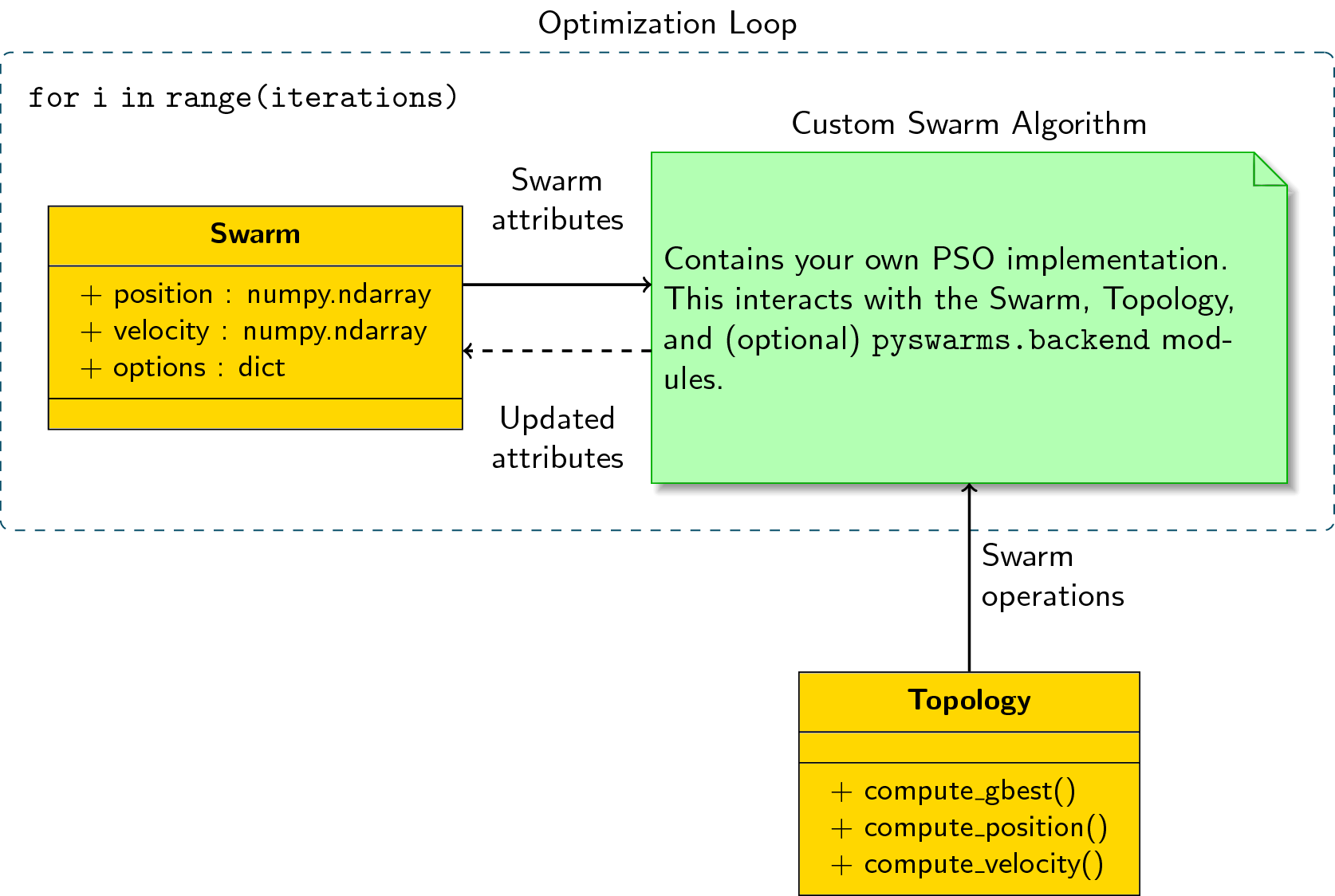
五,安装 NVIDIA-Fabric Manager 软件包
NVIDIA NVSwitch A100 GPU卡,需额外安装与驱动版本对应的 nvidia-fabricmanager 服务使 GPU 卡间能够互联通过NVSwitch互联,如果仅安装NVIDIA GPU 驱动程序,会导致GPU不能正常使用。
1, 安装 nvidia-fabricmanager 详解
安装 nvidia-fabricmanager 详解如下: https://www.volcengine.com/docs/6419/73634
GPU云服务器 -> 用户指南 -> 安装 NVIDIA 驱动 -> 安装NVIDIA-Fabric Manager软件包
2, 整理 nvidia-fabricmanager 安装步骤
1) 查看系统驱动版本
nvidia-smi
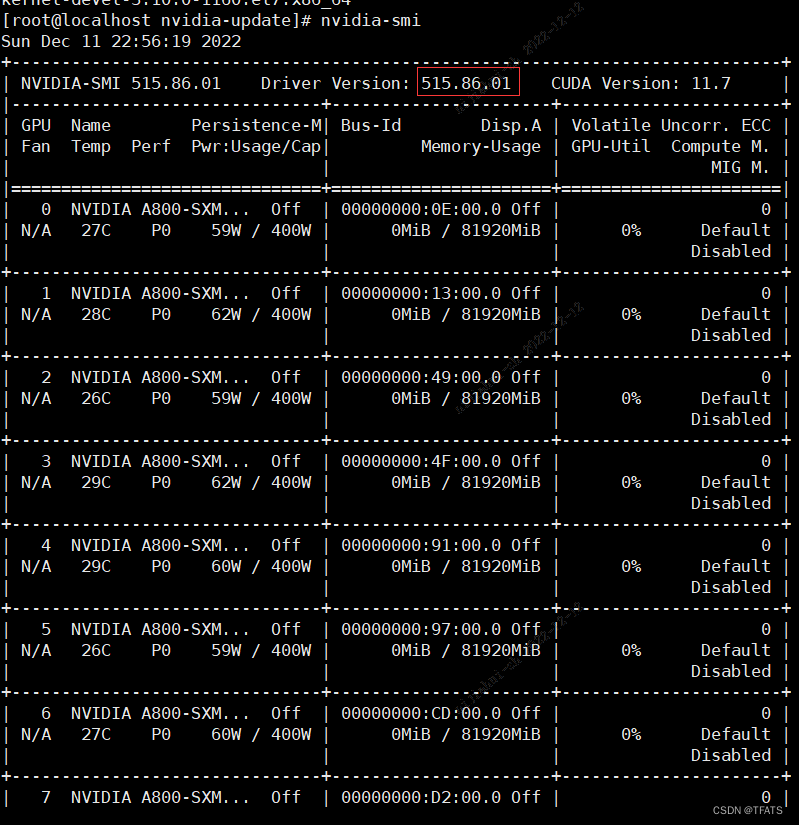
2) 通过安装包安装
- CentOS 8.x
wget https://developer.download.nvidia.cn/compute/cuda/repos/rhel8/x86_64/nvidia-fabric-manager-470.57.02-1.x86_64.rpm
rpm -ivh nvidia-fabric-manager-470.57.02-1.x86_64.rpm
- CentOS 7.x
wget https://developer.download.nvidia.cn/compute/cuda/repos/rhel7/x86_64/nvidia-fabric-manager-470.57.02-1.x86_64.rpm
rpm -ivh nvidia-fabric-manager-470.57.02-1.x86_64.rpm
- Ubuntu 20.04
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64/nvidia-fabricmanager-470_470.57.02-1_amd64.deb
dpkg -i nvidia-fabricmanager-470_470.57.02-1_amd64.deb
- Ubuntu 18.04
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu1804/x86_64/nvidia-fabricmanager-470_470.57.02-1_amd64.deb
dpkg -i nvidia-fabricmanager-470_470.57.02-1_amd64.deb
- Debain 10、veLinux 1.0
wget https://developer.download.nvidia.cn/compute/cuda/repos/debian10/x86_64/nvidia-fabricmanager-470_470.57.02-1_amd64.deb
dpkg -i nvidia-fabricmanager-470_470.57.02-1_amd64.deb
3) 通过源安装
- CentOS 8.x
dnf config-manager --add-repo http://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
dnf module enable -y nvidia-driver:470
dnf install -y nvidia-fabric-manager-0:470.57.02-1
- CentOS 7.x
yum -y install yum-utils
yum-config-manager --add-repo https://developer.download.nvidia.cn/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.repo
yum install -y nvidia-fabric-manager-470.57.02-1
- Ubuntu 20.04
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub
apt-key add 7fa2af80.pub
rm 7fa2af80.pub
echo "deb http://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64 /" | tee /etc/apt/sources.list.d/cuda.list
apt-get update
