欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/132056980

SDXL v1.0 版本 是 Stable Diffusion 的最新版本,是基于潜在扩散模型的文本到图像生成技术,能够根据输入的任何文本生成高分辨率、高质量、高多样性的图像,具有以下特点:
-
更好的成像质量:SDXL v1.0 版本能够以几乎任何艺术风格生成清晰、逼真、美观的图像,无论是风景、人物、建筑还是动物,都能呈现出细节和色彩,相比于之前的版本有着巨大的提升。
-
更多的艺术风格:SDXL v1.0 版本相比于之前的版本,能够实现更多的风格,并且对于每种风格都能驾驭。因此,可以尝试更多的艺术家名称和美学,比如梵高、莫奈、达利等,也可以自由创造出想要的风格。
-
更智能、更简单的语言:SDXL v1.0 版本只需少量单词,就能创建复杂、详细、美观的图像。不再需要调用 “杰作” 等限定词,来获得高质量图像。
-
更高的分辨率:SDXL v1.0 版本的基础分辨率是 1024x1024,相比于之前的版本,可以产生更好的图像细节,同时处理宽高比的效果更好。可以根据需求选择不同的分辨率和宽高比,例如16:9、3:2、4:3等。
-
更大的开放图像模型:在已知的开源文生图模型中,SDXL v1.0 版本拥有最大的参数量,建立在一个创新的架构之上,即由 3.5B 参数的基础模型和 6.6B 参数的精炼器组成。完整模型由一个专家混合管道组成,用于潜在扩散。
SDXL v1.0 版本 也进行以下优化:
-
对于 Stable Diffusion 的U-Net、VAE、CLIP Text Encoder三大组件都做了改进。
- U-Net 增加 Transformer Blocks (自注意力 + 交叉注意力) 来增强特征提取和融合能力;
- VAE 增加条件变分自编码器来提升潜在空间的表达能力;
- CLIP Text Encoder 增加两个大小不同的编码器来提升文本理解和匹配能力。
-
增加单独基于 Latent 的 Refiner 模型,来提升图像的精细化程度。Refiner 模型也是一个潜在扩散模型,接收基础模型生成的图像 Latent 特征作为输入,进一步去噪和优化,使得最终输出的图像更加清晰和锐利。
-
设计了很多训练 Tricks,包括图像尺寸条件化策略,图像裁剪参数条件化以及多尺度训练等。这些 Tricks 可以提高模型的泛化能力和稳定性,使得模型能够适应不同的分辨率和宽高比,以及不同的图像内容和风格。
-
预先发布 SDXL 0.9 测试版本,基于用户使用体验和生成图片的情况,针对性增加数据集和使用 RLHF 技术优化迭代推出 SDXL 1.0 正式版。RLHF 是一种基于强化学习的图像质量评估技术,可以根据人类的偏好来调整模型的参数,使得生成图像的色彩,对比度,光线以及阴影方面更加符合人类的审美。
1. 升级 WebUI
查看 Stable Diffusion WebUI 的当前版本,以及更新至最新版本,即:
git pull
git diff [your file]
git checkout [your file]
git pull
git tag
git pull origin master
升级之后,在 modules/ui_extensions.py 中修改插件更新源,实现更快查询,即:
https://ghproxy.com/
stable-diffusion-webui 官网 GitHub
当前最新版本的提交,即:
commit 68f336bd994bed5442ad95bad6b6ad5564a5409a
Merge: a3ddf46 50973ec
Author: AUTOMATIC1111 <16777216c@gmail.com>
Date: Thu Jul 27 09:02:22 2023 +0300
Merge branch 'release_candidate'
建议预先下载支持工程,工程较大,建议提前下载,即:
cd repositories
git clone https://ghproxy.com/https://github.com/Stability-AI/generative-models.git
重启 WebUI,即可。
nohup python -u launch.py --listen --port 9301 --xformers --no-half-vae --enable-insecure-extension-access --theme dark --gradio-queue > nohup.62.out &
tail -f nohup.62.out
输出日志,启动正确,即:
Python 3.8.16 (default, Mar 2 2023, 03:21:46)
[GCC 11.2.0]
Version: v1.5.1
Commit hash: 68f336bd994bed5442ad95bad6b6ad5564a5409a
Checking roop requirements
Install insightface==0.7.3
Installing sd-webui-roop requirement: insightface==0.7.3
Install onnx==1.14.0
Installing sd-webui-roop requirement: onnx==1.14.0
Install onnxruntime==1.15.0
Installing sd-webui-roop requirement: onnxruntime==1.15.0
Install opencv-python==4.7.0.72
Installing sd-webui-roop requirement: opencv-python==4.7.0.72
Launching Web UI with arguments: --listen --port 9301 --xformers --no-half-vae --enable-insecure-extension-access --theme dark --gradio-queue
[-] ADetailer initialized. version: 23.7.6, num models: 12
dirname: /nfs_baoding/chenlong/workspace_v2/stable_diffusion_webui_docker/localizations
localizations: {'zh-Hans (Stable)': 'extensions/stable-diffusion-webui-localization-zh_Hans/localizations/zh-Hans (Stable).json', 'zh-Hans (Testing)': 'extensions/stable-diffusion-webui-localization-zh_Hans/localizations/zh-Hans (Testing).json'}
2023-08-02 09:27:48,494 - ControlNet - INFO - ControlNet v1.1.233
ControlNet preprocessor location: /nfs_baoding/chenlong/workspace_v2/stable_diffusion_webui_docker/extensions/sd-webui-controlnet/annotator/downloads
2023-08-02 09:27:49,996 - ControlNet - INFO - ControlNet v1.1.233
sd-webui-prompt-all-in-one background API service started successfully.
