深度学习论文: RepViT: Revisiting Mobile CNN From ViT Perspective及其PyTorch实现
RepViT: Revisiting Mobile CNN From ViT Perspective
PDF: https://arxiv.org/pdf/2307.09283.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
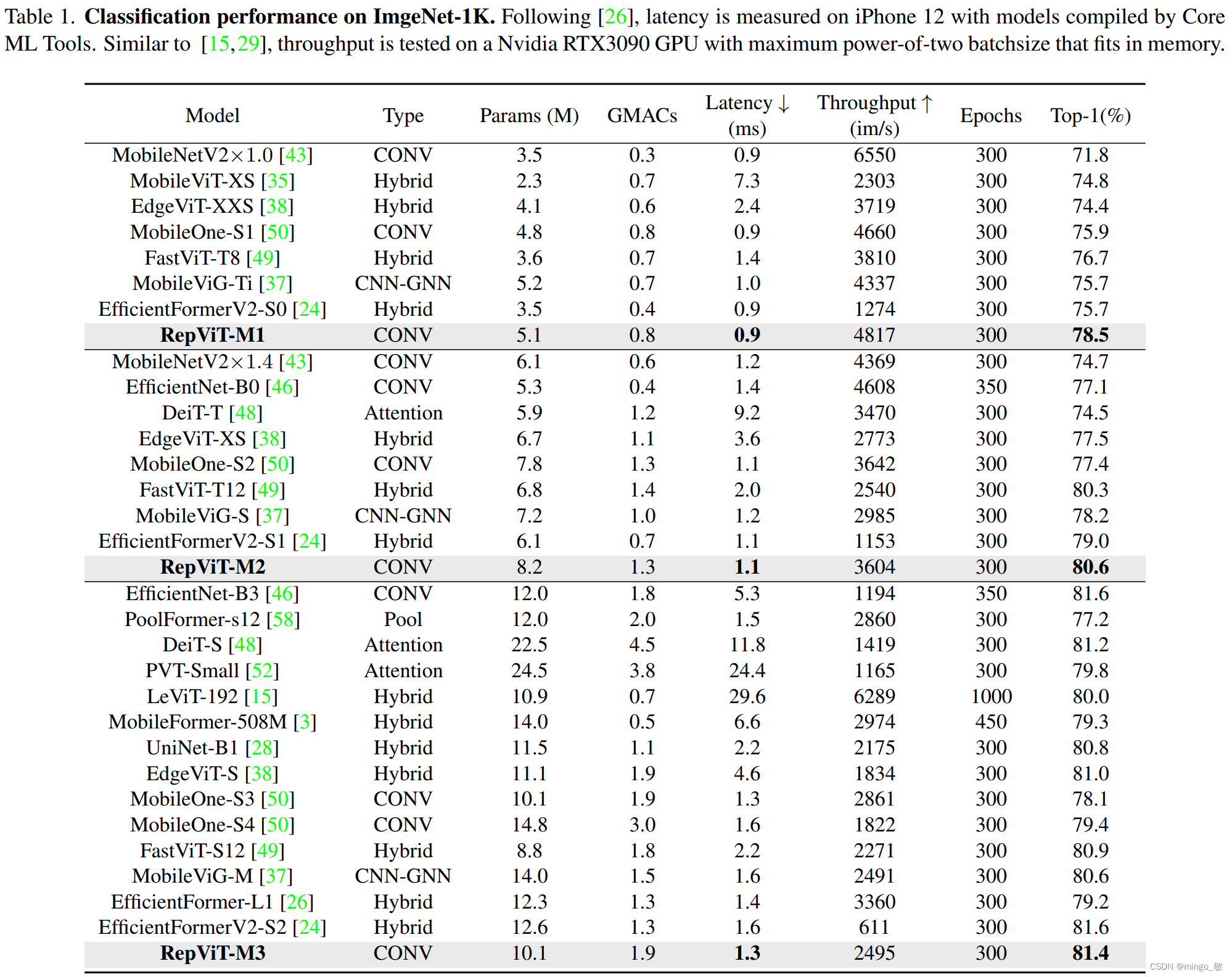
本文通过引入轻量级 ViT 的架构选择,重新审视了轻量级 CNNs 的高效设计。这导致了 RepViT 的出现,这是一种新的轻量级 CNNs 家族,专为资源受限的移动设备设计。在各种视觉任务上,RepViT 超越了现有的最先进的轻量级 ViTs 和 CNNs,显示出优越的性能和延迟。这突显了纯粹的轻量级 CNNs 对移动设备的潜力。
2 RepViT
主要对MobileNetV3-L进行了现代化改进。考虑了移动设备上的延迟和在ImageNet上的top-1准确率。最终,获得了一系列全新的纯轻量级CNN模型,即RepViT,它能够实现更低的延迟和更高的性能。

