前言
数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它出于分析性报告和决策支持的目的而创建的。
数据仓库是一个数据集合
数据仓库是一个为业务决策提供数据支持的数据集合
数据仓库是通过监控业务流程的形式为业务决策提供数据支持的数据集合
主要有以下特征:
面向主题的(Subject-Oriented )
数据仓库是面向主题的,数据仓库通过一个个主题域将多个业务系统的数据加载到一起,为了各个主题(如:用户、订单、商品等)进行分析而建,操作型数据库是为了支撑各种业务而建立。
集成的(Integrated)
数据仓库会将不同源数据库中的数据汇总到一起,数据仓库中的综合数据不能从原有的数据库系统直接得到。因此在数据进入数据仓库之前,必然要经过统一与整合,这一步是数据仓库建设中最关键、最复杂的一步(ETL),要统一源数据中所有矛盾之处,如字段的同名异义、异名同义、单位不统一、字长不一致,等等。
稳定性(Non-Volatile)
操作型数据库主要服务于日常的业务操作,使得数据库需要不断地对数据实时更新,以便迅速获得当前最新数据,不至于影响正常的业务运作。
反应历史变化的 (Time-Variant )
数据仓库包含各种粒度的历史数据。数据仓库中的数据可能与某个特定日期、星期、月份、季度或者年份有关。数据仓库的目的是通过分析企业过去一段时间业务的经营状况,挖掘其中隐藏的模式。虽然数据仓库的用户不能修改数据,但并不是说数据仓库的数据是永远不变的。分析的结果只能反映过去的情况,当业务变化后,挖掘出的模式会失去时效性。因此数据仓库的数据需要定时更新,以适应决策的需要。
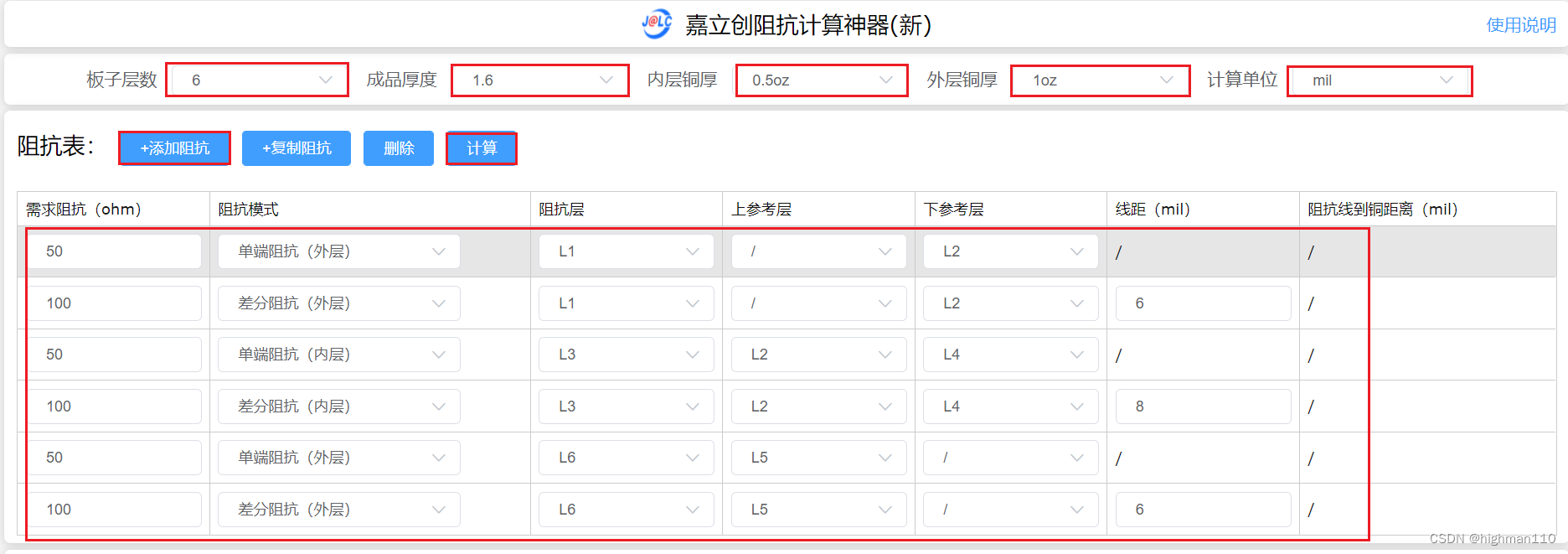
数仓的层级设计
为了更好的管理代码。与(Controller-Service-DAO)相似。它也根据处理方式不同进行分层。
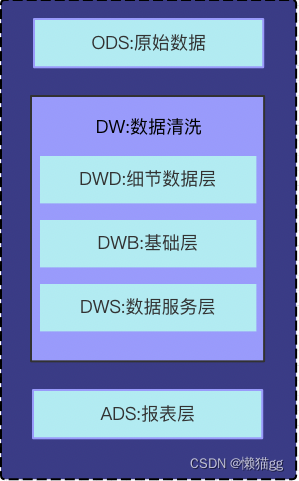
- ODS:Operation Data Store 数据准备区,也称为贴源层。数据仓库源头系统的数据表通常会原封不动的存储一份,这称为ODS层,是后续数据仓库加工数据的来源。
- DWD:data warehouse details 细节数据层,是业务层与数据仓库的隔离层。主要对ODS数据层做一些数据清洗和规范化的操作。数据清洗:去除空值、脏数据、超过极限范围的
- DWB:data warehouse base 数据基础层,存储的是客观数据,一般用作中间层,可以认为是大量指标的数据层。
- DWS:data warehouse service 数据服务层,基于DWB上的基础数据,整合汇总成分析某一个主题域的服务数据层,一般是宽表。用于提供后续的业务查询,OLAP分析,数据分发等。
用户行为,轻度聚合 - ADS:applicationData Service应用数据服务,该层主要是提供数据产品和数据分析使用的数据,一般会存储在ES、mysql等系统中供线上系统使用。
数仓技术架构
基于数仓的定义,你可以用任何数据库来完成它,甚至可以用存储过程。
Lambda架构

