链表是一种常见的基础数据结构,结构体指针在这里得到了充分的利用。链表可以动态的进行存储分配,也就是说,链表是一个功能极为强大的数组,他可以在节点中定义多种数据类型,还可以根据需要随意增添,删除,插入节点。链表都有一个头指针,一般以head来表示,存放的是一个地址。链表中的节点分为两类,头结点和一般节点,头结点是没有数据域的。链表中每个节点都分为两部分,一个数据域,一个是指针域。说到这里你应该就明白了,链表就如同车链子一样,head指向第一个元素:第一个元素又指向第二个元素;……,直到最后一个元素,该元素不再指向其它元素,它称为“表尾”,它的地址部分放一个“NULL”(表示“空地址”),链表到此结束。
作为有强大功能的链表,对他的操作当然有许多,比如:链表的创建,修改,删除,插入,输出,排序,反序,清空链表的元素,求链表的长度等等。

单链表的存储结构就像铁链一样
但是他们在物理地址上并不一定是相邻的
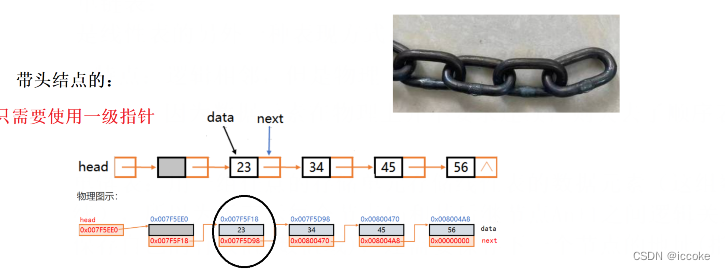
带头节点的就是有个头部,我们可以通过头部来对这个链表进行访问
而不带头结点的单链表我们就需要使用二级指针来访问这个单链表的
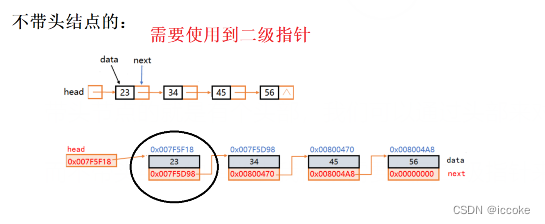
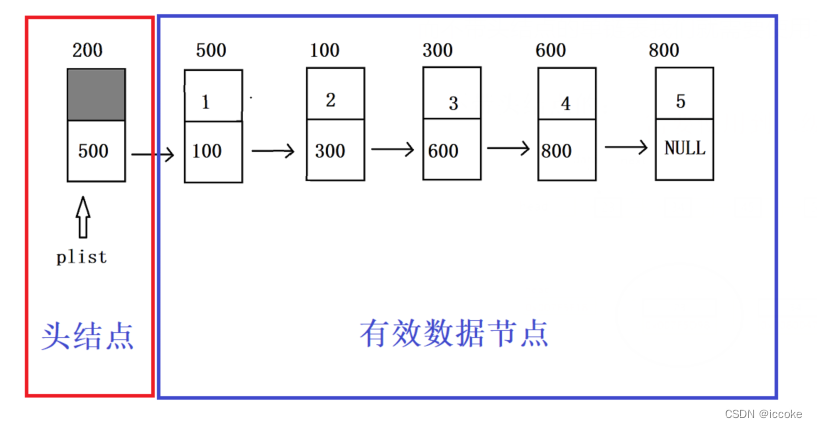 带头结点的单链表的结构就像这样
带头结点的单链表的结构就像这样
每一个结点都有自己的地址 然后是自己的数据域 指向下个结点的指针域
因此我们就可以得到单链表的结构体设计结构
typedef int ELEM_TYPE;
typedef struct Node
{
ELEM_TYPE data;//数据域(保存数据的有效值)
struct Node* next;//指针域(保存着下一个有效节点的地址)
}Node, *PNode;
还有单链表对应的函数
因为单链表在后续的使用过程中相对比较重要
因此这里我们就需要将单链表的完整代码给出
void Init_list(struct Node* plist);
//头插
bool Insert_head(PNode plist, ELEM_TYPE val);
//尾插
bool Insert_tail(PNode plist, ELEM_TYPE val);
//按位置插
bool Insert_pos(PNode plist, int pos, ELEM_TYPE val);
//头删
bool Del_head(PNode plist);
//尾删
bool Del_tail(PNode plist);