2023-08-02 09:28:02,472 - roop - INFO - roop v0.0.2
2023-08-02 09:28:02,516 - roop - INFO - roop v0.0.2
Loading weights [ed989d673d] from models/Stable-diffusion/Dreamshaper_7.safetensors
Creating model from config: /configs/v1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Applying attention optimization: xformers... done.
Model loaded in 4.9s (load weights from disk: 0.2s, create model: 0.6s, apply weights to model: 1.3s, apply half(): 0.6s, move model to device: 1.4s, load textual inversion embeddings: 0.6s).
Running on local URL: http://0.0.0.0:9301
To create a public link, set `share=True` in `launch()`.
Startup time: 657.7s (launcher: 356.6s, import torch: 105.7s, import gradio: 22.1s, setup paths: 27.5s, import ldm: 0.3s, other imports: 21.2s, opts onchange: 0.2s, setup codeformer: 1.7s, list SD models: 0.5s, load scripts: 92.9s, load upscalers: 0.2s, initialize extra networks: 0.2s, create ui: 7.8s, gradio launch: 18.2s, app_started_callback: 2.5s).
2. 配置环境
安装 Refiner 支持插件,参考,即:
cd extensions
git clone https://ghproxy.com/https://github.com/wcde/sd-webui-refiner.git
最新插件源,即:
https://gitcode.net/rubble7343/sd-webui-extensions/raw/master/index.json
准备 SDXL 模型,建议下载地址 LiblibAI,即:
- Stable Diffusion SDXL 正式版
- Stable Diffusion SDXL refiner
- SDXL_offset_example-lora
即
cd models/Stable-diffusion
# Stable Diffusion SDXL 正式版
wget https://liblibai-online.liblibai.com/models/31e35c80fc4829d14f90153f4c74cd59c90b779f6afe05a74cd6120b893f7e5b.safetensors?attname=Stable%20Diffusion%20SDXL%20%E6%AD%A3%E5%BC%8F%E7%89%88_sdxl_1.0.safetensors -O SDXL_1.0.safetensors
# Stable Diffusion SDXL refiner
wget https://liblibai-online.liblibai.com/models/7440042bbdc8a24813002c09b6b69b64dc90fded4472613437b7f55f9b7d9c5f.safetensors?attname=Stable%20Diffusion%20SDXL%20refiner_1.0%20refiner.safetensors -O SDXL_refiner_1.0.safetensors
