之前的两篇文章:
- 第一篇文章介绍了本项目的背景, 获取了
Boost库文档
🫦[C++项目] Boost文档 站内搜索引擎(1): 项目背景介绍、相关技术栈、相关概念介绍…- 第二篇文章 分析实现了
parser模块. 此模块的作用是 对所有文档html文件, 进行清理并汇总
🫦[C++项目] Boost文档 站内搜索引擎(2): 文档文本解析模块parser的实现、如何对文档文件去标签、如何获取文档标题…
至此, 搜索引擎建立索引的4个步骤:
- 爬虫程序爬取网络上的内容, 获取网页等数据
- 对爬取的内容进行解析、去标签, 提取文本、链接、媒体内容等信息
- 对提取的文本进行分词、处理, 得到词条
- 根据词条生成索引, 包括正排索引、倒排索引等
已经完成了前两个
本篇文章完成后两步中, 索引建立的相关接口.
索引
之前做的工作, 已经将所有的文档有效内容写入了data/output/raw文件中
接下来要实现的就是索引的建立.
本项目中, 需要根据raw文件的内容, 分别建立 正排索引 和 倒排索引
- 正排索引, 是从文档
id找到 文件内容 的索引 - 倒排索引, 是从关键字 找到 关键字所在文档
id的索引
而首先要做的是 搭建索引建立的代码结构
建立索引 基本代码结构
本项目要实现的检索索引的流程是:
- 先 通过关键字 检索倒排索引, 获取包含关键字的文档的
id - 然后 通过文档
id检索正排索引, 获取文档内容 - 最后通过文档内容 建立搜索结果的网页
也就是说, 正排索引中需要存储 文档id 和 对应的文档内容, 倒排索引中需要存储 关键字 和 所有包含关键字的文档的id
正排索引和倒排索引的建立都需要获取文档id, 那么 文档id 要在什么时候设置呢? 再建立正排索引时设置还是在建立倒排索引时建立呢?
答案很明显, 要先对文档建立正排索引, 并在 正排索引建立时设置文档id. 因为正排索引的建立 需要 文档id与文档内容 一一对应. 而 倒排索引的建立只是通过 关键字 映射到 包含关键字的文档的id. 没有对应关系也不能与文档本身建立联系.
正排索引结构
暂且不提文档id. 文档内容该怎样存储到正派索引中呢? 直接使用一个string吗?
当然不是, 正排索引中存储的文档内容, 实际是文档的相关信息: title 去标签后的content 官网对应的url
所以, 可以使用结构体(docInfo)来存储文档内容
那么文档id呢? 文档id是索引中文档内容的唯一标识. 文档id该如何设置呢?
当然是使用 数组下标. 如果将每个文档的内容存储在vector中, 那么对应的下标不就天然是文档id吗?
那么, 正排索引 的结构就是 vector<docInfo_t>
倒排索引结构
倒排索引 需要 通过关键字 找到包含关键字的文档id
由于多个文档可能包含相同的关键字, 这意味着在倒排索引中 通过关键字检索 需要可以 获取到一系列数据
这也意味着 本项目中的 倒排索引更适合key:value结构存储. 所以 可以使用unordered_map, 并且value的类型 可以是存储着文档id的vector.
我们将通过关键字 在倒排索引中检索到的 存储有相关文档id的vector, 称为 倒排拉链
而且需要注意的是, 倒排索引是通过关键字 搜索文档的索引. 而搜索引擎, 也是通过关键字来搜索的.
也就是说 搜索引擎搜索到的文档, 就是倒排索引中相关关键字映射到的文档
而 搜索引擎搜索到的结果, 在网页中的显示是需要有一定的顺序的. 也就是 与关键字 高相关的显示在上面, 低相关的显示在后面.
正排索引是文档id到文档内容的索引, 很明显与网页的显示顺序是没有关系的.
而 倒排索引是关键字与相关文档id的映射索引, 所以 设置显示顺序的相关数据也需要在倒排索引中体现. 可以通过 关键字在相关文档中的出现次数, 来简单的判断关键字与文档的相关性(也可以说是关键字在不同文档中的权重).
那么就可以将 关键字相关的文档id 与 关键字在文档中的权重 存储到一个结构体 中. 将此结构体变量存储在 倒排拉链中. 这样 通过关键字检索到文档id的同时, 也检索到了 关键字与此文档的相关度. 可以将这个结构体定义为invertedElem倒排元素
这样 倒排索引 的结构就是 unordered_map<string, vector<invertedElem>>
建立索引 基本结构代码
#pragma once
#include <iostream>
#include <fstream>
#include <utility>
#include <vector>
#include <string>
#include <unordered_map>
#include "util.hpp"
namespace ns_index {
// 用于正排索引中 存储文档内容
typedef struct docInfo {
std::string _title; // 文档标题
std::string _content; // 文档去标签之后的内容
std::string _url; // 文档对应官网url
std::size_t _docId; // 文档id
} docInfo_t;
// 用于倒排索引中 记录关键字对应的文档id和权重
typedef struct invertedElem {
std::size_t _docId; // 文档id
std::string _keyword; // 关键字
std::uint64_t _weight; // 搜索此关键字, 此文档id 所占权重
invertedElem() // 权重初始化为0
: _weight(0) {}
} invertedElem_t;
// 倒排拉链
typedef std::vector<invertedElem_t> invertedList_t;
class index {
private:
// 正排索引使用vector, 下标天然是 文档id
std::vector<docInfo_t> forwardIndex;
// 倒排索引 使用 哈希表, 因为倒排索引 一定是 一个key 对应一组 invertedElem拉链
std::unordered_map<std::string, invertedList_t> invertedIndex;
public:
// 通过关键字 检索倒排索引, 获取对应的 倒排拉链
invertedList_t* getInvertedList(const std::string& keyword) {
return nullptr;
}
// 通过倒排拉链中 每个倒排元素中存储的 文档id, 检索正排索引, 获取对应文档内容
docInfo_t* getForwardIndex(std::size_t docId) {
return nullptr;
}
// 建立索引 input 为 ./data/output/raw
bool buildIndex(const std::string& input) {
return true;
}
private:
// 对一个文档建立正排索引, 获取文档结构体
docInfo_t* buildForwardIndex(const std::string& file) {
return nullptr;
}
// 对一个文档建立倒排索引
bool buildInvertedIndex(const docInfo_t& doc) {
return true;
}
};
}
1. getInvertedList()接口 实现
getInvertedList()接口的功能非常的简单. 只需要通过关键字检索倒排索引, 获取关键字对应的倒排拉链就可以了
我们已经将倒排索引的结构设置成了unordered_map, 所以这个接口非常容易实现:
// 通过关键字 检索倒排索引, 获取对应的 倒排拉链
invertedList_t* getInvertedList(const std::string& keyword) {
// 先找 关键字 所在迭代器
auto iter = invertedIndex.find(keyword);
if (iter == invertedIndex.end()) {
std::cerr << keyword << " have no invertedList!" << std::endl;
return nullptr;
}
// 找到之后
return &(iter->second);
}
直接通过unrodered_map的find()接口找到对应关键字的迭代器.
