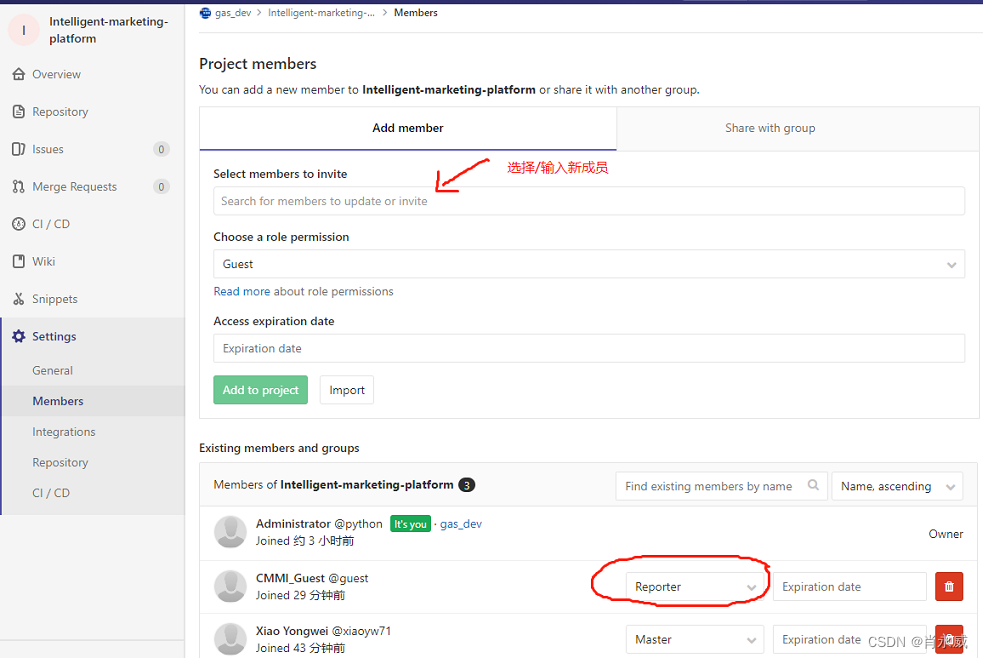
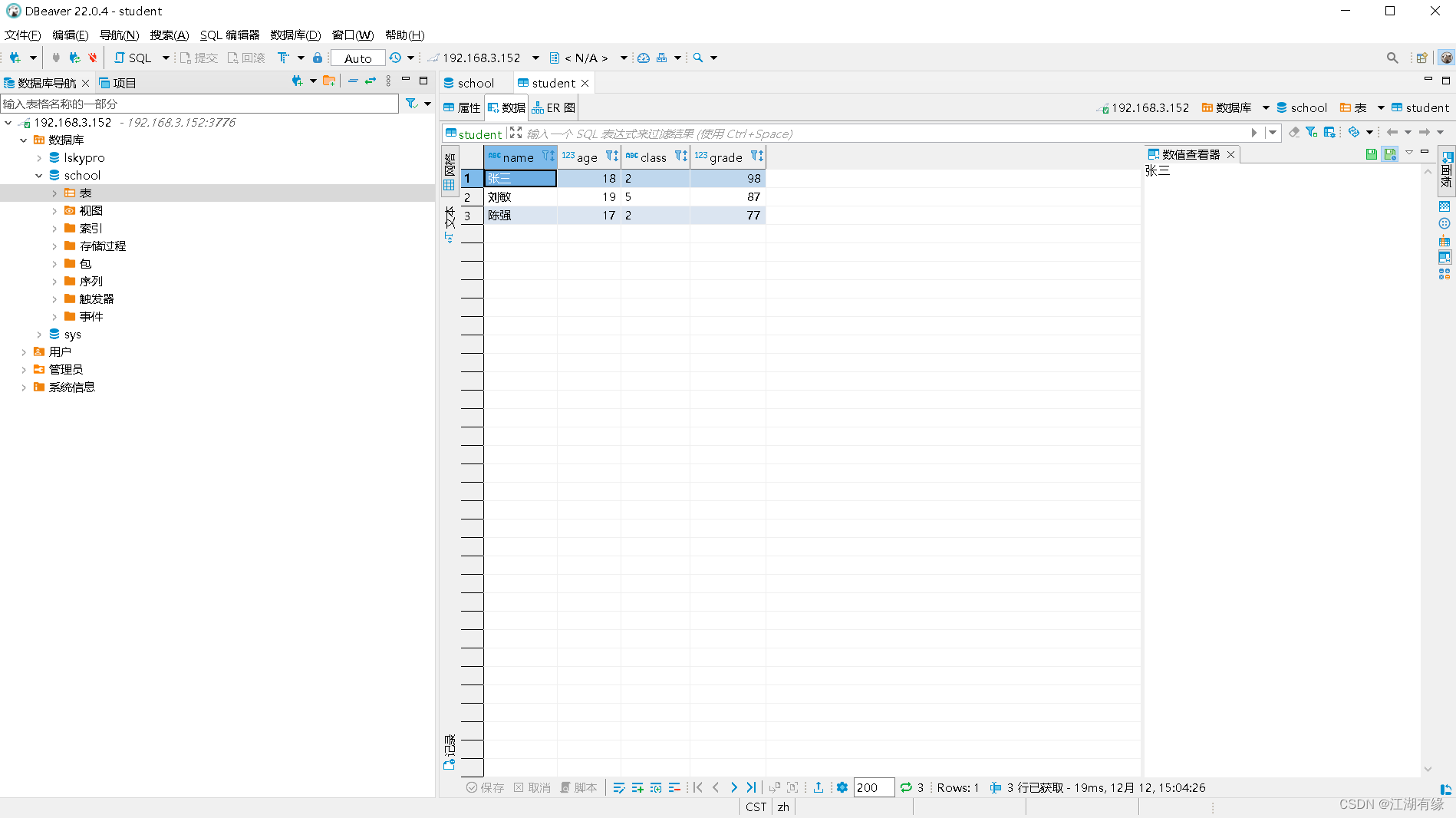
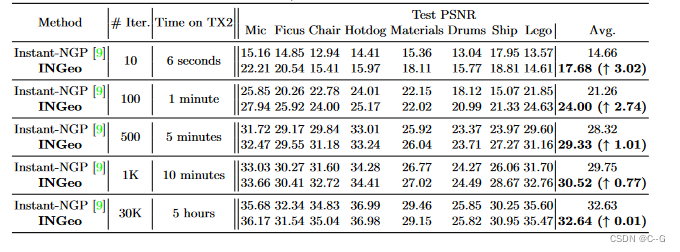
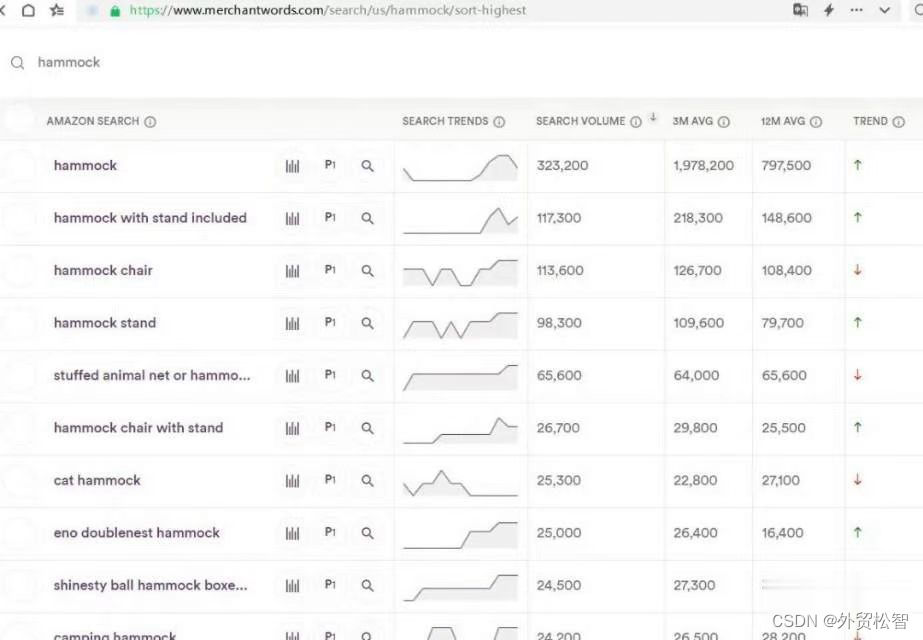
文章目录
- 题目
- 一、BF算法
- 二、RK算法
- 补充
题目
有字符串 str1 和 str2 ,str1 中是否包含 str2,如果没有包含返回 -1,如果包含,则返回 str2 在 str1 中开始的位置
注:保证 str1 和 str2 字符串的长度大于 0
举例:

