对于InfiniBand,很多搞数通的同学肯定不会陌生。
进入21世纪以来,随着云计算、大数据的不断普及,数据中心获得了高速发展。而InfiniBand,就是数据中心里的一项关键技术,地位极为重要。
尤其是今年以来,以ChatGPT为代表的AI大模型强势崛起,更是让InfiniBand的关注热度大涨。因为,GPT们所使用的网络,就是英伟达公司基于InfiniBand构建的。
那么,InfiniBand到底是什么技术?它为什么会倍受追捧?人们经常讨论的“InfiniBand与以太网”之争,又是怎么回事?

今天这篇文章,就让小枣君来逐一解答。
█ InfiniBand的发展历程
InfiniBand(简称IB),是一种能力很强的通信技术协议。它的英文直译过来,就是“无限带宽”。
Infiniband的诞生故事,还要从计算机的架构讲起。
大家都知道,现代意义上的数字计算机,从诞生之日起,一直都是采用的冯·诺依曼架构。在这个架构中,有CPU(运算器、控制器)、存储器(内存、硬盘),还有I/O(输入/输出)设备。
上世纪90年代早期,为了支持越来越多的外部设备,英特尔公司率先在标准PC架构中引入PCI(Peripheral Component Interconnect,外设部件互连标准)总线设计。
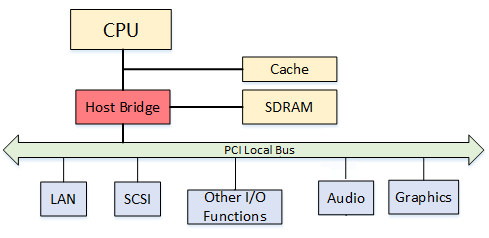
PCI总线,其实就是一条通道。
不久后,互联网进入高速发展阶段。线上业务和用户规模的不断增加,给IT系统的承载能力带来了很大挑战。
当时,在摩尔定律的加持下,CPU、内存、硬盘等部件都在快速升级。而PCI总线,升级速度缓慢,大大限制了I/O性能,成为整个系统的瓶颈。
为了解决这个问题,英特尔、微软、SUN公司主导开发了“Next Generation I/O(NGIO)”技术标准。而IBM、康柏以及惠普公司,则主导开发的“Future I/O(FIO)”。IBM这三家公司,还合力搞出了PCI-X标准(1998年)。
