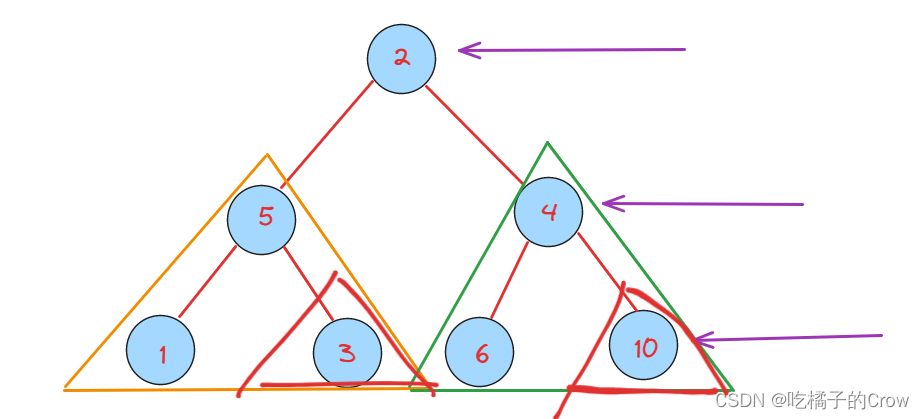
给定一个二叉树的 根节点
root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。

树这类问题用的最多的就是递归,因为树具有天然的递归结构:

我们来分析一下题目,给定一棵树根结点,求出每层的最右边的结点,是不是我们可以换个角度想,是不是相当于求树每层的最右边的结点,将一整棵树分成一层一层的进行看待,这是不是与我们学过的树的层序遍历有关,来我们开始写代码:
因为我们既要关注结点的值,还要关注结点的所在的层数,一般碰到我们需要关注的该物体的属性在2个或者2个以上时,这时候我们就需要手动的去创建一个Piar对,对其进行封装
public class pair{
private TreeNode node;
private Integer level;
public pair(TreeNode node,Integer level){
this.level=level;
this.node=node;
}
}树的层序遍历是通过BFS实现的,实现的数据结构肯定不能少
Queue<pair> queue=new LinkedList<>();因为我们需要返回一个List<Integer>,题目让返回什么,我们就先给它创建什么
List<List<Integer>> list=new ArrayList<>();
List<Integer> path=new ArrayList<>();然后就开始套用BFS模板进行解答
queue.add(start);
while(!queue.isEmpty()){
int val=queue.poll();
...
if(node.left!=null){
queue.add(...);
}
if(node.right!=null){
queue.add(...);
}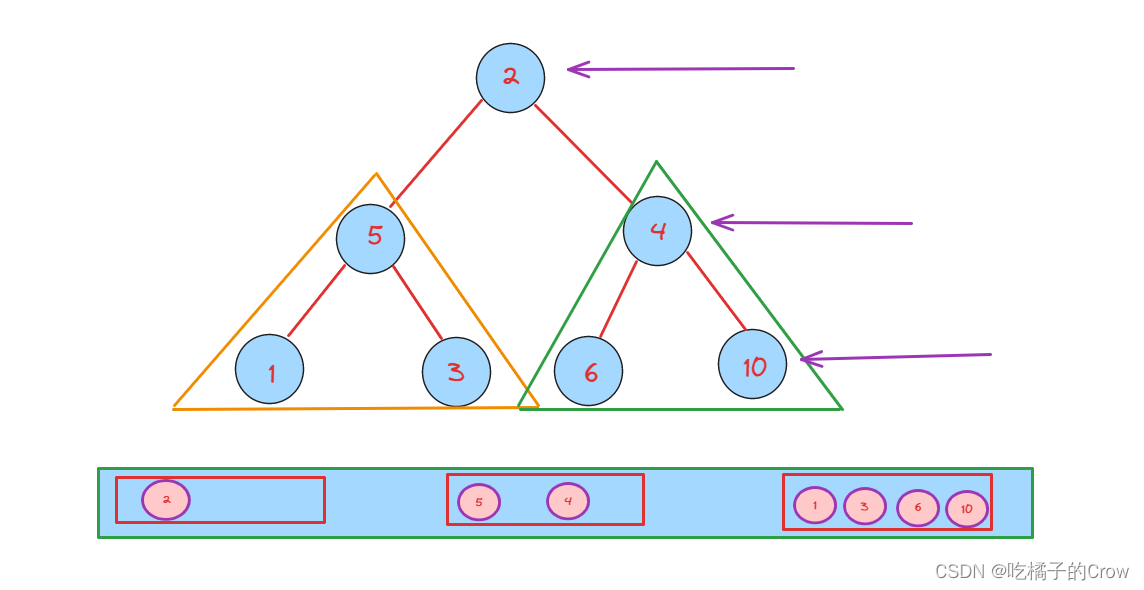
通过BFS遍历之后,我们就会得到一个类似于这样的存储结点的链表,是不是我们所需要的是每个链表中的最后一个元素,我们将每个小链表拿出来,将每个中最后一个元素取出放到一个新的链表中,那么这个新的链表不就是我们想要求的最终列表链表么?

