目录
- 前言
- 一、介绍
- 二、使用方式
- 2-1、安装
- 2-2、代码调用: 使用如下代码时会自动下载模型。
- 2-3、本地加载
- 三、运行
- 总结
前言
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。一、介绍
ChatGLM-6B: 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用 户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答
二、使用方式
2-1、安装
# 克隆到本地
git clone https://github.com/THUDM/ChatGLM-6B.git
# 安装依赖,用一下镜像源。
pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple
# 如果需要在 cpu 上运行量化后的模型,还需要安装 gcc 与 openmp。多数 Linux 发行版默认已安装。
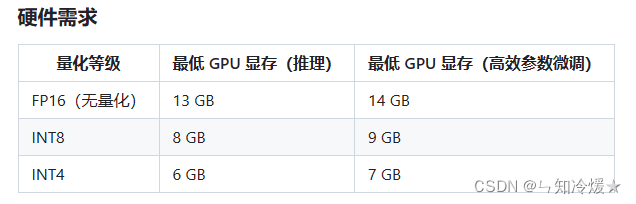
chatGLM运行的硬件需求:
2-2、代码调用: 使用如下代码时会自动下载模型。
GPU版本:
>>> from transformers import AutoTokenizer, AutoModel
>>> # 模型大小大约为13个G。
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
缺点:网络不好的时候,会下载很久,还会时不时的卡顿,稍有不慎就得重来。
CPU版本:
from transformers import AutoTokenizer, AutoModel
# 这里的路径是我自己下载的模型文件路径
# CPU的运行配置最低要求是8核32G。
tokenizer = AutoTokenizer.from_pretrained("/tmp/chatglm_model/", trust_remote_code=True)
model = AutoModel.from_pretrained("/tmp/chatglm_model/", trust_remote_code=True).float()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
Linux上的用例图:
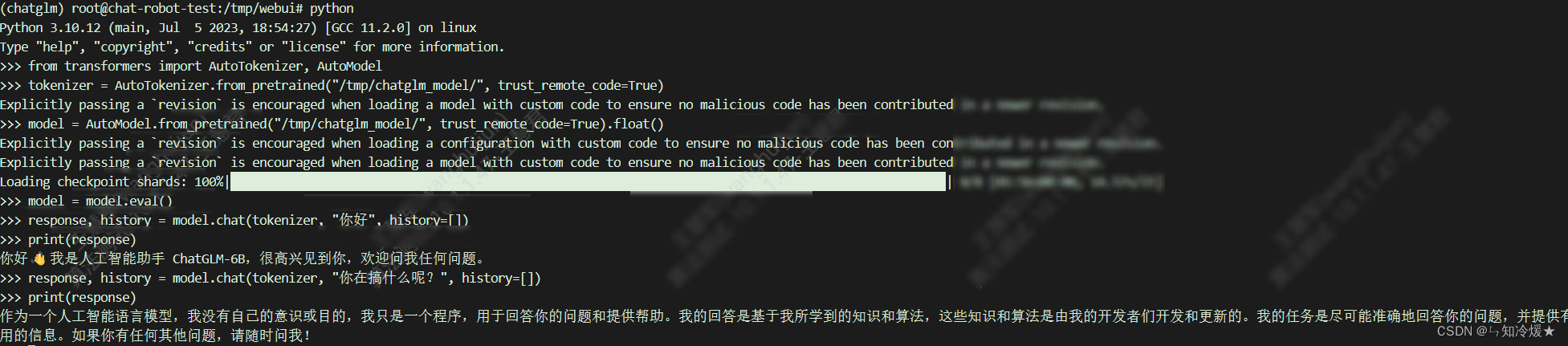
2-3、本地加载