1999年,FIO Developers Forum和NGIO Forum进行了合并,创立了InfiniBand贸易协会(InfiniBand Trade Association,IBTA)。

很快,2000年,InfiniBand架构规范的1.0版本正式发布了。
简单来说,InfiniBand的诞生目的,就是为了取代PCI总线。它引入了RDMA协议,具有更低的延迟,更大的带宽,更高的可靠性,可以实现更强大的I/O性能。(技术细节,后文会详细介绍。)
说到InfiniBand,有一家公司我们是必须提到的,那就是大名鼎鼎的Mellanox。

迈络思
1999年5月,几名从英特尔公司和伽利略技术公司离职的员工,在以色列创立了一家芯片公司,将其命名为Mellanox。
Mellanox公司成立后,就加入了NGIO。后来,NGIO和FIO合并,Mellanox随之加入了InfiniBand阵营。2001年,他们推出了自己的首款InfiniBand产品。
2002年,InfiniBand阵营突遭巨变。
这一年,英特尔公司“临阵脱逃”,决定转向开发PCI Express(也就是PCIe,2004年推出)。而另一家巨头微软,也退出了InfiniBand的开发。
尽管SUN和日立等公司仍选择坚持,但InfiniBand的发展已然蒙上了阴影。
2003年开始,InfiniBand转向了一个新的应用领域,那就是计算机集群互联。
这一年,美国弗吉尼亚理工学院创建了一个基于InfiniBand技术的集群,在当时的TOP500(全球超级计算机500强)测试中排名第三。
2004年,另一个重要的InfiniBand非盈利组织诞生——OFA(Open Fabrics Alliance,开放Fabrics联盟)。