再通过迭代器 返回对应的倒排拉链
2. getForwardIndex()接口 实现
getForwardIndex()接口同样非常简单, 要获取正排索引中的对应docId的文档内容.
实际就是返回vector中docId下标的数据:
// 通过倒排拉链中 每个倒排元素中存储的 文档id, 检索正排索引, 获取对应文档内容
docInfo_t* getForwardIndex(std::size_t docId) {
if (docId >= forwardIndex.size()) {
std::cerr << "docId out range, error!" << std::endl;
return nullptr;
}
return &forwardIndex[docId];
}
3. buildIndex()接口 实现
buildIndex()接口需要实现的功能是: 将parser模块处理过的 所有文档的信息, 建立 正排索引和倒排索引
可以直接打开对应的文本文件, 按行完整地读取到每个文档的内容.
然后根据文档的内容, 先对其建立正排索引, 再建立倒排索引.
// 提取文档信息, 建立 正排索引和倒排索引
// input 为 ./data/output/raw
bool buildIndex(const std::string& input) {
// 先以读取方式打开文件
std::ifstream in(input, std::ios::in);
if (!in.is_open()) {
std::cerr << "Failed to open " << input << std::endl;
return false;
}
std::string line;
while (std::getline(in, line)) {
// 按照parser模块的处理, getline 一次读取到的数据, 就是一个文档的: title\3content\3url\n
docInfo_t* doc = buildForwardIndex(line); // 将一个文档的数据 建立到索引中
if (nullptr == doc) {
std::cerr << "Failed to buildForwardIndex for " << line << std::endl;
continue;
}
// 文档建立正排索引成功, 接着就通过 doc 建立倒排索引
if (!buildInvertedIndex(*doc)) {
std::cerr << "Failed to buildInvertedIndex for " << line << std::endl;
continue;
}
}
return true;
}
这里执行
std::getline()按行读取文件内容, 每一次都可以直接读取到一整个文档的信息.因为,
parser模块处理时, 按'\n'将每个文档的信息分隔开了
读取到之后, 就对文档建立正排索引 和 倒排索引:

buildForwardIndex()接口 实现
buildForwardIndex()接口需要实现的功能是:
接收一行完整的文档信息. 然后将文档信息提取成: title content url 并构成结构体docInfo, 并将结构体存储到forwardIndex(一个vector)中. 并设置下标为docInfo中的docId
// 对一个文档建立正排索引
docInfo_t* buildForwardIndex(const std::string& file) {
// 一个文档的 正排索引的建立, 是将 title\3content\3url (file) 中title content url 提取出来
// 构成一个 docInfo_t doc
// 然后将 doc 存储到正排索引vector中
std::vector<std::string> fileResult;
const std::string sep("\3");
// stringUtil::split() 字符串通用工具接口, 分割字符串
ns_util::stringUtil::split(file, &fileResult, sep);
