Llama 2是Llama 1模型的升级版本,引入了一系列预训练和微调 LLM,参数量范围从7B到70B (7B、13B、70B)。其预训练模型比 Llama 1模型有了显著改进,包括训练数据的总词元数增加了 40%、上下文长度更长 (4k 词元),以及利用了分组查询注意力机制来加速 70B模型的推理!

但最激动人心的还是其发布的微调模型 (Llama 2-Chat),该模型已使用基于人类反馈的强化学习 (RLHF) 技术针对对话场景进行了优化。在相当广泛的有用性和安全性测试基准中,Llama 2-Chat 模型的表现优于大多数开放模型,且其在人类评估中表现出与ChatGPT相当的性能。最最最激动人心的是Llama 2已经开源,且可以进行商用。
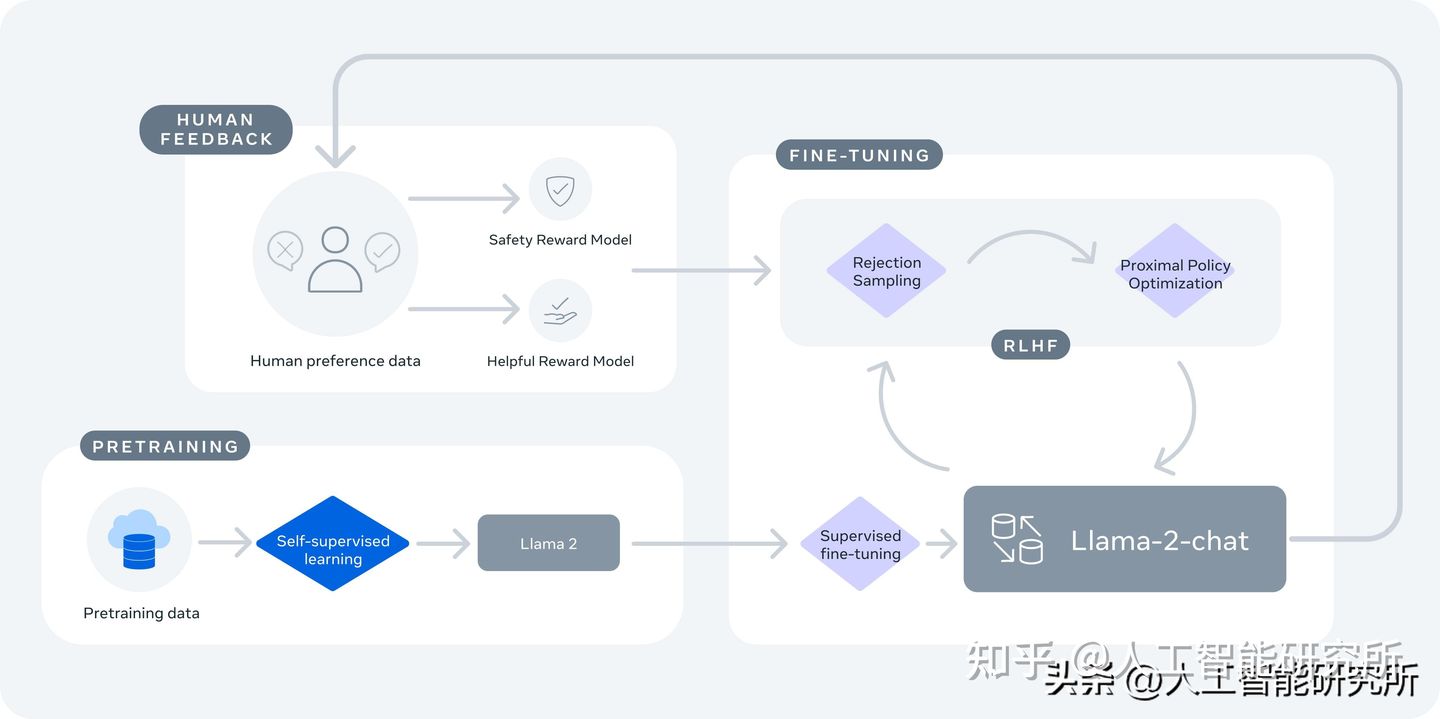
此模型首先使用公开的在线数据对Llama 2进行预训练。 然后通过应用监督微调创建Llama 2-Chat的初始版本。 随后,使用人类反馈强化学习 (RLHF) 方法,特别是通过拒绝采样和近端策略优化 (PPO) 来迭代完善模型。