apt-get -y install nvidia-fabricmanager-470=470.57.02-1
- Ubuntu 18.04
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
apt-key add 7fa2af80.pub
rm 7fa2af80.pub
echo "deb http://developer.download.nvidia.cn/compute/cuda/repos/ubuntu1804/x86_64 /" | tee /etc/apt/sources.list.d/cuda.list
apt-get update
apt-get -y install nvidia-fabricmanager-470=470.57.02-1
4) 启动NVIDIA-Fabric Manager
# 1. 执行以下命令启动Fabric Manager服务。
sudo systemctl start nvidia-fabricmanager
# 2. 执行以下命令查看Fabric Manager服务是否正常启动,回显active(running)表示启动成功。
sudo systemctl status nvidia-fabricmanager
# 3. 执行以下命令配置Fabric Manager服务随实例开机自启动。
sudo systemctl enable nvidia-fabricmanager
六,安装 nvidia-docker
1, 安装 nvidia-docker 详解
安装 nvidia-docker 详解 : https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
2, 总结安装 nvidia-docker
1) 安装在 Ubuntu and Debian
以下步骤可用于在 Ubuntu LTS(18.04、20.04 和 22.04)和 Debian(Stretch、Buster)发行版上设置
NVIDIA Container Toolkit。
- 设置 Docker-CE
curl https://get.docker.com | sh && sudo systemctl --now enable docker
- 设置包存储库和 GPG 密钥:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
要访问experimental功能和发布候选版本,您可能需要将experimental分支添加到存储库列表中:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/experimental/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
- nvidia-docker2更新包列表后安装包(和依赖项)
sudo apt-get update
sudo apt-get install -y nvidia-docker2
- 设置默认运行时后重启Docker守护进程完成安装:
sudo systemctl restart docker
- 此时,可以通过运行基本 CUDA 容器来测试工作设置:
sudo docker run --rm --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi
- 这应该会产生如下所示的控制台输出:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
2) 安装在 CentOS 7/8
以下步骤可用于在 CentOS 7/8 上设置 NVIDIA Container Toolkit。
-
设置官方 Docker CE 存储库:
- CentOS 8.x
sudo dnf config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo- CentOS 7.x
sudo yum-config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo -
现在您可以观察docker-ce存储库中可用的包:
- CentOS 8.x
sudo dnf repolist -v- CentOS 7.x
sudo yum repolist -v
由于 CentOS 不支持containerd.io较新版本的 Docker-CE
所需的特定版本的软件包,因此一种选择是手动安装软件包containerd.io,然后继续安装docker-ce 软件包。
-
安装containerd.io包:
- CentOS 8.x
sudo dnf install -y https://download.docker.com/linux/centos/7/x86_64/stable/Packages/containerd.io-1.4.3-3.1.el7.x86_64.rpm- CentOS 7.x
sudo yum install -y https://download.docker.com/linux/centos/7/x86_64/stable/Packages/containerd.io-1.4.3-3.1.el7.x86_64.rpm -
现在安装最新的docker-ce软件包:
- CentOS 8.x
sudo dnf install docker-ce -y- CentOS 7.x
sudo yum install docker-ce -y -
使用以下命令确保 Docker 服务正在运行:
sudo systemctl --now enable docker -
最后,通过运行hello-world容器来测试你的 Docker 安装:
sudo docker run --rm hello-world -
这应该会产生如下所示的控制台输出:
Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 0e03bdcc26d7: Pull complete Digest: sha256:7f0a9f93b4aa3022c3a4c147a449bf11e0941a1fd0bf4a8e6c9408b2600777c5 Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly. To generate this message, Docker took the following steps: 1. The Docker client contacted the Docker daemon. 2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal. To try something more ambitious, you can run an Ubuntu container with: docker run -it ubuntu bash Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/ For more examples and ideas, visit: https://docs.docker.com/get-started/ -
设置存储库和 GPG 密钥:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \ && curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo -
要访问experimental功能和发布候选版本,您可能需要将experimental分支添加到存储库列表中:
yum-config-manager --enable libnvidia-container-experimental -
nvidia-docker2更新包列表后安装包(和依赖项):
- CentOS 8.x
sudo dnf clean expire-cache --refresh- CentOS 7.x
sudo yum clean expire-cache- CentOS 8.x
sudo dnf install -y nvidia-docker2- CentOS 7.x
sudo yum install -y nvidia-docker2 -
设置默认运行时后重启Docker守护进程完成安装:
sudo systemctl restart docker -
此时,可以通过运行基本 CUDA 容器来测试工作设置:
sudo docker run --rm --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi -
这应该会产生如下所示的控制台输出:
+-----------------------------------------------------------------------------+ | NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+

![[附源码]计算机毕业设计高校车辆管理系统Springboot程序](https://img-blog.csdnimg.cn/cee9635168c542fd912e01f34dd03fe2.png)