docInfo_t doc;
doc._title = fileResult[0];
doc._content = fileResult[1];
doc._url = fileResult[2];
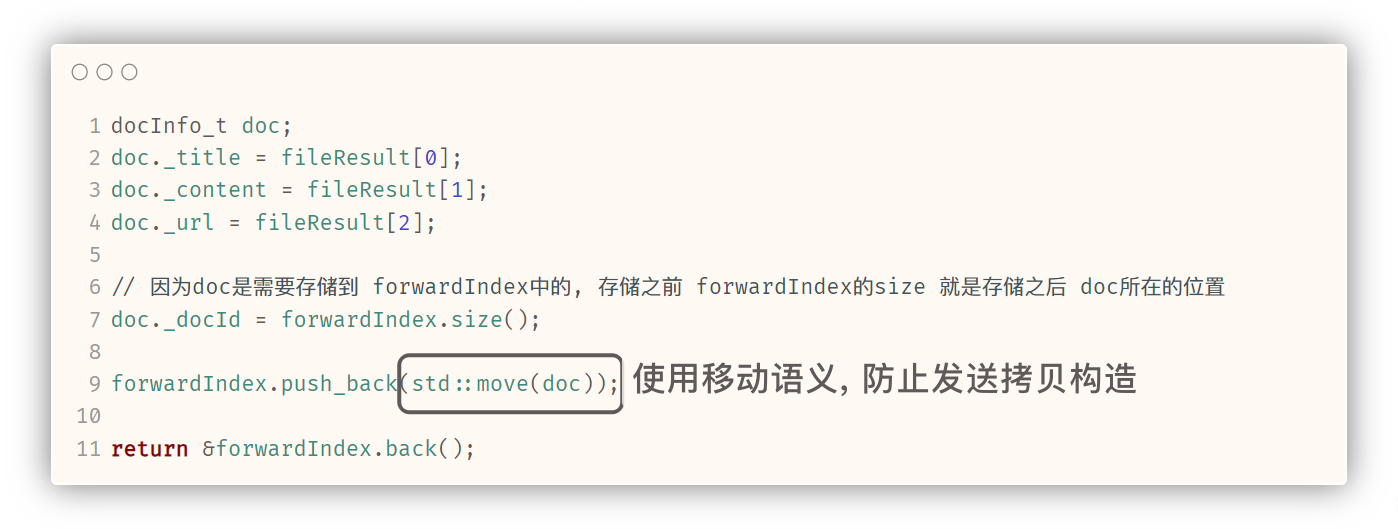
// 因为doc是需要存储到 forwardIndex中的, 存储之前 forwardIndex的size 就是存储之后 doc所在的位置
doc._docId = forwardIndex.size();
forwardIndex.push_back(std::move(doc));
return &forwardIndex.back();
}
本函数接收到完整的一行文档信息file之后, 先通过boost::split()接口以'\3'为分隔符将title content url分隔开. 并按顺序存储到fileResult(一个vector)中
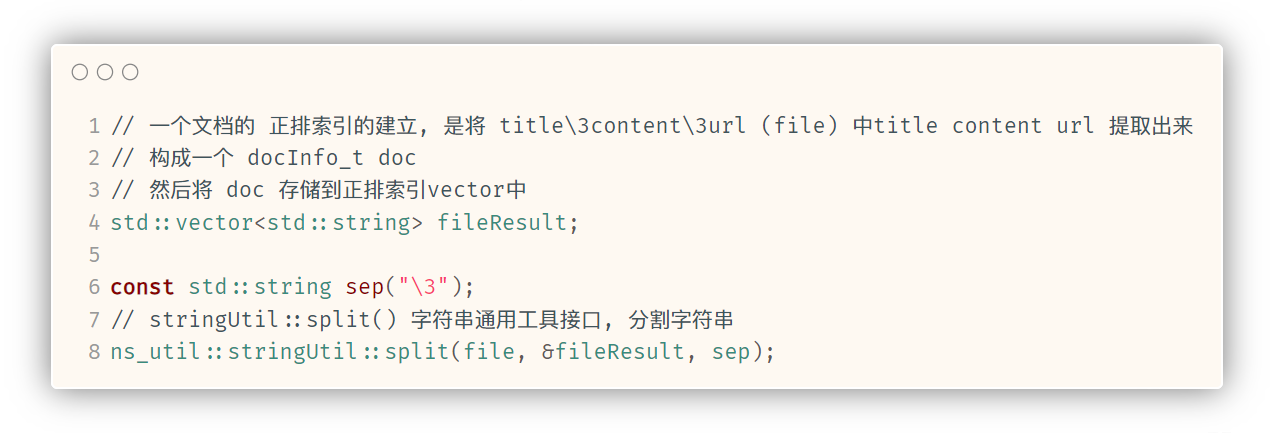
然后, 定义docInfo结构体 并根据fileResult的元素值 填充结构体成员. 填充完毕之后, 将doc存储到forwardIndex中. 并返回正排索引中的当前文档信息.
正排索引的实现相对简单
boost::split()分割字符串接口的使用
buildForwardIndex()函数中, 分割file字符串, 调用了ns_util::stringUtil::split(file, &fileResult, sep)
这是定义在util.hpp中的一个接口:
namespace ns_util {
class stringUtil {
public:
static bool split(const std::string& file, std::vector<std::string>* fileResult, const std::string& sep) {
// 使用 boost库中的split接口, 可以将 string 以指定的分割符分割, 并存储到vector<string>输出型参数中
boost::split(*fileResult, file, boost::is_any_of(sep), boost::algorithm::token_compress_on);
// boost::algorithm::token_compress_on 表示压缩连续的分割符
if (fileResult->empty()) {
return false;
}
return true;
}
};
}
此接口内调用了boost::split()接口
boost::split()是boost库提供的一个 以特定的分割符 分割字符串的接口.
官方文档中, 关于它的描述是这样的:

官方的演示中, split( SplitVec, str1, is_any_of("-*"), token_compress_on ); 将 ("hello abc-*-ABC-*-aBc goodbye"); 分割成了 "hello abc" "ABC" "aBc goodbye" 按顺序存储到了SplitVec中
最后一个框框中的描述 翻译是这样的:
第二个示例使用
split()将字符串str1由字符“-”或“*”分隔的部分 拆分. 然后将这些部分放入SplitVec中. 可以指定相邻分隔符是否连接并且提到, 更多信息可以看
boost/algorithm/string/split.hpp
boost/algorithm/string/split.hpp中, 关于split()的描述是:
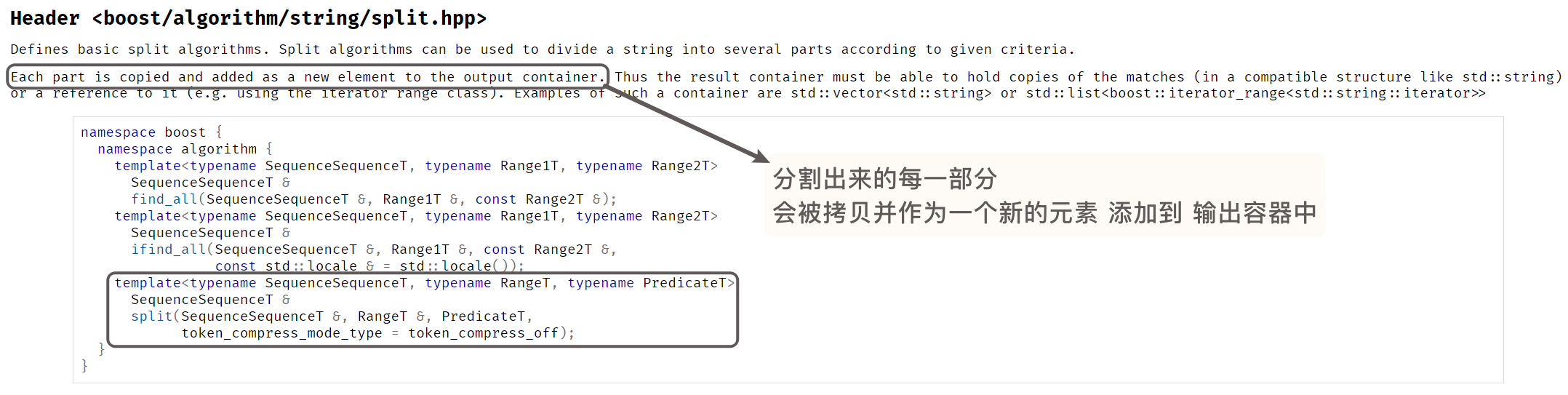
我们根据执行的结果其实已经可以了解到boost::split()的前三个参数是什么了:
boost::split(接收分割出来的字符串的容器, 需要被分割的字符串, boost::is_any_of(分割符字符串), 第四个参数)
boost::split()会将 指定字符串 以分隔符字符串中的任意字符 分割开 并存储到指定的容器中
不过, 第四个参数有什么用呢?
