文章目录
- Kaggle狗图像分类实战
- d2l安装问题
- python语法学习
- os.path.join
- d2l
- 数据加载
- streamlit
Kaggle狗图像分类实战
d2l安装问题
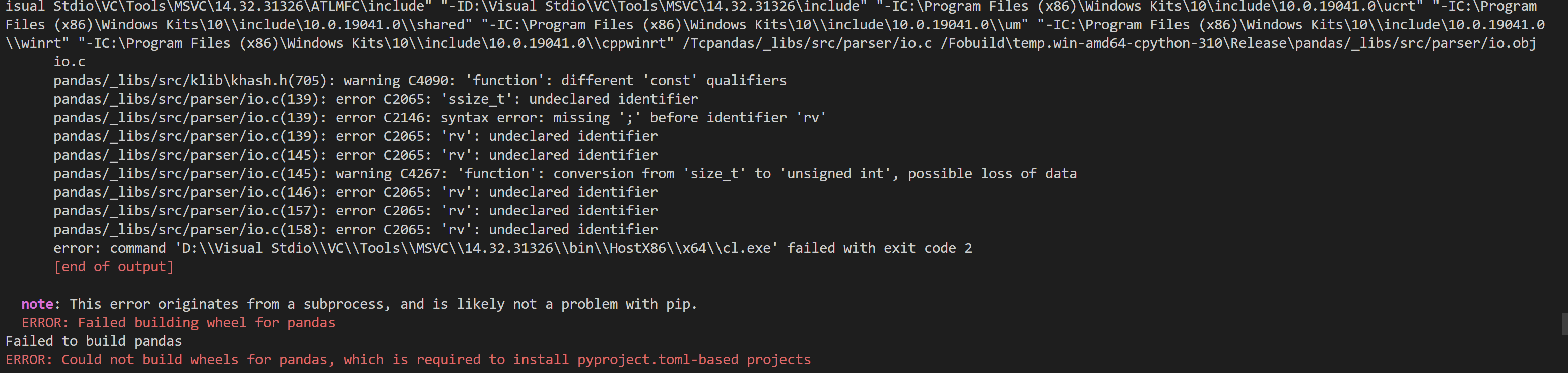 d2l安装失败,报错如上图
d2l安装失败,报错如上图
去下面的网站下载到该项目文件目录下再pip install即可
Python d2l项目安装包(第三方库)下载详情页面 - PyPI - Python中文网 (cnpython.com)
python语法学习
os.path.join
os.path.join(data_dir, 'labels.csv')
具体来说,如果 data_dir 是 'data',那么 os.path.join(data_dir, 'labels.csv') 将返回 'data/labels.csv'。这里使用 '/' 作为路径分隔符
d2l
理解下面两行代码的作用
d2l.reorg_train_valid(data_dir, labels, valid_ratio)
d2l.reorg_test(data_dir)
我把data文件夹里面的所有的文件夹删了,然后把图像放在data文件夹下
报如下错误

说明了reorg_train_valid要去train文件夹下找的
所以我新建了一个train文件夹,把图像放进去
继续报错
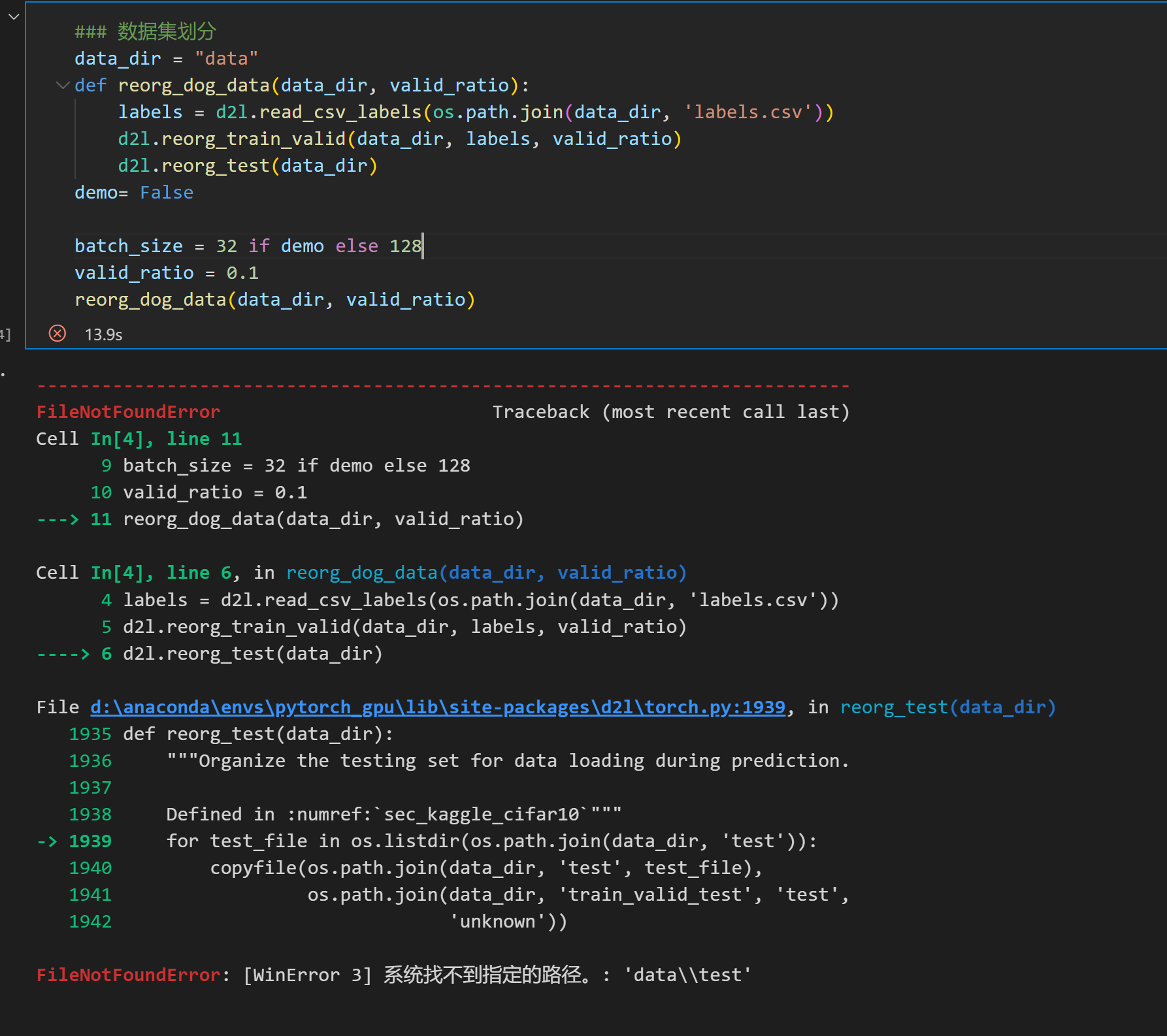
现在是d2l.reorg_test(data_dir)这一行有误,说明d2l.reorg_train_valid(data_dir, labels, valid_ratio)运行成功
