文章目录
- 一、编码
- 二、标准库中 string 类的使用
- 1. 构造函数和拷贝构造函数
- 2. 迭代器相关的成员函数
- 3. 容量相关的成员函数
- 4. 访问对象内容相关的成员函数
- 5. 修改对象内容相关的成员函数
- 6. 字符串操作相关的成员函数
- 7. sting 类相关的非成员函数
- 三、vs 和 g++ 下 string 的结构
- 四、string 类的模拟实现
一、编码
计算机中只能存储二进制,不能存储现实生活中的文字,于是需要对文字进行编码
输入文字时,计算机根据编码表,将文字转换为对应的二进制,输出文字时,计算机根据编码表,将二进制转换为对应的文字
ASCII 码就是为了可以在计算机中存储和显示英文信息

由于计算机的飞速发展,为了可以在计算机中存储和显示出其他国家语言的信息,统一码联盟开发了 Unicode
Unicode 编码为每种语言中的每个字符设定了统一并且唯一的二进制编码,将这些字符的二进制编码转换为程序中的数据,又分为 UTF-8、UTF-16、UTF-32 编码格式
UTF-8 是以字节为单位对 统一码 进行编码的格式,特点是对不同范围的字符使用不同长度的编码,即根据统一码在下表的哪个码点范围中,使用该码点范围对应的字节数编码
- 在统一码中 0 ~ 127 的二进制编码,UTF-8格式 与 ASCII 码相同,因此 UTF-8 兼容 ASCII码
- UTF-8 编码的最大长度是 4 个字节,从下表可以看出,4 字节有 21 个编码位,即可以容纳 21 位二进制数字,而统一码的最大码位 0x10FFFF 也只有 21 位

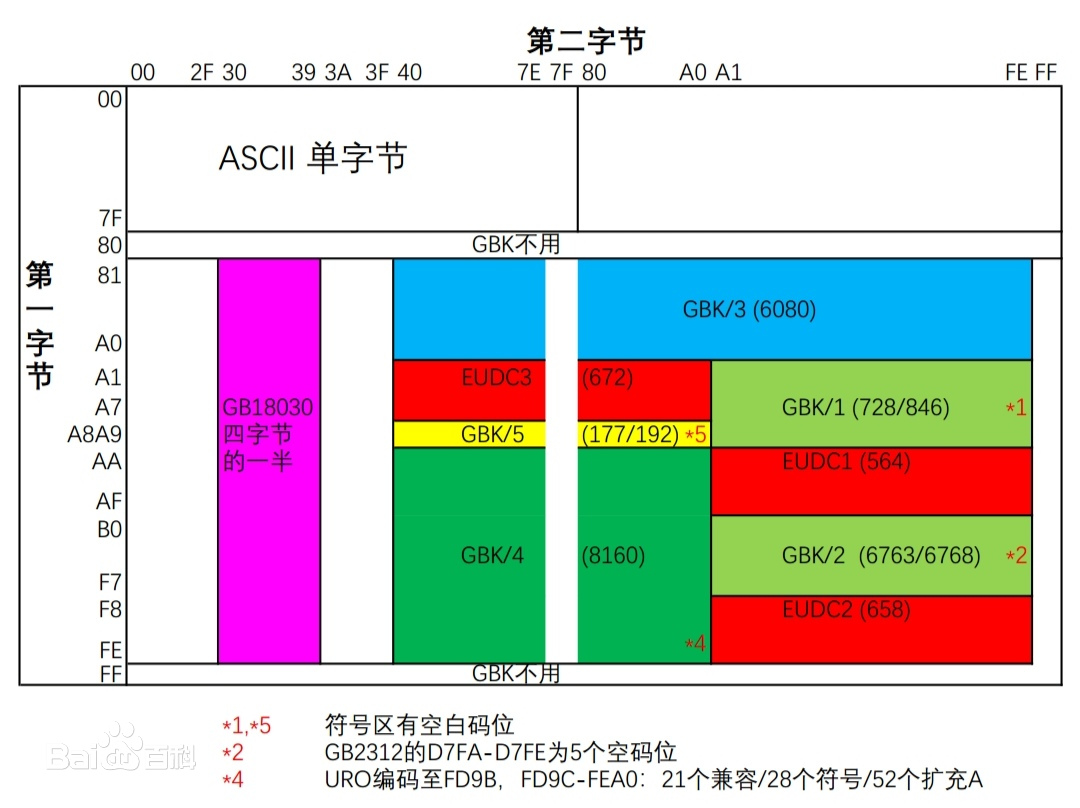
国标码 GBK,采用单双字节变长编码,英文使用单字节编码,完全兼容 ASCII码,中文部分采用双字节编码,总体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线
全部编码分为三大部分:
- 汉字区包括:
a. GB 2312 汉字区,即 GBK/2: B0A1-F7FE,收录 GB 2312 汉字 6763 个,按原顺序排列
b. GB 13000.1 扩充汉字区包括:
(1) GBK/3: 8140-A0FE,收录 GB 13000.1 中的 CJK(中日韩) 汉字 6080 个
(2) GBK/4: AA40-FEA0,收录 CJK 汉字和增补的汉字 8160 个,CJK 汉字在前,按 UCS 代码大小排列;增补的汉字(包括部首和构件)在后,按《康熙字典》的页码/字位排列 - 图形符号区包括:
a. GB 2312 非汉字符号区,即 GBK/1: A1A1-A9FE,其中除 GB 2312 的符号外,还有 10 个小写罗马数字和 GB 12345 增补的符号,计符号 717 个。
b. GB 13000.1 扩充非汉字区,即 GBK/5: A840-A9A0,BIG-5 非汉字符号、结构符和“○”排列在此区,计符号 166 个。 - 用户自定义区:分为(1)(2)(3)三个小区。
(1) AAA1-AFFE,码位 564 个。
(2) F8A1-FEFE,码位 658 个。
(3) A140-A7A0,码位 672 个。
第(3)区尽管对用户开放,但限制使用,因为不排除未来在此区域增补新字符的可能性。
二、标准库中 string 类的使用
参考网站 cplusplus

string 类是 basic_string 类模板中填入 char 类型的实例化,basic_string 类模板底层是一个顺序表
sting 类的所有成员函数(如长度或大小)及其迭代器是按照字节进行操作,独立于所使用的编码处理字节,所以 string 类是可以用于处理汉字的
1. 构造函数和拷贝构造函数
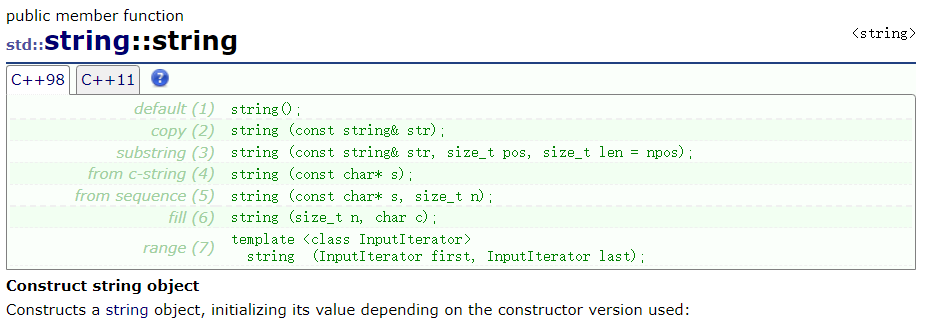
拷贝构造函数和常用的构造函数使用如下:
#include <iostream>
#include <string>
