文章目录
- 一、redis高可用性概述
- 二、主从复制
- 2.1 主从复制
- 2.2 数据同步的方式
- 2.2.1 全量数据同步
- 2.2.2 增量数据同步
- 2.3 实现原理
- 2.3.1 服务器 RUN ID
- 2.3.2 复制偏移量 offset
- 2.3.3 环形缓冲区
- 三、哨兵模式
- 3.1 原理
- 3.2 配置
- 3.3 流程
- 3.4 使用
- 3.5 缺点
- 四、cluster集群
- 4.1 原理
- 4.2 特征
- 4.3 流程
- 4.4 缺点
- 4.5 故障转移
- 4.5.1 故障检测
- 4.5.2 故障转移
- 4.6 集群配置和管理
- 4.6.1 主要命令
- 4.6.2 创建集群
- 4.6.3 查看集群配置信息
- 4.6.4 测试集群
- 4.6.5 扩容
- 4.6.6 缩容
一、redis高可用性概述
1、高可用是分布式的概念。
Redis的高可用性是指在Redis集群中,当主节点宕机了,通过切换备用节点顶替它继续运行,保持系统正常运行且数据可靠性不受影响。
2、通过实现Redis的高可用性,可以提供以下几个主要优势:
1)避免单点故障:通过配置和设置多个Redis节点,如果其中一个节点发生故障,其他节点可以接替工作,避免了单点故障对整个系统的影响。
2)数据冗余和复制:通过数据的复制和持久化备份,Redis能够在主节点出现故障时,自动切换到备用节点,并恢复数据,确保数据的持久性和可用性。
3)故障自动检测和故障转移:Redis的高可用方案通常具备故障检测和自动故障转移的功能,能够监控节点的健康状态,并在节点故障时自动将从节点升级为主节点。
3、因此,redis的高可用主要完成以下工作:
1)数据同步。主节点和从节点(备用节点)之间的数据需要进行同步。
2)主从切换。若主节点宕机,需要有一种机制可以切换从节点变成主节点。
二、主从复制
2.1 主从复制
主从复制是数据同步方式,解决了单点故障的问题,但不能保证高可用(是高可用的基础)。主要用来实现 redis 数据的可靠性,防止主 redis 所在磁盘损坏,造成数据永久丢失。
主从之间采用异步复制的方式,以及采用读写分离的方式,主节点(master)可以进行读写操作,从节点(replica)一般是只读。也就是说,所有的数据修改只在主节点上进行,然后将最新的数据同步给节点,这样就使得主从服务器的数据是一致的。
