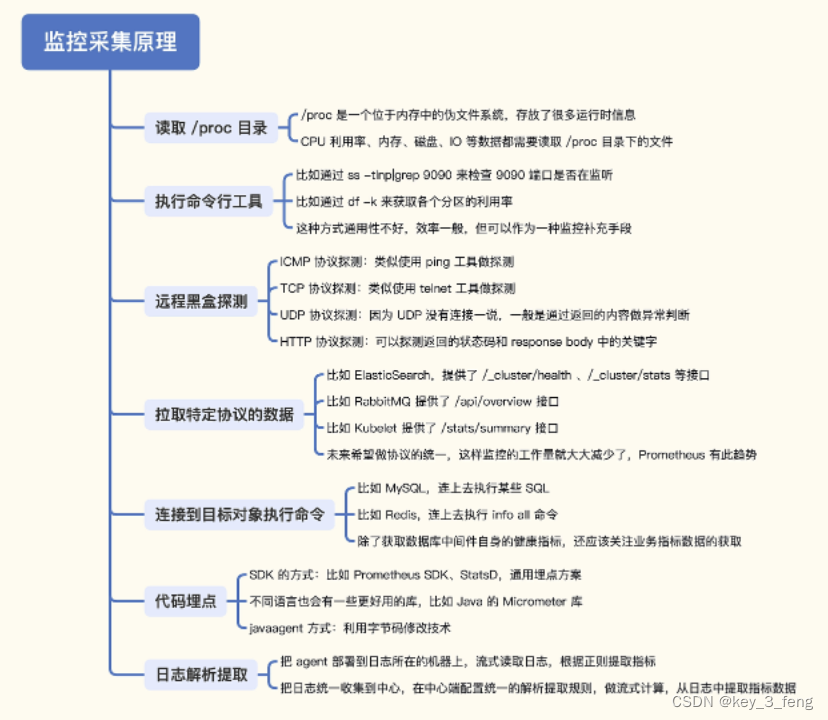
1、读取 /proc 目录
/proc 是一个位于内存中的伪文件系统,该目录下保存的不是真正的文件和目录,而是一些“运行时”信息,Linux 操作系统层面的很多监控数据,比如内存数据、网卡流量、机器负载等,都是从 /proc 中获取的信息。
/proc/meminfo内存总量、剩余量、可用量、Buffer、Cached 等数据都可以轻易拿到。没有使用率、可用率这样的百分比指标,这类指标需要二次计算,可以在客户端采集器中完成,也可以在服务端查询时现算。
2、执行命令行工具
这种方式非常简单,就是调用一下系统命令,解析输出就可以了。比如我们想获取 9090 端口的监听状态,可以使用 ss 命令 ss -tln|grep 9090,想要拿到各个分区的使用率可以通过 df 命令 df -k。但是这个方式不太通用,性能也不好。
3、远程黑盒探测
典型的探测手段有三类,ICMP、TCP 和 HTTP。有一个软件叫 Blackbox Exporter,就是专门用来探测的,Categraf、Datadog-Agent 等采集器也都可以做这种探测。
监控采集器和手工 Ping 测试的原理是一样的,也是发几个包做统计。不过有些机器是禁 Ping 的,这时候我们就可以通过 TCP 或 HTTP 来探测。对于 Linux 机器,一般是会开放 sshd 的 22 端口,那我们就可以用类似 telnet 的方式探测机器的 22 端口,如果成功就认为机器存活。
对于 HTTP 协议的探测,除了基本的连通性测试,还可以检查协议内容,比如要求返回的 status code 必须是 200,返回的 response body 必须包含 success 字符串,如果任何一个条件没有满足,从监控的角度就认为是异常的。
4、拉取特定协议的数据
有很多组件都通过 HTTP 接口的方式,暴露了自身的监控指标。如 RabbitMQ,访问 /api/overview 可以拿到 Message 数量、Connection 数量等概要信息。再比如 Kubelet,访问 /stats/summary 可以拿到 Node 和 Pod 等很多概要信息。
不同的接口返回的内容虽然都是指标数据,但是要推给监控服务端,还是要做一次格式转换,比如统一转换为 Prometheus 的文本格式。要是这些组件都直接暴露 Prometheus 的协议数据就好了,使用统一的解析器,就能大大简化监控采集逻辑。
这种拉取监控数据的方式虽然需要做一些数据格式的转换,但并不复杂。因为目标对象会把需要监控的数据直接通过接口暴露出来,监控采集器把数据拉到本地做格式转换即可。
5、连接到目标对象执行命令
目前最常用的数据库就是 MySQL 和 Redis 了。MySQL,我们经常需要获取一些连接相关的指标数据,比如当前有多少连接,总共拒绝了多少连接,总共接收过多少连接,登录 MySQL 命令行,使用下面的命令可以获取。
mysql> show global status like '%onn%';
+-----------------------------------------------+---------------------+
| Variable_name | Value |
+-----------------------------------------------+---------------------+
| Aborted_connects | 3212 |
| Connection_errors_accept | 0 |
| Connection_errors_internal | 0 |
| Connection_errors_max_connections | 0 |
| Connection_errors_peer_address | 0 |
| Connection_errors_select | 0 |
| Connection_errors_tcpwrap | 0 |
| Connections | 3281 |
| Locked_connects | 0 |
| Max_used_connections | 13 |
