前言
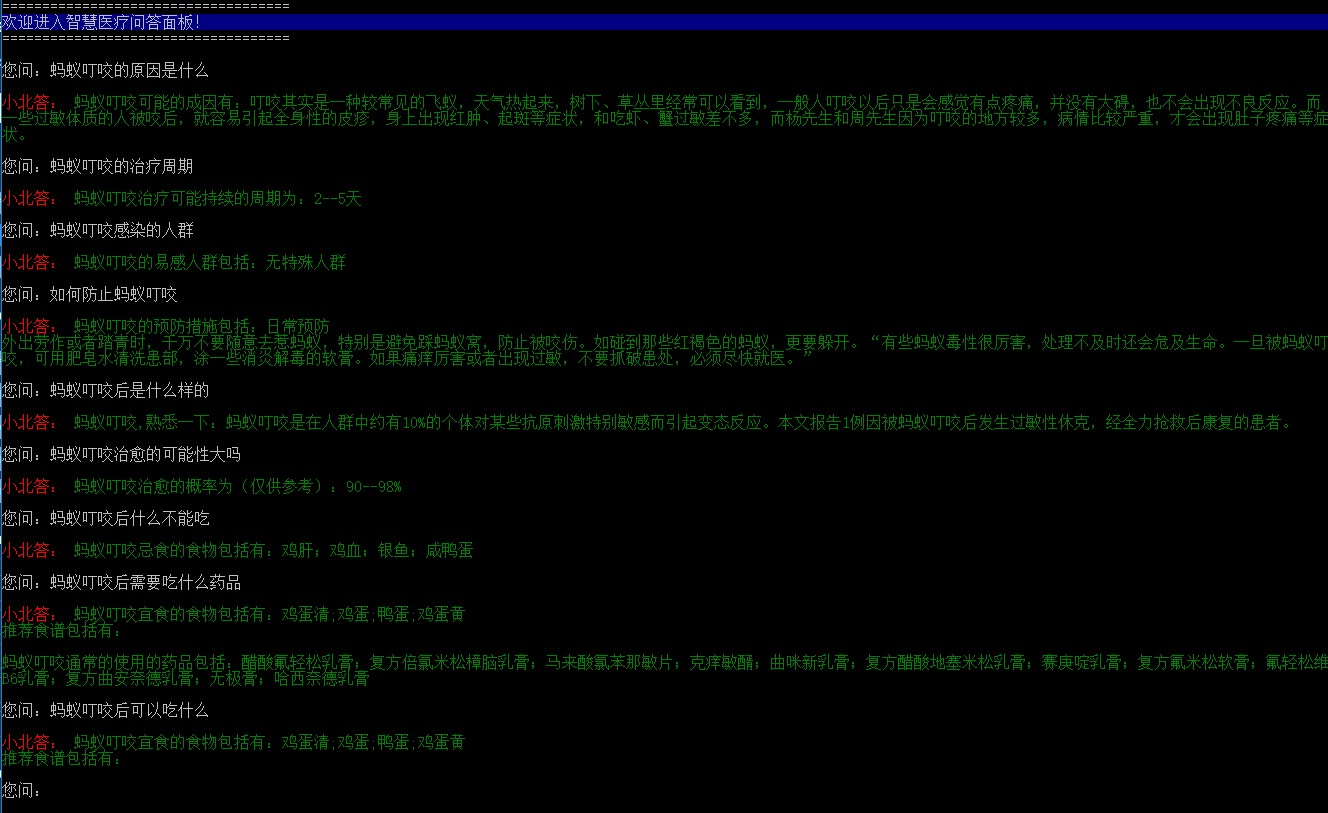
Neo4j的数据库构建完成后,现在就是要实现医疗知识的解答功能了。因为是初版,这里的问题解答不会涉及深度学习,目前只是一个条件查询的过程。而这个过程包括对问题的关键词拆解分类,然后提取词语和类型去图数据库查询,最后就是根据查询结果和问题类型组装语言完成回答,那么以下就是完成这个过程的全部代码流程了。
环境
这里所需的环境除了前面提到的外,还需要ahocorasick库,用于从问题中提取关键词。另一个是colorama,用于给输出面板文字美化的库。
编码
1. 问答面板
from colorama import init,Fore,Style,Back
from classifier import Classifier
from parse import Parse
from answer import Answer
class ChatRobot:
def __init__(self):
init(autoreset=True)
print("====================================")
print(Back.BLUE+"欢迎进入智慧医疗问答面板!")
