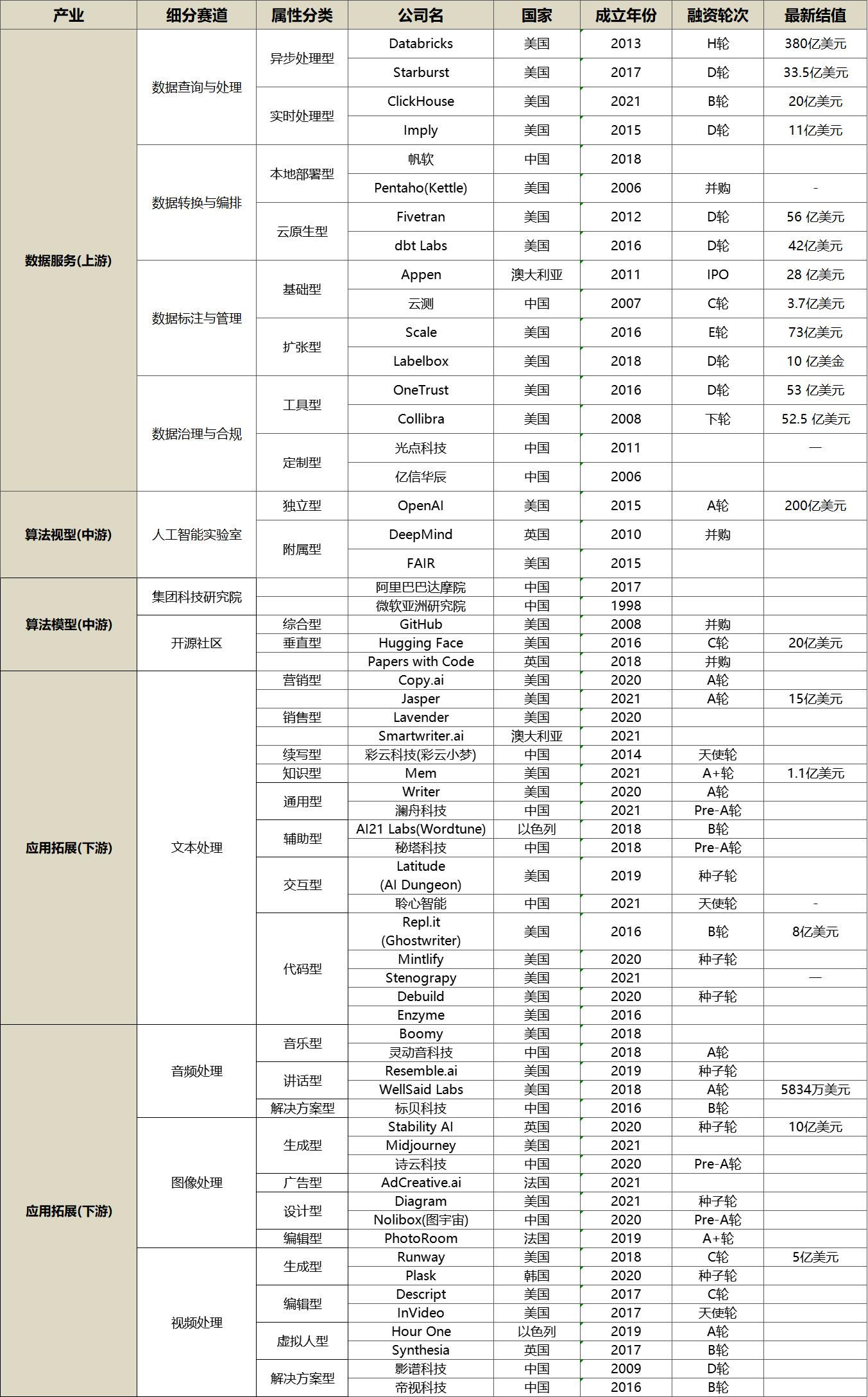
Python爬虫 从小白到高手 各种最新案例! Urllib Xpath JsonPath BeautifulSoup
requests
1.基本使用
1.官方文档:
http://cn.python‐requests.org/zh_CN/latest/
快速上手 http://cn.python‐requests.org/zh_CN/latest/user/quickstart.html
2.安装
pip install requests
3.response的属性以及类型
import requests
url = 'http://www.baidu.com'
response = requests.get(url=url)
# 一个类型和六个属性
# Response类型
# print(type(response))
# 设置响应的编码格式 乱码变中文
# response.encoding = 'utf-8'
# 以字符串的形式来返回了网页的源码
# print(response.text)
# 返回url地址
# print(response.url)
# 返回的是二进制的数据
# print(response.content)
# 返回响应的状态码
# print(response.status_code)
# 返回的是响应头
print(response.headers)类型 :models.Response
r.text: 获取网站源码
r.encoding: 访问或定制编码方式
r.url: 获取请求的url
r.content: 响应的字节类型
r.status_code:响应的状态码
r.headers: 响应的头信息
urlib与requests区别
urllib
(1) 一个类型以及六个方法 (2)get请求 (3)post请求 百度翻译
(4)ajax的get请求(5)ajax的post请求(6)cookie登陆 微博(7)代理
requests
(1)一个类型以及六个属性(2)get请求(3)post请求
(4)代理(5)cookie 验证码
2.get请求
import requests
url = 'https://www.baidu.com/s'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'wd':'北京'
}
# url 请求资源路径
# params 参数
# kwargs 字典
response = requests.get(url=url,params=data,headers=headers)
content = response.text
print(content)总结:
(1)参数使用params传递
(2)参数无需urlencode编码
(3)不需要请求对象的定制
(4)请求资源路径中的?可以加也可以不加
3.post请求(百度翻译)
import requests
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'kw': 'eye'
}
# url 请求地址
# data 请求参数
# kwargs 字典
response = requests.post(url=url,data=data,headers=headers)
content =response.text
import json
obj = json.loads(content)
print(obj)
# 总结:
# (1)post请求 是不需要编解码
# (2)post请求的参数是data
# (3)不需要请求对象的定制json.loads传入参数encoding=‘utf-8’会有报错,取消此参数即可
6:get和post区别?