文档中对boost::split()的描述有这样一句话: It is possible to specify if adjacent separators are concatenated or not.(可以指定相邻分隔符是否连接)
什么是相邻分隔符是否连接呢?
可以举一个例子来试验一下:
#include <iostream>
#include <string>
#include <vector>
#include <boost/algorithm/string.hpp>
int main() {
std::string str = "asdasdasd\3\3\3\3\3\3\3\3\3\3qwdasdasdasda";
std::vector<std::string> strV;
boost::split(strV, str, boost::is_any_of("\3"), boost::algorithm::token_compress_on);
//boost::split(strV, str, boost::is_any_of("\3"), boost::algorithm::token_compress_off);
for (auto& e : strV) {
std::cout << e << std::endl;
}
return 0;
}

第四个参数设置为boost::algorithm::token_compress_on时的结果是这样的.
如果设置为boost::algorithm::token_compress_off:

在分割出来的两个字符串之间, 还存在9个空行.
这就是 设置相邻分隔符不连接 的情况.
相邻分隔符连接的意思是, 将相邻的分隔符压缩成一个分隔符. 比如: \3\3\3\3\3\3\3\3\3\3 会被压缩成\3
如果 设置相邻分隔符不连接, 那么 两个分隔符之间会被看作有一个空字符串. 这个空字符串也会被存储到输出型容器中: \3\3两个分隔符之间有一个空字符串"", 被添加到strV中.
如果, 在打印strV内容的时候不换行:

可以看到, 中间是没有任何数据的.
buildInvertedIndex()接口 实现
buildInvertedIndex()接口针对文档信息, 创建倒排索引的接口.
倒排索引是 从关键字 到 相关文档id和权重 的索引. 所以首先要做的就是 针对文档标题和文档内容进行分词
本项目中使用cppjieba开源库分词.
准备: 在项目中安装cppjieba中文分词库
此开源库的安装非常简单.
首先找一个目录执行这两个命令:
git clone https://github.com/yanyiwu/cppjieba.git
git clone https://github.com/yanyiwu/limonp.git
先看一看cppjieba/deps/limonp目录下有没有内容:

# 如果cppjieba/deps/limonp没有内容, 执行下面的命令
cp -r limonp/include/limonp cppjieba/include/cppjieba/.
# 如果cppjieba/deps/limonp有内容, 执行下面的命令
cp -r cppjieba/deps/limonp cppjieba/include/cppjieba/.
然后查看cppjieba/include/cppjieba/limonp目录下 应该是有内容的:

然后, 将cppjieba/include/cppjieba和cppjieba/dict拷贝到项目目录下:
# 博主的项目路径是 /home/July/gitCode/github/Boost-Doc-Searcher
# 注意自己的项目路径
# ❯ pwd
# /home/July/jieba
cp -r cppjieba/include/cppjieba /home/July/gitCode/github/Boost-Doc-Searcher/.
cp -r cppjieba/dict /home/July/gitCode/github/Boost-Doc-Searcher/.