print("====================================")
def main(self, question):
print("")
default_answer = "您好,小北知识有限,暂时回答不上来,正在努力迭代中!"
final_classify = Classifier().classify(question)
parse_sql = Parse().main(final_classify)
final_answer = Answer().main(parse_sql)
if not final_answer:
return default_answer
return "\n\n".join(final_answer)
if __name__ == "__main__":
robot = ChatRobot()
while 1:
print(" ")
question = input("您问:")
if "关闭" in question:
print("")
print("小北说:", "好的,已经关闭了哦,欢迎您下次提问~")
break;
answer = robot.main(question)
print(Fore.LIGHTRED_EX+"小北答:", Fore.GREEN + answer)2. 问题归类
import ahocorasick
class Classifier:
def __init__(self):
# print("开始初始化:", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
self.checks_wds = [i.strip() for i in open("dict/checks.txt", encoding="utf-8", mode="r") if i.strip()]
self.departments_wds = [i.strip() for i in open("dict/departments.txt", encoding="utf-8", mode="r") if i.strip()]
self.diseases_wds = [i.strip() for i in open("dict/diseases.txt", encoding="utf-8", mode="r") if i.strip()]
self.drugs_wds = [i.strip() for i in open("dict/drugs.txt", encoding="utf-8", mode="r") if i.strip()]
self.foods_wds = [i.strip() for i in open("dict/foods.txt", encoding="utf-8", mode="r") if i.strip()]
self.producers_wds = [i.strip() for i in open("dict/producers.txt", encoding="utf-8", mode="r") if i.strip()]
self.symptoms_wds = [i.strip() for i in open("dict/symptoms.txt", encoding="utf-8", mode="r") if i.strip()]
self.features_wds = set(self.checks_wds+self.departments_wds+self.diseases_wds+self.drugs_wds+self.foods_wds+self.producers_wds+self.symptoms_wds)
self.deny_words = [name.strip() for name in open("dict/deny.txt", encoding="utf-8", mode="r") if name.strip()]
# actree 从输入文本中提取出指定分词表中的词
self.actree = self.build_actree(list(self.features_wds))
# 给每个词创建类型词典(相当慢的操作)
self.wds_dict = self.build_words_dict()
# print("给每个词创建类型词典结束:", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
# 问句疑问词
self.symptom_qwds = ['症状', '表征', '现象', '症候', '表现']
self.cause_qwds = ['原因', '成因', '为什么', '怎么会', '怎样才', '咋样才', '怎样会', '如何会', '为啥', '为何', '如何才会', '怎么才会', '会导致',
'会造成']
self.acompany_qwds = ['并发症', '并发', '一起发生', '一并发生', '一起出现', '一并出现', '一同发生', '一同出现', '伴随发生', '伴随', '共现']
self.food_qwds = ['饮食', '饮用', '吃', '食', '伙食', '膳食', '喝', '菜', '忌口', '补品', '保健品', '食谱', '菜谱', '食用', '食物', '补品']
self.drug_qwds = ['药', '药品', '用药', '胶囊', '口服液', '炎片']
self.prevent_qwds = ['预防', '防范', '抵制', '抵御', '防止', '躲避', '逃避', '避开', '免得', '逃开', '避开', '避掉', '躲开', '躲掉', '绕开',
'怎样才能不', '怎么才能不', '咋样才能不', '咋才能不', '如何才能不',
'怎样才不', '怎么才不', '咋样才不', '咋才不', '如何才不',
'怎样才可以不', '怎么才可以不', '咋样才可以不', '咋才可以不', '如何可以不',
'怎样才可不', '怎么才可不', '咋样才可不', '咋才可不', '如何可不']
self.lasttime_qwds = ['周期', '多久', '多长时间', '多少时间', '几天', '几年', '多少天', '多少小时', '几个小时', '多少年']
self.cureway_qwds = ['怎么治疗', '如何医治', '怎么医治', '怎么治', '怎么医', '如何治', '医治方式', '疗法', '咋治', '怎么办', '咋办', '咋治']
self.cureprob_qwds = ['多大概率能治好', '多大几率能治好', '治好希望大么', '几率', '几成', '比例', '可能性', '能治', '可治', '可以治', '可以医']
self.easyget_qwds = ['易感人群', '容易感染', '易发人群', '什么人', '哪些人', '感染', '染上', '得上']
self.check_qwds = ['检查', '检查项目', '查出', '检查', '测出', '试出']
self.belong_qwds = ['属于什么科', '属于', '什么科', '科室']
self.cure_qwds = ['治疗什么', '治啥', '治疗啥', '医治啥', '治愈啥', '主治啥', '主治什么', '有什么用', '有何用', '用处', '用途',
'有什么好处', '有什么益处', '有何益处', '用来', '用来做啥', '用来作甚', '需要', '要']
'''构造actree,加速过滤'''
def build_actree(self, wordlist):
actree = ahocorasick.Automaton()
for index, word in enumerate(wordlist):
actree.add_word(word, (index, word))
actree.make_automaton()
return actree
# 构建特征词属性
def build_words_dict(self):