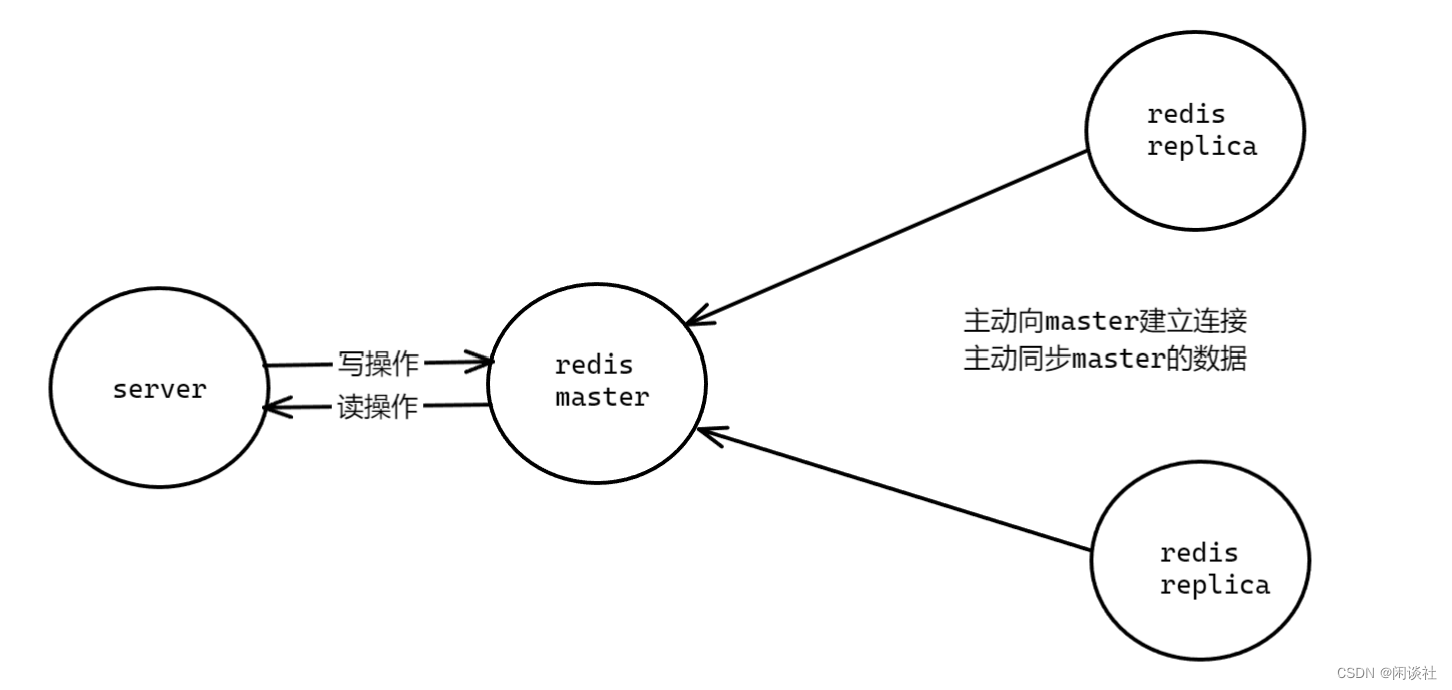
需要注意的是:
1)主从复制无法提供高可用和数据保护能力,因为主节点发生故障时,需要手动进行故障转移。
2)从节点主动向主节点建立连接,从节点主动同步主节点的数据。
2.2 数据同步的方式
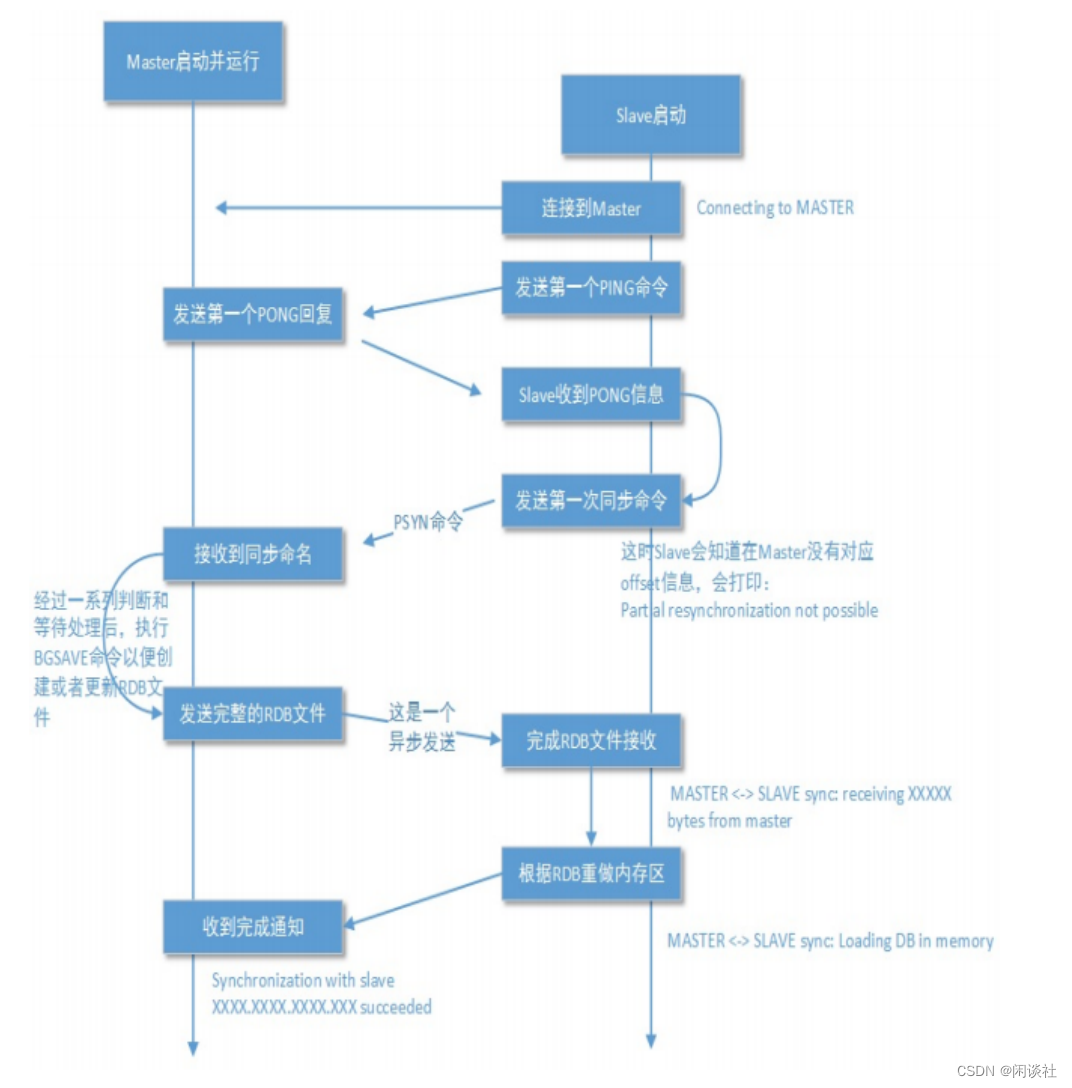
2.2.1 全量数据同步
1)全量数据同步是在从节点刚加入复制集群或者需要进行完整数据更新时执行的同步过程。
2)它的目标是将主节点上的所有数据完整地同步到从节点。全量数据同步的过程是将主节点上的所有内存数据通过快照(RDB文件)方式发送给从节点,从节点接收到快照后将其加载到自己的数据库中。
3)全量数据同步会消耗较大的网络带宽和时间,特别是在数据集较大的情况下。并且在全量数据同步过程中,从节点无法处理外部的读取请求,因为它正在重新加载大量的数据。
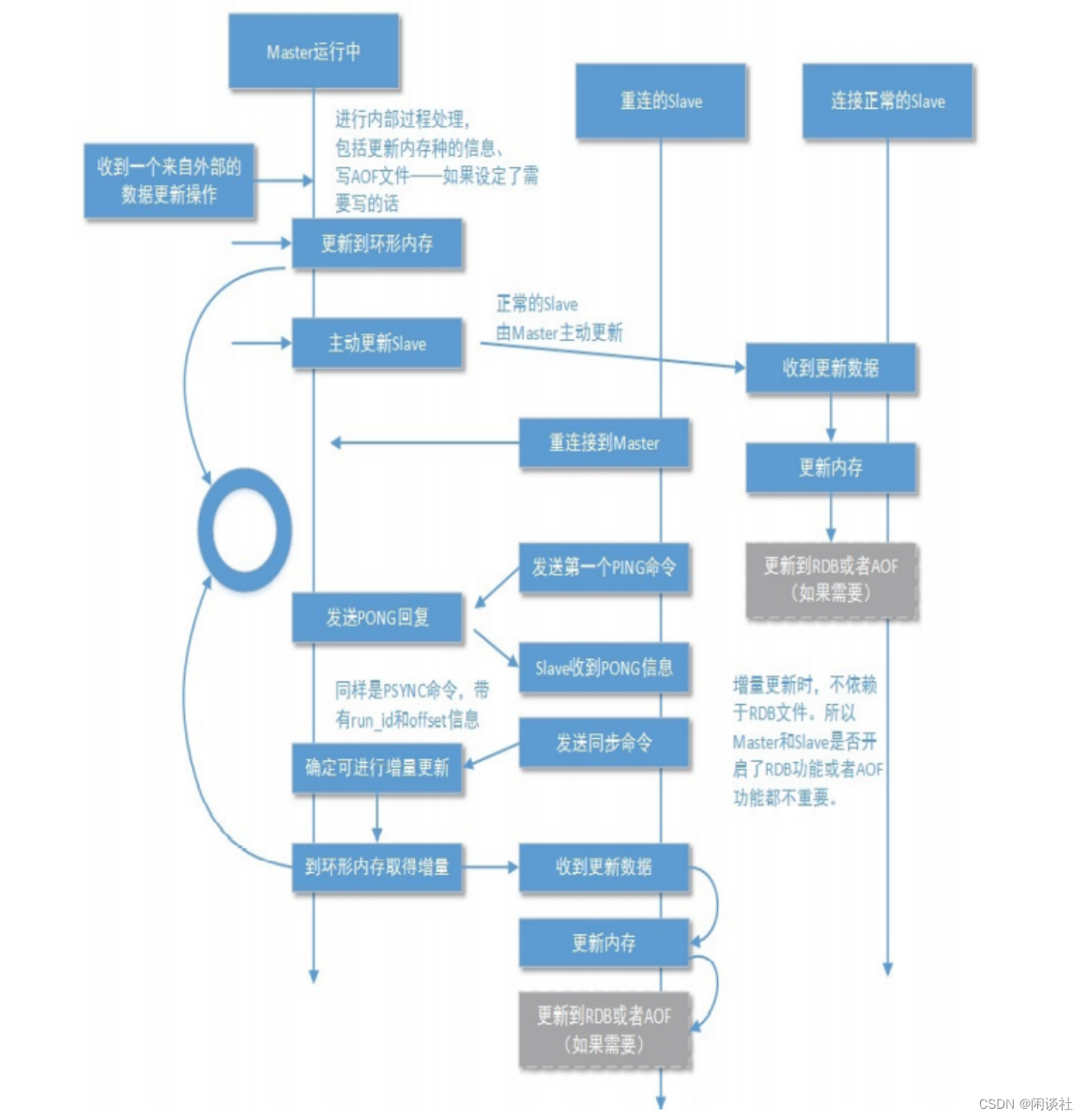
2.2.2 增量数据同步
1)增量数据同步是在全量数据同步完成后,用于保持主从节点之间数据的一致性。
2)它通过记录主节点上的增量写命令(例如AOF日志文件)并将其发送给从节点来实现。增量数据同步的过程是在主节点上记录所有的写操作,并将这些操作记录传输给从节点,从节点接收到后执行这些操作以保持与主节点的数据一致。
3)增量数据同步具有实时性,可以减少数据同步的延迟
从数据库会记录一个偏移量offset(即记录同步到哪里了)。当从数据库断开重连,主数据库补发丢失数据到从数据库。此时如果offset在环形缓冲区当中,从数据库就会将offset后面的那部分数据同步过来,增量同步;如果offset不在环形缓存区中,说明数据过期太久,就会全量同步,把主数据库内部所有数据都同步过来。
2.3 实现原理
主从复制主要由环形缓冲区、复制偏移量、RUN ID三个部分组成。
2.3.1 服务器 RUN ID
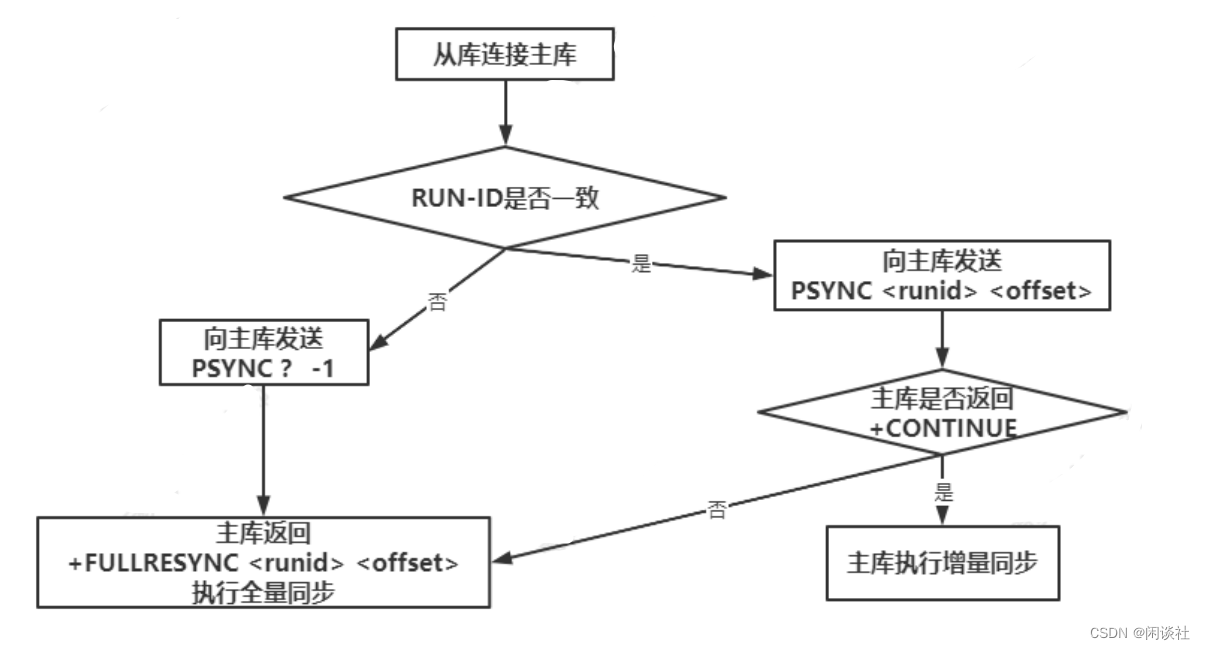
RUNID用于构建主从的关系。无论主库还是从库都有自己的 RUN ID , RUN ID 启动时自动产生, RUN ID 由 40 个随机的十六进制字符组成。
当从库对主库初次复制时,主库将自身的 RUN ID 传送给从库,从库会将 RUN ID 保存。
当从库断线重连主库时,从库将向主库发送之前保存的 RUN ID :
∙
\bullet