本地加载:自动下载模型的过程中可能会遇到各种各样的错误导致下载终止,我们可以下载模型后在本地加载,模型文件默认加载到C:\Users\你的文件夹名称.cache\huggingface\hub\models–THUDM–chatglm-6b\snapshots下。
从Hugging Face上下载模型:注意要先安装LFS,否则会报错。
安装方式如下:
-
使用lscpu命令查看架构。
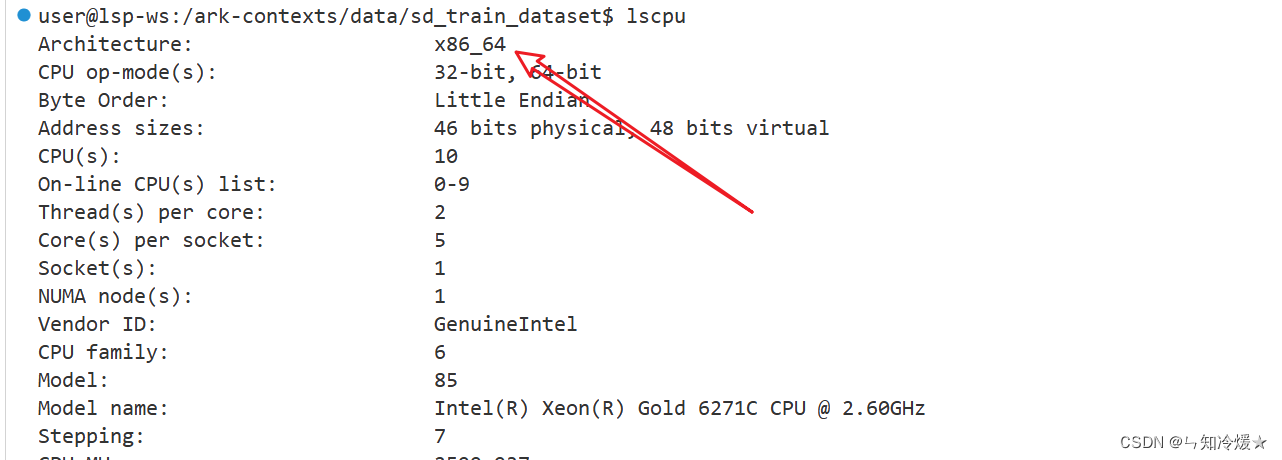
-
下载对应的版本https://github.com/git-lfs/git-lfs/releases,下拉找到对应版本。
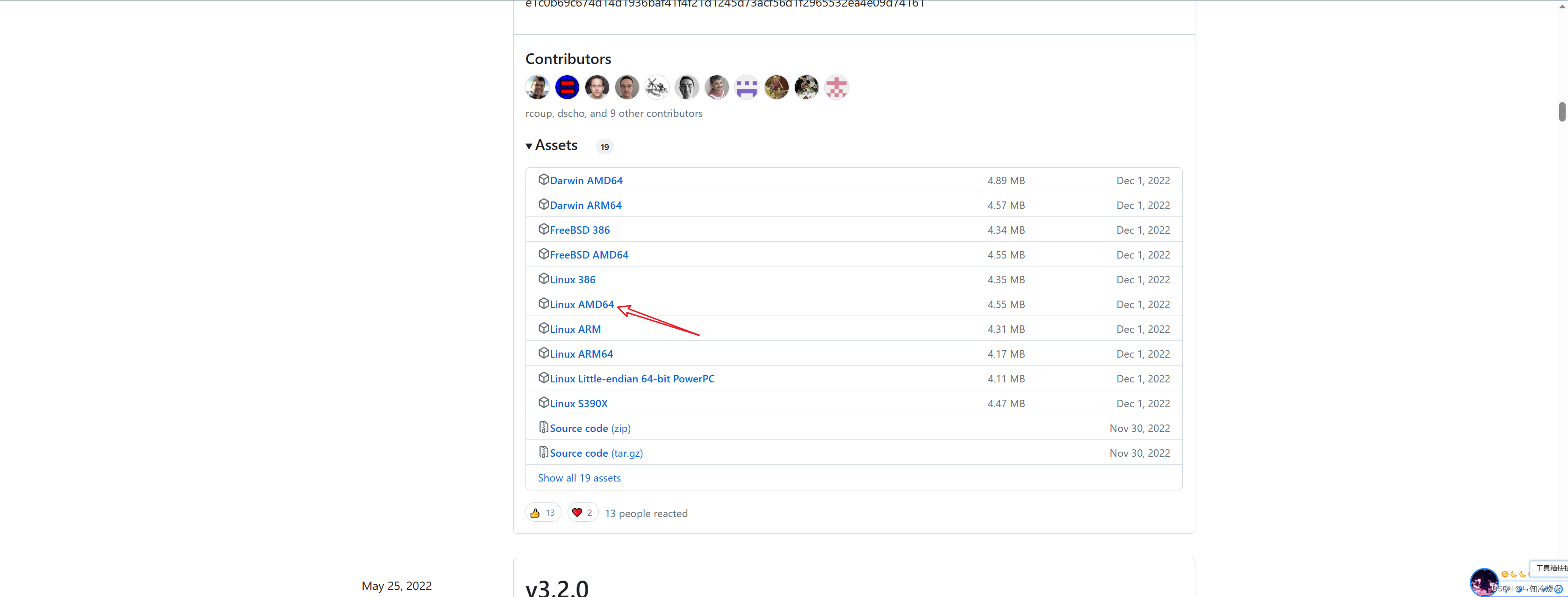
-
下载安装包后上传到服务器上并且进行解压(小文件直接拖拽上传即可,大文件需要在安装好lfs后再进行安装)
tar -zxvf git-lfs-linux-amd64-v2.9.0.tar.gz
- 解压后打开文件夹,使用命令执行安装文件
sudo ./install.sh
这种下载方式也存在一些问题,即会下载仓库中的所有文件,极大的延长模型下载的时间。
git clone https://huggingface.co/THUDM/chatglm-6b
Hugging Face上的模型配置文件如下所示:
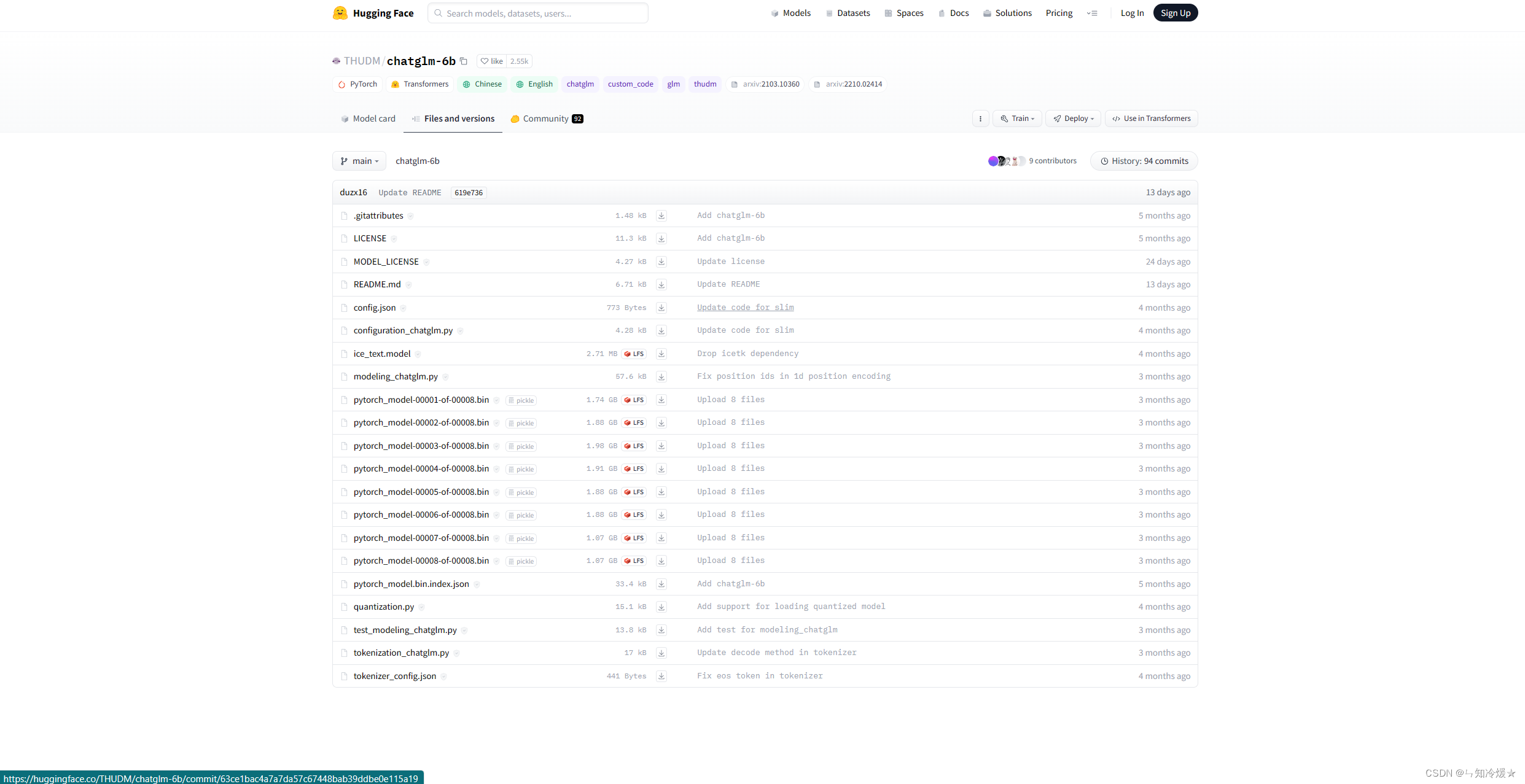