OFA和IBTA是配合关系。IBTA主要负责开发、维护和增强Infiniband协议标准;OFA负责开发和维护Infiniband协议和上层应用API。
2005年,InfiniBand又找到了一个新场景——存储设备的连接。
老一辈网工一定记得,当年InfiniBand和FC(Fibre Channel,光纤通道)是非常时髦的SAN(Storage Area Network,存储区域网络)技术。小枣君初次接触InfiniBand,就是在这个时候。
再后来,InfiniBand技术逐渐深入人心,开始有了越来越多的用户,市场占比也不断提升。
到了2009年,在TOP500榜单中,已经有181个采用了InfiniBand技术。(当然,千兆以太网当时仍然是主流,占了259个。)
在InfiniBand逐渐崛起的过程中,Mellanox也在不断壮大,逐渐成为了InfiniBand市场的领导者。

2010年,Mellanox和Voltaire公司合并,InfiniBand主要供应商只剩下Mellanox和QLogic。不久后,2012年,英特尔公司出资收购了QLogic的InfiniBand技术,返回到InfiniBand的竞争赛道。
2012年之后,随着高性能计算(HPC)需求的不断增长,InfiniBand技术继续高歌猛进,市场份额不断提升。
2015年,InfiniBand技术在TOP500榜单中的占比首次超过了50%,达到51.4%(257套)。
这标志着InfiniBand技术首次实现了对以太网(Ethernet)技术的逆袭。InfiniBand 成为超级计算机最首选的内部连接技术。
2013年,Mellanox相继收购了硅光子技术公司Kotura和并行光互连芯片厂商IPtronics,进一步完善了自身产业布局。2015年,Mellanox在全球InfiniBand市场上的占有率达到80%。他们的业务范围,已经从芯片逐步延伸到网卡、交换机/网关、远程通信系统和线缆及模块全领域,成为世界级网络提供商。
