论文地址:https://arxiv.org/pdf/2304.02643.pdf
项目地址:Segment Anything | Meta AI (segment-anything.com)
SAM贡献:
1.SA任务:提出了提示图像分割任务,在给定任何图像分割提示的情况下返回一个有效的分割掩码(mask),提示内容包括图像空间信息(点、框)或者相关文本信息。
2.SA-1B数据集:采用一种高效的数据收集方法(data engine),建立了到目前为止最大图像分割数据集。数据收集方法包括三个步骤:手工、半自动、全自动。
3.SAM模型:建立和训练一种可用于提示工程的预训练的图像分割基础模型,可在one-shot和few-shot场景应用新分布的图像数据。模型支持灵活的提示,在实时中计算掩码以允许交互使用,并且具有歧义意识。
SA任务:
任务定义:给定任何提示的有效图像分割mask。提示可以是一组前景/背景点,一个粗略的框或蒙版,自由格式的文本,或者更一般来说,任何指示图像中分割内容的信息,(论文中实现的有点、框和文本)。“有效”掩码意味着即使提示是不明确的,也可以生成与该提示相关的多个mask(至少一个),(比如给出鸵鸟眼睛的提示,模型可以给出鸵鸟头、鸵鸟上半部分身体、鸵鸟全身的结果)。
预训练:提示分割任务提出了一种自然的预训练算法,该算法为每个训练样本模拟一系列提示(例如,点、框、掩码),并将模型的掩码预测与基本事实进行比较。
zero-shot 任务迁移:在新的数据集上可以直接使用,不需要进一步的训练。
相关任务:提示图像分割包含很多图像分割任务,比如实例分割、语义分割、全景分割等。
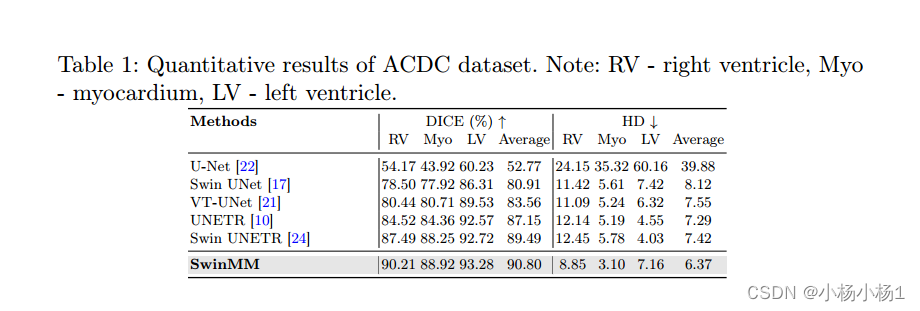
SAM模型:
SAM模型包含三个部分:图像编码器、提示编码器和掩码解码器。框架图如下图所示。
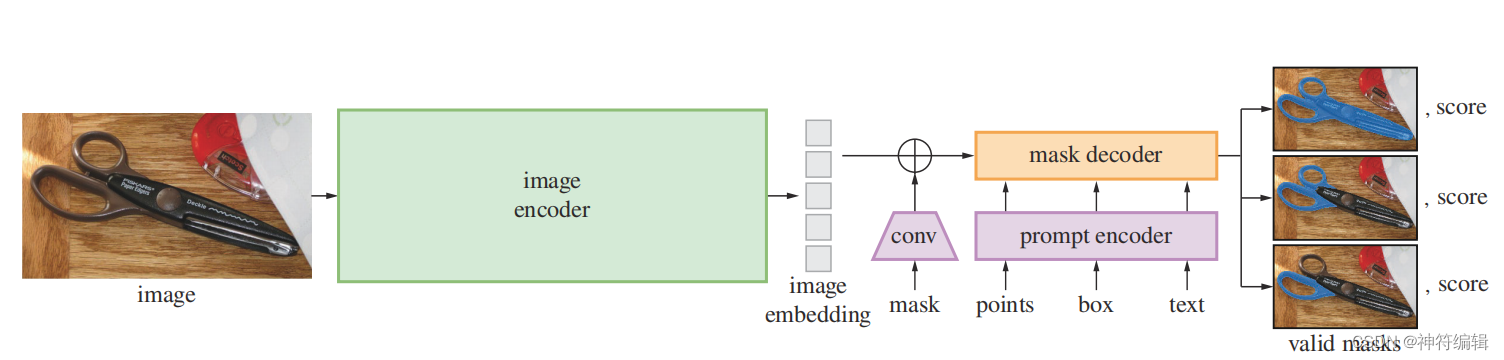
图像编码器:图像编码器每个图像运行一次,可以在提示编码器之前应用。图像编码器采用的是预训练的视觉编码器(ViT)。
提示编码器:提示分为两种,稀疏提示(点、框和文本),密集提示(mask)。对于点和框,通过位置编码进行表示;对于文本,采用CLIP的文本编码器。对于稀疏提示,需要学习他们的嵌入向量。对于mask,通过卷积神经层得到的嵌入和原图像的嵌入进行对应元素点加。
掩码解码器:掩码解码器有效地将图像嵌入、提示嵌入和输出令牌映射到掩码。采用了对Transformer解码器块的修改,然后是动态掩码预测头。改进的解码器块在两个方向上使用提示自注意和交叉注意(提示到图像嵌入,反之亦然)来更新所有嵌入。在运行两个块之后,对图像嵌入进行上采样,MLP将输出标记映射到动态线性分类器,然后该分类器计算每个图像位置的掩码前景概率。
解决模糊(歧义):对于一个输出,如果给出一个模糊的提示,该模型将平均多个有效掩码。为了解决这个问题,进行了模型修改,以预测单个提示符的多个输出掩码。3个掩码输出足以解决大多数常见情况(嵌套掩码通常最多有三个深度:整体,部分和子部分)。在训练期间,只在mask上进行最小损失。为了对掩码进行排序,该模型预测每个掩码的置信度分数(即估计的借据)。
性能:给定预先计算的图像嵌入,提示编码器和掩码解码器在web浏览器中运行,在CPU上,大约50ms。这种运行时性能支持模型的无缝、实时交互式提示。
损失和训练:损失和训练。使用使用的焦损失和骰子损失的线性组合来监督掩模预测。使用几何提示的混合来训练可提示的分割任务。通过在每个掩码中随机抽取11轮提示来模拟交互式设置,从而使SAM无缝地集成到的数据引擎中。