LAST: 如果采用了上述方式还是没有下载好模型,点击这里手动下载,并替换掉本地的目录。
Tips:还没下载好的话关注点赞收藏,私信我获取模型。
三、运行
运行:我们提供了一个基于 Gradio 的网页版 Demo 和一个命令行 Demo。使用时首先需要下载本仓库(上边已经下载完成)
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B
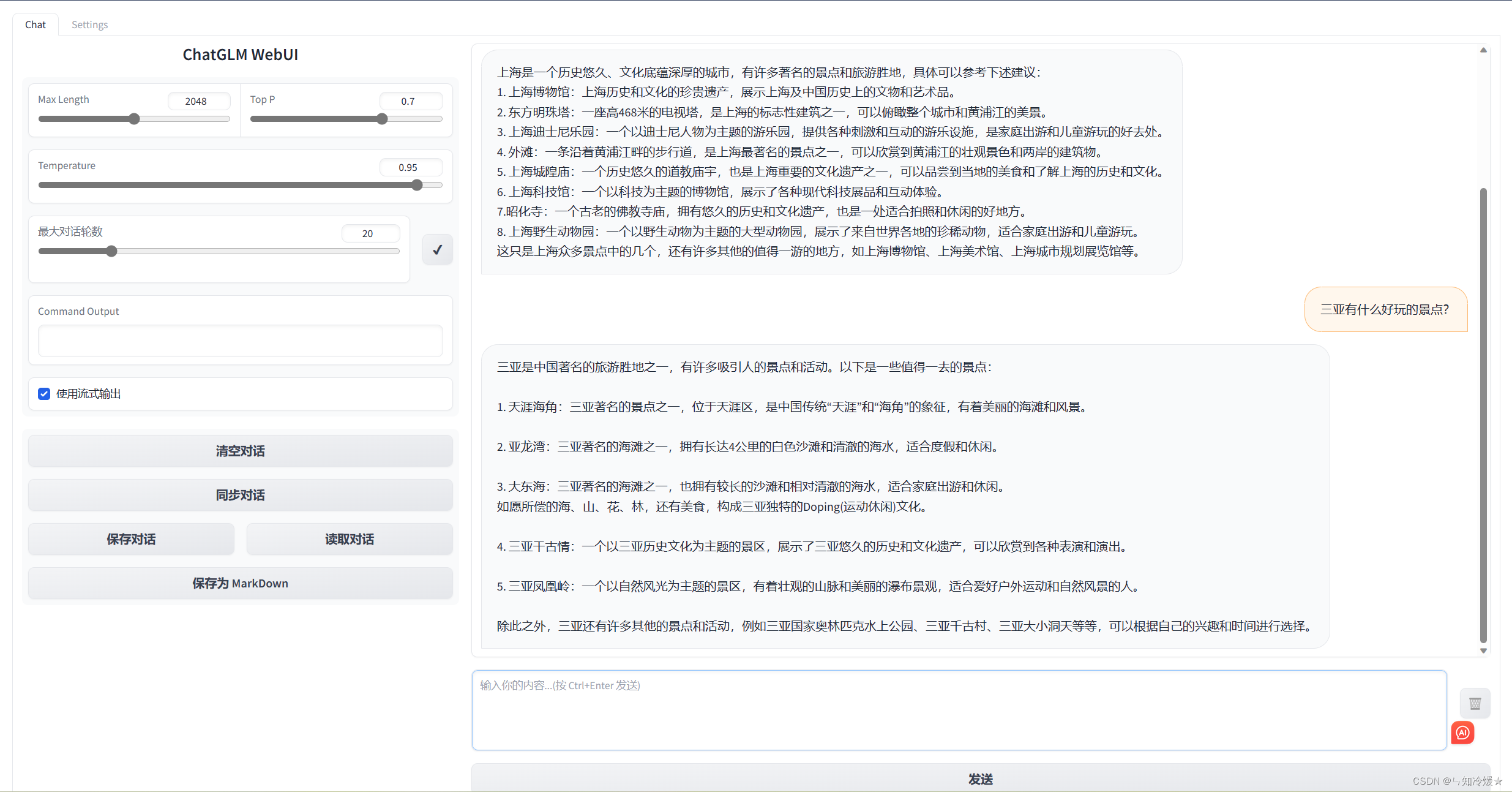
首先安装 Gradio:pip install gradio,然后运行仓库中的 web_demo.py:
python web_demo.py
参考文章:
ChatGLM-6B官方GitHub
VisualGLM: 一个支持图像理解的多模态对话语言模型
ChatGLM vs ChatGPT 的部分对比
如何优雅的下载huggingface-transformers模型
十分钟部署清华ChatGLM-6B,实测效果还可以~~(Linux版)
ChatGLM-6B 在 ModelWhale 平台的部署与微调教程
基于本地知识的 ChatGLM 应用实现
ChatGLM2-6B官方GitHub
Baichuan-13B-Chat
总结
吃了佩奇馅的包子。