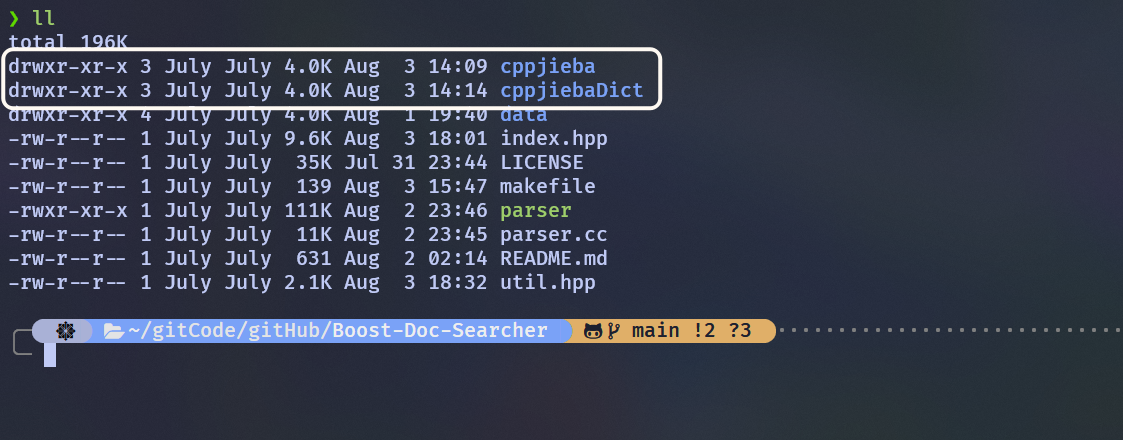
然后查看项目路径下:
这样就把cppjieba库和dict分词库都安装到项目中了
这里博主将
dict目录重命名为cppjiebaDict
关于cppjieba的使用
git clone下来的cppjieba中, 提供了一个简单的cppjieba/test/demo.cpp测试文件:
可以也将其临时拷贝到项目目录下, 然后打开补全 并修正 头文件:
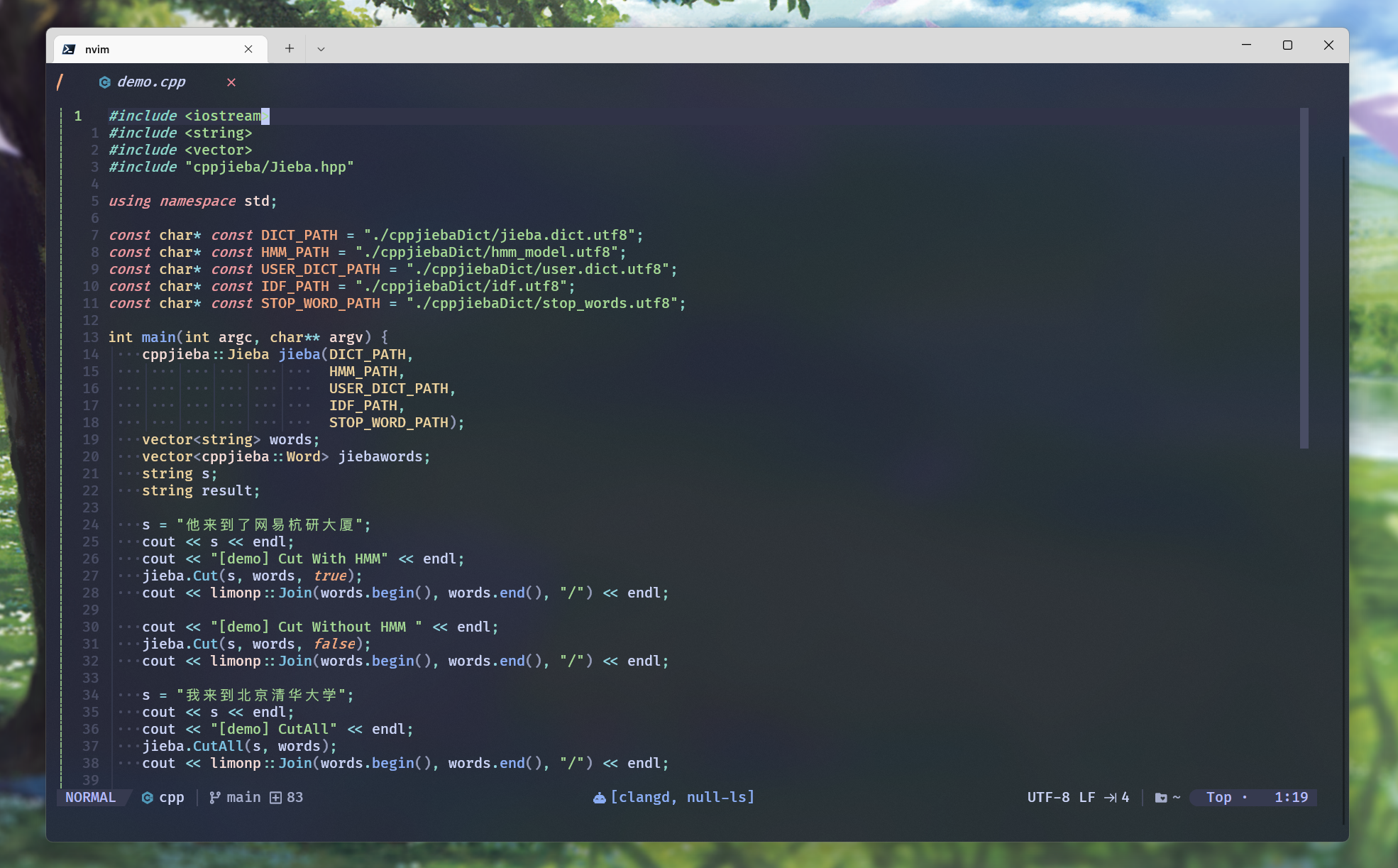
然后编译, 运行可以执行程序:

可以看到有许多的分词方式, 我们选择CutForSearch:

cppjieba的使用是先根据各种分词库, 创建一个Jieba对象. 然后调用Jieba对象中的相应的接口, 来实现分词.
jieba.CutForSearch()是按照搜索的风格分词分词的, 第一个参数是需要分词的字符串, 第二个参数是需要记录分词的vector

开始: 实现buildInvertedIndex()接口
倒排索引是用来通过关键词定位文档的.
倒排索引的结构是 std::unordered_map<std::string, invertedList_t> invertedIndex;
unordered_map的key值就是关键字, value值则是关键字所映射到的文档的倒排拉链
对一个文档建立倒排索引的原理是:
-
首先对文档的标题 和 内容进行分词, 并记录分词
-
分别统计整理 标题分词的词频 和 内容分词的词频
统计词频是为了可以大概表示关键字在文档中的 相关性. 在本项目中, 可以简单的认为关键词在文档中出现的频率, 代表了此文档内容与关键词的相关性. 当然这是非常肤浅的联系, 一般来说相关性的判断都是非常复杂的. 因为涉及到词义 语义等相关分析.
每个关键字 在标题中出现的频率 和 在内容中出现的频率, 可以记录在一个结构体
(keywordCnt)中. 此结构体就表示关键字的词频这里可以直接使用
unordered_map<std::string, keywordCnt_t>容器, 并使用[]重载来记录关键字以及词频 -
通过遍历 记录关键字与词频的
unordered_map, 构建invertedElem:_docId,_keyword,_weight -
构建了关键字的
invertedElem之后, 再将关键词的invertedElem添加到在invertedIndex中 关键词的倒排拉链invertedList中
要实现搜索引擎不区分大小写, 可以将分词出来的所有的 关键字, 在倒排索引中均以小写的形式映射. 在搜索时 同样将 搜索请求分词出的关键字小写化, 在进行检索. 就可以实现搜索不区分大小写.
bool buildInvertedIndex(const docInfo_t& doc) {
// 用来映射关键字 和 关键字的词频
std::unordered_map<std::string, keywordCnt_t> keywordsMap;
// 标题分词
std::vector<std::string> titleKeywords;
ns_util::jiebaUtil::cutString(doc._title, &titleKeywords);
// 标题词频统计 与 转换 记录
for (auto keyword : titleKeywords) {
boost::to_lower(keyword); // 关键字转小写
keywordsMap[keyword]._titleCnt++; // 记录关键字 并统计标题中词频
// unordered_map 的 [], 是用来通过keyword值 访问value的.
// 如果keyword值已经存在, 则返回对应的value, 如果keyword值不存在, 则会插入keyword并创建对应的value
}
// 内容分词
std::vector<std::string> contentKeywords;
ns_util::jiebaUtil::cutString(doc._content, &contentKeywords);
// 内容词频统计 与 转换 记录
for (auto keyword : contentKeywords) {
boost::to_lower(keyword); // 关键字转小写
keywordsMap[keyword]._contentCnt++; // 记录关键字 并统计内容中词频
}
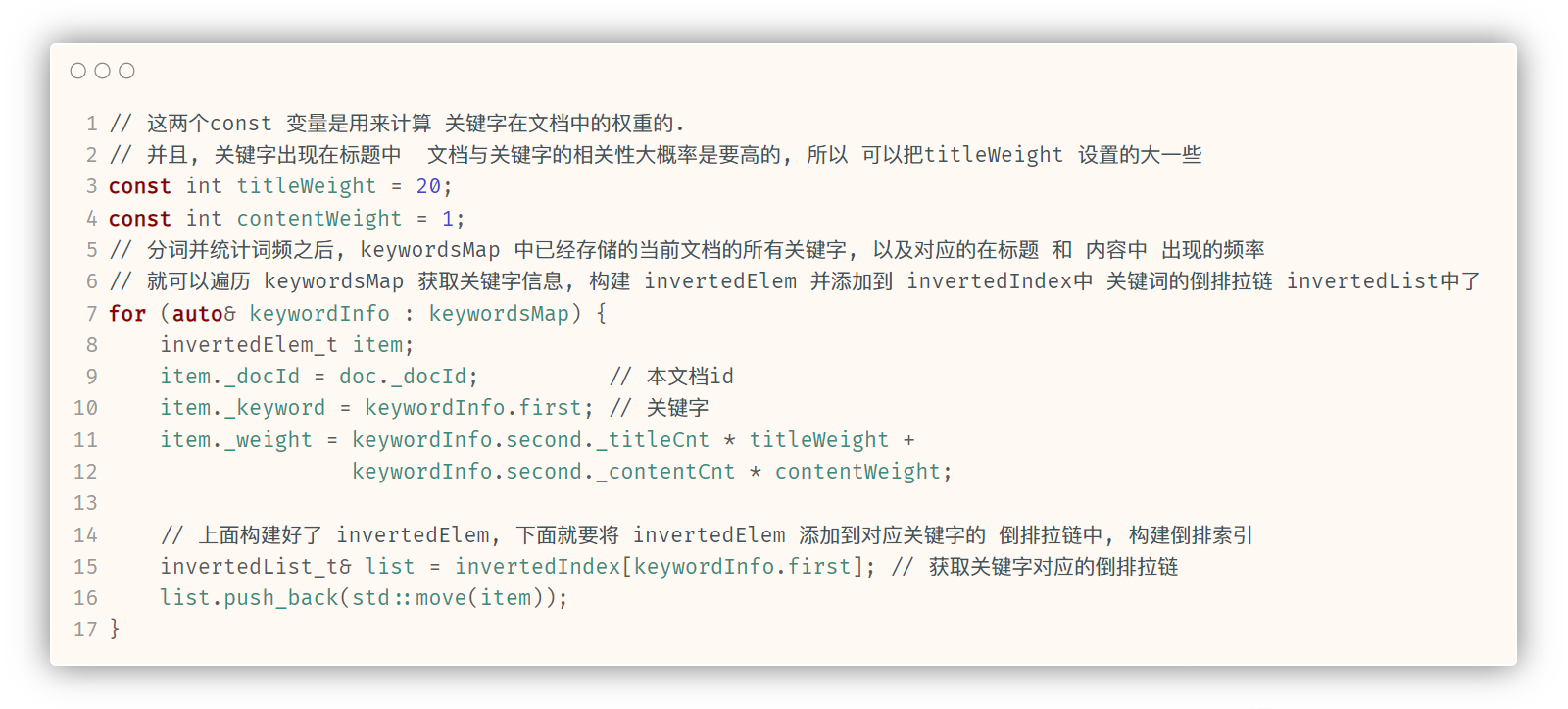
// 这两个const 变量是用来计算 关键字在文档中的权重的.
// 并且, 关键字出现在标题中 文档与关键字的相关性大概率是要高的, 所以 可以把titleWeight 设置的大一些
const int titleWeight = 20;
const int contentWeight = 1;
// 分词并统计词频之后, keywordsMap 中已经存储的当前文档的所有关键字, 以及对应的在标题 和 内容中 出现的频率
// 就可以遍历 keywordsMap 获取关键字信息, 构建 invertedElem 并添加到 invertedIndex中 关键词的倒排拉链 invertedList中了
for (auto& keywordInfo : keywordsMap) {
invertedElem_t item;
item._docId = doc._docId; // 本文档id
item._keyword = keywordInfo.first; // 关键字
item._weight = keywordInfo.second._titleCnt * titleWeight + keywordInfo.second._contentCnt * contentWeight;
// 上面构建好了 invertedElem, 下面就要将 invertedElem 添加到对应关键字的 倒排拉链中, 构建倒排索引
invertedList_t& list = invertedIndex[keywordInfo.first]; // 获取关键字对应的倒排拉链
list.push_back(std::move(item));
}
return true;
}
首先, 分别针对title和content进行分词.