| Max_used_connections_time | 2022-10-30 16:41:35 |
| Performance_schema_session_connect_attrs_lost | 0 |
| Ssl_client_connects | 0 |
| Ssl_connect_renegotiates | 0 |
| Ssl_finished_connects | 0 |
| Threads_connected | 1 |
+-----------------------------------------------+---------------------+
16 rows in set (0.01 sec)Threads_connected 表示当前有多少连接,Max_used_connections 表示曾经最多有多少连接,Connections 表示总计接收过多少连接。当然,除了连接数相关的指标,通过 show global status 还可以获取很多其他的指标,这些指标用于表示 MySQL 的运行状态,随着实例运行,这些数据会动态变化。
还有另一个命令 show global variables 可以获取一些全局变量信息,比如使用下面的命令可以获取 MySQL 最大连接数。
mysql> show global variables like '%onn%';
+-----------------------------------------------+-----------------+
| Variable_name | Value |
+-----------------------------------------------+-----------------+
| character_set_connection | utf8 |
| collation_connection | utf8_general_ci |
| connect_timeout | 10 |
| disconnect_on_expired_password | ON |
| init_connect | |
| max_connect_errors | 100 |
| max_connections | 5000 |
| max_user_connections | 0 |
| performance_schema_session_connect_attrs_size | 512 |
+-----------------------------------------------+-----------------+
9 rows in set (0.01 sec)其中 max_connections 就是最大连接数,这个数值默认是 151。在很多生产环境下,都应该调大,所以我们要把这个指标作为一个告警规则监控起来,如果发现这个数值太小要及时告警。
比如 show slave status 可以获取 Slave 节点的信息。总的来看,MySQL 监控的原理就是,连上 MySQL 后执行各种 SQL 语句,解析结果,转换为监控时序数据。
6、代码埋点
所谓的代码埋点方式,是指应用程序内嵌一些监控相关的 SDK,在请求的关键链路上调用 SDK 的方法,告诉 SDK 当前是个什么请求、耗时多少、是否成功之类的,SDK 汇总这些数据并二次计算,最终推给监控服务端。
比如一个用 Go 写的 Web 程序,提供了 10 个 HTTP 接口,我们想获取这 10 个接口的成功率和延迟数据,那就要写程序实现这些逻辑,包括数据采集、统计、转发给服务端等。这些监控相关的逻辑是典型的横向需求,这个 Web 程序有需求,其他的程序也有这个需求,所以就把这部分代码抽象成一个统一的 Lib,即上面提到的这个 SDK,每个需要监控逻辑的程序都可以复用这个 SDK,提升效率。
7、日志解析
一般程序都会打印日志,可以写日志解析程序,从日志中提取一些关键信息,比如从业务日志中很容易拿到 Exception 关键字出现的次数,从接入层日志中很容易就能拿到某个接口的访问次数。
此文章为8月Day3学习笔记,内容来源于极客时间《运维监控系统实战笔记》,推荐该课程。