∙ 从库 RUN ID 和主库 RUN ID 一致,说明从库断线前复制的就是当前的主库;主库尝试执行增量同步操作;
∙
\bullet
∙ 若不一致,说明从库断线前复制的主库并不时当前的主库,则主库将对从库执行全量同步操作。
2.3.2 复制偏移量 offset
主从都会维护一个复制偏移量:
∙
\bullet
∙ 主库向从库发送 N 个字节的数据时,将自己的复制偏移量上加 N;
∙
\bullet
∙ 从库接收到主库发送的 N 个字节数据时,将自己的复制偏移量加上 N。
通过比较主从偏移量得知主从之间数据是否一致;偏移量相同,则数据一致;偏移量不同,则数据不一致。
2.3.3 环形缓冲区
本质:固定长度先进先出队列。
当因某些原因(网络抖动或从库宕机)从库与主库断开连接,避免重新连接后开始全量同步,在主库设置了一个环形缓冲区;该缓冲区会在从库失联期间累计主库的写操作;当从库重连,会发送自身的复制偏移量到主库,主库会比较主从的复制偏移量“
∙
\bullet
∙ 若从库 offset 还在复制积压缓冲区中,则进行增量同步;
∙
\bullet
∙ 否则,主库将对从库执行全量同步。
三、哨兵模式
3.1 原理
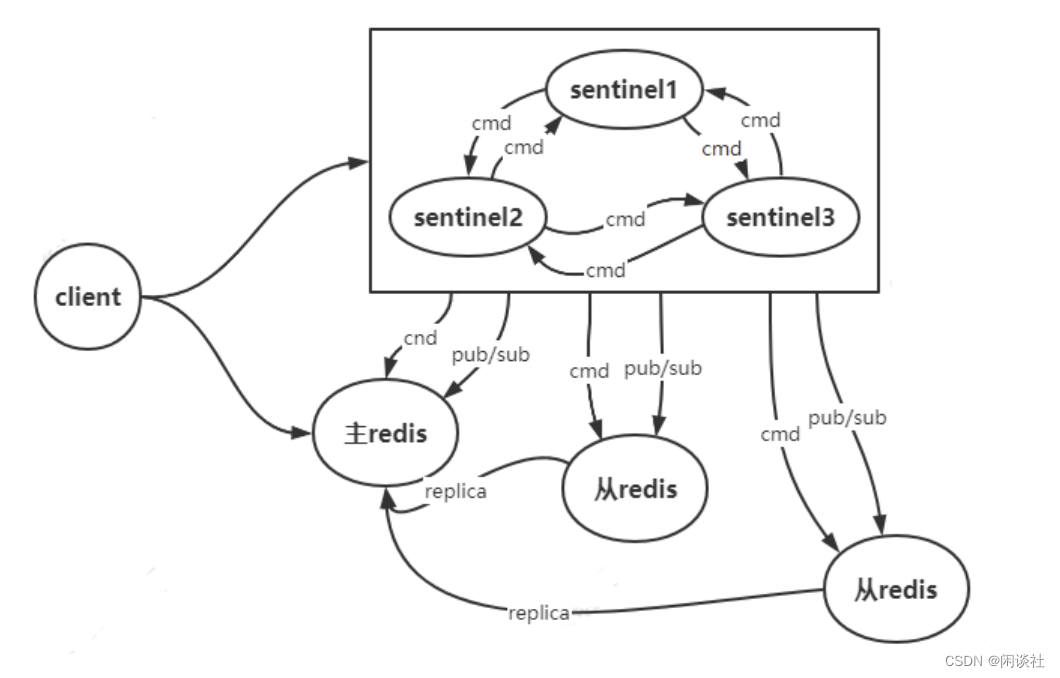
哨兵模式是 Redis 可用性的解决方案,它由一个或多个 sentinel实例构成 sentinel 系统。该系统通过 ping-pong 心跳检测的方法监视任意多个主库以及这些主库所属的从库。当主库处于下线状态,自动将该主库所属的某个从库升级为新的主库,从而实现高可用。
客户端来连接集群时,会首先连接 sentinel,通过 sentinel 来查询主节点的地址,然后再连接主节点进行数据交互。当主节点发生故障时,客户端会重新向 sentinel 索要主库地址,sentinel会将最新的主库地址告诉客户端。通过这样客户端无须重启即可自动完成节点切换。
Sentinel 节点个数是奇数,不存储数据,用来监控节点的状态和选举主节点,只提供一个数据节点服务。Sentinel 节点不仅监控 Redis 主从节点,同时还互相监控,形成多哨兵模式。
Sentinel 模式当中涉及的多个选举流程采用的是 raft 一致性算法。
3.2 配置
# sentinel.cnf
# sentinel 只需指定检测主节点就行了,通过主节点自动发现从节点
sentinel monitor mymaster 127.0.0.1 6379 2