然后分别遍历 标题分词 和 内容分词, 并将当前分词转换为全小写, 然后通过unordered_map::operator[]()来记录分词和分词的词频

最终, 将 标题和内容 的所有分词 以及对应出现在标题的频率和内容的频率, 都记录在了keywordsMap中
然后, 遍历keywordsMap根据当前的关键字以及词频, 构建invertedElem结构体 并填充数据.
填充完之后, 获取对应关键词在invertedIndex中的倒排拉链, 将invertedElem添加到倒排拉链中, 完成对文档的倒排索引建立
ns_util::jiebaUtil::cutString()接口 实现
Jieba::CutForSearch()不仅构建索引时需要使用, 在搜索输入字符串时, 同样需要对输入的字符串以相同的算法分词.
而且, 由于CutForSearch()是Jieba类内成员函数. 所以是需要通过Jieba对象调用的. 如果每次分词都需要先实例化一个Jieba对象, 这未免太麻烦了
所以将可以将Jieba::CutForSearch()在util.hpp中, 实现为一个通用工具函数:
namespace ns_util{
const char* const DICT_PATH = "./cppjiebaDict/jieba.dict.utf8";
const char* const HMM_PATH = "./cppjiebaDict/hmm_model.utf8";
const char* const USER_DICT_PATH = "./cppjiebaDict/user.dict.utf8";
const char* const IDF_PATH = "./cppjiebaDict/idf.utf8";
const char* const STOP_WORD_PATH = "./cppjiebaDict/stop_words.utf8";
class jiebaUtil {
private:
static cppjieba::Jieba jieba;
public:
static void cutString(const std::string& src, std::vector<std::string>* out) {
// 以用于搜索的方式 分词
jieba.CutForSearch(src, *out);
}
};
cppjieba::Jieba jiebaUtil::jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);
}
在jiebaUtil类内, 定义一个static cppjieba::Jieba jieba. 通过这个静态的Jieba对象 调用CutForSearch(), 并将其封装为一个static函数.
就可以实现非常方便的分词函数.
建立索引代码接口 整合
只包括本篇文章新增的代码, 不包括之前的代码
util.hpp:
#pragma once
#include <iostream>
#include <vector>
#include <string>
#include <fstream>
#include <boost/algorithm/string.hpp>
#include "cppjieba/Jieba.hpp"
namespace ns_util {
class stringUtil {
public:
static bool split(const std::string& file, std::vector<std::string>* fileResult, const std::string& sep) {
// 使用 boost库中的split接口, 可以将 string 以指定的分割符分割, 并存储到vector<string>输出型参数中
boost::split(*fileResult, file, boost::is_any_of(sep), boost::algorithm::token_compress_on);
// boost::algorithm::token_compress_on 表示压缩连续的分割符
if (fileResult->empty()) {
return false;
}
return true;
}
};
const char* const DICT_PATH = "./cppjiebaDict/jieba.dict.utf8";
const char* const HMM_PATH = "./cppjiebaDict/hmm_model.utf8";
const char* const USER_DICT_PATH = "./cppjiebaDict/user.dict.utf8";
const char* const IDF_PATH = "./cppjiebaDict/idf.utf8";
const char* const STOP_WORD_PATH = "./cppjiebaDict/stop_words.utf8";
class jiebaUtil {
private:
static cppjieba::Jieba jieba;
public:
static void cutString(const std::string& src, std::vector<std::string>* out) {
// 以用于搜索的方式 分词
jieba.CutForSearch(src, *out);
}
};
cppjieba::Jieba jiebaUtil::jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);
} // namespace ns_util
index.hpp:
#pragma once
#include <iostream>
#include <fstream>
#include <utility>
#include <vector>
#include <string>
#include <unordered_map>
#include "util.hpp"
namespace ns_index {
// 用于正排索引中 存储文档内容
typedef struct docInfo {
std::string _title; // 文档标题
std::string _content; // 文档去标签之后的内容
std::string _url; // 文档对应官网url
std::size_t _docId; // 文档id
} docInfo_t;
// 用于倒排索引中 记录关键字对应的文档id和权重
typedef struct invertedElem {
std::size_t _docId; // 文档id
std::string _keyword; // 关键字
std::uint64_t _weight; // 搜索此关键字, 此文档id 所占权重
invertedElem() // 权重初始化为0
: _weight(0) {}
} invertedElem_t;
// 关键字的词频
typedef struct keywordCnt {
std::size_t _titleCnt; // 关键字在标题中出现的次数
std::size_t _contentCnt; // 关键字在内容中出现的次数
keywordCnt()
: _titleCnt(0)
, _contentCnt(0) {}
} keywordCnt_t;
// 倒排拉链
typedef std::vector<invertedElem_t> invertedList_t;
class index {
private:
// 正排索引使用vector, 下标天然是 文档id
std::vector<docInfo_t> forwardIndex;
// 倒排索引 使用 哈希表, 因为倒排索引 一定是 一个keyword 对应一组 invertedElem拉链
std::unordered_map<std::string, invertedList_t> invertedIndex;
public:
// 通过关键字 检索倒排索引, 获取对应的 倒排拉链
invertedList_t* getInvertedList(const std::string& keyword) {
// 先找 关键字 所在迭代器
auto iter = invertedIndex.find(keyword);
if (iter == invertedIndex.end()) {
std::cerr << keyword << " have no invertedList!" << std::endl;
return nullptr;
}
// 找到之后
return &(iter->second);
}
// 通过倒排拉链中 每个倒排元素中存储的 文档id, 检索正排索引, 获取对应文档内容
docInfo_t* getForwardIndex(std::size_t docId) {
if (docId >= forwardIndex.size()) {
std::cerr << "docId out range, error!" << std::endl;
return nullptr;
}
return &forwardIndex[docId];
}
// 根据parser模块处理过的 所有文档的信息
// 提取文档信息, 建立 正排索引和倒排索引
// input 为 ./data/output/raw
bool buildIndex(const std::string& input) {
// 先以读取方式打开文件
std::ifstream in(input, std::ios::in);
if (!in.is_open()) {
std::cerr << "Failed to open " << input << std::endl;
return false;
}
std::string line;
while (std::getline(in, line)) {
// 按照parser模块的处理, getline 一次读取到的数据, 就是一个文档的: title\3content\3url\n
docInfo_t* doc = buildForwardIndex(line); // 将一个文档的数据 建立到索引中
if (nullptr == doc) {
std::cerr << "Failed to buildForwardIndex for " << line << std::endl;
continue;
}
// 文档建立正排索引成功, 接着就通过 doc 建立倒排索引
if (!buildInvertedIndex(*doc)) {
std::cerr << "Failed to buildInvertedIndex for " << line << std::endl;
continue;
}
}
return true;
}
private:
// 对一个文档建立正排索引
docInfo_t* buildForwardIndex(const std::string& file) {
// 一个文档的 正排索引的建立, 是将 title\3content\3url (file) 中title content url 提取出来
// 构成一个 docInfo_t doc
// 然后将 doc 存储到正排索引vector中
std::vector<std::string> fileResult;
const std::string sep("\3");
// stringUtil::split() 字符串通用工具接口, 分割字符串
ns_util::stringUtil::split(file, &fileResult, sep);
docInfo_t doc;
doc._title = fileResult[0];
doc._content = fileResult[1];
doc._url = fileResult[2];
// 因为doc是需要存储到 forwardIndex中的, 存储之前 forwardIndex的size 就是存储之后 doc所在的位置
doc._docId = forwardIndex.size();
forwardIndex.push_back(std::move(doc));
return &forwardIndex.back();
}
// 对一个文档建立倒排索引
// 倒排索引是用来通过关键词定位文档的.
// 倒排索引的结构是 std::unordered_map<std::string, invertedList_t> invertedIndex;
// keyword值就是关键字, value值则是关键字所映射到的文档的倒排拉链
// 对一个文档建立倒排索引的原理是:
// 1. 首先对文档的标题 和 内容进行分词, 并记录分词
// 2. 分别统计整理标题分析的词频 和 内容分词的词频
// 统计词频是为了可以大概表示关键字在文档中的 相关性.
// 在本项目中, 可以简单的认为关键词在文档中出现的频率, 代表了此文档内容与关键词的相关性. 当然这是非常肤浅的联系, 一般来说相关性的判断都是非常复杂的. 因为涉及到词义 语义等相关分析.
// 每个关键字 在标题中出现的频率 和 在内容中出现的频率, 可以记录在一个结构体中. 此结构体就表示关键字的词频
// 3. 使用 unordered_map<std::string, wordCnt_t> 记录关键字与其词频
// 4. 通过遍历记录关键字与词频的 unordered_map, 构建 invertedElem: _docId, _keyword, _weight
// 5. 构建了关键字的invertedElem 之后, 再将关键词的invertedElem 添加到在 invertedIndex中 关键词的倒排拉链 invertedList中
// 注意, 搜索引擎一般不区分大小写, 所以可以将分词出来的所有的关键字, 在倒排索引中均以小写的形式映射. 在搜索时 同样将搜索请求分词出的关键字小写化, 在进行检索. 就可以实现搜索不区分大小写.
// 关于分词 使用 cppjieba 中文分词库
bool buildInvertedIndex(const docInfo_t& doc) {
// 用来映射关键字 和 关键字的词频
std::unordered_map<std::string, keywordCnt_t> keywordsMap;
// 标题分词
std::vector<std::string> titleKeywords;
ns_util::jiebaUtil::cutString(doc._title, &titleKeywords);
// 标题词频统计 与 转换 记录
for (auto keyword : titleKeywords) {
boost::to_lower(keyword); // 关键字转小写
keywordsMap[keyword]._titleCnt++; // 记录关键字 并统计标题中词频
// unordered_map 的 [], 是用来通过keyword值 访问value的. 如果keyword值已经存在, 则返回对应的value, 如果keyword值不存在, 则会插入keyword并创建对应的value
}
// 内容分词
std::vector<std::string> contentKeywords;
ns_util::jiebaUtil::cutString(doc._content, &contentKeywords);
// 内容词频统计 与 转换 记录
for (auto keyword : contentKeywords) {
boost::to_lower(keyword); // 关键字转小写
keywordsMap[keyword]._contentCnt++; // 记录关键字 并统计内容中词频
}
// 这两个const 变量是用来计算 关键字在文档中的权重的.
// 并且, 关键字出现在标题中 文档与关键字的相关性大概率是要高的, 所以 可以把titleWeight 设置的大一些
const int titleWeight = 20;
const int contentWeight = 1;
// 分词并统计词频之后, keywordsMap 中已经存储的当前文档的所有关键字, 以及对应的在标题 和 内容中 出现的频率
// 就可以遍历 keywordsMap 获取关键字信息, 构建 invertedElem 并添加到 invertedIndex中 关键词的倒排拉链 invertedList中了
for (auto& keywordInfo : keywordsMap) {
invertedElem_t item;
item._docId = doc._docId; // 本文档id
item._keyword = keywordInfo.first; // 关键字
item._weight = keywordInfo.second._titleCnt * titleWeight + keywordInfo.second._contentCnt * contentWeight;
// 上面构建好了 invertedElem, 下面就要将 invertedElem 添加到对应关键字的 倒排拉链中, 构建倒排索引
invertedList_t& list = invertedIndex[keywordInfo.first]; // 获取关键字对应的倒排拉链
list.push_back(std::move(item));
}
return true;
}
};
} // namespace ns_index
OK了, 首版关于索引建立的相关接口就完成了
感谢阅读~