words_dict = {}
check_words = set(self.checks_wds)
department_words = set(self.departments_wds)
disease_words = set(self.diseases_wds)
drug_words = set(self.drugs_wds)
food_words = set(self.foods_wds)
producer_words = set(self.producers_wds)
symptom_words = set(self.symptoms_wds)
for word in self.features_wds:
words_dict[word] = []
if word in check_words:
words_dict[word].append("check")
if word in department_words:
words_dict[word].append("department")
if word in disease_words:
words_dict[word].append("disease")
if word in drug_words:
words_dict[word].append("drug")
if word in food_words:
words_dict[word].append("food")
if word in producer_words:
words_dict[word].append("producer")
if word in symptom_words:
words_dict[word].append("symptom")
return words_dict
# 根据输入返回问题类型
def classify(self, sent):
# 最终输入给解析器的字典
data = {}
region_words = []
lists = self.actree.iter(sent)
for ii in lists:
cur_word = ii[1][1]
region_words.append(cur_word)
# {'职业黑变病': ['diseases'], '倒睫': ['diseases', 'symptom']}
final_dict = {i_name: self.wds_dict.get(i_name) for i_name in region_words}
data['args'] = final_dict
question_type = "other"
questions_type = []
# ['diseases', 'diseases', 'symptom']
type = []
for i_type in final_dict.values():
type += i_type
# 判断type中是否有指定类型, 提出的问题是否包含指定的修饰词,给问题定类型
# 1. 如提问词是否出现状态词语,那就是问某种疾病会出现什么症状
if self.check_word_exist(self.symptom_qwds, sent) and ('disease' in type):
question_type = "disease_symptom"
questions_type.append(question_type)
# 根据症状问疾病
if self.check_word_exist(self.symptom_qwds, sent) and ('symptom' in type):
question_type = "symptom_disease"
questions_type.append(question_type)
# 原因
if self.check_word_exist(self.cause_qwds, sent) and ('disease' in type):
question_type = 'disease_cause'
questions_type.append(question_type)
# 并发症
if self.check_word_exist(self.acompany_qwds, sent) and ('disease' in type):
question_type = 'disease_acompany'
questions_type.append(question_type)
# 推荐食品
if self.check_word_exist(self.food_qwds, sent) and 'disease' in type:
deny_status = self.check_word_exist(self.deny_words, sent)
if deny_status:
question_type = 'disease_not_food'
else:
question_type = 'disease_do_food'
questions_type.append(question_type)
# 已知食物找疾病
if self.check_word_exist(self.food_qwds + self.cure_qwds, sent) and 'food' in type:
deny_status = self.check_word_exist(self.deny_words, sent)
if deny_status:
question_type = 'food_not_disease'
else:
question_type = 'food_do_disease'
questions_type.append(question_type)
# 推荐药品
if self.check_word_exist(self.drug_qwds, sent) and 'disease' in type:
question_type = 'disease_drug'
questions_type.append(question_type)
# 药品治啥病
if self.check_word_exist(self.cure_qwds, sent) and 'drug' in type:
question_type = 'drug_disease'
questions_type.append(question_type)
# 疾病接受检查项目
if self.check_word_exist(self.check_qwds, sent) and 'disease' in type:
question_type = 'disease_check'
questions_type.append(question_type)
# 已知检查项目查相应疾病
if self.check_word_exist(self.check_qwds + self.cure_qwds, sent) and 'check' in type:
question_type = 'check_disease'
questions_type.append(question_type)
# 症状防御
if self.check_word_exist(self.prevent_qwds, sent) and 'disease' in type:
question_type = 'disease_prevent'
questions_type.append(question_type)
# 疾病医疗周期
if self.check_word_exist(self.lasttime_qwds, sent) and 'disease' in type:
question_type = 'disease_lasttime'
questions_type.append(question_type)
# 疾病治疗方式
if self.check_word_exist(self.cureway_qwds, sent) and 'disease' in type:
question_type = 'disease_cureway'