1: get请求的参数是params post请求的参数 是data
2: 请求资源路径后面可以不加?
3: post 不需要编解码
4: 不需要做请求对象的定制
4.代理
7:proxy定制
write出来的东西要百度 安全卫士验证
import requests
url = 'http://www.baidu.com/s?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
data = {
'wd':'ip'
}
proxy = {
'http':'212.129.251.55:16816'
}
response = requests.get(url = url,params=data,headers = headers,proxies = proxy)
content = response.text
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)5.cookie定制
8:cookie定制
通过登陆 然后进入到主页面

通过找登陆接口我们发现 登陆的时候需要的参数很多
_VIEWSTATE: /m1O5dxmOo7f1qlmvtnyNyhhaUrWNVTs3TMKIsm1lvpIgs0WWWUCQHl5iMrvLlwnsqLUN6Wh1aNpitc4WnOt0So3k6UYdFyqCPI6jWSvC8yBA1Q39I7uuR4NjGo=
__VIEWSTATEGENERATOR: C93BE1AE
from: 我的收藏_古诗文网
email: 595165358@qq.com
pwd: action
code: PId7
denglu: 登录
我们观察到_VIEWSTATE __VIEWSTATEGENERATOR code验证码是一个可以变化的量
难点:(1)_VIEWSTATE __VIEWSTATEGENERATOR 一般情况看不到的数据 都是在页面的源码中
Ctrl+f观察到这两个数据在页面的源码中 所以我们需要获取页面的源码 然后进行解析就可以获取了

(2)验证码 获取验证码图片
应用案例:
(1)古诗文网(需要验证)
import requests
# 这是登陆页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 获取页面的源码
response = requests.get(url = url,headers = headers)
content = response.text
# print(content)
# 解析页面源码 然后获取_VIEWSTATE __VIEWSTATEGENERATOR
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# 获取_VIEWSTATE
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
# 获取__VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
# 有坑
# import urllib.request
# urllib.request.urlretrieve(url=code_url,filename='code.jpg')
# requests里面有一个方法 session() 通过session的返回值 就能使 请求变成一个对象
session = requests.session()
# 验证码的url的内容
response_code = session.get(code_url)
# 注意此时要使用二进制数据 因为我们要使用的是图片的下载
content_code = response_code.content
# wb的模式就是将二进制数据写入到文件
with open('code.jpg','wb')as fp:
fp.write(content_code)
# 获取了验证码的图片之后 下载到本地 然后观察验证码 观察之后 然后在控制台输入这个验证码 就可以将这个值给
# code的参数 就可以登陆
code_name = input('请输入你的验证码')
# 点击登陆
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstategenerator,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '',
'pwd': '',
'code': code_name,
'denglu': '登录',
}
response_post = session.post(url = url, headers = headers, data = data_post)
content_post = response_post.text
with open('gushiwen.html','w',encoding= ' utf-8')as fp:
fp.write(content_post)
# 难点
# (1) 隐藏域
# (2) 验证码(2)云打码平台 超级鹰 破解验证码
用户登陆 actionuser action
开发者登陆 actioncode action
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def PostPic_base64(self, base64_str, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