Lambda架构的核心理念是“流批分离”,如上图所示,整个数据流向自左向右流入平台。进入平台后一分为二,一部分走批处理模式,一部分走流式计算模式。无论哪种计算模式,最终的处理结果都通过服务层对应用提供,确保访问的一致性。
Kappa架构

Kappa架构的方案也被称为“批流一体化”方案。我们借用Flink+Kafka来构建流批一体化场景,当需要对ODS层数据做进一步的分析时,将Flink计算结果的DWD层写入到Kafka,同样也会将一部分DWS层的计算结果Kafka。
Lambda VS Kappa
| 功能 | Lambda | Kappa |
|---|---|---|
| 实时性 | 实时 | 实时 |
| 计算资源 | 两套架,资源较大 | 只有流处理,相对较小 |
| 重新计算 | 全量批处理,吞吐量大 | 全量,流处理吞吐量相对较小 |
| 开发&运维 | 两套系统,两套代码 | 一系统,一套代码 |
| 分析能力 | 通过SQL能干一切, 灵活性十足 | 不怎么方便 |
在真实的场景中,很多时候并不是完全规范的Lambda架构或Kappa架构,可以是两者的混合,比如大部分实时指标使用Kappa架构完成计算,少量关键指标(比如金额相关)使用Lambda架构用批处理重新计算,增加一次校对过程。
Fink在数仓的应用