面对InfiniBand的赶超,以太网也没有坐以待毙。
2010年4月,IBTA发布了RoCE(RDMA over Converged Ethernet,基于融合以太网的远程直接内存访问),将InfiniBand中的RDMA技术“移植”到了以太网。2014年,他们又提出更加成熟的RoCE v2。
有了RoCE v2,以太网大幅缩小了和InfiniBand之间的技术性能差距,结合本身固有的成本和兼容性优势,又开始反杀回来。
大家通过下面这张图,可以看出从2007年到2021年的TOP500榜单技术占比。
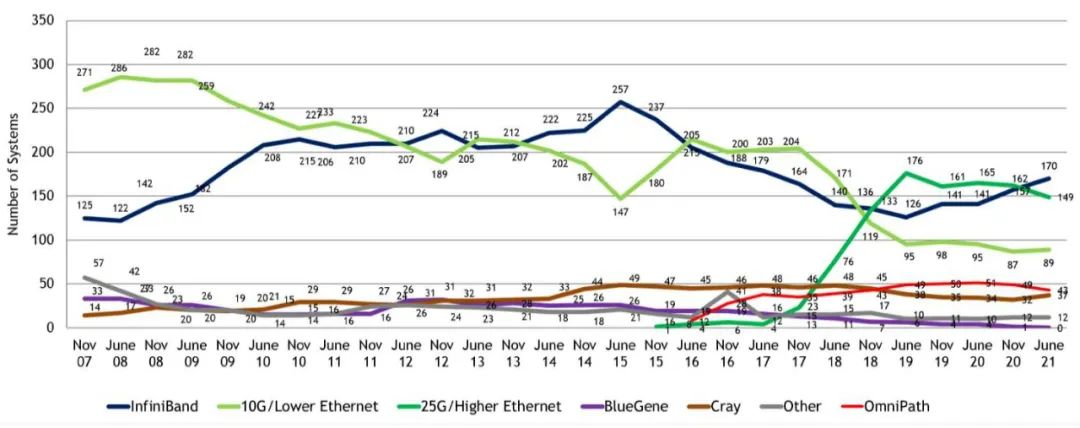
如图所示,2015年开始,25G及更高速率的以太网(图中深绿色的线)崛起,迅速成为行业新宠,一度压制住了InfiniBand。
2019年,英伟达(Nvidia)公司豪掷69亿美元,击败对手英特尔和微软(分别出价60亿和55亿美元),成功收购了Mellanox。

对于收购原因,英伟达CEO黄仁勋是这么解释的:
“这是两家全球领先高性能计算公司的结合,我们专注于加速计算(accelerated computing),而Mellanox专注于互联和存储。”
现在看来,老黄的决策是非常有远见的。
正如大家所见,AIGC大模型崛起,整个社会对高性能计算和智能计算的需求井喷。

想要支撑如此庞大的算力需求,必须依赖于高性能计算集群。而InfiniBand,在性能上是高性能计算集群的最佳选择。
将自家的GPU算力优势与Mellanox的网络优势相结合,就等于打造了一个强大的“算力引擎”。在算力基础设施上,英伟达毫无疑问占据了领先优势。
如今,在高性能网络的竞争上,就是InfiniBand和高速以太网的缠斗。双方势均力敌。不差钱的厂商,更多会选择InfiniBand。而追求性价比的,则会更倾向高速以太网。