//按位置删
bool Del_pos(PNode plist, int pos);
//按值删
bool Del_val(PNode plist, ELEM_TYPE val);
//查找 //查找到,返回的是查找到的这个节点的地址
struct Node* Search(PNode plist, ELEM_TYPE val);
//判空
bool IsEmpty(PNode plist);
//清空
void Clear(PNode plist);
//销毁1
void Destroy(PNode plist);
//销毁2
void Destroy2(PNode plist);
//打印
void Show(PNode plist);
//获取有效值个数
int GetLength(PNode plist);
接下来我们就要逐步实现单链表
首先是初始化
头节点我们只需要使用指针域 并不使用数据域
因此我们不初始化数据域
后续的结点可以通过购买获得
而且因为点链表中的结点是通过指针连接 因此我们并不需要对其进行大小的给定 可以在使用时调整
void Init_list(struct Node* plist)
{
//1.判断plist是否为NULL地址
assert(plist != NULL);
//2.对plist指向的头结点里面的每一个成员变量进行赋值
//3.因为头结点直接借用的是有效节点的结构体设计,省事,但是多了一个数据域用不到,
// 既然头结点的数据域用不到,那就浪费掉,只用指针域即可
//plist->data; 头结点的数据域不使用
plist->next = NULL;
然后我们就可以得到他的基础结构
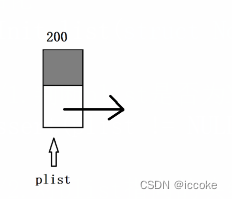
这里头节点的地址我们为了方便可以随机给一个值
但是这里是仅仅为了方便 实际上头节点的地址我们是未知也不需要知道的
然后是插入函数
我们先写头插 因为这里的特殊情况较少
bool Insert_head(PNode plist, ELEM_TYPE val)
{
//0.安全性处理
assert(plist != NULL);
//1.购买新节点
struct Node* pnewnode = (struct Node*)malloc(1 * sizeof(struct Node));
assert(pnewnode != NULL);
pnewnode->data = val;
//2.找到合适的插入位置(其实就是用柱子很指向插入位置上一个节点)