questions_type.append(question_type)
# 疾病治愈可能性
if self.check_word_exist(self.cureprob_qwds, sent) and 'disease' in type:
question_type = 'disease_cureprob'
questions_type.append(question_type)
# 疾病易感染人群
if self.check_word_exist(self.easyget_qwds, sent) and 'disease' in type:
question_type = 'disease_easyget'
questions_type.append(question_type)
# 若没有查到相关的外部查询信息,那么则将该疾病的描述信息返回
if questions_type == [] and 'disease' in type:
questions_type = ['disease_desc']
# 若没有查到相关的外部查询信息,那么则将该疾病的描述信息返回
if questions_type == [] and 'symptom' in type:
questions_type = ['symptom_disease']
# 将多个分类结果进行合并处理,组装成一个字典
data['question_types'] = questions_type
return data
def check_word_exist(self, word_list, words):
for item in word_list:
if item in words:
return True
return False
3. 类型解析(查询组装)
class Parse:
def main(self, classify):
entity = classify['args']
questions_type = classify['question_types']
entity_dict = self.entity_transform(entity)
sqls = []
for question in questions_type:
sql_dict = {}
sql_dict["qustion_type"] = question
sql_dict["sql"] = []
sql = []
if question == 'disease_symptom':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'symptom_disease':
sql = self.sql_transfer(question, entity_dict.get('symptom'))
elif question == 'disease_cause':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'disease_acompany':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'disease_not_food':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'disease_do_food':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'food_not_disease':
sql = self.sql_transfer(question, entity_dict.get('food'))
elif question == 'food_do_disease':
sql = self.sql_transfer(question, entity_dict.get('food'))
elif question == 'disease_drug':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'drug_disease':
sql = self.sql_transfer(question, entity_dict.get('drug'))
elif question == 'disease_check':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'check_disease':
sql = self.sql_transfer(question, entity_dict.get('check'))
elif question == 'disease_prevent':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'disease_lasttime':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'disease_cureway':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'disease_cureprob':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'disease_easyget':
sql = self.sql_transfer(question, entity_dict.get('disease'))
elif question == 'disease_desc':
sql = self.sql_transfer(question, entity_dict.get('disease'))
if sql:
sql_dict['sql'] = sql
sqls.append(sql_dict)
return sqls
def sql_transfer(self, question_type, entities):
# 查询语句
sql = []
# 查询疾病的原因
if question_type == 'disease_cause':
sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.cause".format(i) for i in entities]
# 查询疾病的防御措施
elif question_type == 'disease_prevent':
sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.prevent".format(i) for i in entities]
# 查询疾病的持续时间
elif question_type == 'disease_lasttime':
sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.cure_lasttime".format(i) for i in entities]
# 查询疾病的治愈概率
elif question_type == 'disease_cureprob':
sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.cured_prob".format(i) for i in entities]
# 查询疾病的治疗方式
elif question_type == 'disease_cureway':
sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.cure_way".format(i) for i in entities]
# 查询疾病的易发人群
elif question_type == 'disease_easyget':
sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.easy_get".format(i) for i in entities]
# 查询疾病的相关介绍
elif question_type == 'disease_desc':
sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.desc".format(i) for i in entities]
# 查询疾病有哪些症状
elif question_type == 'disease_symptom':
sql = [
"MATCH (m:Diseases)-[r:has_symptoms]->(n:Symptoms) where m.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
# 查询症状会导致哪些疾病
elif question_type == 'symptom_disease':
sql = [
"MATCH (m:Diseases)-[r:has_symptoms]->(n:Symptoms) where n.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
# 查询疾病的并发症
elif question_type == 'disease_acompany':
sql1 = [
"MATCH (m:Diseases)-[r:acompany_with]->(n:Symptoms) where m.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
sql2 = [
"MATCH (m:Diseases)-[r:acompany_with]->(n:Symptoms) where n.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
sql = sql1 + sql2
# 查询疾病的忌口
elif question_type == 'disease_not_food':
sql = ["MATCH (m:Diseases)-[r:not_eat]->(n:Foods) where m.name = '{0}' return m.name, r.name, n.name".format(i)
for i in entities]
# 查询疾病建议吃的东西
elif question_type == 'disease_do_food':
sql1 = [
"MATCH (m:Diseases)-[r:do_eat]->(n:Foods) where m.name = '{0}' return m.name, r.name, n.name".format(i)
for i in entities]
sql2 = [
"MATCH (m:Diseases)-[r:recomment_eat]->(n:Foods) where m.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
sql = sql1 + sql2
# 已知忌口查疾病
elif question_type == 'food_not_disease':
sql = ["MATCH (m:Diseases)-[r:not_eat]->(n:Foods) where n.name = '{0}' return m.name, r.name, n.name".format(i)
for i in entities]
# 已知推荐查疾病
elif question_type == 'food_do_disease':
sql1 = [
"MATCH (m:Diseases)-[r:do_eat]->(n:Foods) where n.name = '{0}' return m.name, r.name, n.name".format(i)
for i in entities]
sql2 = [
"MATCH (m:Diseases)-[r:recomment_eat]->(n:Foods) where n.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
sql = sql1 + sql2
# 查询疾病常用药品-药品别名记得扩充
elif question_type == 'disease_drug':
sql1 = [
"MATCH (m:Diseases)-[r:common_drug]->(n:Drugs) where m.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
sql2 = [
"MATCH (m:Diseases)-[r:recommand_drug]->(n:Drugs) where m.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
sql = sql1 + sql2
# 已知药品查询能够治疗的疾病
elif question_type == 'drug_disease':
sql1 = [
"MATCH (m:Diseases)-[r:common_drug]->(n:Drugs) where n.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
sql2 = [
"MATCH (m:Diseases)-[r:recommand_drug]->(n:Drugs) where n.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
sql = sql1 + sql2
# 查询疾病应该进行的检查
elif question_type == 'disease_check':
sql = [
"MATCH (m:Diseases)-[r:need_check]->(n:Checks) where m.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
# 已知检查查询疾病
elif question_type == 'check_disease':
sql = [
"MATCH (m:Diseases)-[r:need_check]->(n:Checks) where n.name = '{0}' return m.name, r.name, n.name".format(
i) for i in entities]
return sql
def entity_transform(self, entity):
entity_dict = {}
for args, types in entity.items():
for type in types:
if type in entity_dict:
entity_dict[type] = [args]
else:
entity_dict[type] = []
entity_dict[type].append(args)
return entity_dict4. 数据查询(回答组装)
from py2neo import Graph, Node
class Answer:
def __init__(self):
self.neo4j = Graph('bolt://localhost:7687', auth=('neo4j', 'beiqiaosu123456'))
self.num_limit = 20
def main(self, question_parse):
answers_final = []
for item in question_parse:
question_type = item['qustion_type']
sqls = item['sql']
answer = []
for sql in sqls:
data = self.neo4j.run(sql)
answer+=data.data()
final_answer = self.answer_prettify(question_type, answer)
if final_answer:
answers_final.append(final_answer)
return answers_final