'file_base64':base64_str
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
#用户中心的 软件id生成一个替换96001
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print chaojiying.PostPic(im, 1902) #1902 对应价格体系 #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
#print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码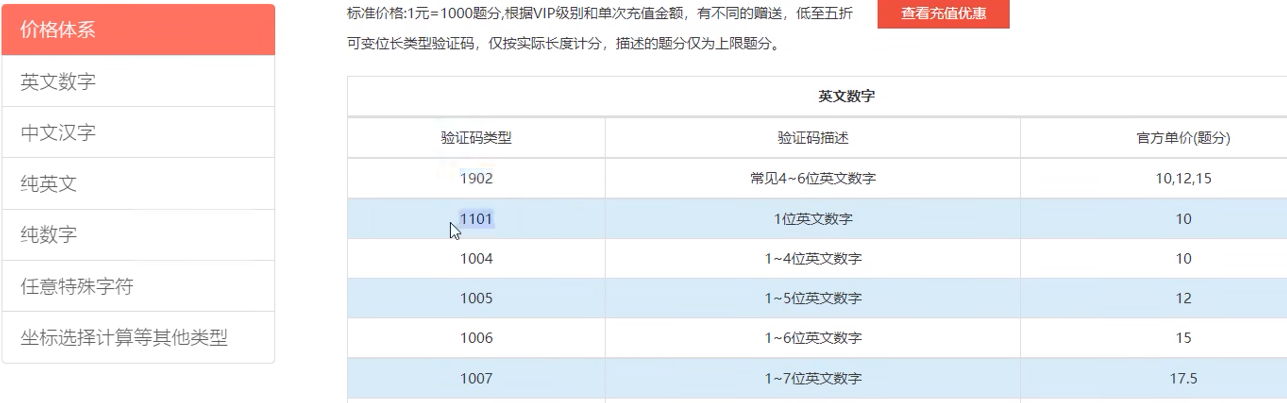
作业:国家统计局(http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2017/)共计68万条数
scrapy 用的最多的爬虫技术
1.scrapy
(1)scrapy是什么?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
(2)安装scrapy:
pip install scrapy
安装过程中出错:
building 'twisted.test.raiser' extension
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++
Build Tools": http://landinghub.visualstudio.com/visual‐cpp‐build‐tools
解决方案:
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
下载twisted对应版本的whl文件(如我的Twisted‐17.5.0‐cp36‐cp36m‐win_amd64.whl),cp后面是python版本,
cmd输入python 查询版本
amd64代表64位操作系统,运行命令:
pip install C:\Users\...\Twisted‐17.5.0‐cp36‐cp36m‐win_amd64.whl
如果再报错 提示升级pip
python ‐m pip install ‐‐upgrade pip
如果再报错 win32
解决方法:
pip install pypiwin32
再报错:使用anaconda
使用步骤:
打开anaconda
点击environments
点击not installed
输入scrapy
apply
在pycharm中选择anaconda的环境
1.scrapy项目的创建以及运行
1.创建scrapy项目:
终端输入scrapy startproject 项目名称 (不能数字、汉字开头)
2.项目组成:
spiders 文件夹
__init__.py
自定义的爬虫文件.py ‐‐‐》由我们自己创建,是实现爬虫核心功能的文件
__init__.py
items.py ‐‐‐》定义数据结构的地方,是一个继承自scrapy.Item的类
middlewares.py ‐‐‐》中间件 代理
pipelines.py ‐‐‐》管道文件,里面只有一个类,用于处理下载数据的后续处理
默认是300优先级,值越小优先级越高(1‐1000)
settings.py ‐‐‐》配置文件 比如:是否遵守robots协议,User‐Agent定义等
3.创建爬虫文件:
(1)跳转到spiders文件夹 cd 目录名字/目录名字/spiders
(2)scrapy genspider 爬虫名字 网页的域名
爬虫文件的基本组成:
继承scrapy.Spider类
name = 'baidu'‐‐‐》 运行爬虫文件时使用的名字
allowed_domains‐‐‐》 爬虫允许的域名,在爬取的时候,如果不是此域名之下的url,会被过滤掉
start_urls ‐‐‐》 声明了爬虫的起始地址,可以写多个url,一般是一个
parse(self, response) ‐‐‐》解析数据的回调函数
response.text ‐‐‐》响应的是字符串
response.body‐‐‐》响应的是二进制文件
response.xpath()‐》xpath方法的返回值类型是selector列表
extract() ‐‐‐》提取的是selector对象的是data
extract_first() ‐‐‐》提取的是selector列表中的第一个数据
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 使用的值
name = 'baidu'
# 允许访问的域名
allowed_domains = ['http://www.baidu.com']
# 起始的url地址 指的是第一次要访问的域名
# start_urls 是在allowed_domains的前面添加 http://
# 在 allowed_domains的后面添加 一个/
start_urls = ['http://www.baidu.com/']
# 执行了start_urls之后 执行的方法 方法中的response 就是返回的那个对象
# 相当于 response = urllib.request.urlopen()
# response = requests.get()
def parse(self, response):
print('苍茫的天涯是我的爱')4.运行爬虫文件:
scrapy crawl 爬虫名称
注意:应在spiders文件夹内执行