剩下还有一些技术,例如IBM的BlueGene、Cray,还有Intel的OmniPath,基本属于第二阵营了。
█ InfiniBand的技术原理
介绍完InfiniBand的发展历程,接下来,我们再看看它的工作原理。为什么它会比传统以太网更强。它的低时延和高性能,究竟是如何实现的。
起家本领——RDMA
前文提到,InfiniBand最突出的一个优势,就是率先引入RDMA(Remote Direct Memory Access,远程直接数据存取)协议。
在传统TCP/IP中,来自网卡的数据,先拷贝到核心内存,然后再拷贝到应用存储空间,或从应用空间将数据拷贝到核心内存,再经由网卡发送到Internet。
这种I/O操作方式,需要经过核心内存的转换。它增加了数据流传输路径的长度,增加了CPU的负担,也增加了传输延迟。
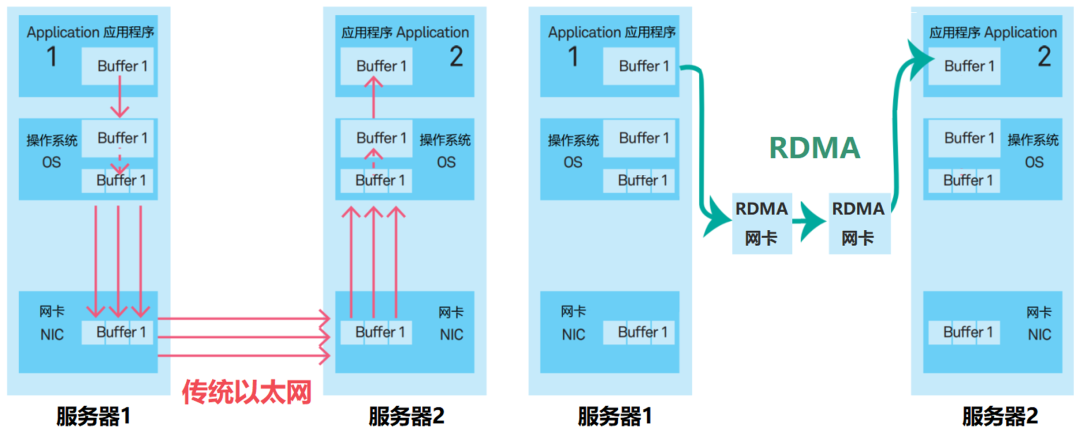
传统模式 VS RDMA模式
RDMA相当于是一个“消灭中间商”的技术。
RDMA的内核旁路机制,允许应用与网卡之间的直接数据读写,将服务器内的数据传输时延降低到接近1us。
同时,RDMA的内存零拷贝机制,允许接收端直接从发送端的内存读取数据,绕开了核心内存的参与,极大地减少了CPU的负担,提升CPU的效率。
如前文所说,InfiniBand之所以能迅速崛起,RDMA居功至伟。
InfiniBand的网络架构
InfiniBand的网络拓扑结构示意,如下图所示:
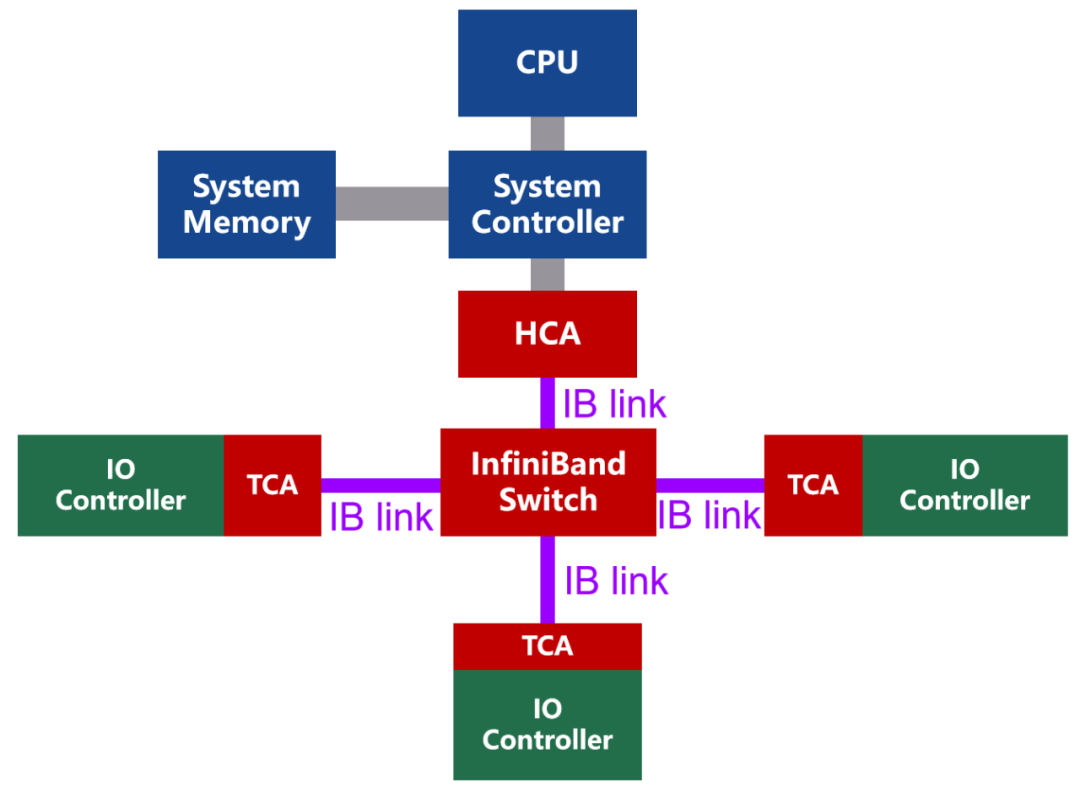
InfiniBand是一种基于通道的结构,组成单元主要分为四类:
· HCA(Host Channel Adapter,主机通道适配器)
· TCA(Target Channel Adapter,目标通道适配器)
· InfiniBand link(连接通道,可以是电缆或光纤,也可以是板上链路)
· InfiniBand交换机和路由器(组网用的)
通道适配器就是搭建InfiniBand通道用的。所有传输均以通道适配器开始或结束,以确保安全或在给定的QoS(服务质量)级别下工作。
使用InfiniBand的系统可以由多个子网(Subnet)组成,每个子网最大可由6万多个节点组成。子网内部,InfiniBand交换机进行二层处理。子网之间,使用路由器或网桥进行连接。
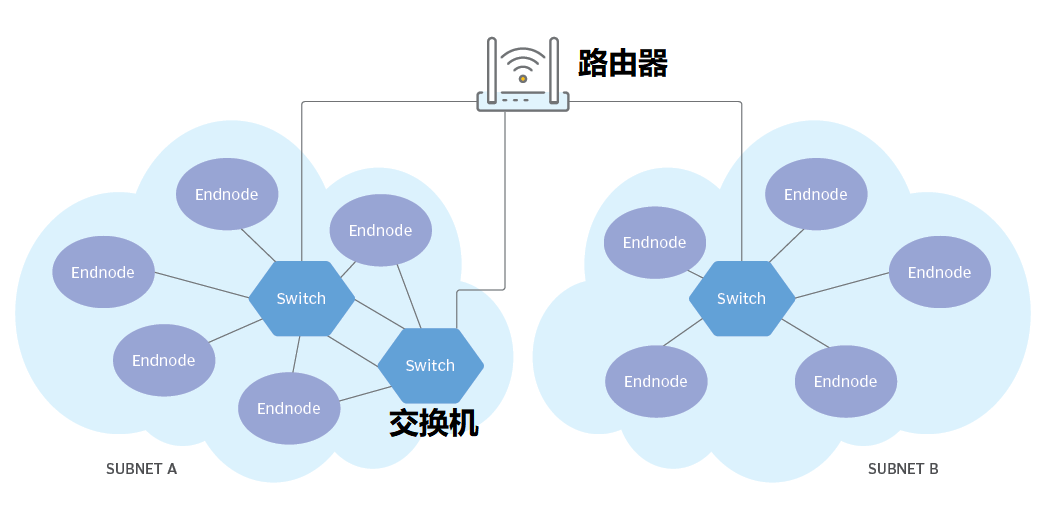
InfiniBand组网示例
InfiniBand的二层处理过程非常简单,每个InfiniBand子网都会设一个子网管理器,生成16位的LID(本地标识符)。InfiniBand交换机包含多个InfiniBand端口,并根据第二层本地路由标头中包含的LID,将数据包从其中一个端口转发到另一个端口。除管理数据包外,交换机不会消耗或生成数据包。
简单的处理过程,加上自有的Cut-Through技术,InfiniBand将转发时延大幅降低至100ns以下,明显快于传统以太网交换机。
在InfiniBand 网络中,数据同样以数据包(最大4KB)的形式传输,采用的是串行方式。
InfiniBand的协议栈
InfiniBand协议同样采用了分层结构。各层相互独立,下层为上层提供服务。如下图所示:
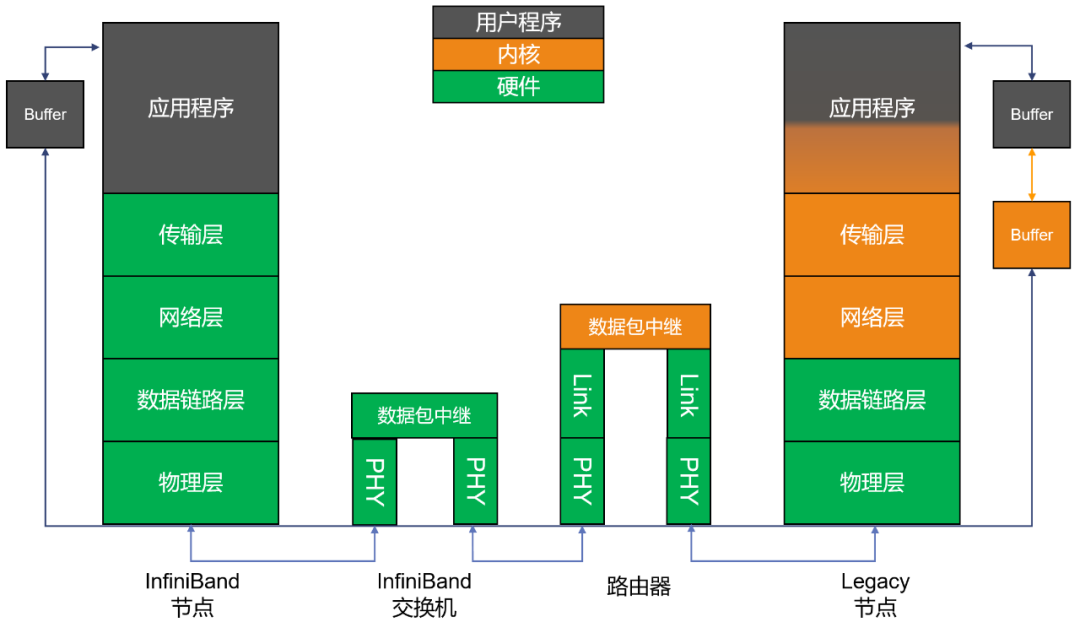
其中,物理层定义了在线路上如何将比特信号组成符号,然后再组成帧、数据符号以及包之间的数据填充等,详细说明了构建有效包的信令协议等。
链路层定义了数据包的格式以及数据包操作的协议,如流控、 路由选择、编码、解码等。