历史方案
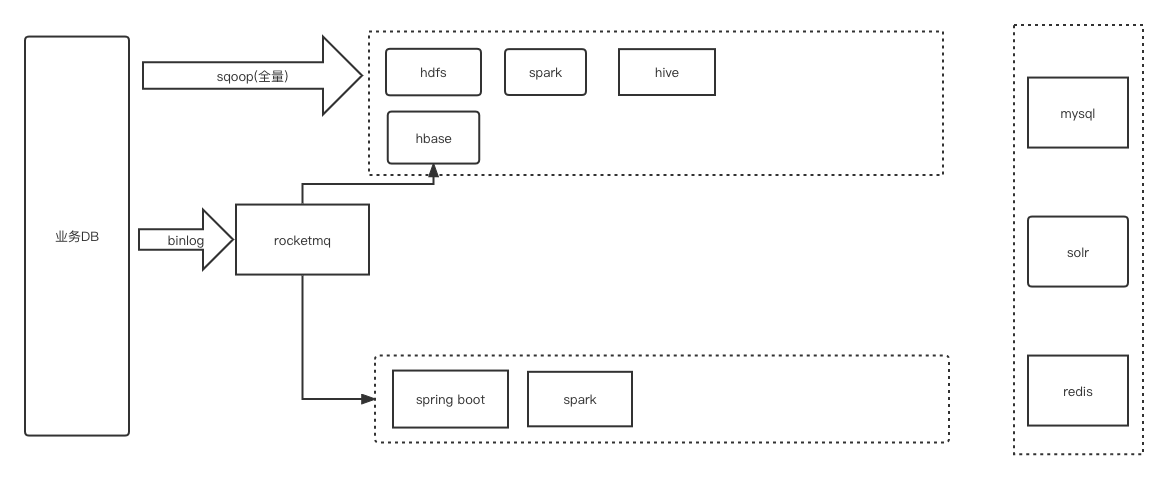
- 利用hbase管理小文件问题,将离线任务管理范围(T+1)增加到(h+1)
- 实时使用rocketmq的消费者消费,更加轻量节省成功
- 实时与离线的数据一致性问题,最终以离线的为主
使用dataworks
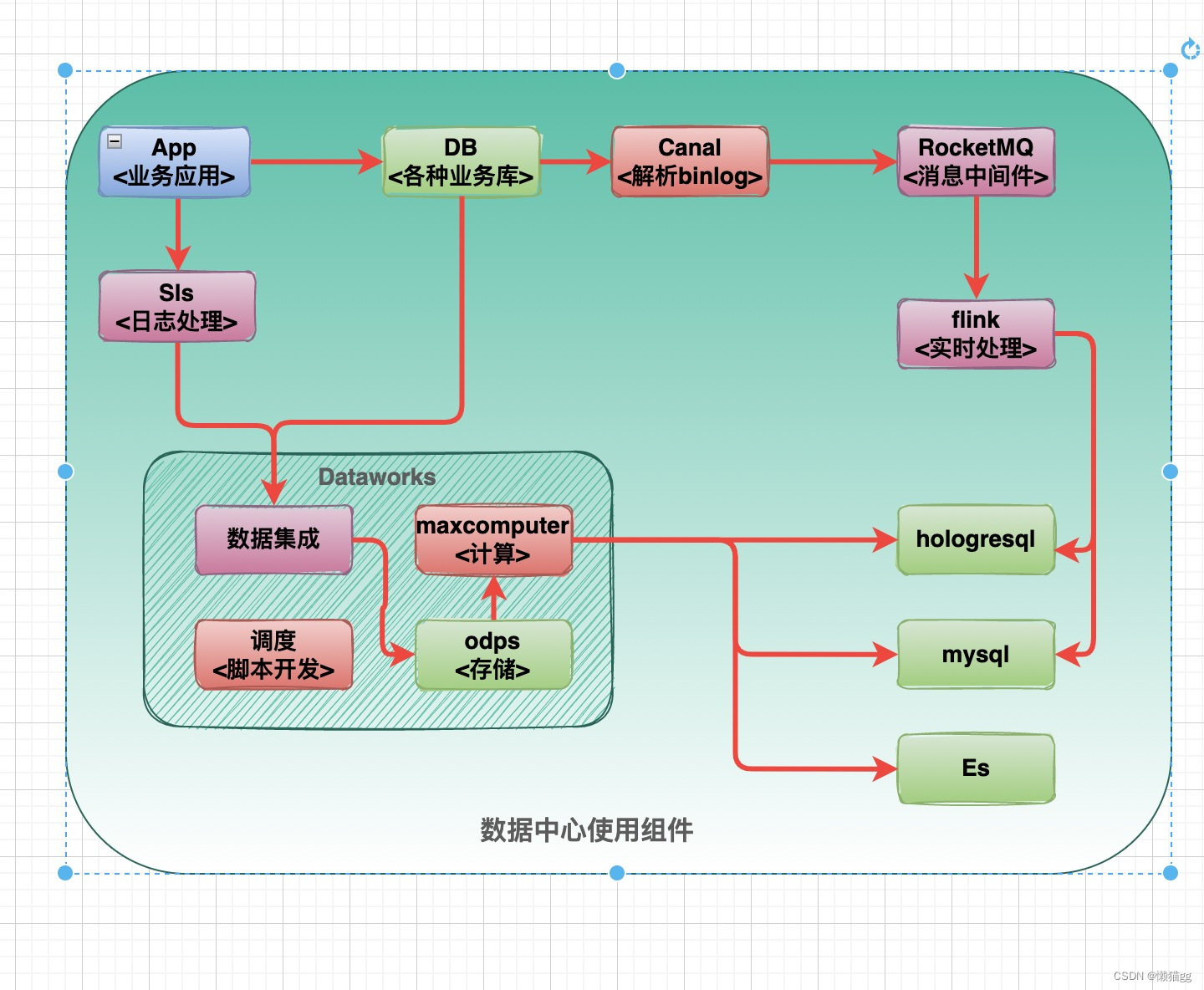
使用dataworks成本大大减少:
- 没上云,要30台32c128g的ECS, 月成功约为15W 左右(不加其它的)
- 使用dataworks分为4个部份
| 功能 | 说明 | 金额 |
|---|---|---|
| 调度 | 4台普通8c16G ECS | 5000 |
| 计算 | 150/核, 200个 | 30000 |
| 存储 | 0.004元/GB/天 | 10000 |
| 平台使用费用 | 脚本编辑,数据源管理等待功能 | 5000 |
总结:便宜多了
数据湖
Lambda 与 Kappa 架构 本质是数据层的统一问题。
- hdfs不支持数据更新,无法很好的实时;
- kafka 不篮球olap分析,回溯及全量同步的吞吐量(成本)
如果现在有这么一个数据库:

数据湖的需求,就这么产生了。
数据湖理念
数据湖是一个集中式存储库,可以存储结构化和非结构化数据。可以按业务数据的原样存储(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。

Hudi支持三种不同的查询表的方式:
- Snapshot Queries(快照查询):
动态合并最新的基本文件(parquet)和增量文件(Avro)来提供近实时数据集- Copy On Write表读parquet文件,
- Merge On Read表读parquet + log文件。
- Incremental Queries(增量查询)
仅查询新写入数据集的文件,需要指定一个Commit/Compaction的即时时间(位于Timeline上的某个instant)作为条件,来查询此条件之后的新数据 - Read Optimized Queries(读优化查询)
直接查询基本文件(数据集的最新快照),其实就是列式文件(Parquet)。
- 支持多数数据格式,以及hdfs 小文件问题解决
- 增量查询 功能很容易的对接fink实现