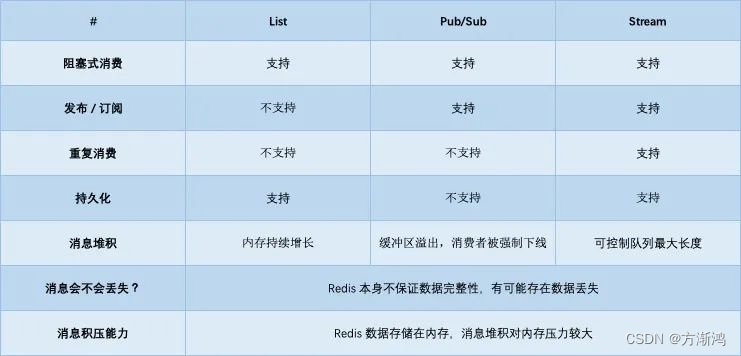
论文链接: https://arxiv.org/abs/2303.13479
代码链接: https://github.com/CVMI-Lab/IST-Net
01.背景介绍
Category-level 的物体姿态估计旨在让模型学习到类别独有的特征,从而能够在面对未见过的同类别物体时展现出良好的泛化性。为了解决 inrta-class variation 的问题,SPD 在早期提出了一种 Prior-based 的框架,现已被大多数主流的方法所采用。具体操作是当我们想估计一个 RGBD 图片的位姿时,使用预先训练好的一个 shape prior 作为辅助,学习 deformation 和 matching 的矩阵让 prior 通过先重建 RGBD 图片所对应的 3D 模型再进一步转换到世界坐标系下的视角(NOCS)。有了匹配的相机坐标系和世界坐标系下的视角,求解位姿便是一件十分容易的事情。
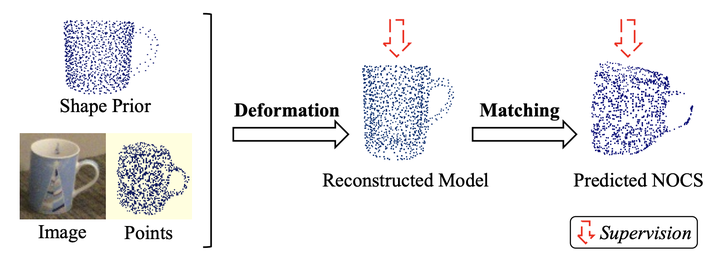
02.Prior-based 方法对于 3D 模型的开销
3D 模型的标注是昂贵和耗时的,因此减少对于 3D 模型的依赖对于算法的实际应用是十分重要的。Prior-based 方法所产生的对于 3D 模型的数据开销主要来源于两个方面。一方面是训练过程中,网络在学习 deformation 的矩阵时(图 1)需要来自 3D 模型的监督。而另一方面是,prior 的产生需要依赖于大量的 3D 模型。
如图 2 所示,首先使用大量的 3D 模型训练一个 auto-encoder, 在训练完成后将相同类别的所有 3D 模型输入到 encoder 中得到 latent embeddings。再将这些 latent embedings 取平均再送入 decoder,重建得到的输出就是当前类的 shape prior。在这个过程中,为了得到一个通用的表征需要收集大量的 3D 模型。而当所需要预测的类别数量增多时,对于 3D 模型的依赖会变成一个严重的问题。
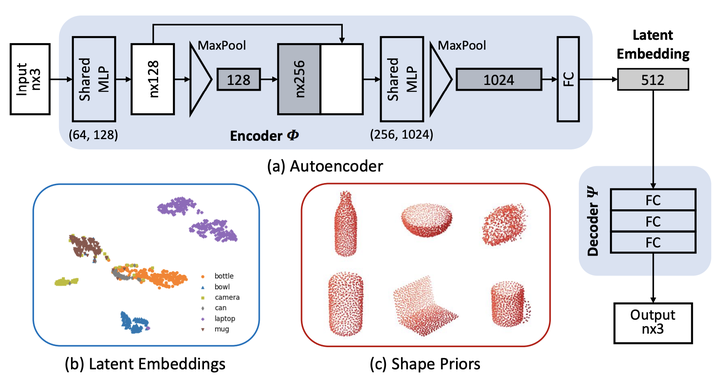
03.Prior 真的重要吗?
当作者重新审视 prior-based 的方法时也逐渐产生了疑问,假设随机给一个 object shape 是否可以变换到 target shape 上呢?将这个过程拆解开就可以发现,random shape 到 target 的变换可以拆解为:从 random shape 到 prior 的变换加上 prior 到 target 的变换。其中 prior 到 target 的变换前述方法已经证明是可行的,而 random shape 到 prior 的变换,由于这两个量都是给定的,所以这个变换矩阵是直接可以求解的。因此作者猜想其实对于任意 shape 网络都可以将其变换到 target shape。
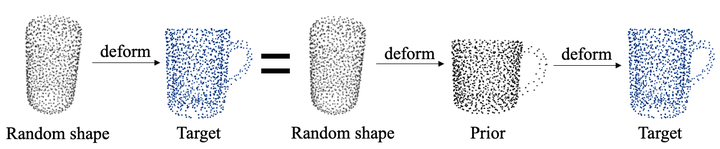
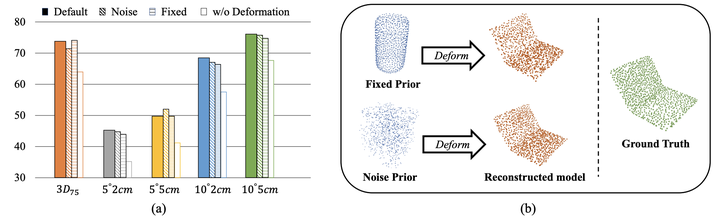
作者进一步在目前 SOTA 的 prior-based 方法上做了验证性实验–对 shape prior 进行替换,共有三组对照组:(1)使用默认的 prior; (2)所有类都使用相同的 prior(fixed prior);(3)使用 random noise 作为 prior。可以观察到即使使用 noise 作为 prior 网络也可以很好重建出 target shape,同时各项指标都与 baseline 几乎相同。而只有当去掉了 deformation 这个模块后才会产生明显的掉点。作者因此得出结论:真正重要的是如何构建世界坐标系与相机坐标系的对应关系,而不是 prior 本身。
04.解决方案
基于上述分析,作者提出了 IST-Net,一个高效且简洁的姿态估计器。旨在摒弃 prior 的同时,从 feature 层面完成从相机坐标系到世界坐标系的变换。IST-Net 包含如下三个模块:


05.实验结果
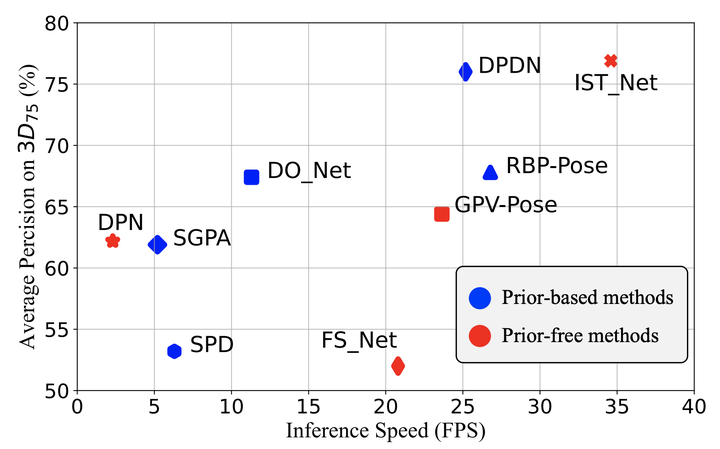
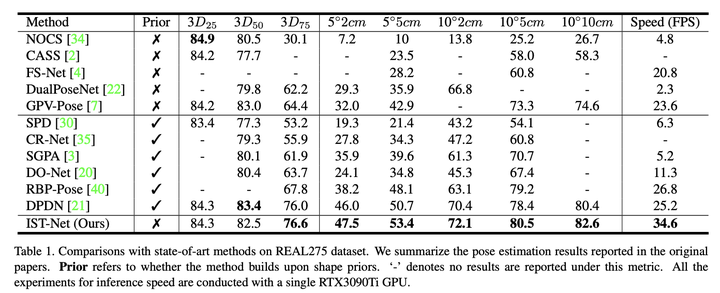
作者在 REAL275 数据集上验证了 IST-Net 的性能。结合图 6 和表 1,可以看到 IST-Net 在各项指标上都有十分优异的表现,同时在速度上大幅度领先之前的方法。
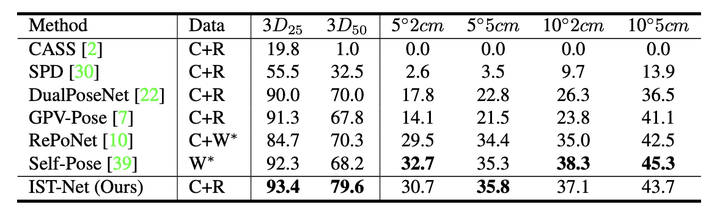
作者将在 REAL275 和 CAMERA25 上训练好的模型直接在 Wild6D 数据集上进行测试结果如下表。IST-Net 展现出了良好的泛化性能甚至在很多指标上超过了在 Wild6D 上训练过的方法。
下表 3 展示了,仅在少量数据上(REAL275)训练得到的模型的性能。IST-Net 显著优于 prior-based 方法。

下表 4 展示了模型对于新的类别的迁移能力。在面对新的类别时,prior-based 方法对于 prior 的依赖导致了较弱的泛化能力。而 IST-Net 在面对相对相对简单的物体时 (bowl),展现出了明显更好的泛化性。

06.总结
本文分析了基于 prior 的姿态估计方法中被忽视的问题,通过实验发现:prior 不会对性能提升做出贡献。真正重要的实际上是 deformation 的过程:它构建了相机和世界坐标之间的对应关系,重建了世界坐标系中的物体形状。受到此启发,作者设计了一个隐式空间变换网络(IST-Net) 将相机空间特征转换为世界空间的特征。它无需目标对象的 prior 或是 3D 模型即可构建空间对应关系。此外,作者还设计了两个独立的增强器进一步增加了几何约束。大量实验表明所提出的方法在效率和准确性方面的有效性。希望这篇文章能为该领域未来的研究提供新的见解。
参考文献
[1] Tian, Meng, Marcelo H. Ang, and Gim Hee Lee. “Shape prior deformation for categorical 6d object pose and size estimation.” Computer Vision–ECCV 2020
[2] Lin, Jiehong, et al. “Category-level 6D object pose and size estimation using self-supervised deep prior deformation networks.” European Conference on Computer Vision.
[3] Chen, Kai, and Qi Dou. “Sgpa: Structure-guided prior adaptation for category-level 6d object pose estimation.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[4] Di, Yan, et al. “Gpv-pose: Category-level object pose estimation via geometry-guided point-wise voting.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[5] Zhang, Ruida, et al. “RBP-Pose: Residual bounding box projection for category-level pose estimation.” European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区