# 判断主观下线时长
sentinel down-after-milliseconds mymaster 30000
# 指定可以有多少个Redis服务同步新的主机,一般而言,这个数字越小同步时间越长,而越大,则对网络资源要求越高
sentinel parallel-syncs mymaster 1
# 指定故障切换允许的毫秒数,超过这个时间,就认为故障切换失败,默认为3分钟
sentinel failover-timeout mymaster 180000
3.3 流程
1)主观下线
sentinel 会以每秒一次的频率向所有节点(其他sentinel、主节点、以及从节点)发送 ping 消息,然后通过接收返回判断该节点是否下线。如果在配置指定 down-after-milliseconds 时间内则被判断为主观下线。
2)客观下线
当一个 sentinel 节点将一个主节点判断为主观下线之后,为了确认这个主节点是否真的下线,它会向其他 sentinel 节点进行询问,如果收到一定数量(半数以上)的已下线回复,sentinel 会将主节点判定为客观下线,并通过领头 sentinel 节点对主节点执行故障转移。
3)故障转移
主节点被判定为客观下线后,开始领头 sentinel 选举。按照谁发现谁处理的原则选举领头 sentinel,需要半数以上的 sentinel 支持。选举领头 sentinel 后,开始执行对主节点故障转移:
∙
\bullet
∙ 从从节点中选举一个从节点作为新的主节点
∙
\bullet
∙ 通知其他从节点复制连接新的主节点
∙
\bullet
∙ 若故障主节点重新连接,将作为新的主节点的从节点
3.4 使用
1)连接哨兵节点 —— 连接一个哨兵节点,并且获取主节点信息:SENTINEL GET-MASTER-ADDR-BY-NAME 。
2)获取主节点地址并连接 —— 验证当前获取的主节点:ROLE 或者 INFO REPLICATION。
3)发起发布订阅连接,监听主节点迁移信息 —— 为当前连接的哨兵节点,添加发布订阅(PUB/SUB)连接,并且订阅 +switch-master 频道,以此互相感知,互相连接,组成哨兵集群。
3.5 缺点
redis 采用异步复制的方式,意味着当主节点挂掉时,从节点可能没有收到全部的同步消息,这部分未同步的消息将丢失。如果主从延迟特别大,那么丢失可能会特别多。sentinel 无法保证消息完全不丢失,但是可以通过配置来尽量保证少丢失。
# 主库必须有一个从节点在进行正常复制,否则主库就停止对外
写服务,此时丧失了可用性
min-slaves-to-write 1
# 这个参数用来定义什么是正常复制,该参数表示如果在10s内
没有收到从库反馈,就意味着从库同步不正常;
min-slaves-max-lag 10
总结来说:
1)部署麻烦:哨兵模式的配置相对复杂,需要管理和维护多个哨兵节点以及与它们关联的 Redis 服务器。调试和故障排除也可能变得更加困难。
2)数据一致性:哨兵模式下的故障转移是异步进行的,这意味着在发生主服务器故障时,可能会有一段时间内的数据丢失。因此,在一些对数据一致性要求非常高的场景下,哨兵模式可能无法满足需求。
3)难以在线扩容的缺点,Redis的容量受限于单机配置
4)延迟增加:当主服务器故障时,哨兵节点需要通过选举机制选择新的主服务器,并通知其他从服务器切换到新的主服务器。这个过程需要时间(至少十几秒),会导致系统的延迟增加。
5)单点故障:哨兵节点是集群的核心,,它们负责监控主服务器和从服务器的状态,并执行故障转移操作。然而,如果哨兵节点本身发生故障,整个系统的可用性将会受到影响。
四、cluster集群
4.1 原理
Redis cluster 通过将数据库分散存储到多个节点上来平衡各个节点的负载压力,实现了 Redis 的分布式存储。
通过分布式一致性hash算法crc(key)%16384,将所有数据划分为 16384(
2
14
2^{14}
214)个槽位,每个redis 节点负责其中一部分槽位。cluster 集群是一种去中心化的集群方式;
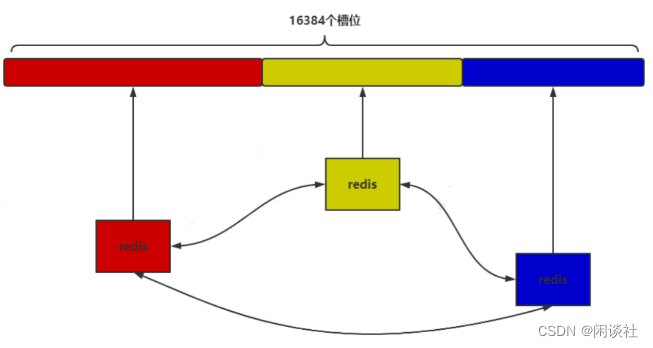
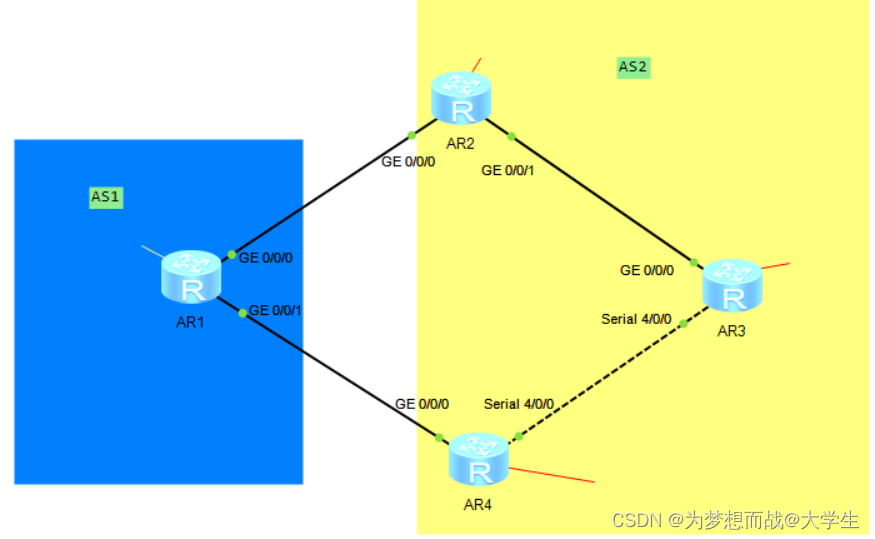
如图,该集群由三个 redis 节点组成,每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样。这三个节点相互连接组成一个对等的集群,它们之间通过一种特殊的二进制协议交互集群信息。
当 redis cluster 的客户端来连接集群时,会得到一份集群的槽位配置信息。这样当客户端要查找某个 key 时,可以直接定位到目标节点。
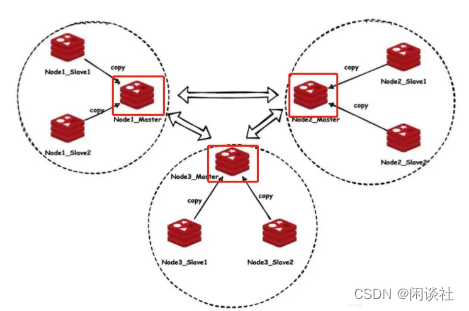
客户端为了可以直接定位(对 key 通过 crc16 进行 hash 再对
2
14
2^{14}
214取余 crc16(key)% 16384)某个具体的 key 所在节点,需要缓存槽位相关信息,这样才可以准确快速地定位到相应的节点。同时因为可能会存在客户端与服务器存储槽位的信息不一致的情况,还需要纠正机制(比如通过返回 -MOVED 3999 127.0.0.1:6479 ,客户端收到后需要立即纠正本地的槽位映射表)来实现槽位信息的校验调整。
另外,redis cluster 的每个节点会将集群的配置信息持久化到配置文件中,这就要求确保配置文件是可写的,而且尽量不要依靠人工修改配置文件。
4.2 特征
1)去中心化,主节点关系对等
2)解决了数据扩容
3)客户端与服务端缓存槽位信息,以服务端为准,客户节点缓存主要为了避免连接切换
4)可人为迁移数据
5)主节点处理读写命令
4.3 流程
1)连接集群中任意一个节点
2)若数据不在该节点,将收到连接切换的命令,继而连接到目标节点
3)故障转移(主节点下移)
∙
\bullet
∙ 集群结点间互相监控,交换节点的状态信息
∙
\bullet
∙ 若某主节点下线,将会被其他主节点标记下线
∙
\bullet
∙ 接着从下线主节点的从节点中选择一个数据最新的从节点作为主节点
∙
\bullet
∙ 从节点继承下线主节点的槽位信息,并广播该消息给集群中的其他节点
4.4 缺点
主从异步复制在故障转移时仍存在数据丢失的问题
4.5 故障转移
cluster 集群中节点分为主节点和从节点,其中主节点用于处理槽,而从节点则用于复制该主节点,并在主节点下线时,代替主节点继续处理命令请求。
4.5.1 故障检测
集群中每个节点都会定期地向集群中的其他节点发送 ping 消息,如果接收 ping 消息的节点没有在规定时间内回复 pong消息,那么这个没有回复 pong消息的节点会被标记为 PFAIL(probable fail)。
集群中各个节点会通过互相发送消息的方式来交换集群中各个节点的状态信息;如果在一个集群中,半数以上负责处理槽的主节点都将某个主节点 A 报告为疑似下线,那么这个主节点 A将被标记为下线( FAIL );标记主节点 A 为下线状态的主节点会广播这条消息,其他节点(包括A节点的从节点)也会将A节点标识为 FAIL;
4.5.2 故障转移
当从节点发现自己的主节点进入 FAIL 状态,从节点将开始对下线主节点进行故障转移:
∙
\bullet
∙ 从数据最新的从节点中选举为主节点;
∙
\bullet
∙ 该从节点会执行 replica no one 命令,称为新的主节点;
∙
\bullet
∙ 新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己;
∙
\bullet
∙ 新的主节点向集群广播一条 pong 消息,这条 pong 消息可以让集群中的其他节点立即知道这个节点已经由从节点变成主节点,并且这个主节点已经接管了之前下线的主节点;
∙
\bullet
∙ 新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移结束
4.6 集群配置和管理
4.6.1 主要命令
redis-cli --cluster help
# 创建集群
create <ip>:<port>
--cluster-replicas <num> # 创建集群的同时,为每个主节点配备的从节点个数
# 查看集群的信息,群中任意节点地址作为参数,后面同理
info <ip>:<port>
# 检查集群的配置
check <ip>:<port>
# 重分片,将指定数量的槽从源节点迁移至目标节点,由目标节点负责迁移的槽和槽中数据
reshared <ip>:<port>
--cluster-from # 源节点的ID
--cluster-to # 目标节点的ID
--cluster-slots <num> # 需要迁移的槽数量
# 添加节点,添加新节点 new 集群 existing,默认添加主节点
add-node <new_host>:<port> <existing_host>:<port>
# 添加从节点,需要以下两个子命令
--cluster-slave
--cluster-master-id <id> # 设置从节点要复制的主节点
# 移除节点
del-node <ip>:<port> <id>
4.6.2 创建集群
zxm@ubuntu:~/cluster-example$ redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
4.6.3 查看集群配置信息
zxm@ubuntu:~/cluster-example$ redis-cli --cluster check 127.0.0.1:7001
127.0.0.1:7001 (0456481a...) -> 1 keys | 6461 slots | 1 slaves.