List<Integer> result=new ArrayList<>(list.size());
for (List<Integer> item:list) {
result.add(item.get(item.size()-1));
}第一种方法的源码:
public List<Integer> rightSideView(TreeNode root) {
List<List<Integer>> list=new ArrayList<>();
List<Integer> path=new ArrayList<>();
if(root==null){
return path;
}
Queue<pair> queue=new LinkedList<>();
queue.add(new pair(root,0));
while(!queue.isEmpty()){
pair pair=queue.poll();
TreeNode node=pair.node;
Integer level=pair.level;
if(list.size()==level){
list.add(new ArrayList<>());
}
List<Integer> list2=list.get(level);
list2.add(node.val);
if(node.left!=null){
queue.add(new pair(node.left,level+1));
}
if(node.right!=null){
queue.add(new pair(node.right,level+1));
}
}
List<Integer> result=new ArrayList<>(list.size());
for (List<Integer> item:list) {
result.add(item.get(item.size()-1));
}
return result;
}
public class pair{
private TreeNode node;
private Integer level;
public pair(TreeNode node,Integer level){
this.level=level;
this.node=node;
}
}这样一来我们这道题的解决完了,下面给大家提供一种新的思路(递归)
因为树是天然的递归结构,每层的最右边的结点是不是一般在某棵数的右子树(存在的时候)中,所以我们可以先递归右子树、后递归左子树
DG(root.right);
DG(root.left);我们怎么才能获得最右边的节点呢?这样是不是和我们刚才讲的思路相差不多,树的高度,我们可以在递归的时候将树的高度当做参数传下去,然后我们就可以写成:
private void DG(TreeNode root, int depth) {
DG(root.right,depth+1);
DG(root.left,depth+1);
}递归的两要素:递归结束条件+递归操作
那么是不是当我们这个结点为空时,直接return出去就好了
if(root==null){
return;
}我们还应该声明一个容器去存储我们得到的结果,直接看源代码:
List<Integer> list=new ArrayList<>();
public List<Integer> rightSideView(TreeNode root) {
if(root==null){
return list;
}
DG(root,0);
return list;
}
private void DG(TreeNode root, int depth) {
if(root==null){
return;
}
if(depth==list.size()){
list.add(root.val);
}
DG(root.right,depth+1);
DG(root.left,depth+1);
}这里一定有人回问?这里为什么是当depth==list.size()的时候,会将这个结点加入list中去,这种问题对于读递归不是很熟的东西确实是比较难以捉摸的,原因是这样的,因为我们在递归的时候是优先递归的是右子树,后递归的左子树,所以每次都是每层的最右边的那个节点优先到达的这层,所以才往我们的结果集中加入当前节点,所以才会这么写