1. 创建爬虫的项目 scrapy startproject 项目的名字
注意:项目的名字不允许使用数字开头 也不能包含中文
2. 创建爬虫文件
要在spiders文件夹中去创建爬虫文件
cd 项目的名字\项目的名字\spiders
cd scrapy_baidu_091\scrapy_baidu_091\spiders
创建爬虫文件
scrapy genspider 爬虫文件的名字 要爬取网页
eg:scrapy genspider baidu http://www.baidu.com
一般情况下不需要添加http协议 因为start_urls的 值是根据allowed_domains修改的 所以添加了http的话 那么start_urls就需要我们手动去修改了
3. 运行爬虫代码
scrapy crawl 爬虫的名字
eg:
scrapy crawl baidu
58同城项目结构和基本方法
这里大家可以在setting里面设置cookie便不需要验证码了
import scrapy
class TcSpider(scrapy.Spider):
name = 'tc'
allowed_domains = ['https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91']
start_urls = ['https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91']
def parse(self, response):
# 字符串
# content = response.text
# 二进制数据
# content = response.body
# print('===========================')
# print(content)
span = response.xpath('//div[@id="filter"]/div[@class="tabs"]/a/span')[0]
print('=======================')
print(span.extract())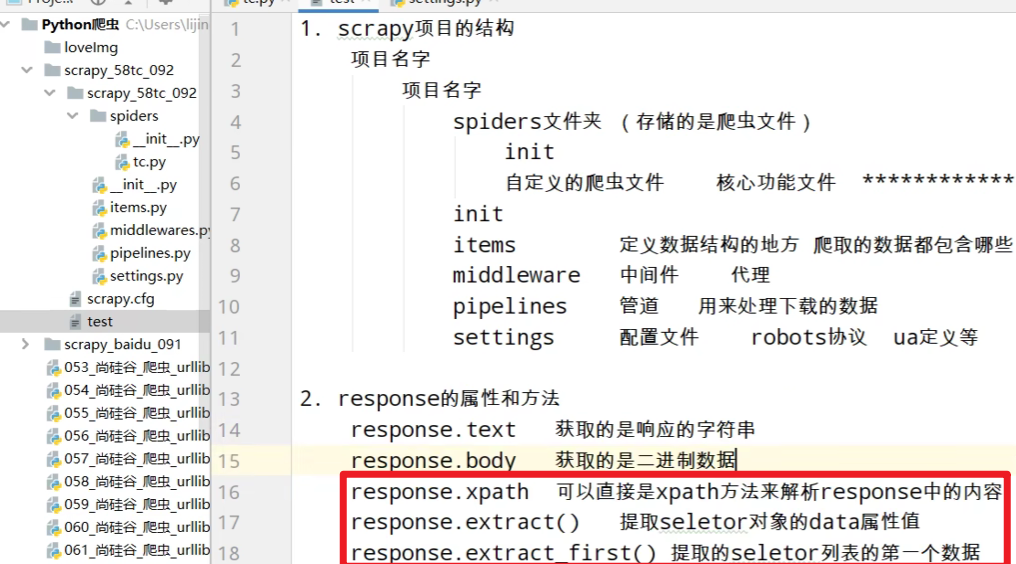
3.scrapy架构组成
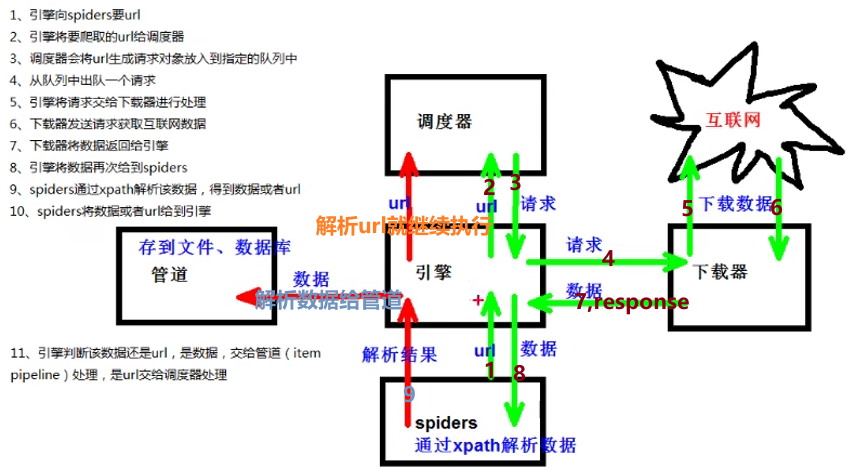
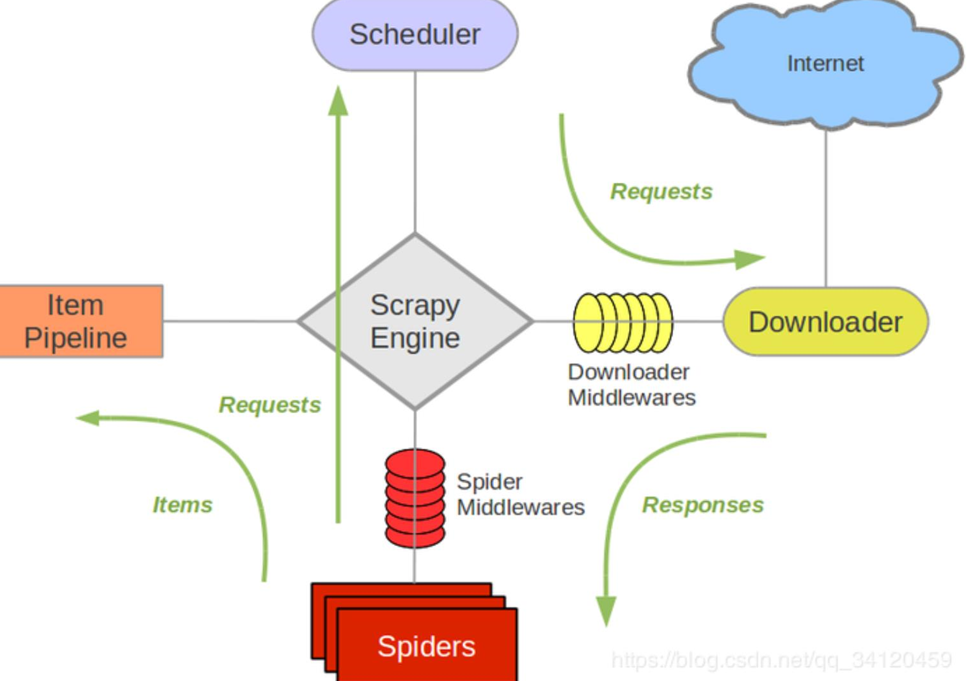
(1)引擎 ‐‐‐》自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
(2)下载器 ‐‐‐》从引擎处获取到请求对象后,请求数据
(3)spiders ‐‐‐》Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
(4)调度器 ‐‐‐》有自己的调度规则,无需关注
(5)管道(Item pipeline) ‐‐‐》最终处理数据的管道,会预留接口供我们处理数据
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个item pipeline组件(有时称为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:
1. 清理HTML数据
2. 验证爬取的数据(检查item包含某些字段)
3. 查重(并丢弃)
4. 将爬取结果保存到数据库中
4.scrapy工作原理
案例:1.汽车之家
url的html链接最后不能/
import scrapy
class CarSpider(scrapy.Spider):
name = 'car'
allowed_domains = ['https://car.autohome.com.cn/price/brand-15.html']
# 注意如果你的请求的接口是html为结尾的 那么是不需要加/的
start_urls = ['https://car.autohome.com.cn/price/brand-15.html']
def parse(self, response):
name_list = response.xpath('//div[@class="main-title"]/a/text()')
price_list = response.xpath('//div[@class="main-lever"]//span/span/text()')
for i in range(len(name_list)):
name = name_list[i].extract()
price = price_list[i].extract()
print(name,price)2.scrapy shell
1.什么是scrapy shell?
Scrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。 其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码。
该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据。 在编写您的spider时,该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。
一旦熟悉了Scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。
进入到scrapy shell的终端 直接在window的终端中输入scrapy shell 域名