127.0.0.1:7002 (2b83d979...) -> 1 keys | 4961 slots | 1 slaves.
127.0.0.1:7003 (da48c6b4...) -> 0 keys | 4962 slots | 1 slaves.
[OK] 2 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 127.0.0.1:7001)
M: 0456481a2e18b0ec97ad8173dd0352f890d39659 127.0.0.1:7001
slots:[0-5961],[10923-11421] (6461 slots) master
1 additional replica(s)
S: 78d4179ab020052fbc4197d4d7867607c3787d27 127.0.0.1:7006
slots: (0 slots) slave
replicates da48c6b4d48ae37d6e8ac6b1e12e9e2831f484e2
S: 96d453c5607eef91ce068f0c09193877a1cf3346 127.0.0.1:7004
slots: (0 slots) slave
replicates 0456481a2e18b0ec97ad8173dd0352f890d39659
S: 1e8d9da3b8649c3b52ef407d031efbb11bcc56c1 127.0.0.1:7005
slots: (0 slots) slave
replicates 2b83d9798821b0e2b1353c8b83da17e018b2b754
M: 2b83d9798821b0e2b1353c8b83da17e018b2b754 127.0.0.1:7002
slots:[5962-10922] (4961 slots) master
1 additional replica(s)
M: da48c6b4d48ae37d6e8ac6b1e12e9e2831f484e2 127.0.0.1:7003
slots:[11422-16383] (4962 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
4.6.4 测试集群
#集群模式主从节点对等,可从任意节点进入。
# 虽然从7005进入,但是crc16计算后,应分配在7002节点,切换
zxm@ubuntu:~/cluster-example$ redis-cli -c -h 127.0.0.1 -p 7005
127.0.0.1:7005> set zxm 1
-> Redirected to slot [9010] located at 127.0.0.1:7002
OK
# 虽然从7005进入,但是zxm的值在7002节点,切换
zxm@ubuntu:~/cluster-example$ redis-cli -c -h 127.0.0.1 -p 7005
127.0.0.1:7005> get zxm
-> Redirected to slot [9010] located at 127.0.0.1:7002
"1"
4.6.5 扩容
先添加节点,再分配槽位。
# 1,创建节点文件
cp -R 7001 7007
cd 7007
mv 7001.conf 7007.conf
rm 7001.log dump.rdb nodes-7001.conf
sed -i "s/7001/7007/g" 7007.conf
cd ..
cp -R 7007 7008
cd 7008
mv 7007.conf 7008.conf
sed -i "s/7007/7008/g" 7008.conf
cd ..
redis-server 7007/7007.conf
redis-server 7008/7008.conf
# 2, 添加节点
# 添加主节点,新添加的节点默认作为主节点
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001
# 添加从节点
redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7001 --cluster-slave --cluster-master-id 0456481a2e18b0ec97ad8173dd0352f890d39659
# 3,分配槽位
# 重分片,将主节点 7001 的 1000 个槽迁移至新的主节点 7007
redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from 0456481a2e18b0ec97ad8173dd0352f890d39659 --cluster-to 9f3d34828e1eb41214c158a142c350ca3f604487 --cluster-slots 1000
4.6.6 缩容
先移动槽位,再删除节点.
# 1,移动槽位
# 将主节点 7007 的所有槽迁移至主节点 7001
redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from 9f3d34828e1eb41214c158a142c350ca3f604487 --cluster-to 0456481a2e18b0ec97ad8173dd0352f890d39659 --cluster-slots 1000
# 2、删除节点
# 删除节点 7007
redis-cli --cluster del-node 127.0.0.1:7001 9f3d34828e1eb41214c158a142c350ca3f604487
# 此时 7008 成为其他节点的 副本节点
# S: d7316f5d4f0fdef182d7a27c56c911b9fe644b97 127.0.0.1:7008
# slots: (0 slots) slave
# replicates 0456481a2e18b0ec97ad8173dd0352f890d39659
# 删除从节点7008
redis-cli --cluster del-node 127.0.0.1:7001 d7316f5d4f0fdef182d7a27c56c911b9fe644b97