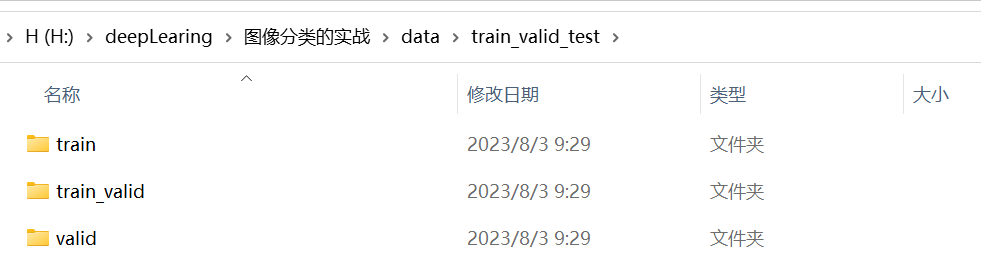
果然发现data下面多了train_vaild_test文件夹,里面分了三个文件夹。
然后新建了一个test文件夹,运行成功
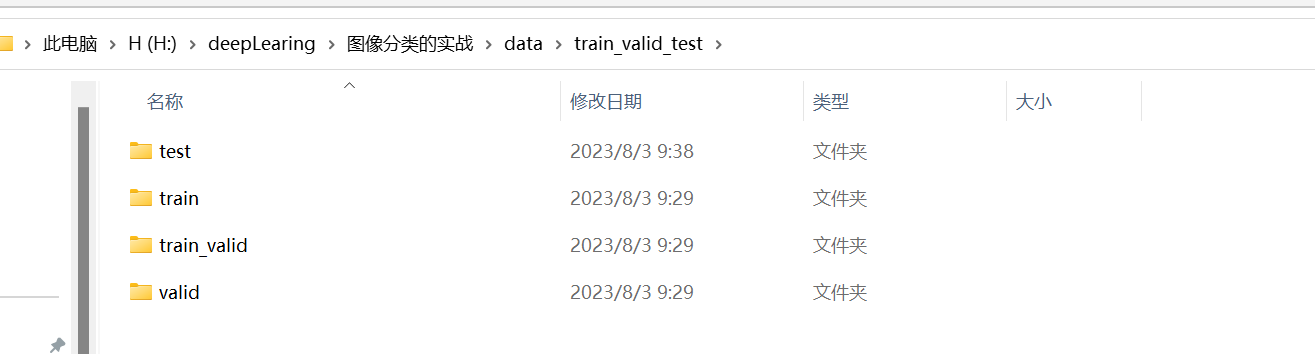
发现在train_vaild_test文件夹中多了test文件夹
数据加载
使用ImageFlolder加载数据集中的图像,并使用指定的预处理操作来处理图像
train_dataset = datasets.ImageFolder(root=os.path.join("data/train_valid_test", "train"), transform=data_transform["train"])
validate_dataset = datasets.ImageFolder(root=os.path.join("data/train_valid_test", "valid"), transform=data_transform["val"])
使用 DataLoader 将 ImageFloder 加载的数据集处理成批量(batch)加载模式
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)
validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=4, shuffle=False, num_workers=num_workers)
streamlit
运行代码:streamlit run streamlit界面.py