如果想看到一些高亮 或者 自动补全 那么可以安装ipython pip install ipython
scrapy shell www.baidu.com
2.安装ipython
安装:pip install ipython
简介:如果您安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。
3.应用:
(1)scrapy shell www.baidu.com
(2)scrapy shell http://www.baidu.com
(3) scrapy shell "http://www.baidu.com"
(4) scrapy shell "www.baidu.com"
语法:
(1)response对象:
response.body
response.text
response.url
response.status
(2)response的解析:
response.xpath() (常用)
使用xpath路径查询特定元素,返回一个selector列表对象
response.css()
使用css_selector查询元素,返回一个selector列表对象
获取内容 :response.css('#su::text').extract_first()
获取属性 :response.css('#su::attr(“value”)').extract_first()
(3)selector对象(通过xpath方法调用返回的是seletor列表)
extract()
提取selector对象的值
如果提取不到值 那么会报错
使用xpath请求到的对象是一个selector对象,需要进一步使用extract()方法拆包,转换为unicode字符串
extract_first()
提取seletor列表中的第一个值
如果提取不到值 会返回一个空值
返回第一个解析到的值,如果列表为空,此种方法也不会报错,会返回一个空值
xpath()
css()
注意:每一个selector对象可以再次的去使用xpath或者css方法
3.yield
1. 带有 yield 的函数不再是一个普通函数,而是一个生成器generator,可用于迭代
2. yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行
3. 简要理解:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始
案例:
1.当当网 100页的 图片 价格 等
(1)yield(2).管道封装(3).多条管道下载 (4)多页数据下载
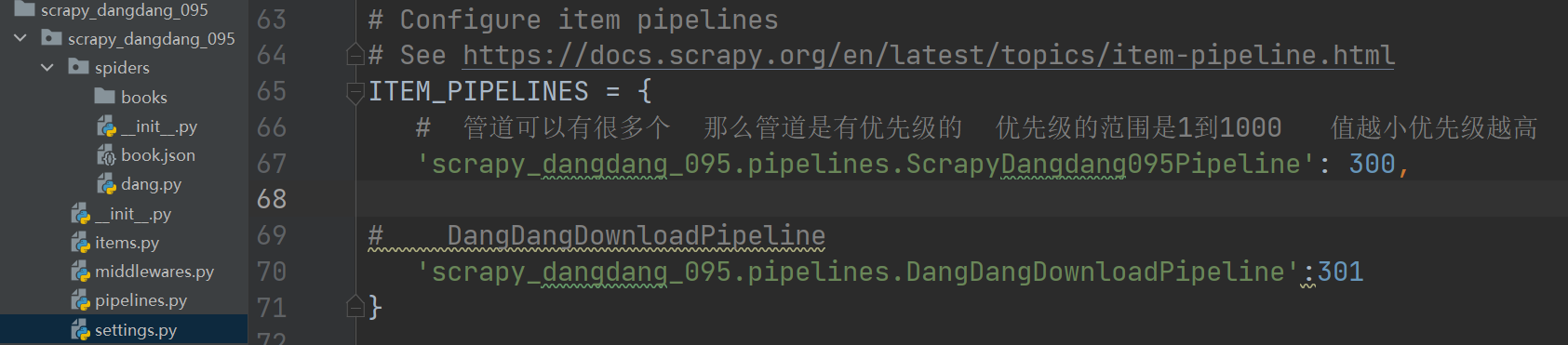
pipelines.py 开管道要调settings
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# 如果想使用管道的话 那么就必须在settings中开启管道
class ScrapyDangdang095Pipeline:
# 在爬虫文件开始的之前就执行的一个方法
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')//打开文件
# item就是yield后面的book对象
def process_item(self, item, spider):
# 以下这种模式不推荐 因为每传递过来一个对象 那么就打开一次文件 对文件的操作过于频繁
# # (1) write方法必须要写一个字符串 而不能是其他的对象
# # (2) w模式 会每一个对象都打开一次文件 覆盖之前的内容
# with open('book.json','a',encoding='utf-8')as fp:
# fp.write(str(item))
self.fp.write(str(item))
return item
# 在爬虫文件执行完之后 执行的方法
def close_spider(self,spider):
self.fp.close() //关闭文件
import urllib.request
# 多条管道开启
# (1) 定义管道类
# (2) 在settings中开启管道
# 'scrapy_dangdang_095.pipelines.DangDangDownloadPipeline':301
class DangDangDownloadPipeline:
def process_item(self, item, spider):
url = 'http:' + item.get('src')
filename = './books/' + item.get('name') + '.jpg'
urllib.request.urlretrieve(url = url, filename= filename)
return itemdang.py
import scrapy
from scrapy_dangdang_095.items import ScrapyDangdang095Item
class DangSpider(scrapy.Spider):
name = 'dang'
# 如果是多页下载的话 那么必须要调整的是allowed_domains的范围 一般情况下只写域名
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