using namespace std;
int main()
{
//默认构造
string s1;
//用字符串构造 s2
//string s2("hello world");
string s2 = "hello world!"; //构造临时变量 + 拷贝构造 -> 直接用字符串构造 s2
//拷贝构造
//string s3(s2);
string s3 = s2;
return 0;
}
2. 迭代器相关的成员函数


rbegin 和 rend 也是如此,普通对象调用时,返回反向迭代器,const 对象调用时,返回 const 反向迭代器
迭代器的使用像指针一样:
#include <iostream>
#include <string>
using namespace std;
//参数是 const 引用
void fun(const string& s)
{
//const 正向迭代器和正向迭代器一样,只是不能修改迭代器指向的内容
string::const_iterator it = s.begin();
while (it != s.end())
{
//++(*it); -error
cout << *it;
++it;
}
cout << endl; //输出 hello world
//const 反向迭代器和反向迭代器一样,只是不能修改迭代器指向的内容
//string::const_reverse_iterator rit = s.rbegin();
auto rit = rbegin(); //类型名太长了,可以使用 auto 自动推导
while (rit != s.rend())
{
//++(*rit); -error
cout << *rit;
++rit;
}
cout << endl; //输出 dlrow olleh
}
int main()
{
string s = "hello world";
//正向迭代器
//begin 返回指向对象中第一个字符的迭代器
//end 返回指向对象中最后一个字符的下一个字符的迭代器,空串时返回值和 begin 相同
string::iterator it = s.begin();
while (it != s.end())
{
cout << *it;
++it;
}
cout << endl; //输出 hello world
//反向迭代器
//rbegin 返回指向对象中反向开始的第一个字符的迭代器
//rend 返回指向对象中反向开始的最后一个字符的下一个字符的迭代器,空串时返回值和 rbegin 相同
string::reverse_iterator rit = s.rbegin();
while (rit != s.rend())
{
cout << *rit;
++rit;
}
cout << endl; //输出 dlrow olleh
fun(s);
return 0;
}
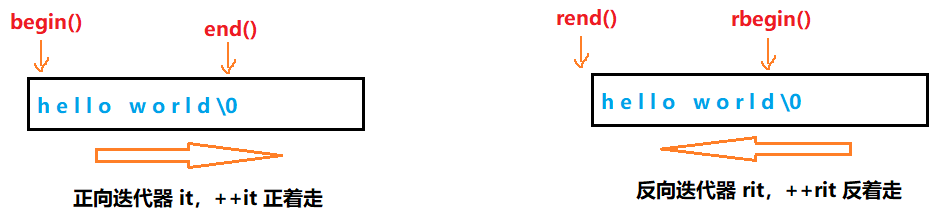
cbegin、cend、crbegin、crend、返回的都是 const 迭代器,只是因为调用 begin 时,有时会返回 const 迭代器,有时不会返回 const 迭代器,为了做区分
3. 容量相关的成员函数

size、length、capacity、reserve、resize 函数使用如下:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s = "hello world!";
//返回 string 类对象的长度,不包括对象数组中的 '\0'
cout << s.size() << endl; //输出 12
cout << s.length() << endl; //输出 12
//返回已为对象数组分配存储容量的大小,不同的平台可能不同
//vs2022 输出15,g++ 4.8.5 输出 12
cout << s.capacity() << endl;