'''根据对应的qustion_type,调用相应的回复模板'''
def answer_prettify(self, question_type, answers):
final_answer = []
if not answers:
return ''
if question_type == 'disease_symptom':
desc = [i['n.name'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}的症状包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'symptom_disease':
desc = [i['m.name'] for i in answers]
subject = answers[0]['n.name']
final_answer = '症状{0}可能染上的疾病有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_cause':
desc = [i['m.cause'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}可能的成因有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_prevent':
desc = [i['m.prevent'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}的预防措施包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_lasttime':
desc = [i['m.cure_lasttime'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}治疗可能持续的周期为:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_cureway':
desc = [';'.join(i['m.cure_way']) for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}可以尝试如下治疗:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_cureprob':
desc = [i['m.cured_prob'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}治愈的概率为(仅供参考):{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_easyget':
desc = [i['m.easy_get'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}的易感人群包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_desc':
desc = [i['m.desc'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0},熟悉一下:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_acompany':
desc1 = [i['n.name'] for i in answers]
desc2 = [i['m.name'] for i in answers]
subject = answers[0]['m.name']
desc = [i for i in desc1 + desc2 if i != subject]
final_answer = '{0}的症状包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_not_food':
desc = [i['n.name'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}忌食的食物包括有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_do_food':
do_desc = [i['n.name'] for i in answers if i['r.name'] == '可以吃']
recommand_desc = [i['n.name'] for i in answers if i['r.name'] == '推荐吃']
subject = answers[0]['m.name']
final_answer = '{0}宜食的食物包括有:{1}\n推荐食谱包括有:{2}'.format(subject, ';'.join(list(set(do_desc))[:self.num_limit]),
';'.join(list(set(recommand_desc))[:self.num_limit]))
elif question_type == 'food_not_disease':
desc = [i['m.name'] for i in answers]
subject = answers[0]['n.name']
final_answer = '患有{0}的人最好不要吃{1}'.format(';'.join(list(set(desc))[:self.num_limit]), subject)
elif question_type == 'food_do_disease':
desc = [i['m.name'] for i in answers]
subject = answers[0]['n.name']
final_answer = '患有{0}的人建议多试试{1}'.format(';'.join(list(set(desc))[:self.num_limit]), subject)
elif question_type == 'disease_drug':
desc = [i['n.name'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}通常的使用的药品包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'drug_disease':
desc = [i['m.name'] for i in answers]
subject = answers[0]['n.name']
final_answer = '{0}主治的疾病有{1},可以试试'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_check':
desc = [i['n.name'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}通常可以通过以下方式检查出来:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'check_disease':
desc = [i['m.name'] for i in answers]
subject = answers[0]['n.name']
final_answer = '通常可以通过{0}检查出来的疾病有{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
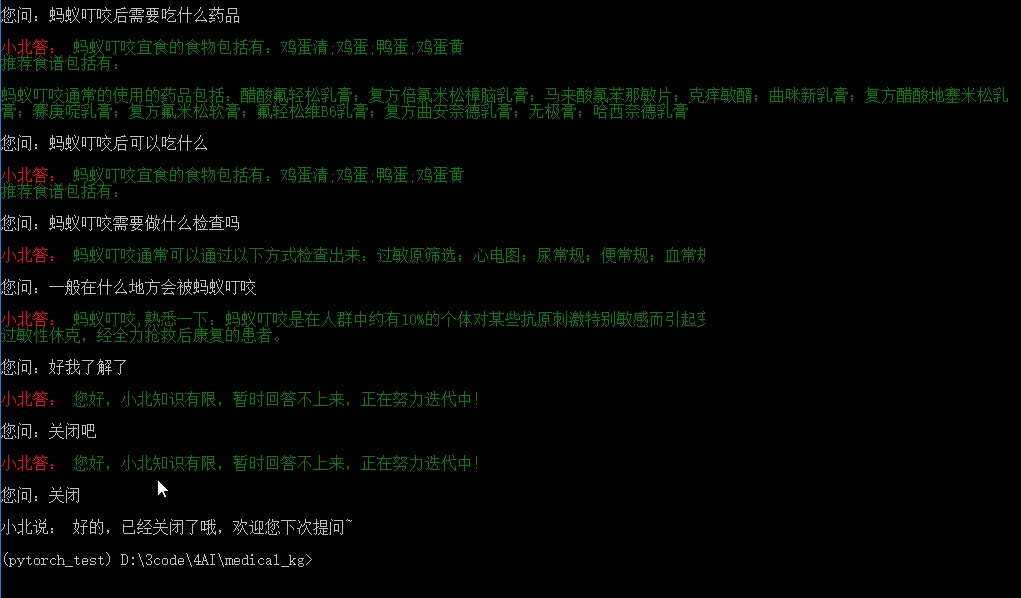
return final_answer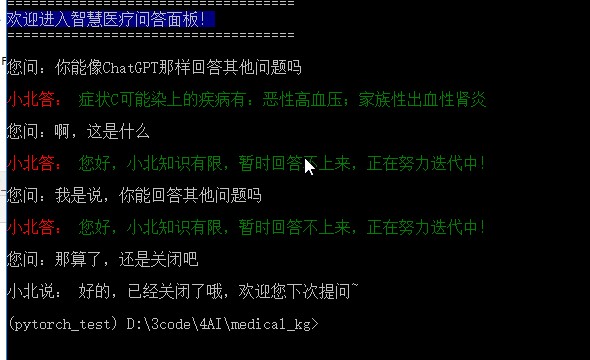
写在最后
以上就是这个医疗知识问答机器人的全部代码了,从上面的问答里也能看出,回答得还是很生硬。因为这就只是一个程序化得思维导图,所以修改完善空间还是很大,这个就要后期用深度学习得方式对分类解析部分进行改动。