# pipelines 下载数据
# items 定义数据结构的
# src = //ul[@id="component_59"]/li//img/@src
# alt = //ul[@id="component_59"]/li//img/@alt
# price = //ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()
# 所有的seletor的对象 都可以再次调用xpath方法
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
# 第一张图片和其他的图片的标签的属性是不一样的
# 第一张图片的src是可以使用的 其他的图片的地址是data-original
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = ScrapyDangdang095Item(src=src,name=name,price=price)
# 获取一个book就将book交给pipelines
yield book
# 每一页的爬取的业务逻辑全都是一样的,所以我们只需要将执行的那个页的请求再次调用parse方法
# 就可以了
# http://category.dangdang.com/pg2-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg3-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg4-cp01.01.02.00.00.00.html
if self.page < 100:
self.page = self.page + 1
url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
# 怎么去调用parse方法
# scrapy.Request就是scrpay的get请求
# url就是请求地址
# callback是你要执行的那个函数 注意不需要加()
yield scrapy.Request(url=url,callback=self.parse)电影天堂 (1)一个item包含多级页面的数据
只把域名 改成这个 www.dytt.to 就能运行
import scrapy
from scrapy_movie_099.items import ScrapyMovie099Item
class MvSpider(scrapy.Spider):
name = 'mv'
allowed_domains = ['www.dytt.to']
start_urls = ['https://www.dytt.to/html/gndy/china/index.html']
def parse(self, response):
# 要第一个的名字 和 第二页的图片
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[2]')
for a in a_list:
# 获取第一页的name 和 要点击的链接
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# 第二页的地址是
url = 'https://www.dytt.to' + href
#print(name,url)
# 对第二页的链接发起访问 将name存到 meta字典
yield scrapy.Request(url=url,callback=self.parse_second,meta={'name':name})
def parse_second(self,response):
# 注意 如果拿不到数据的情况下 一定检查你的xpath语法是否正确
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# 接受到请求的那个meta参数的值
name = response.meta['name']
movie = ScrapyMovie099Item(src=src,name=name)
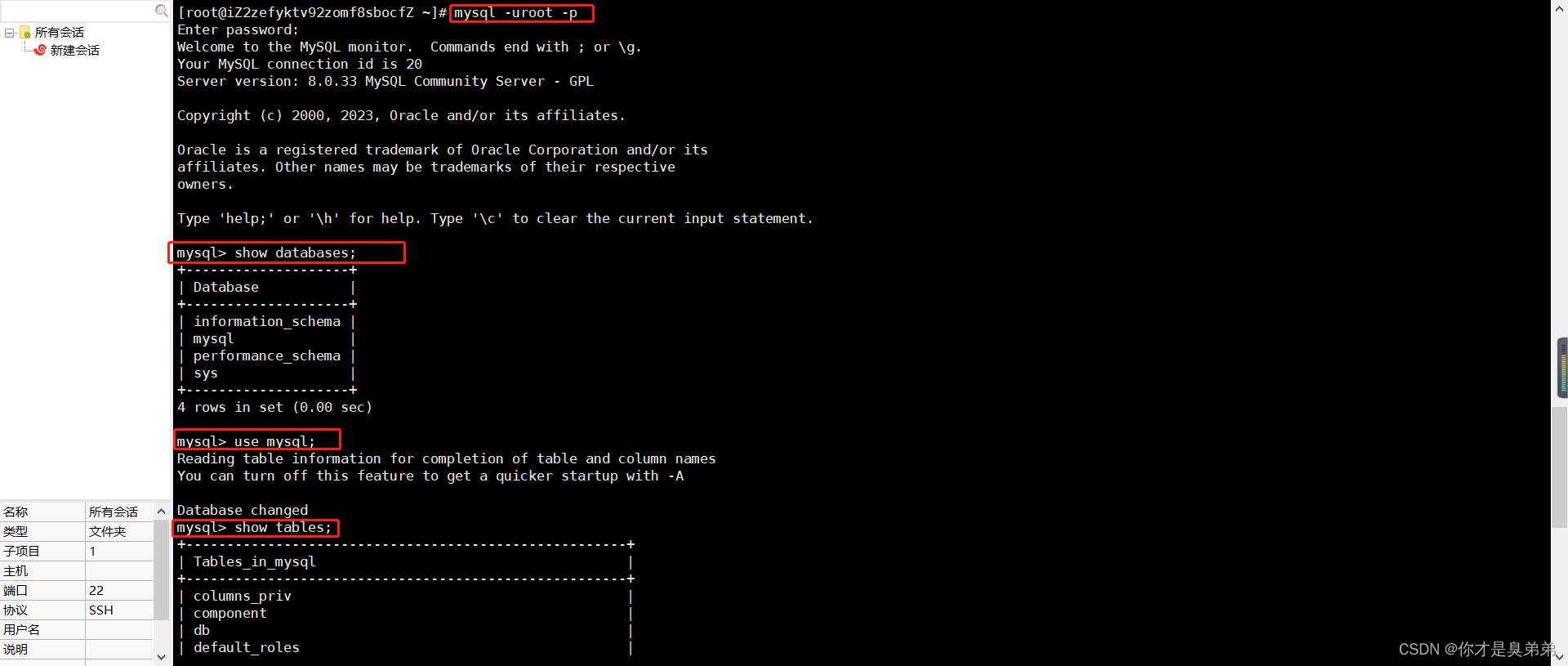
yield movie4.Mysql
(1)下载(MySQL :: Download MySQL Installer)
(2)安装(MySQL数据库5.7.20的下载与安装_互联网-百度经验)
5.pymysql的使用步骤
1.pip install pymysql
![]()
2.pymysql.connect(host,port,user,password,db,charset)
3.conn.cursor()
4.cursor.execute()
6.CrawlSpider
1.继承自scrapy.Spider
2.独门秘笈
CrawlSpider可以定义规则,解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求
所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的
3.提取链接
链接提取器,在这里就可以写规则提取指定链接
scrapy.linkextractors.LinkExtractor(
allow = (), # 正则表达式 提取符合正则的链接
deny = (), # (不用)正则表达式 不提取符合正则的链接
allow_domains = (), # (不用)允许的域名
deny_domains = (), # (不用)不允许的域名
restrict_xpaths = (), # xpath,提取符合xpath规则的链接
restrict_css = () # 提取符合选择器规则的链接)