//因为是头插,永远都是插入在头结点后面,所以不用找 直接用plist即可
//3.插入
pnewnode->next = plist->next;
plist->next = pnewnode;
return true;
}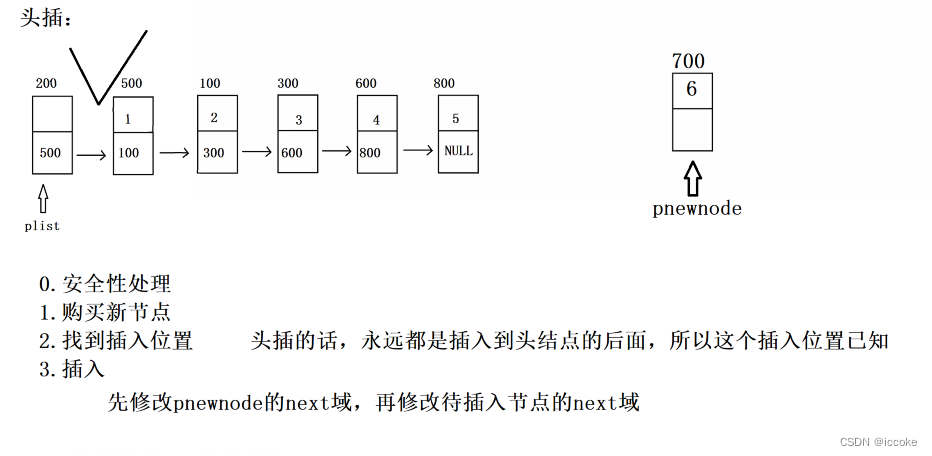
我们可以看到因为每一个结点都有指针域 因此我们在头插的时候就需要改变前一个的next域和购买的新指针指向下一个结点 保持单链表的结点的连续性
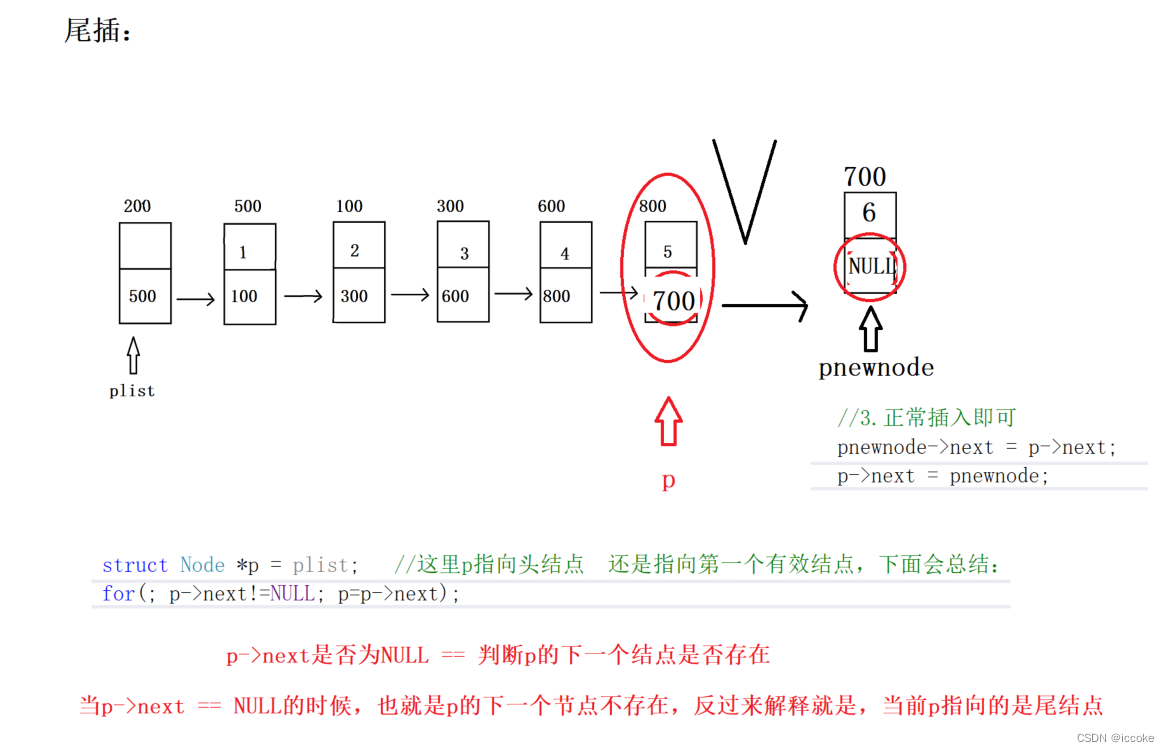
尾插就相对简单 因为尾插后插入的新结点就作为目前单链表的结尾 因此它的next域就可以为NULL
bool Insert_tail(PNode plist, ELEM_TYPE val)
{
//0.安全性处理
assert(plist != NULL); //判断plist指向的单链表的头结点是否存在
//1.购买新节点
struct Node *pnewnode = (struct Node *)malloc(1 * sizeof(struct Node));
assert(pnewnode != NULL);
pnewnode->data = val;
//pnewnode->next = NULL; //这行代码可以省略,也可以留下
//2.找到合适的插入位置 (找到在哪一个结点后面插入,然后用指针p指向这个结点)
struct Node *p = plist; //这里p指向头结点 还是指向第一个有效结点,下面会总结:
for(; p->next!=NULL; p=p->next);
//3.正常插入即可
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}这里就涉及到了单链表中常见的两种访问结点的循环方式
我们可以根据情况改变使用方法

这个循环在后续的使用中会非常常见 因此我们要牢记两种的使用情景
这里我们使用的就是需要前驱的循环
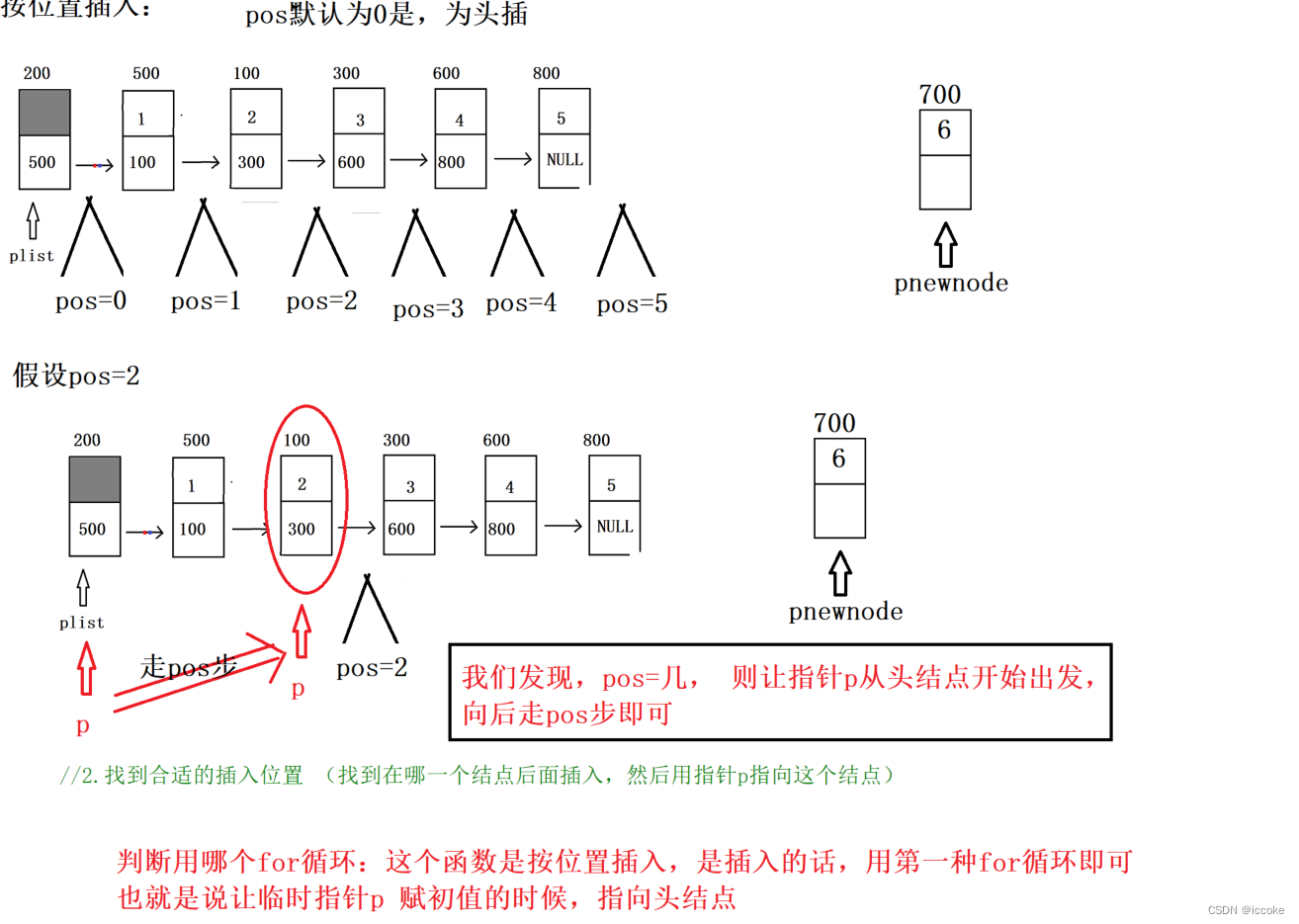
然后就是按位置插入
如果是 0 就是头插
bool Insert_pos(PNode plist, int pos, ELEM_TYPE val)
{
//0.安全性处理
assert(plist != NULL); //判断plist指向的单链表的头结点是否存在
assert(pos>=0 && pos<=GetLength(plist));
//1.购买新节点