网络层通过在数据包上添加一个40字节的全局的路由报头(Global Route Header, GRH)来进行路由的选择,对数据进行转发。
在转发的过程中,路由器仅仅进行可变的CRC校验,这样就保证了端到端的数据传输的完整性。
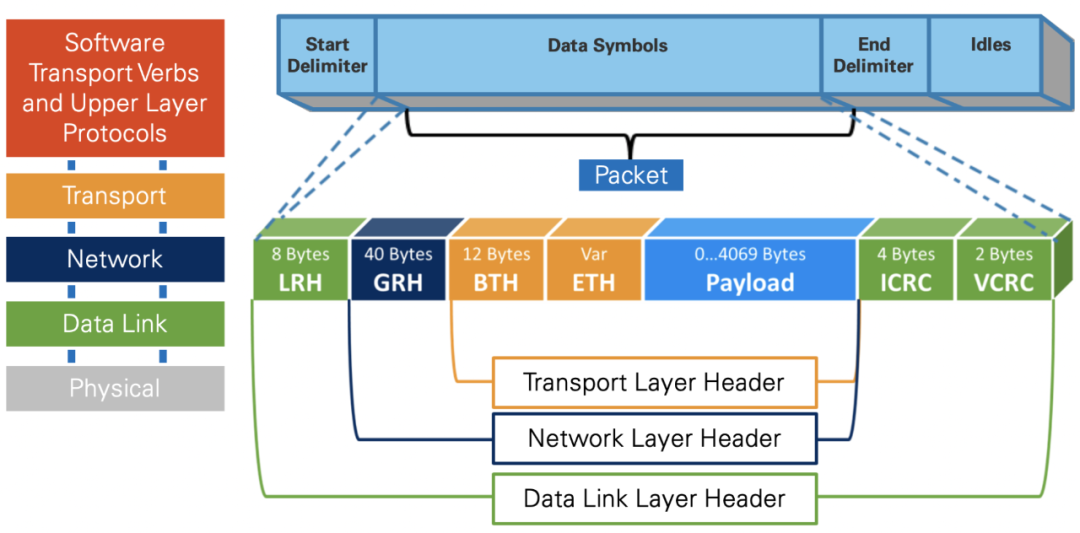
Infiniband报文封装格式
传输层再将数据包传送到某个指定的队列偶(Queue Pair, QP)中,并指示QP如何处理该数据包。
可以看出,InfiniBand拥有自己定义的1-4层格式,是一个完整的网络协议。端到端流量控制,是InfiniBand网络数据包发送和接收的基础,可以实现无损网络。
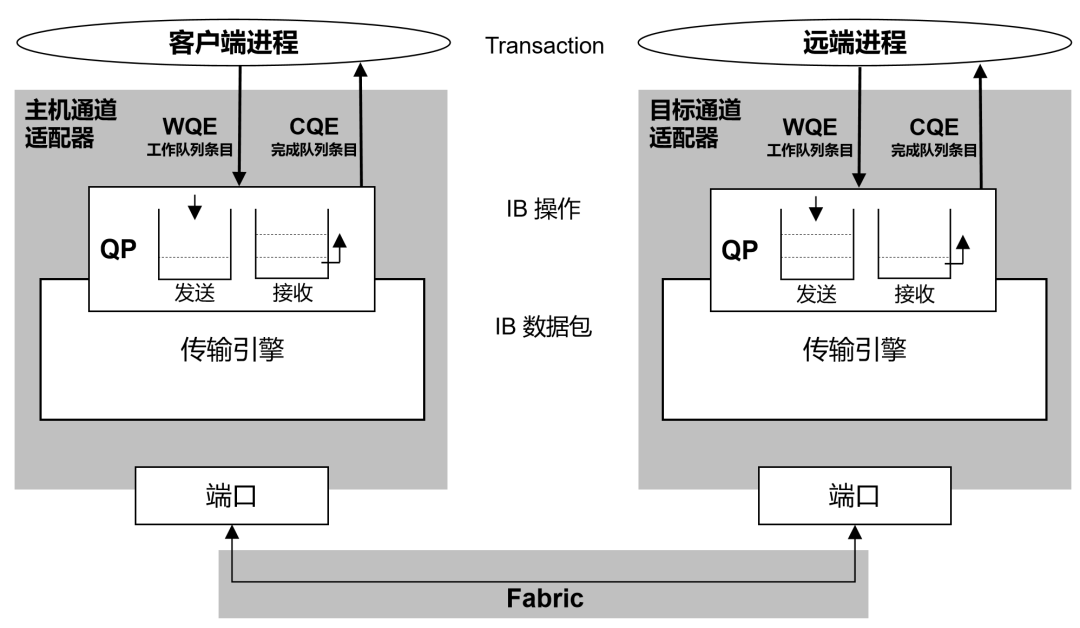
说到QP(队列偶),我们需要多提几句。它是RDMA技术中通信的基本单元。
队列偶就是一对队列,SQ(Send Queue,发送工作队列)和RQ(Receive Queue,接收工作队列)。用户调用API发送接收数据的时候,实际上是将数据放入QP当中,然后以轮询的方式,将QP中的请求一条条的处理。
InfiniBand的链路速率
InfiniBand链路可以用铜缆或光缆,针对不同的连接场景,需使用专用的InfiniBand线缆。
InfiniBand在物理层定义了多种链路速度,例如1X,4X,12X。每个单独的链路是四线串行差分连接(每个方向两根线)。
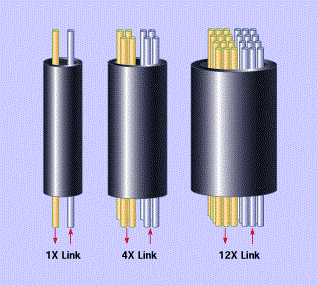
以早期的SDR(单数据速率)规范为例,1X链路的原始信号带宽为2.5Gbps,4X链路是10Gbps,12X链路是30Gbps。
1X链路的实际数据带宽为2.0Gbps(因为采用8b/10b编码)。由于链路是双向的,因此相对于总线的总带宽是4Gbps。