可以看的出来,str2 字符串确实是 str1 的子串,并且 str2 在 str1 中第一次出现的位置是 2(字符串位置索引从 0 开始),因此返回 2

在上面的例子中,str1 中没有 str2 的子串,因此返回 -1
一、BF算法
BF算法,就是暴力算法,解决问题简单粗暴,缺点就是所消耗的代价较大,在一些极端情况下,效率极低
解题思路:
暴力解法的思路就是把 str1 字符串的每一个字符都尝试着作为 str2 的头向后进行匹配,如果匹配后发现是不同的字符,说明 str1 中无法以该字符为开始将 str2 匹配成功
例子演示:
1)从 str1 的下标 0 开始,进行字符的逐个比较,发现到了第三个字符就匹配失败了

2)将 str2 字符串向后移动一位,对应 str1 的下标 1 的字符,进行匹配,第一个字符就匹配失败了

3)将 str2 字符串向后移动一位,对应 str1 的下标 2 的字符,进行匹配,逐个比较,成功,返回 2

代码展示:
public static int BF(String str1,String str2) {
int len1 = str1.length();
int len2 = str2.length();
//进入循环的条件是len1不小于len2,一共尝试匹配(len1-len2+1)轮
for (int i = 0; i < (len1 - len2 + 1); i++) {
int j = 0;
for (; j < len2; j++) {
//如果有个字符匹配不上了,说明从 str1 的位置i开始无法匹配出 str2
if (str1.charAt(i + j) != str2.charAt(j)) {
break;
}
}
//若成立,表示从 str1 的位置 i 开始匹配出 str2,返回结果
if (j == len2) {
return i;
}
}
return -1;
}
反思:
在某些极端的情况下,暴力算法的效率会很低

可以看出,上面的例子一共要比较 7 轮,并且每一轮都需要比较 3 次,因为除了最后一轮,其他的每轮比较都会发现前两个字符相同,最后一个字符不同
如果 str1 的长度为 N,str2 的长度为 M,那么最坏情况下,时间复杂度为 O(N*M)
二、RK算法
RK 算法实际上是建立在 BF 算法基础上的一种优化。
解题思路:
BF 算法之所以有效率低的缺点,就是因为在最坏的情况下需要将两个字符串的所有字符进行一次比对,如果我们将需要比对的两个字符串进行哈希,比对哈希值是否相等,就可以避免字符的挨个比较了。
如果哈希值不同,那么两个字符串一定不同,如果相同,再调用 equals 方法,精确比较
该算法的优化关键就在于进行了哈希,生成了 hashcode,那么哈希函数有很多种,这里采取的方法就是简单的按位相加,即将 ‘a’ 当成 1,‘b’ 当成 2,…,‘z’ 当成 26(假设字符串中只包含小写字母)
hash(“abcd”) = 1 + 2 + 3 + 4 = 10
这样的哈希生成算法简单,但是容易产生哈希碰撞,即明明不同的字符串,算出的哈希值却是相同的,比如 “abc” 和 “cba”,所以精确比较很有必要
例子演示:
1)可以算出 “abb” 的 hashcode 为 5,str1 中第一个长度为 3 的子串 “aba” 的 hashcode 为 4,不相等,说明匹配失败,进行下一轮

2)str2 向后移动一格,对应到的 str1 的字符串 "bab"的 hashcode 为 5,相等,进行精确比较,“bab”.equals(“abb”),返回 false,说明不匹配,进行下一轮

3)str2 向后移动一格,对应到的 str1 的字符串 "abb"的 hashcode 为 5,相等,进行精确比较,“abb”.equals(“abb”),返回 true,匹配成功,返回 2

代码展示:
public static int RK (String str1,String str2) {
int len1 = str1.length();
int len2 = str2.length();
int str2code = hash(str2);//str2字符串的哈希值
int str1code = hash(str1.substring(0,len2));//str1首次比对的子串的哈希值
for (int i = 0; i < (len1-len2+1); i++) {
if (str1code == str2code && realCompare(str1,str2,i)) {
return i;
}
//说明还没有匹配成功,需要求出下一轮比对的str1子串的哈希值
//如果已经是最后一轮了,就不需要更新,说明整体匹配失败
if (i < len1-len2) {
str1code = refreshHash(str1,str1code,i,len2);
}
}
return -1;
}
//更新哈希值,为下一次的比对做准备
public static int refreshHash(String str1,int oldHash,int index,int len2) {
oldHash -= (str1.charAt(index) - 'a' + 1);
oldHash += (str1.charAt(index + len2) -'a' + 1);
return oldHash;
}
//精确比对,index表示str1是从哪个位置开始比对的
public static boolean realCompare(String str1,String str2,int index) {
return str2.equals(str1.substring(index,index + str2.length()));
}
//按位相加,哈希函数
public static int hash (String str) {
int result = 0;
for (int i = 0; i < str.length(); i++) {
result += (str.charAt(i) - 'a' + 1);
}
return result;
}
反思:
计算哈希值的时候没有必要每次都将字符重新进行按位相加,可以利用之前计算出来的旧的哈希值来计算新的
例如 “abbc”,“abb” 的哈希值是 5(旧的哈希值),下一个要计算哈希值的字符串是 “bbc”,实际上就是在原来的字符串中减掉字符 ‘a’,加上字符 ‘c’,所以新的哈希值就是 7(5 - 1 + 3)
总结下来,如果 str1 的长度为 N,str2 的长度为 M,由于每个字符都会参与到哈希值的计算当中,RK 算法的时间复杂度为 O(N+M)
该算法的缺点也显而易见——性能不稳定。有产生哈希冲突的可能性,当冲突非常严重的时候,就需要经常进行精确比对,RK 算法和 BF 算法就差不多了
补充
问:那么有没有一种方法能够避免无谓的比对,又能够性能稳定,非常高效呢?
答:KMP 算法