4.模拟使用
正则用法:links1 = LinkExtractor(allow=r'list_23_\d+\.html')
xpath用法:links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]')
css用法:links3 = LinkExtractor(restrict_css='.x')

5.提取连接
link.extract_links(response)
6.注意事项
【注1】callback只能写函数名字符串, callback='parse_item'
【注2】在基本的spider中,如果重新发送请求,那里的callback写的是allback=self.parse_item follow=true 是否跟进 就是按照提取连接规则进行提取
运行原理:
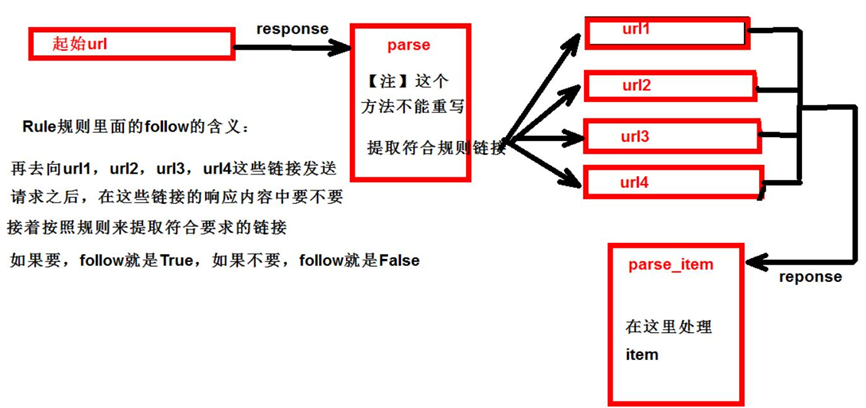
7.CrawlSpider案例
需求:读书网数据入库
1.创建项目:scrapy startproject dushuproject
2.跳转到spiders路径 cd\dushuproject\dushuproject\spiders
3.创建爬虫类:scrapy genspider ‐t crawl (爬虫文件的名字 爬取的域名)read www.dushu.com
4.items
5.spiders
6.settings
# 参数中一个端口号 一个是字符集 都要注意
DB_HOST = '127.0.0.1'
# 端口号是一个整数
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWROD = '123456'
DB_NAME = 'spider01'
# utf-8的杠不允许写
DB_CHARSET = 'utf8'
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy_readbook_101.pipelines.ScrapyReadbook101Pipeline': 300,
# MysqlPipeline
'scrapy_readbook_101.pipelines.MysqlPipeline':301
}7.pipelines
数据保存到本地
数据保存到mysql数据库
class ScrapyReadbook101Pipeline:
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
# 加载settings文件
#解耦,很多地方用到的话一旦数据库配置变了只需要改一个地方就可以
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipeline:
def open_spider(self,spider):
settings = get_project_settings()
self.host = settings['DB_HOST']
self.port =settings['DB_PORT']
self.user =settings['DB_USER']
self.password =settings['DB_PASSWROD']
self.name =settings['DB_NAME']
self.charset =settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'],item['src'])
# 执行sql语句
self.cursor.execute(sql)
# 提交
self.conn.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()新建数据库spider01
create table book(
id int PRIMARY key auto_increment,
name VARCHAR(128),
src VARCHAR(128)
);import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_readbook_101.items import ScrapyReadbook101Item
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1188_1.html']
rules = (
Rule(LinkExtractor(allow=r'/book/1188_\d+.html'),
callback='parse_item',
follow=True),
)
def parse_item(self, response):
img_list = response.xpath('//div[@class="bookslist"]//img')
for img in img_list:
src = img.xpath('./@data-original').extract_first()
name = img.xpath('./@alt').extract_first()
print(src,name)
book = ScrapyReadbook101Item(name=name,src=src)
yield book那就改正则的规则,比如本例改为1188(_\d+)?\.html
8. 数据入库
(1)settings配置参数:
DB_HOST = '192.168.231.128'
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = '1234'
