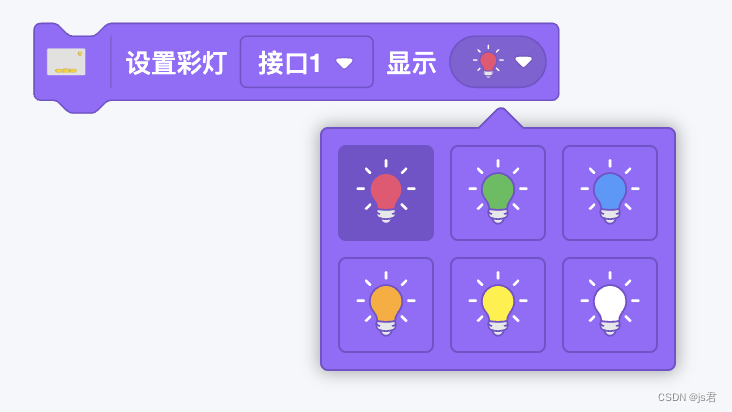
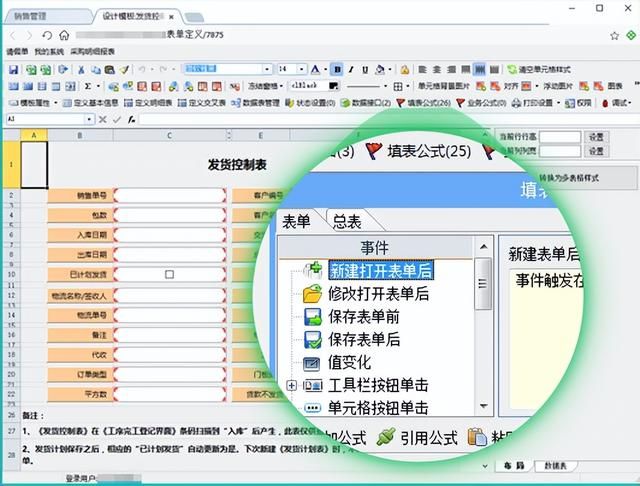
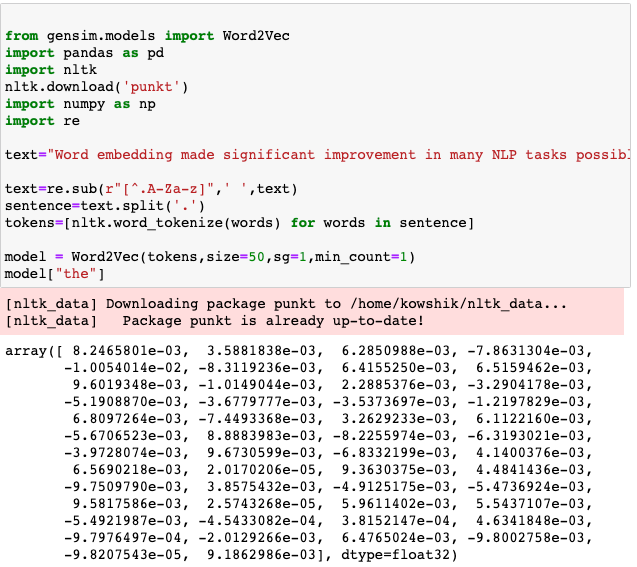
介绍
使用预训练 ViT 模型的图像字幕可以被视为图像下方的文本或书面描述,旨在提供图像细节的描述。它将图像翻译成文本描述的任务。它是通过连接视觉(图像)和语言(文本)来完成的。在本文中,我们使用图像中的 Vision Transformers (ViT) 作为使用 PyTorch 后端的主要技术来实现这一目标。目标是展示一种使用 Transformer(尤其是 ViT)生成图像标题的方法,使用经过训练的模型而无需从头开始重新训练。
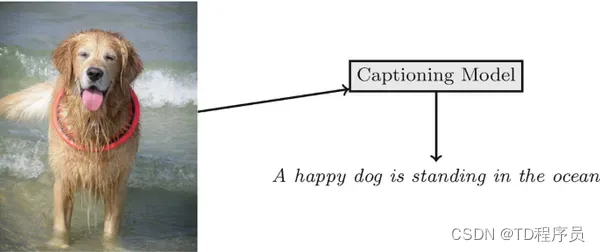

使用预训练 ViT 模型的图像字幕可以被视为图像下方的文本或书面描述,旨在提供图像细节的描述。它将图像翻译成文本描述的任务。它是通过连接视觉(图像)和语言(文本)来完成的。在本文中,我们使用图像中的 Vision Transformers (ViT) 作为使用 PyTorch 后端的主要技术来实现这一目标。目标是展示一种使用 Transformer(尤其是 ViT)生成图像标题的方法,使用经过训练的模型而无需从头开始重新训练。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/825255.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!

![[深度学习] GPU处理能力(TFLOPS/TOPS)](https://img-blog.csdnimg.cn/88f630201e5f4a26877de460331d60bf.png)