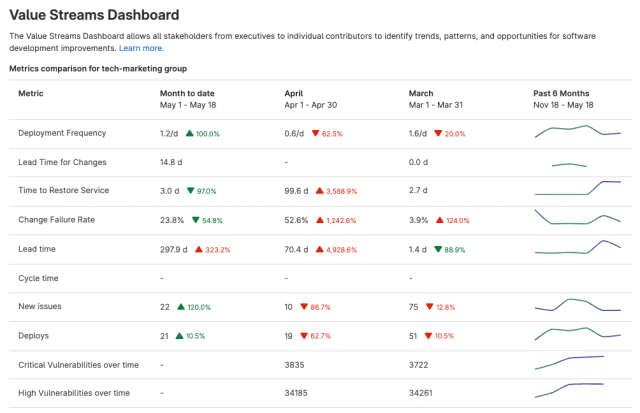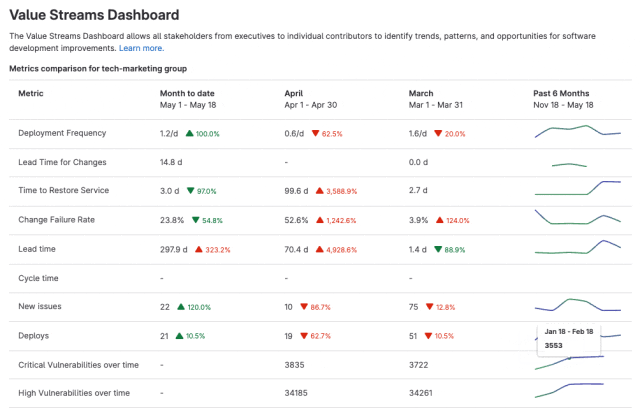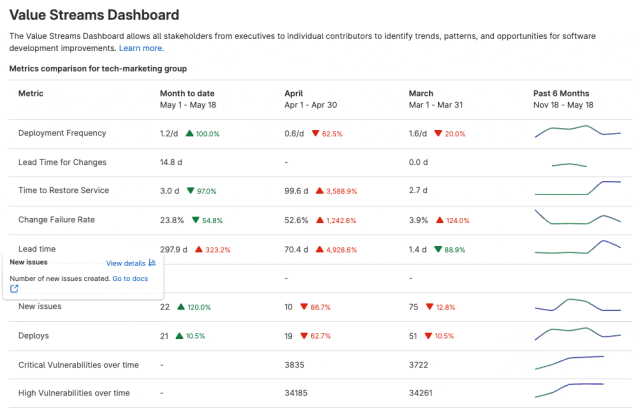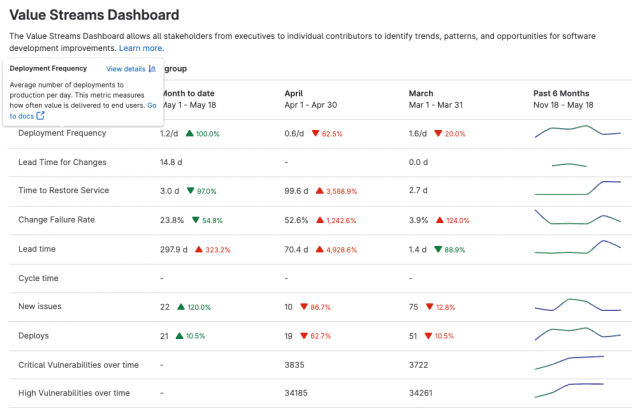
这个问题是检验web和计网学习程度的经典问题。
网站访问流程:
1.域名->ip地址
1) 在输入完一个域名之后,首先是检查浏览器自身的DNS缓存是否有相应IP地址映射,如果没有对应的解析记录,浏览器会查找本机的hosts配置文件(一般是C:\Windows\System32\drivers\etc\hosts,这个文件是用于在操作系统级别上主机名和IP地址的映射。在这个文件中,可以手动添加自定义的主机名和对应的IP地址,当操作系统进行域名解析时,会首先查找hosts文件,如果找到匹配的主机名,就会直接使用对应的IP地址进行访问,而不再通过DNS进行解析)。

hosts文件中的映射关系优先级比DNS解析高。如果在hosts文件中有映射关系,浏览器会直接使用该映射关系中的IP地址进行访问
2) 如果以上都没有查到,才进行DNS解析。
a.在进行DNS解析时,首先会检查本地DNS缓存中是否存在对应的解析结果。如果已经存在,则直接使用缓存中的结果,不再向远程DNS服务器发送查询请求。
如果本地DNS服务器缓存中没有对应的解析记录,则本地DNS服务器会向根DNS服务器发起递归查询请求。
- Windows DNS客户端服务会在解析域名时自动将域名解析的结果存储在本地DNS缓存中,以便在后续的请求中能够快速获取解析结果,提高解析的速度和效率。存储在本地DNS缓存中的解析记录包括域名和对应的IP地址。本地DNS缓存的域名解析记录存储在Windows DNS客户端服务(DNS Client Service)管理的缓存数据库中,不是一个特定的文件。该缓存位于系统内存中,而不是磁盘上的文件。
- 解析记录的存储时间是有限的,具体的存活时间由服务器的TTL(Time-to-Live)时间决定。TTL是DNS服务器在返回解析结果时附加的一个时间值,表示该解析结果的有效生命周期。一般情况下,解析记录的存活时间为TTL值减去DNS查询的耗时。
- 当解析记录的存活时间过期后,下一次需要解析该域名时,DNS客户端服务会重新发送解析请求给DNS解析器,并更新本地DNS缓存中的解析记录。因此,本地DNS缓存中的解析记录是动态的,会根据TTL值进行自动更新。
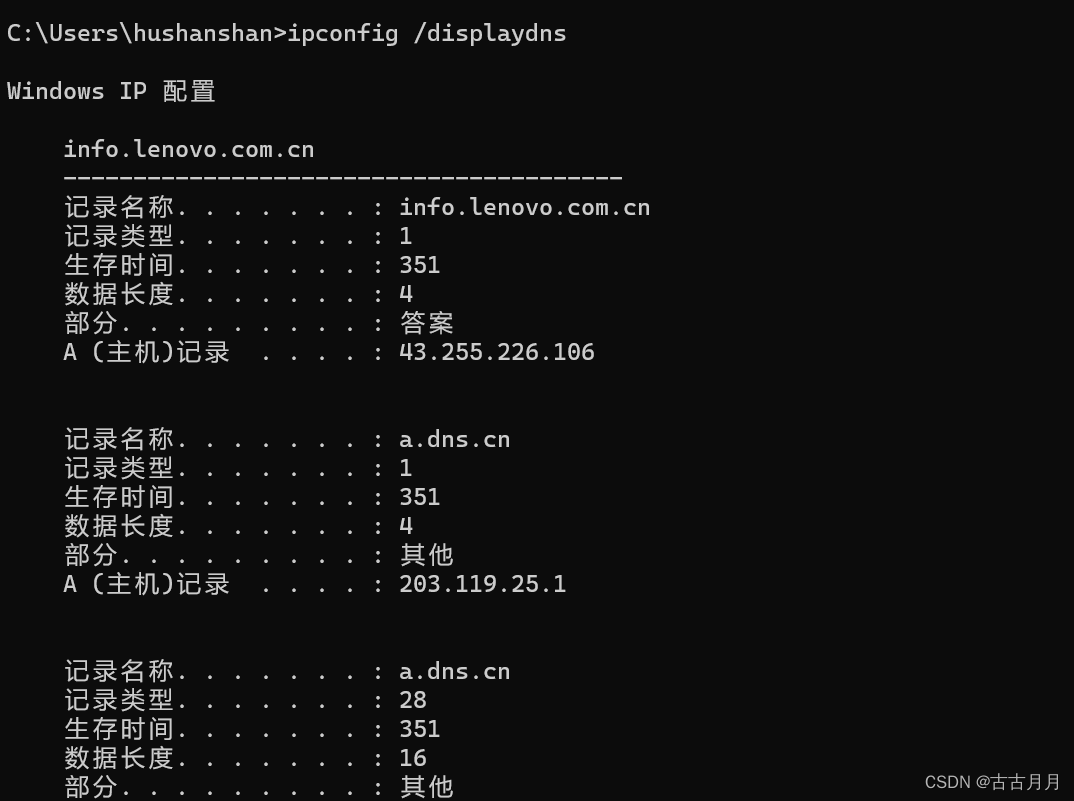
- Windows系统中,可以通过命令行ipconfig /displaydns执行以下命令来显示本地DNS缓存的详细信息:
b.如果本地DNS服务器缓存中没有对应的解析记录,浏览器会向由你的网络服务提供商(ISP,如中国移动中国电信等)提供的DNS服务器发起解析请求(除了ISP提供,也可以是组织内部建立的DNS服务器),传递需要解析的域名给这个DNS服务器。
- 这个DNS服务器称为本地DNS服务器,它是用户主机在进行域名解析时的第一站,它会查找自己的缓存,看是否存在对应的解析记录,如果没有,则本地DNS服务器会向根DNS服务器发起递归查询请求。
- 根DNS服务器是互联网域名系统(DNS)的最高层级服务器,它存储了所有顶级域名(如.com、.net、.org等)的DNS记录。根DNS服务器的作用是将域名解析请求转发到下一级的DNS服务器。本地DNS服务器将结果返回给用户主机,用户主机操作系统接收到DNS解析器返回的结果后,将结果存储到本地DNS缓存中,并将IP地址返回给浏览器。
- 完成域名解析过程。
2.浏览器根据解析得到的IP地址,与服务器建立TCP连接
浏览器通过DNS解析获取到目标服务器的IP地址之后,使用TCP的三次握手来确保连接的可靠性。
- 浏览器向目标服务器发起连接请求(SYN包),其中包含自己的初始序列号。
- 目标服务器接收到连接请求后,会回复一个确认连接请求的ACK包,其中包含自己的初始序列号和对浏览器初始序列号的确认。
- 浏览器收到目标服务器的ACK包后,会向目标服务器发送一个确认ACK包,同时会发送自己所期望的下一个序列号。