DB_NAME = 'test'
DB_CHARSET = 'utf8'
(2)管道配置
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipeline(object):
#__init__方法和open_spider的作用是一样的
#init是获取settings中的连接参数
def __init__(self):
settings = get_project_settings()
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.pwd = settings['DB_PWD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
# 连接数据库并且获取cursor对象
def connect(self):
self.conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
password=self.pwd,
db=self.name,
charset=self.charset)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = 'insert into book(image_url, book_name, author, info) values("%s",
"%s", "%s", "%s")' % (item['image_url'], item['book_name'],
item['author'], item['info'])
sql = 'insert into book(image_url,book_name,author,info) values("{}",
"{}","{}","{}")'.format(item['image_url'], item['book_name'], item['author'],
item['info'])
# 执行sql语句
self.cursor.execute(sql)
self.conn.commit()
return item
def close_spider(self, spider):
self.conn.close()
self.cursor.close()
9.日志信息和日志等级
(1)日志级别:
CRITICAL:严重错误
ERROR:一般错误
WARNING: 警告
INFO: 一般信息
DEBUG:调试信息
默认的日志等级是DEBUG
只要出现了DEBUG或者DEBUG以上等级的日志 那么这些日志将会打印
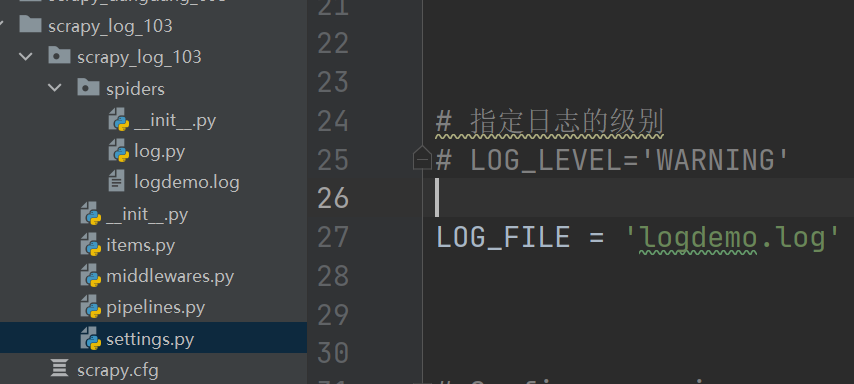
(2)settings.py文件设置:
默认的级别为DEBUG,会显示上面所有的信息
在配置文件中 settings.py
LOG_FILE : 将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.log
LOG_LEVEL : 设置日志显示的等级,就是显示哪些,不显示哪些 一般不调整这个
scrapy的post请求 携带参数
Post请求 必须用start_requests 这个方法
(1)重写start_requests方法:
def start_requests(self)
(2) start_requests的返回值:
scrapy.FormRequest(url=url, headers=headers, callback=self.parse_item, formdata=data)
url: 要发送的post地址
headers:可以定制头信息
callback: 回调函数
formdata: post所携带的数据,这是一个字典
import scrapy
import json
class TestpostSpider(scrapy.Spider):
name = 'testpost'
allowed_domains = ['https://fanyi.baidu.com/sug']
# post请求 如果没有参数 那么这个请求将没有任何意义
# 所以start_urls 也没有用了
# parse方法也没有用了
# start_urls = ['https://fanyi.baidu.com/sug/']
#
# def parse(self, response):
# pass
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
data = {
'kw': 'final'
}
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse_second)
def parse_second(self,response):
content = response.text
#json现在不要encoding了
obj = json.loads(content)
print(obj)11.代理
(1)到settings.py中,打开一个选项
DOWNLOADER_MIDDLEWARES = {
'postproject.middlewares.Proxy': 543,
}
(2)到middlewares.py中写代码
def process_request(self, request, spider):
request.meta['proxy'] = 'https://113.68.202.10:9999'
return None