struct Node *pnewnode = (struct Node *)malloc(1 * sizeof(struct Node));
assert(pnewnode != NULL);
pnewnode->data = val;
//pnewnode->next = NULL; //这行代码可以省略,也可以留下
//2.找到合适的插入位置 (找到在哪一个结点后面插入,然后用指针p指向这个结点)
// 发现规律:pos=几 则让指针p从头结点开始向后走,走pos步即可
struct Node *p = plist;
for(int i=0; i<pos; i++)
{
p = p->next;
}
//3.正常插入
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}如果是任意位置 我们就带头节点的for循环来访问
我们先访问到待插结点的前一个位置 然后正常插入
改变 next域即可
这里涉及到了统计结点个数的函数
我们一并实现
实际就是用不带头结点的for循环即可
int GetLength(PNode plist) {
int count = 0;
for (struct Node* p = plist->next; p != NULL; p = p->next) {
count++;
}
return count;
}
接下来是删除
其实在插入和删除前我们都要考虑到是否为 空 或者是否为满
因为单链表不存在满的情况 因此我们在插入时并没做判断
但是单链表存在空的情况
因此我们需要在删除前进行判断
bool Del_head(PNode plist)
{
//0.安全性处理 不仅仅判断头结点是否存在,还需要判断是否是空链表
assert(plist != NULL);
if(IsEmpty(plist))
{
return false;
}
//如果不是空链表,则代表至少有一个有效节点
//1.申请一个临时指针p指向待删除节点
struct Node *p = plist->next;//头删比较特殊,待删除节点就是第一个有效节点
//2.申请一个临时指针q指向待删除节点的上一个节点(前驱)
//头删比较特殊,待删除节点的上一个节点就是头结点,所以这里q不用定义,直接使用plist即可
//3.跨越指向
plist->next = p->next;
//4.释放待删除节点
free(p);
return true;
bool IsEmpty(PNode plist)
{
return plist->next == NULL;
}