2-1 Aligning training recipe
train: 300 epochs
optimizer: AdamW
schedule: cosine annealing learning rate
warmup: 5 epochs
数据增强: Mixup, auto-augmentation, random erasing
正则化: Label Smoothing
activations: GeLU replace Hardswish
benchmark metric: Latency metric
2-2 Block design
Separate token mixer and channel mixer. RepViT 将深度卷积提前,使得通道混合器和令牌混合器能够被分开。为了提高性能,还引入了结构重参数化来在训练时为深度滤波器引入多分支拓扑。

Reducing expansion ratio and increasing width. 在通道混合器中,原本的扩张比例是4,这意味着MLP块的隐藏维度是输入维度的四倍,这对计算资源造成了很大的负担,对推理时间产生了显著影响。为了解决这个问题,我们可以将扩张比例降低到2,从而减少了参数冗余和延迟,使得MobileNetV3-L的延迟降低到0.65毫秒。随后,通过增加网络的宽度,即增加各阶段的通道数量,Top-1准确率提高到73.5%,而延迟仅增加到0.89毫秒!
2-3 Macro design
RepViT 从宏观架构元素出发,包括 stem,降采样层,分类器以及整体阶段比例。通过优化这些宏观架构元素,模型的性能可以得到显著提高。
Early convolutions for stem. 复杂的起始模块会引入显著的延迟瓶颈,因此用早期卷积替换了原始的起始模块,同时增大通道数到24。总的延迟降低到0.86ms,同时 top-1 准确率提高到 73.9%。

Deeper downsampling layers. 首先使用一个 1x1 卷积来调整通道维度,然后将两个 1x1 卷积的输入和输出通过残差连接,形成一个前馈网络。此外,他们还在前面增加了一个 RepViT 块以进一步加深下采样层,增加网络深度并减少由于分辨率降低带来的信息损失。这一步提高了 top-1 准确率到 75.4%,同时延迟为 0.96ms。

**Simple classifier. ** 将原来复杂的分类器替换为一个简单的分类器,即一个全局平均池化层和一个线性层,这一步将延迟降低到 0.77ms,同时 top-1 准确率为 74.8%。

Overall stage ratio. 在这项改进中,论文选择了一个更优的阶段比例1:1:7:1,并将网络深度增加到2:2:14:2,从而实现了更深层的布局。这一步使得top-1准确率提高到76.9%,同时延迟仅为1.02毫秒。
2-4 Micro design
RepViT 通过逐层微观设计来调整轻量级 CNN,这包括选择合适的卷积核大小和优化挤压-激励(Squeeze-and-excitation,简称SE)层的位置。这两种方法都能显著改善模型性能。
Kernel size selection. 众所周知,CNNs 的性能和延迟通常受到卷积核大小的影响。为了建模像 MHSA 这样的远距离上下文依赖,ConvNeXt 使用了大卷积核,从而实现了显著的性能提升。然而,大卷积核对于移动设备并不友好,因为它的计算复杂性和内存访问成本。MobileNetV3-L 主要使用 3x3 的卷积,有一部分块中使用 5x5 的卷积。本文将它们替换为3x3的卷积,这导致延迟降低到 1.00ms,同时保持了76.9%的top-1准确率。
Squeeze-and-excitation layer placement.
作为一个通道注意力模块,SE层可以弥补卷积在缺乏数据驱动属性上的限制,从而带来更好的性能。本文设计了一种策略,在所有阶段以交叉块的方式使用SE层,从而在最小的延迟增量下最大化准确率的提升,这一步将top-1准确率提升到77.4%,同时延迟降低到0.87ms。
RepViT的整体架构如下:
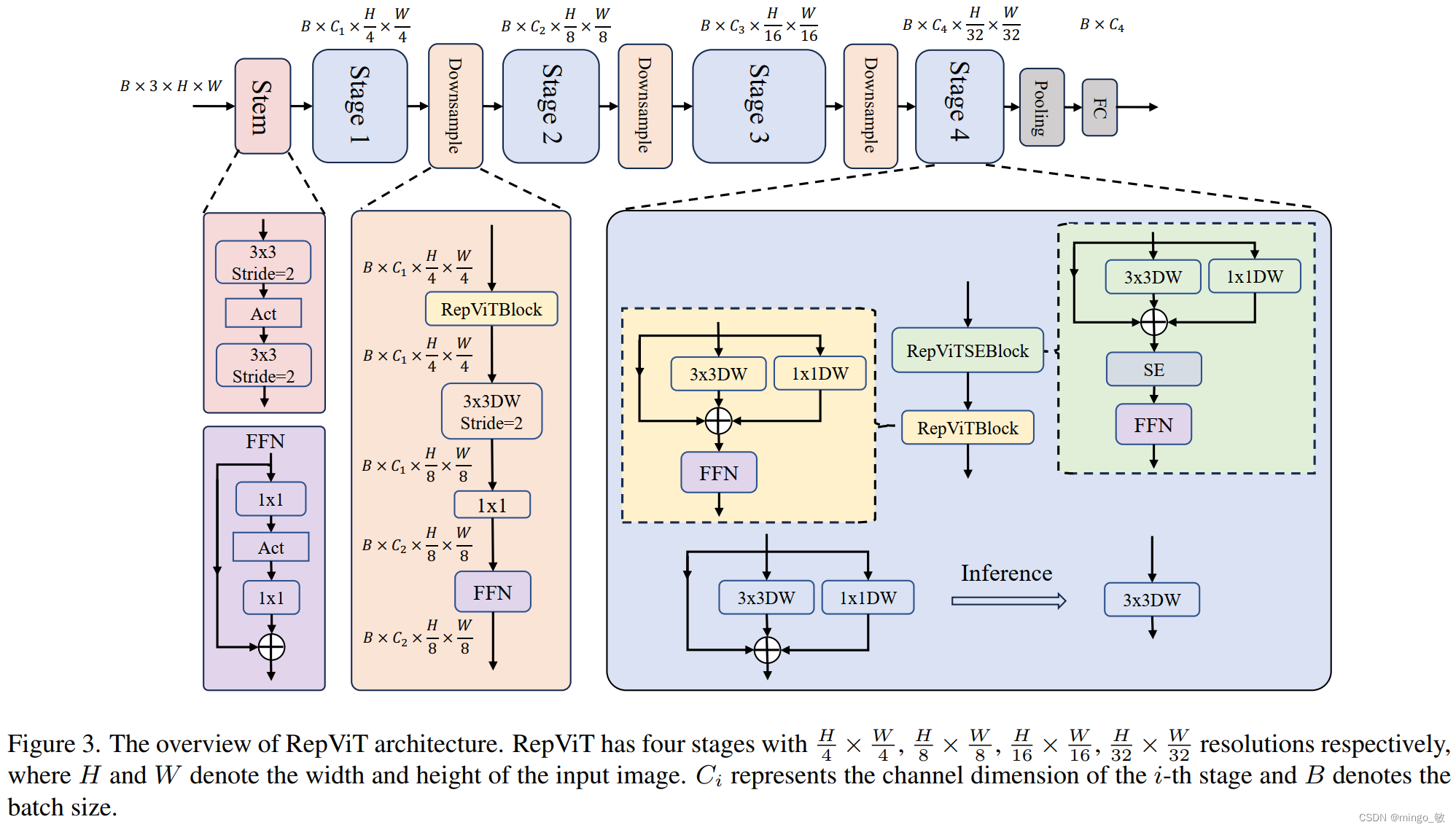
通过整合上述改进策略,我们便得到了模型RepViT的整体架构。

3 Experiments