//调整容量大于等于 20,缺省值为 0
//如果参数小于等于当前容量时,容量不变
s.reserve(20);
cout << s.size() << endl; //reserve 不改变对象长度,输出 12
cout << s.capacity() << endl; //vs2022 输出31,g++ 4.8.5 输出 24
//调整对象内容长度为 40,通过尾插 '\0' 使 size 达到 40,容量不够时会扩容
//如果参数小于当前 size 时,容量不会缩小,相当于删除对象内容
s.resize(40);
cout << s << endl; //输出 hello world!
cout << s.size() << endl; //输出 40
cout << s.capacity() << endl; //vs2022 输出47,g++ 4.8.5 输出 48
//增加对象长度时,可以指定尾插的字符
s.resize(60, 'x');
cout << s << endl; //输出 hello world!xxxxxxxxxxxxxxxxxxxx
return 0;
}
4. 访问对象内容相关的成员函数

operator[] 有 const 对象的函数重载,当普通对象调用时,返回的是下标元素的引用,可以读写,当 const 对象调用时,返回的是下标元素的 const 引用,只能读,不能写 `
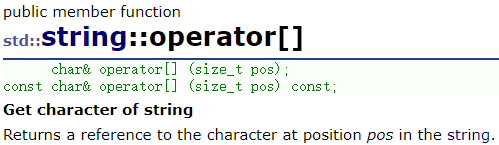
函数使用如下:
#include <iostream>
#include <string>
using namespace std;
void Print(const string& s)
{
//const 对象调用时,只能读不能写
for (int i = 0; i < s.size(); ++i)
{
//++s[i]; -error
cout << s[i];
}
cout << endl;
}
int main()
{
string s = "hello";
//operator[] 返回下标为 i 的元素的引用(别名),下标从 0 开始
//于是便可以像数组一样用下标和 [] 读和写对象内容的数据
for (int i = 0; i < s.size(); ++i)
{
++s[i]; //编译器自动转换为 ++s.operator[](i);
cout << s[i];
}
cout << endl; //输出 ifmmp
//const 对象调用时,只可以读
Print(s); //输出 ifmmp
//at 和 operator[] 的功能类似
//不同点是 at 访问越界时抛异常,operator[] 报断言错误
for (int i = 0; i < s.size(); ++i)
{
--s.at(i);
cout << s.at(i);
}
cout << endl; //输出 hello
//front 返回第一个元素的引用,back 返回最后一个元素的引用
s.front() = 'a';
s.back() = 'z';
cout << s << endl; //输出 aellz
return 0;
}
5. 修改对象内容相关的成员函数

对象中追加字符、字符串或者 string 类对象:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s = "hello";
//向对象中追加字符
s.push_back('*');
cout << s << endl; //输出 hello*
//向对象中追加字符串、string 类对象等
s.append("world");
cout << s << endl; //输出 hello*world
//+= 运算符重载函数可以追加字符、字符串、string 类对象
s += '!';
cout << s << endl; //输出 hello*world!
s += "!!";
cout << s << endl; //输出 hello*world!!!
return 0;
}
insert 和 erase 不推荐经常使用,因为 string 的底层是顺序表,使用 insert 和 erase 可能需要挪动数据,效率较低
insert 和 erase 函数使用如下:
#include <iostream>
#include <string>
using namespace std;
//插入和删除
int main()
{
string s = "hello world";
//在下标为 5 的位置处插入字符串 "xxx"
s.insert(5, "xxx");
cout << s << endl; //输出 helloxxx world
//在最后一个位置处插入 3 个字符 '!'
s.insert(s.size(), 3, '!');
cout << s << endl; //输出 helloxxx world!!!
//从下标为 5 的位置开始删除 3 个字符
s.erase(5, 3);
cout << s << endl; //输出 hello world!!!
//删除下标为 5 的位置开始后的所有字符
s.erase(5);
cout << s << endl; //输出 hello
//删除字符串中的所有字符
s.erase();
cout << s << endl; //输出 换行
return 0;
}
replace 函数也不推荐经常使用,因为可能需要挪动数据,效率较低
replace 和 swap 函数使用如下:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s1 = "hello world";
//将下标从 5 的位置开始的 1 个字符替换为字符串 "xxx"
s1.replace(5, 1, "xxx");
cout << s1 << endl; //输出 helloxxxworld
string s2 = "abcdefg";
s1.swap(s2);
cout << s1 << endl; //输出 abcdefg
cout << s2 << endl; //输出 helloxxxworld
return 0;
}
6. 字符串操作相关的成员函数

c_str 和 substr 函数使用如下:
#include <iostream>
#include <string>
using namespace std;
int main()
{
//返回指向对象中数组首元素的 const char* 指针
string s1 = "hello world";
cout << s1.c_str() << endl; //输出 hello world
//返回对象中下标为 6 开始的 3 个字符构成的对象
string subs1 = s1.substr(6, 3);
cout << subs1 << endl; //输出 wor
//返回对象中下标为 6 开始后的所有字符构成的对象
string subs2 = s1.substr(6);
cout << subs2 << endl; //输出 world
return 0;
}

find 函数是在对象中从 pos 位置开始查找第一个匹配的字符、字符串、string 对象,省略 pos 时,从头开始查找,找到则返回对象中匹配项的起始元素的下标,未找到则返回 npos
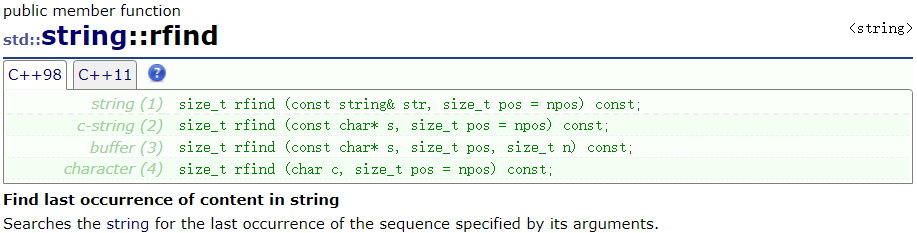
rfind 函数是在对象中从头开始查找 pos 位置之前的最后一个匹配的字符、字符串、string 对象,省略 pos 时,查找整个对象中最后一个匹配项,找到则返回对象中匹配项的起始元素的下标,未找到则返回 npos
npos 表示无符号整形的最大值
static const size_t npos = -1;
find 和 rfind 函数使用如下:
#include <iostream>
#include <string>
using namespace std;
int main()
{
//取出对象 s1 中的协议、域名、资源
string s1 = "https://legacy.cplusplus.com/reference/string/string/find/";
//查找 "://",取出协议
size_t realm = s1.find("://");
if (realm == string::npos)
return 0;
cout << s1.substr(0, realm - 0) << endl; //输出 https
//从域名的第一个字符开始查找 '/',取出域名和资源
size_t url = s1.find('/', realm + 3);
if (url == string::npos)
return 0;
string sub = s1.substr(realm + 3, url - realm - 3);
cout << sub << endl; //输出 legacy.cplusplus.com
cout << s1.substr(url) << endl; //输出 /reference/string/string/find/
//取出文件名的后缀
string s2 = "test.tar.gz.zip";
size_t suffix = s2.rfind(".");
if (suffix == string::npos)
return 0;
cout << s2.substr(suffix) << endl; //输出 .zip
return 0;
}

find_first_of 函数是在对象中从 pos 位置开始查找第一个匹配 字符、字符串、string 对象中的任意一个字符,省略 pos 时,从头开始查找,找到则返回对象中匹配项的起始元素的下标,未找到则返回 npos
find_first_not_of 函数是在对象中从 pos 位置开始查找第一个 不匹配 字符、字符串、string 对象中的任意一个字符,省略 pos 时,从头开始查找,找到则返回对象中匹配项的起始元素的下标,未找到则返回 npos
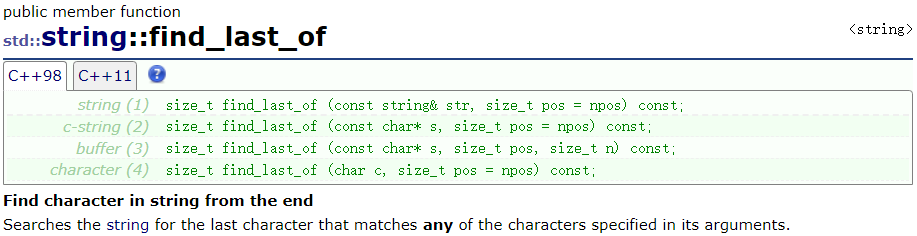
find_last_of 函数是在对象中从头开始查找 pos 位置之前的最后一个匹配的 字符、字符串、string 对象中的任意一个字符,省略 pos 时,查找整个对象中最后一个匹配项,找到则返回对象中匹配项的起始元素的下标,未找到则返回 npos
find_last_not_of 函数是在对象中从头开始查找 pos 位置之前的最后一个 不匹配的 字符、字符串、string 对象中的任意一个字符,省略 pos 时,查找整个对象中最后一个匹配项,找到则返回对象中匹配项的起始元素的下标,未找到则返回 npos
函数使用如下:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s = "I love c++ so much that I can not sleep";
cout << "length: " << s.size() << endl; //输出 length: 39
size_t first = s.find_first_of("starrycat");
cout << first << s[first] << endl; //输出 7c
size_t last = s.find_last_of("starrycat");
cout << last << s[last] << endl; //输出 34s
size_t first_not = s.find_first_not_of("starrycat");
cout << first_not << s[first_not] << endl; //输出 0I
size_t last_not = s.find_last_not_of("starrycat");
cout << last_not << s[last_not] << endl; //输出 38p
return 0;
}
7. sting 类相关的非成员函数

非成员函数 swap 的效率优于成员函数 swap

swap 函数使用如下:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s1 = "hello";
string s2 = "world";
cout << s1 << endl; //输出 hello
cout << s2 << endl; //输出 world
swap(s1, s2); //非成员函数 swap,效率高
s1.swap(s1); //成员函数 swap,效率低
cout << s1 << endl; //输出 hello
cout << s2 << endl; //输出 world
}
其他函数使用如下:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s1;
//>> 运算符重载,以空格或换行做分隔符
cin >> s1; //输入 hello
s1 += '\0';
s1 += '\0';
s1 += '\0';
s1 += " world";
cout << s1.c_str() << endl; //遇到 '\0' 结束,输出 hello
//<< 运算符重载,打印到对象中的 size 位置
cout << s1 << endl; //'\0' 不是可显字符,输出 hello world
string s2;
//获取输入的一行初始化 s2,遇到字符 f 停止,并抛弃界定符 f
//不传最后一个参数时,遇到换行停止,并抛弃换行
getline(cin, s2, 'f'); //hello abcdefghi
cout << s2; //输出 hello abcde
//+ 运算符重载,返回时需要拷贝对象,建议用 +=
string s3 = "hello,";
string s4 = "world";
string s5 = s3 + s4;
cout << s5 << endl; //输出 hello,world
//比较运算符重载
cout << (s3 >= s4) << endl; //输出 0
cout << (s3 == s4) << endl; //输出 0
cout << (s3 <= s4) << endl; //输出 1
return 0;
}
三、vs 和 g++ 下 string 的结构
-
vs2022 输出 15 31 47 70 105,1.5倍扩容
vs 底层对于 string 类包含 4个非静态成员,指针、size、capacity、还有一个 16 个元素的数组,当对象容量小于16 个元素时,浪费指针,当对象容量大于 16 时,在堆上动态开辟足够的空间,用指针指向,并且浪费 16 个元素的数组,所以 31 才是第一次在堆上开辟的空间大小,然后1.5 倍增长
sizeof(string) 是 40 -
g++ 4.8.5 输出 0 1 2 4 8 16 32 64 128,2倍扩容
sizeof(string) 是 8
观察扩容情况:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s;
size_t size = s.capacity();
cout << size << " ";
while (size < 100)
{
s.push_back('*');
if (size != s.capacity())
{
size = s.capacity();
cout << size << " ";
}
}
return 0;
}
四、string 类的模拟实现
string 类常用接口模拟实现:
//test.cpp
#include "string.h"
int main()
{
try
{
starrycat::test_string9();
}
catch (const std::exception& e)
{
cout << e.what() << endl;
}
return 0;
}
//string.h
#define _CRT_SECURE_NO_WARNINGS
#pragma once
#include <iostream>
#include <string>
#include <string.h>
#include <assert.h>
using std::cout;
using std::endl;
namespace starrycat
{
class string
{
public:
//构造函数
//string()
// : _str(new char[1]{ 0 })
// , _size(0)
// , _capacity(0)
//{
//}
//string(const char* s)
// : _size(strlen(s))
//{
// _capacity = _size;
// _str = new char[_capacity + 1];
// strcpy(_str, s);
//}
string(const char* s = "")
: _size(strlen(s))
{
//防止扩容 2 倍时,出现问题
_capacity = _size == 0 ? 3 : _size;
_str = new char[_capacity + 1];
strcpy(_str, s);
}
~string()
{
if (_str != nullptr)
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
}
//拷贝构造 - 深拷贝
string(const string& s)
: _size(s._size)
, _capacity(s._capacity)
{
_str = new char[s._capacity + 1];
memcpy(_str, s._str, s._size + 1);
}
//赋值重载 - 深拷贝
string& operator=(const string& s)
{
//防止自己赋值自己
if (this != &s)
{
//防止开辟空间失败导致原空间被破坏
char* tmp = new char[s._capacity + 1];
//拷贝数据,释放原空间
memcpy(tmp, s._str, s._size + 1);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}
//迭代器
typedef char* iterator;
typedef const char* const_iterator;
//返回指向对象中第一个字符的迭代器
iterator begin()
{
return _str;
}
const_iterator begin() const
{
return _str;
}
//返回指向对象中反向开始的最后一个字符的下一个字符的迭代器
iterator end()
{
return _str + _size;
}
const_iterator end() const
{
return _str + _size;
}
//size
size_t size() const
{
return _size;
}
//capacity
size_t capacity() const
{
return _capacity;
}
//clear
void clear()
{
_str[0] = '\0';
_size = 0;
}
//reserve
void reserve(size_t n)
{
if (n > _capacity)
{
//防止开辟空间失败导致原空间被破坏
char* tmp = new char[n + 1];
//拷贝数据,释放原空间
memcpy(tmp, _str, _size + 1);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
//resize
void resize(size_t n, char c = '\0')
{
//扩容 + 初始化
if (n > _size)
{
reserve(n);
memset(_str + _size, c, n - _size);
}
_size = n;
_str[_size] = '\0';
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
string& push_back(char c)
{
//扩容
if (_size + 1 > _capacity)
{
reserve(2 * _capacity);
}
_str[_size] = c;
++_size;
_str[_size] = '\0';
return *this;
}
string& append(const char* s)
{
size_t len = strlen(s);
//扩容
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, s);
_size += len;
return *this;
}
string& operator+=(char c)
{
push_back(c);
return *this;
}
string& operator+=(const char* s)
{
append(s);
return *this;
}
string& insert(size_t pos, char c)
{
assert(pos <= _size);
//扩容
if (_size + 1 > _capacity)
{
reserve(2 * _capacity);
}
//挪动数据
size_t end = _size + 1;
while (end > pos) //end - 1 >= pos 不行
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = c;
++_size;
return *this;
}
string& insert(size_t pos, const char* s)
{
assert(pos <= _size);
size_t len = strlen(s);
//扩容
if (_size + len > _capacity)
{
reserve(_size + len);
}
//挪动数据
size_t end = _size + len;
while (end > pos + len - 1) //end - len >= pos 不行
{
_str[end] = _str[end - len];
--end;
}
//拷贝数据
strncpy(_str + pos, s, len);
_size += len;
return *this;
}
string& erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
//len 大于等于 pos 位置开始的字符串长度,或者为 npos
if (len >= _size - pos)
{
_str[pos] = '\0';
_size = pos;
}
else
{
//挪动数据
strcpy(_str + pos, _str + pos + len);
_size -= len;
_str[_size] = '\0';
}
return *this;
}
string& replace(size_t pos, size_t len, const char* s)
{
assert(pos <= _size);
size_t lenS = strlen(s);
//扩容
if (_size + lenS - len > _capacity)
{
reserve(_size + lenS);
}
erase(pos, len);
insert(pos, s);
return *this;
}
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
const char* c_str() const
{
return _str;
}
size_t find(char c, size_t pos = 0) const
{
assert(pos < _size);
for (int i = pos; i < _size; ++i)
{
if (_str[i] == c)
return i;
}
return npos;
}
size_t find(const char* s, size_t pos = 0) const
{
assert(pos < _size);
const char* p = strstr(_str + pos, s);
if (p == nullptr)
return npos;
else
return p - _str;
}
size_t rfind(char c, size_t pos = npos) const
{
int i = pos < _size ? pos : _size - 1;
while (i >= 0)
{
if (_str[i] == c)
return i;
--i;
}
return npos;
}
size_t rfind(const char* s, size_t pos = npos) const
{
const char* ret = nullptr;
const char* p = strstr(_str, s);
while (p != nullptr && p - _str <= pos)
{
ret = p;
p = strstr(p + 1, s);
}
if (ret == nullptr)
return npos;
else
return ret - _str;
}
string substr(size_t pos, size_t len = npos) const
{
assert(pos < _size);
size_t capacity = len >= _size - pos ? _size - pos : len;
char* tmp = new char[capacity + 1];
if (len >= _size - pos)
strcpy(tmp, _str + pos);
else
strncpy(tmp, _str + pos, len);
tmp[len] = '\0';
return string(tmp);
}
string operator+(const string& s) const
{
string tmp = *this;
tmp += s._str;
return tmp;
}
bool operator==(const string& s) const
{
return strcmp(_str, s._str) == 0;
}
bool operator!=(const string& s) const
{
return !(*this == s);
}
bool operator<(const string& s) const
{
return strcmp(_str, s._str) < 0;
}
bool operator<=(const string& s) const
{
return (*this < s) || (*this == s);
}
bool operator>(const string& s) const
{
return !(*this <= s);
}
bool operator>=(const string& s) const
{
return !(*this < s);
}
private:
char* _str;
size_t _size;
size_t _capacity;
static const size_t npos;
//只有 const int 类型的静态成员可以这样写
//static const int N = 10;
};
const size_t string::npos = -1;
std::istream& operator>>(std::istream& in, string& s)
{
char c;
char buffer[128];
int index = 0;
c = in.get();
while (c != ' ' && c != '\n')
{
//s += c;
buffer[index++] = c;
if (index == 127)
{
buffer[index] = '\0';
s += buffer;
index = 0;
}
c = in.get();
}
if (index > 0)
{
buffer[index] = '\0';
s += buffer;
}
return in;
}
std::ostream& operator<<(std::ostream& out, const string& s)
{
for (auto e : s)
{
out << e;
}
return out;
}
//string 测试
void test_string1()
{
//构造
string s1;
string s2("hello world");
//拷贝构造
string s3 = s2;
//赋值
string s4;
s4 = s3;
cout << s1.c_str() << endl; //输出 换行
cout << s2.c_str() << endl; //输出 hello world
cout << s3.c_str() << endl; //输出 hello world
cout << s4.c_str() << endl; //输出 hello world
}
//测试迭代器
void test_string2()
{
string s1 = "hello world";
string::iterator it = s1.begin();
while (it != s1.end())
{
++(*it);
cout << *it;
++it;
}
cout << endl; //输出 ifmmp!xpsme
const string s2 = s1;
string::const_iterator cit = s2.begin();
while (cit != s2.end())
{
cout << *cit;
++cit;
}
cout << endl; //输出 ifmmp!xpsme
}
//容量相关
void test_string3()
{
string s = "hello world";
cout << s.size() << endl; //输出 11
cout << s.capacity() << endl; //输出 11
cout << s.c_str() << endl; //输出 hello world
s.reserve(15);
cout << s.size() << endl; //输出 11
cout << s.capacity() << endl; //输出 15
cout << s.c_str() << endl; //输出 hello world
s.resize(20, 'x');
cout << s.size() << endl; //输出 20
cout << s.capacity() << endl; //输出 20
cout << s.c_str() << endl; //输出 hello worldxxxxxxxxx
}
void test_string4()
{
string s1 = "hello world";
for (int i = 0; i < s1.size(); ++i)
{
cout << s1[i];
}
cout << endl; //输出 hello world
const string s2 = s1;
for (int i = 0; i < s2.size(); ++i)
{
cout << s2[i];
}
cout << endl; //输出 hello world
}
void test_string5()
{
string s1 = "hello world";
s1.push_back('!');
cout << s1.c_str() << endl; //输出 hello world!
s1.append("!!");
cout << s1.c_str() << endl; //输出 hello world!!!
string s2 = "hello world";
s2 += '!';
cout << s2.c_str() << endl; //输出 hello world!
s2 += "!!";
cout << s2.c_str() << endl; //输出 hello world!!!
}
void test_string6()
{
string s1 = "123456";
s1.insert(0, 'a');
cout << s1.c_str() << endl; //输出 a123456
s1.insert(3, ' ');
cout << s1.c_str() << endl; //输出 a12 3456
s1.insert(s1.size(), 'a');
cout << s1.c_str() << endl; //输出 a12 3456a
string s2 = "123456";
s2.insert(0, "000");
cout << s2.c_str() << endl; //输出 000123456
s2.insert(3, "aaa");
cout << s2.c_str() << endl; //输出 000aaa123456
s2.insert(s2.size(), "000");
cout << s2.c_str() << endl; //输出 000aaa123456000
s2.erase(0, 3);
cout << s2.c_str() << endl; //输出 aaa123456000
s2.erase(5, 30);
cout << s2.c_str() << endl; //输出 aaa12
s2.erase(2);
cout << s2.c_str() << endl; //输出 aa
}
void test_string7()
{
string s1 = "hello world";
string s2 = s1;
s1.replace(5, 1, "%20");
cout << s1.c_str() << endl; //输出 hello%20world
cout << s2.c_str() << endl; //输出 hello world
s1.swap(s2);
cout << s1.c_str() << endl; //输出 hello world
cout << s2.c_str() << endl; //输出 hello%20world
}
void test_string8()
{
//取出对象 s 中的协议、域名、资源
string s1 = "https://legacy.cplusplus.com/reference/string/string/find/";
//查找 "://",取出协议
size_t realm = s1.find("://");
cout << s1.substr(0, realm) << endl; //输出 https
//从域名的第一个字符开始查找 '/',取出域名和资源
size_t url = s1.find('/', realm + 3);
string sub = s1.substr(realm + 3, url - realm - 3);
cout << sub << endl; //输出 legacy.cplusplus.com
cout << s1.substr(url) << endl; //输出 /reference/string/string/find/
//取出文件名的后缀
string s2 = "test.tar.gz.zip";
size_t suffix = s2.rfind(".");
cout << s2.substr(suffix) << endl; //输出 .zip
}
void test_string9()
{
string s1 = "hello";
string s2 = s1 + " world";
cout << s2.c_str() << endl; //输出 hello world
cout << (s1 == s2) << endl; //输出 0
cout << (s1 < s2) << endl; //输出 1
cout << (s1 > s2) << endl; //输出 0
string s3;
std::cin >> s3; //输入 hello world
cout << s3 << endl; //输出 hello
}
}