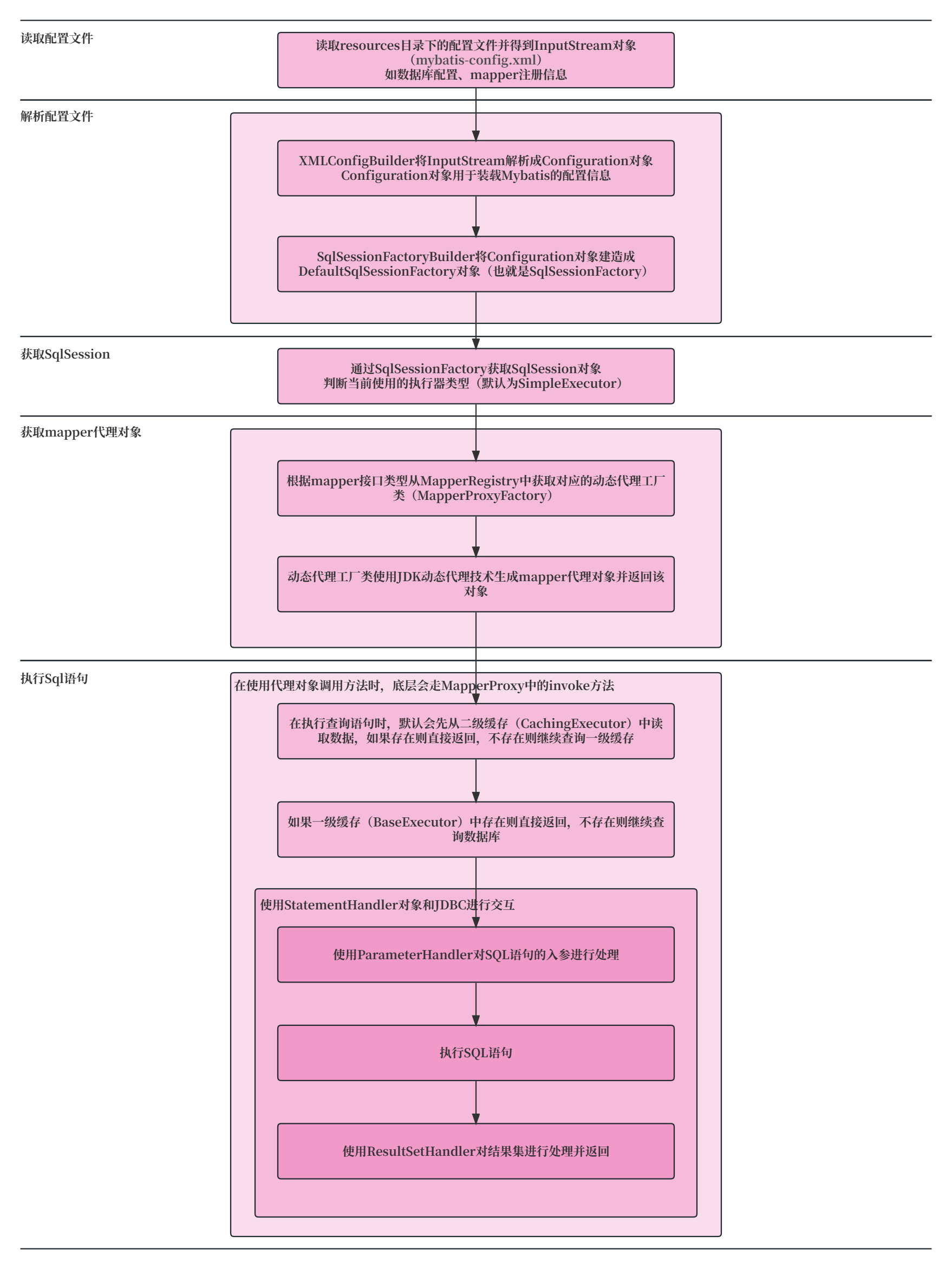
Relu介绍:
relu是一个非线性激活函数,可以避免梯度消失,过拟合等情况。我们一般将thresh设为0。
operator类:
#ifndef KUIPER_COURSE_INCLUDE_OPS_OP_HPP_
#define KUIPER_COURSE_INCLUDE_OPS_OP_HPP_
namespace kuiper_infer {
enum class OpType {
kOperatorUnknown = -1,
kOperatorRelu = 0,
};
class Operator {
public:
OpType op_type_ = OpType::kOperatorUnknown; //不是一个具体节点 制定为unknown
virtual ~Operator() = default; //
explicit Operator(OpType op_type);
};
这里的 kOperatorUnknown = -1 , kOperatorRelu = 0分别是他们的代号
operator是一个父类,我们的relu就要继承于这个父类
class ReluOperator : public Operator {
public:
~ReluOperator() override = default;
explicit ReluOperator(float thresh);
void set_thresh(float thresh);
float get_thresh() const;
private:
// 需要传递到reluLayer中,怎么传递?
float thresh_ = 0.f; // 用于过滤tensor<float>值当中大于thresh的部分
// relu存的变量只有thresh
// stride padding kernel_size 这些是到时候convOperator需要的
// operator起到了属性存储、变量的作用
// operator所有子类不负责具体运算
// 具体运算由另外一个类Layer类负责
// y =x , if x >=0 y = 0 if x < 0
};operator起到了属性存储、变量的作用
operator所有子类不负责具体运算
具体运算由另外一个类Layer类负责
layer类:
class Layer {
public:
explicit Layer(const std::string &layer_name);
virtual void Forwards(const std::vector<std::shared_ptr<Tensor<float>>> &inputs,
std::vector<std::shared_ptr<Tensor<float>>> &outputs);
// reluLayer中 inputs 等于 x , outputs 等于 y= x,if x>0
// 计算得到的结果放在y当中,x是输入,放在inputs中
virtual ~Layer() = default;
private:
std::string layer_name_; //relu layer "relu"
};父类只保留了一个layer_name属性和两个方法。
具体的在relu_layer这个class中
class ReluLayer : public Layer {
public:
~ReluLayer() override = default;
// 通过这里,把relu_op中的thresh告知给relu layer, 因为计算的时候要用到
explicit ReluLayer(const std::shared_ptr<Operator> &op);
// 执行relu 操作的具体函数Forwards
void Forwards(const std::vector<std::shared_ptr<Tensor<float>>> &inputs,
std::vector<std::shared_ptr<Tensor<float>>> &outputs) override;
// 下节的内容,不用管
static std::shared_ptr<Layer> CreateInstance(const std::shared_ptr<Operator> &op);
private:
std::unique_ptr<ReluOperator> op_;
};具体的方法实现:
ReluLayer::ReluLayer(const std::shared_ptr<Operator> &op) : Layer("Relu") {
CHECK(op->op_type_ == OpType::kOperatorRelu) << "Operator has a wrong type: " << int(op->op_type_);
// dynamic_cast是什么意思? 就是判断一下op指针是不是指向一个relu_op类的指针
// 这边的op不是ReluOperator类型的指针,就报错
// 我们这里只接受ReluOperator类型的指针
// 父类指针必须指向子类ReluOperator类型的指针
// 为什么不讲构造函数设置为const std::shared_ptr<ReluOperator> &op?
// 为了接口统一,具体下节会说到
ReluOperator *relu_op = dynamic_cast<ReluOperator *>(op.get());
CHECK(relu_op != nullptr) << "Relu operator is empty";
// 一个op实例和一个layer 一一对应 这里relu op对一个relu layer
// 对应关系
this->op_ = std::make_unique<ReluOperator>(relu_op->get_thresh());
}
void ReluLayer::Forwards(const std::vector<std::shared_ptr<Tensor<float>>> &inputs,
std::vector<std::shared_ptr<Tensor<float>>> &outputs) {
// relu 操作在哪里,这里!
// 我需要该节点信息的时候 直接这么做
// 实行了属性存储和运算过程的分离!!!!!!!!!!!!!!!!!!!!!!!!
//x就是inputs y = outputs
CHECK(this->op_ != nullptr);
CHECK(this->op_->op_type_ == OpType::kOperatorRelu);
const uint32_t batch_size = inputs.size(); //一批x,放在vec当中,理解为batchsize数量的tensor,需要进行relu操作
for (int i = 0; i < batch_size; ++i) {
CHECK(!inputs.at(i)->empty());
const std::shared_ptr<Tensor<float>> &input_data = inputs.at(i); //取出批次当中的一个张量
//对张量中的每一个元素进行运算,进行relu运算
input_data->data().transform([&](float value) {
// 对张良中的没一个元素进行运算
// 从operator中得到存储的属性
float thresh = op_->get_thresh();
//x >= thresh
if (value >= thresh) {
return value; // return x
} else {
// x<= thresh return 0.f;
return 0.f;
}
});
// 把结果y放在outputs中
outputs.push_back(input_data);
}
}