跨域指向就是把待删除结点的后一个结点的地址赋值给前一个结点的next域
尾删就相对简单 我们将倒数第二个元素的next域指向NULL 然后释放最后一个结点 就可以实现
bool Del_tail(PNode plist)
{
//0.安全性处理 不仅仅判断头结点是否存在,还需要判断是否是空链表
//如果不是空链表,则代表至少有一个有效节点
assert(plist != NULL);
if(IsEmpty(plist))
{
return false;
}
//1.申请一个临时指针p指向待删除节点 p指向倒数第一个节点(尾结点)
struct Node *p = plist;
for(; p->next!=NULL; p=p->next);
//此时,for循环执行结束,指针p指向尾结点
//2.申请一个临时指针q指向待删除节点的上一个节点(前驱) q指向倒数第二个节点
struct Node *q = plist;
for(; q->next!=p; q=q->next); //for( ; q->next->next!=NULL; q=q->next);
//3.跨越指向
q->next = p->next;
//4.释放待删除节点
free(p);
return true;
}这里找到倒数第二个元素时我们就可以使用 先找到最后一个结点 再通过 最后一个结点找倒数第二个结点
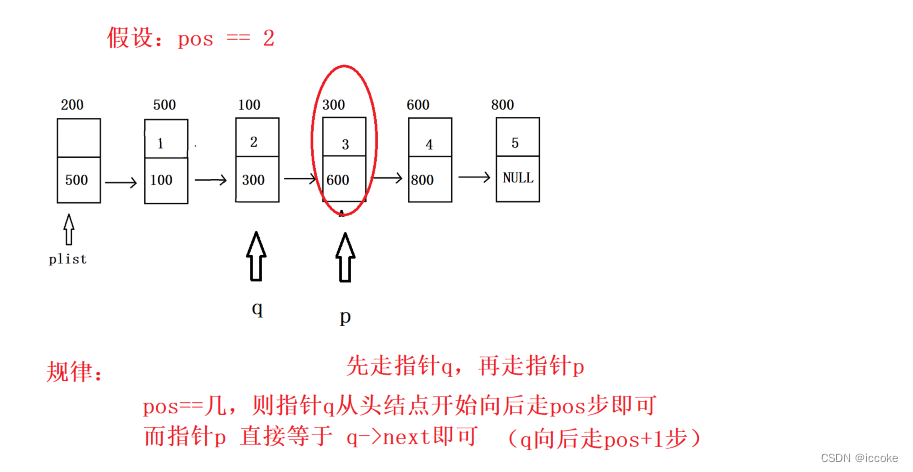
然后是按位置删除
bool Del_pos(PNode plist, int pos)
{
//0.安全性处理
assert(plist!=NULL);
assert(pos>=0 && pos<GetLength(plist));
//这里先找q,再找p
//1.申请一个临时指针q指向待删除节点的上一个节点(前驱)
struct Node *q = plist;
for(int i=0; i<pos; i++)
{
q = q->next;
}
//2.申请一个临时指针p指向待删除节点,将q的next给p
struct Node *p = q->next;
//3.跨越指向
q->next = p->next;
//4.释放
free(p);
return true;
} 
然后还有一个按值删除 就是对应数据域
我们就先要实现一个查找函数
struct Node* Search(PNode plist, ELEM_TYPE val)
{
//判断使用不需要前驱的for循环,只要将单链表遍历一遍即可