随着时间的推移,InfiniBand的网络带宽不断升级,从早期的SDR、DDR、QDR、FDR、EDR、HDR,一路升级到NDR、XDR、GDR。如下图所示:
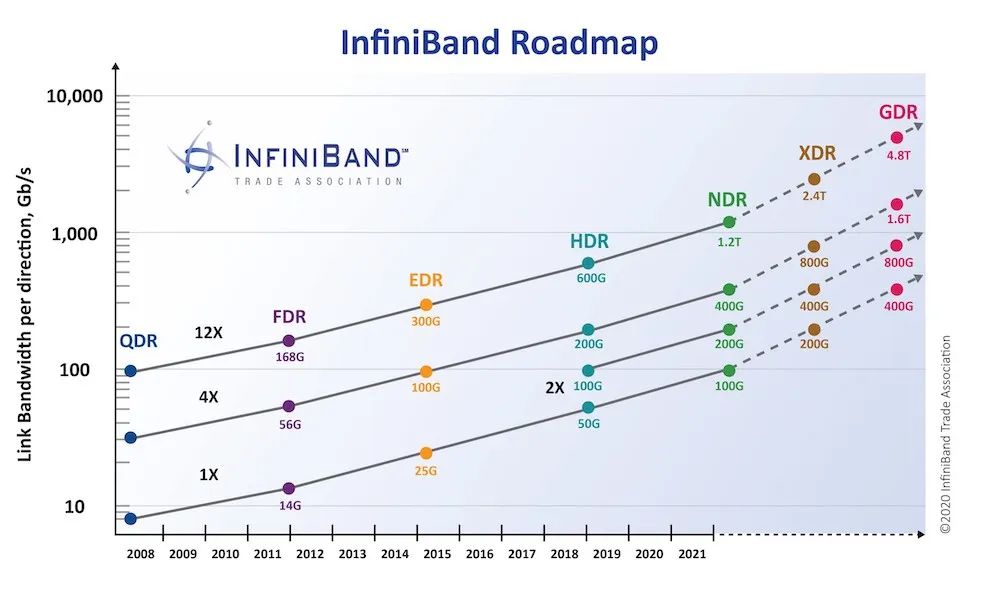
英伟达最新的Quantum-2平台好像采用的是NDR 400G
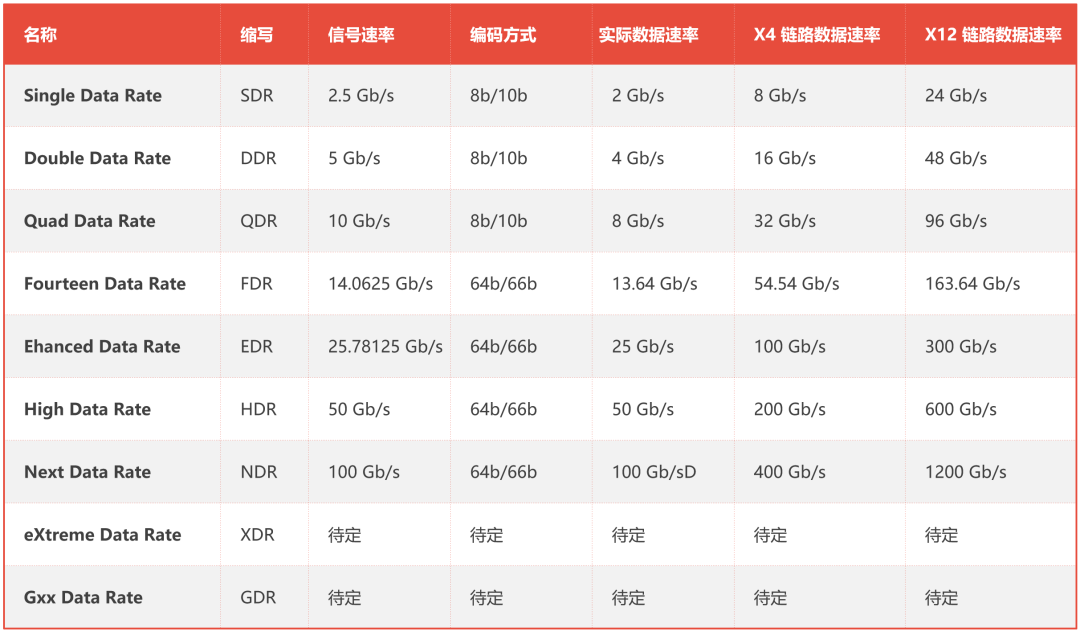
具体速率和编码方式
InfiniBand的商用产品
最后,我们再来看看市面上的InfiniBand商用产品。
英伟达收购Mellanox之后,于2021年推出了自己的第七代NVIDIA InfiniBand架构——NVIDIA Quantum-2。
NVIDIA Quantum-2平台包括:NVIDIA Quantum-2 系列交换机、NVIDIA ConnectX-7 InfiniBand 适配器、BlueField-3 InfiniBand DPU,以及相关的软件。

NVIDIA Quantum-2 系列交换机采用紧凑型1U设计,包括风冷和液冷版本。交换机的芯片制程工艺为7nm,单芯片拥有570亿个晶体管(比A100 GPU还多)。采用64个400Gbps端口或128个200Gbps端口的灵活搭配,提供总计51.2Tbps的双向吞吐量。
NVIDIA ConnectX-7 InfiniBand 适配器,支持PCIe Gen4和Gen5,具有多种外形规格,可提供400Gbps的单或双网络端口。
█ 结语
根据行业机构的预测,到2029年,InfiniBand的市场规模将达到983.7亿美元,相比2021年的66.6亿美元,增长14.7倍。预测期内(2021-2029)的复合年增长率,为 40%。
在高性能计算和人工智能计算的强力推动下,InfiniBand的发展前景令人期待。
究竟它和以太网谁能笑到最后,就让时间来告诉我们答案吧!

InfiniBand采用双队列程序提取技