- 目标服务器收到浏览器的确认ACK包后,连接建立成功,可以开始进行数据传输。
浏览器 目标服务器 -------------- SYN包 --------------> <--------------ACK包 (对SYN的确认,以及自己的序列号) -------------- ACK包 -------------->三次握手的目的是确保双方都能正确接收到对方的连接请求和确认,以建立一个可靠的连接。在握手过程中,双方交换了初始序列号,这是为了后续的数据传输进行序列号的管理和确认。
-
思考:三次握手是什么,为什么吗,为什么不多或者少次数?
3.建立连接后,浏览器发送请求,服务器处理请求
建立连接后,用户的请求会发送给本地网络中的网关设备,网关会根据目标服务器的IP地址和本地网络的路由表来选择到达目标服务器的下一跳。网关会检查请求的目标IP地址,然后查找本地网络的路由表,确定该请求需要通过哪个接口发送出去,经过一系列路由的选择,最终到达目标服务器(当用户主机与服务器位于同一个局域网或子网中时,用户主机可以直接与服务器建立连接,不需要经过网关或路由器。在这种情况下,用户主机会通过ARP(Address Resolution Protocol,地址解析协议)获取目标服务器的MAC地址,直接发送数据包到目标服务器)。
请求包括:
- 请求方法(Get,Post,HEAD,DELETE,PUT,TRACT…)
- 请求URL(包含主机名、路径等)
- 请求头部(包括用户代理、语言、内容类型、Cookie等)
- 请求正文(POST请求时包含表单数据等)
Accept: //告诉服务器它所支持的数据类型
Accept-Encoding: //支持哪种编码格式:GBK,UTF-8,GB2312,ISO8859-1
Accept-Language: //告诉服务器它的语言环境
Cache-Control: //缓存控制
Connection: //告诉服务器,请求完成是断开还是保持连接
HOST: //主机
...
思考:GET和POST请求区别?
GET:一次请求可以携带的参数比较少,大小有限制,会在浏览器的URL地址栏显示数据内容,不安全,但高效。
POST:一次请求可以携带的参数没有限制,大小没有限制,不会在浏览器的URL地址栏显示数据内容,安全,但不高效。TCP就像汽车,我们用TCP来运输数据,它很可靠,从来不会发生丢件少件的现象。但是如果路上跑的全是看起来一模一样的汽车,那这个世界看起来是一团混乱,送急件的汽车可能被前面满载货物的汽车拦堵在路上,整个交通系统一定会瘫痪。为了避免这种情况发生,交通规则HTTP诞生了。HTTP给汽车运输设定了好几个服务类别,有GET, POST, PUT, DELETE等等一共8类,HTTP规定,当执行GET请求的时候,要给汽车贴上GET的标签(设置method为GET),而且要求把传送的数据放在车顶上(url中)以方便记录。如果是POST请求,就要在车上贴上POST的标签,并把货物放在车厢里。
还有另一个重要的角色:运输公司。不同的浏览器(发起http请求)和服务器(接受http请求)就是不同的运输公司。 虽然理论上,你可以在车顶上无限的堆货物(url中无限加参数)。但是运输公司可不傻,装货和卸货也是有很大成本的,他们会限制单次运输量来控制风险,数据量太大对浏览器和服务器都是很大负担。如果你用GET服务,在request body偷偷藏了数据,不同服务器的处理方式也是不同的,有些服务器会帮你卸货,读出数据,有些服务器直接忽略,所以,虽然GET可以带request body,也不能保证一定能被接收到。
总结:HTTP只是个行为准则,HTTP的底层是TCP/IP,所以可以理解为GET和POST的底层也是TCP/IP,也就是说,GET/POST都是TCP链接。GET和POST能做的事情从本质上说是一样的。
传输数据方式存在区别:
传送方式:get通过地址栏传输,post通过报文传输(request body)。
get方式的安全性较Post方式要差些,包含机密信息的话,建议用Post数据提交方式,在做数据查询时,建议用Get方式;而在做数据添加、修改或删除时,建议用Post方式。
传送长度:get有长度限制,一般限制在 2kb 左右;post传送的数据量较大,一般被默认为不受限制。 get和post的传送数据大小跟各个浏览器、操作系统以及服务器的限制有关。
因为GET是通过URL提交数据,那么GET可提交的数据量就跟URL的长度有直接关系 了。而实际上,URL不存在参数上限的问题,HTTP协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制。IE对URL长度的限制是2083字节(2KB+35)。用apache测试,使用get方式,url最长可达8167b。
get请求的过程:
(1)浏览器请求tcp连接(第一次握手)
(2)服务器答应进行tcp连接(第二次握手)
(3)浏览器确认,并发送get请求头和数据(第三次握手,这个报文比较小,所以http会在此时进行第一次数据发送)
(4)服务器返回200 OK响应
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
post请求的过程:
(1)浏览器请求tcp连接(第一次握手)
(2)服务器答应进行tcp连接(第二次握手)
(3)浏览器确认,并发送post请求头(第三次握手,这个报文比较小,所以http会在此时进行第一次数据发送)
(4)服务器返回100 Continue响应
(5)浏览器发送数据
(6)服务器返回200 OK响应
服务器处理请求:
- 服务器接收到HTTP请求后,会根据请求的内容进行处理。这可能包括查询数据库、读取文件、执行程序等。
- 服务器处理完请求后,生成一个HTTP响应,包括响应行(如状态码)、响应头部和响应正文(所请求的资源)。
浏览器解析服务器的HTTP相应:
-
渲染页面:
a. 浏览器开始解析HTML响应内容,逐步构建DOM树(文档对象模型)。当解析到外部资源(如CSS和JavaScript)时,浏览器会发送额外的HTTP请求去获取这些资源。
b. 浏览器使用CSS解析器对页面进行样式计算,并生成渲染树。
c. 浏览器进行布局和绘制过程,将页面元素摆放在正确的位置,并根据样式信息绘制页面。 -
显示页面:
a. 浏览器将绘制好的页面内容显示在浏览器窗口中,用户可以看到页面并与页面进行交互。
在整个过程中,还包括了一些优化措施,如缓存机制(浏览器会缓存静态资源,如图片、CSS和JavaScript),以及一些安全机制(如HTTPS的加密通信)。每个步骤都有其特定的协议和规范,以保证数据的传输和交互的可靠性、安全性和效率。
不准确的地方恳请指正~