for(struct Node *p=plist->next; p!=NULL; p=p->next)
{
if(p->data == val)
{
return p;
}
}
return NULL;
}bool Del_val(PNode plist, ELEM_TYPE val)
{
//1.先判断这个值是否存在于单链表
struct Node *p = Search(plist, val);
if(p == NULL)
{
return false;
}
//此时,如果p!=NULL,则代表val这个节点存在,且现在还被指针p指向
//这时待删除节点找到了,则接下来需要找待删除节点的上一个节点,用q指向
struct Node *q = plist;
for(; q->next!=p; q=q->next);
//此时,指针q也找到了,现在q指向了待删除结点的上一个结点了
//p和q现在都找到了,则跨越指向+释放
q->next = p->next;
free(p);
return true;
}然后就是正常普通的删除
最后我们使用完整个单链表
我们可以 销毁这个单链表
void Destroy(PNode plist)
{
/*while(!IsEmpty(plist))
{
Del_head(plist);
}*/
while(plist->next != NULL)
{
struct Node *p = plist->next;
plist->next = p->next;
free(p);
}
}
//销毁2
void Destroy2(PNode plist)
{
//0.安全性处理
//1.定义两个指针p和q p指向第一个有效节点 q先不要赋值
struct Node *p = plist->next;
struct Node *q = NULL;
//2.断开头结点 因为不借助头结点,所以一开始就将头结点变成最终销毁完成后的样子
plist->next = NULL;
//3.两个指针p和q合作,循环释放后续节点
while(p != NULL)
{
q = p->next;
free(p);
p = q;
}
}这里有两种方式 最能够想到的就是一直头删 因为头删的时间复杂度小 因此使用头删
还有一种就是 通过两个指针合作来一个一个的删除
这就是单链表的全部代码








![[附源码]Python计算机毕业设计大学生志愿者管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/09c1c1cb17c64c60856bc89421698c0f.png)