# DreamShaper XL1.0 alpha2
wget "https://liblibai-online.liblibai.com/models/0f1b80cfe81b9c3bde7fdcbf6898897b2811b27be1df684583c3d85cbc9b1fa4.safetensors?attname=DreamShaper%20XL1.0_alpha2%20(xl1.0).safetensors" -O DreamShaper_XL1.0_alpha2.safetensors
cd models/Lora
# SDXL_offset_example-lora
wget https://liblibai-online.liblibai.com/web/model/4852686128f953d0277d0793e2f0335352f96a919c9c16a09787d77f55cbdf6f.safetensors?attname=SDXL_offset_example-lora_1.0.safetensors -O SDXL_offset_lora_1.0.safetensors
显存占用,峰值大约 25G 左右,即:
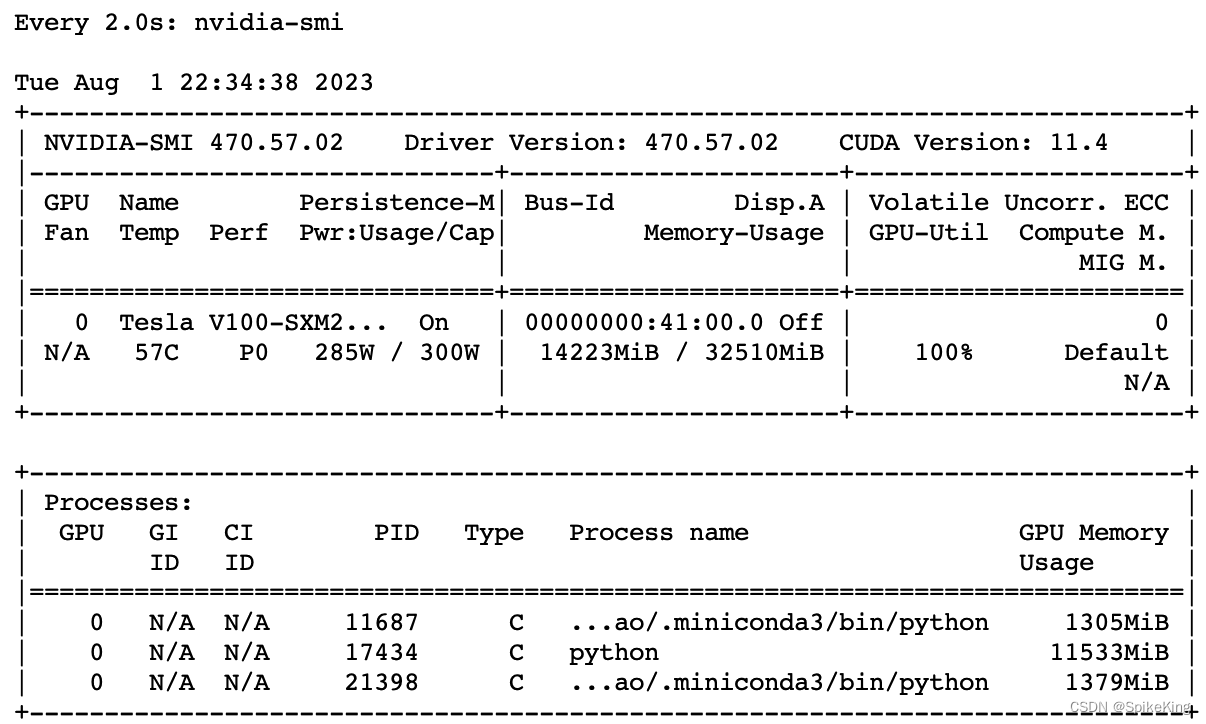
3. 测试图像
测试:
photo, 8k portrait of beautiful cyborg with brown hair, intricate, elegant, highly detailed, majestic, digital photography, art by artgerm and ruan jia and greg rutkowski surreal painting gold butterfly filigree, broken glass, (masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), hdr, realistic, high definition
Steps: 40, Sampler: DPM++ 2M SDE Karras, CFG scale: 8, Seed: 17748028598468, Face restoration: GFPGAN, Size: 1024x1024, Model hash: 31e35c80fc, Model: SDXL_1.0, Clip skip: 2, Version: v1.5.1
seed:17748028598468
注意:目前不加负向提示词,且不要使用高清修复,效果很差。
面部修复建议使用 GFPGAN 算法,即:
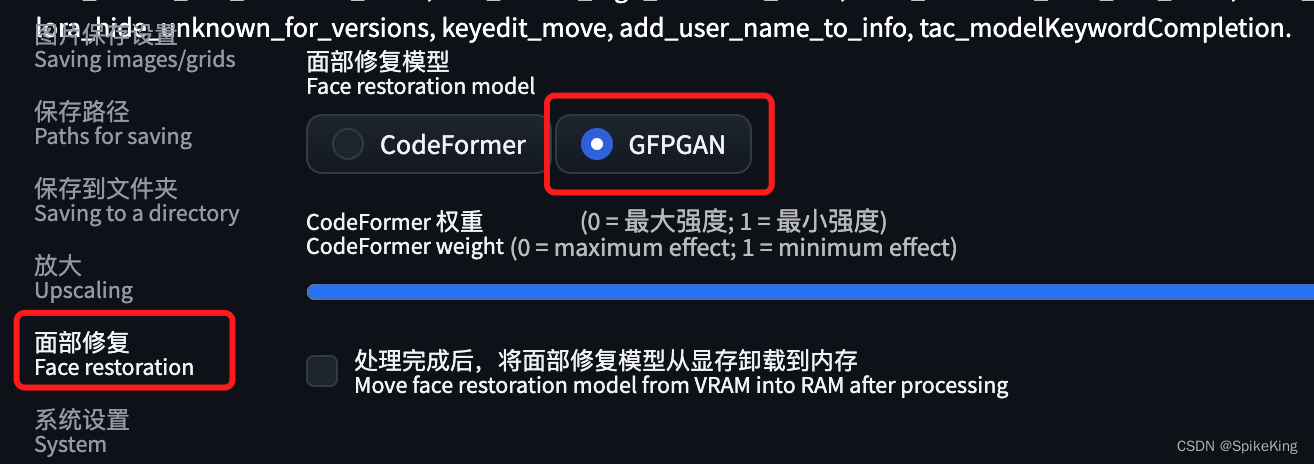
原版模型与GFPGAN的效果差异,即:

DreamShaper的效果,额外添加负向提示词 NSFW,关闭 Refiner (是否开启差别不大),即:
photo, 8k portrait of beautiful cyborg with brown hair, intricate, elegant, highly detailed, majestic, digital photography, art by artgerm and ruan jia and greg rutkowski surreal painting gold butterfly filigree, broken glass, (masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), hdr, realistic, high definition
Negative prompt: nsfw,
Steps: 40, Sampler: DPM++ 2M SDE Karras, CFG scale: 8, Seed: 17748028598468, Face restoration: GFPGAN, Size: 1024x1024, Model hash: 0f1b80cfe8, Model: DreamShaper_XL1.0_alpha2, Clip skip: 2, Version: v1.5.1
图像效果: