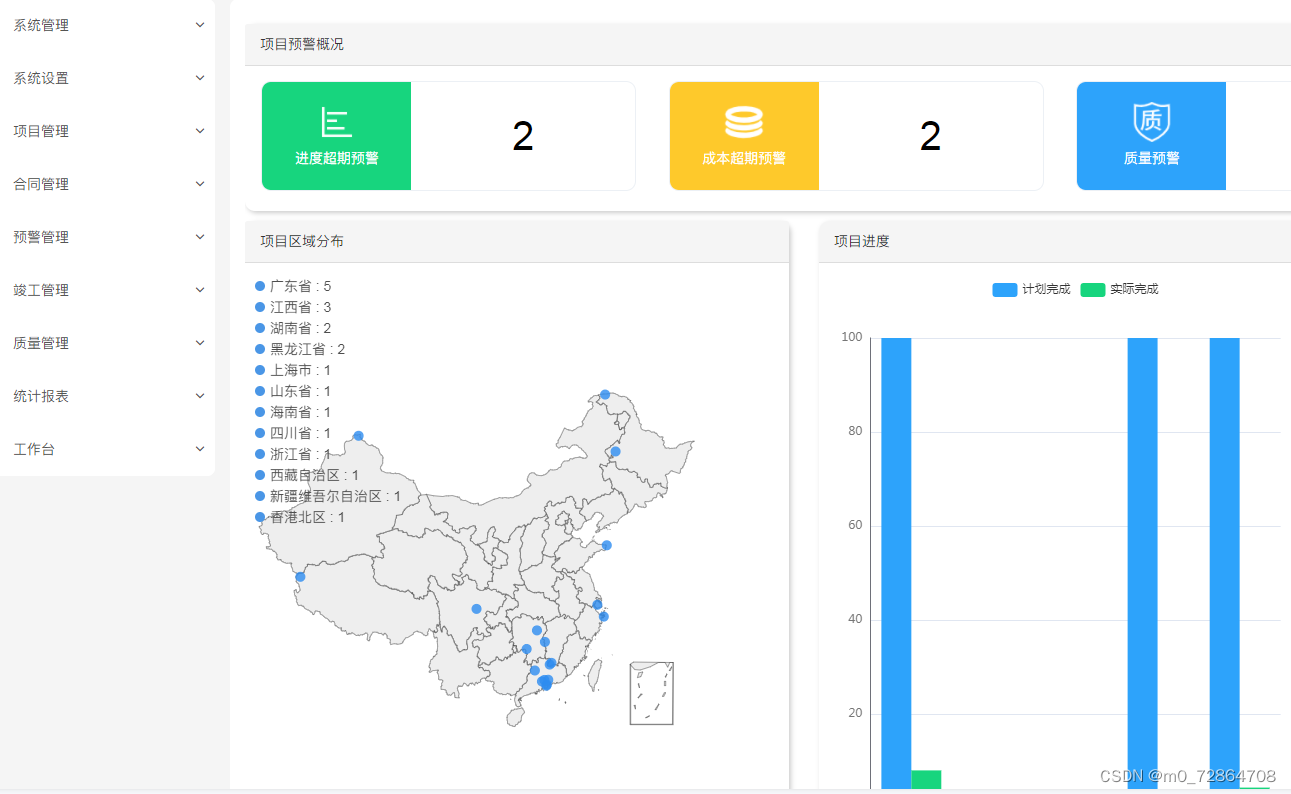
目的:大模型预训练+微调范式,微调成本高。adapter只只微调新增的小部分参数【但adapter增加了模型层数,引入了额外的推理延迟。】
-
Adapters最初来源于CV领域的《Learning multiple visual domains with residual adapters》一文,其核心思想是在神经网络模块基础上添加一些残差模块,并只优化这些残差模块,由于残差模块的参数更少,因此微调成本更低。
-
Houlsby等人将这一思想应用到了自然语言处理领域。他们提出在Transformer的注意力层和前馈神经网络(FFN)层之后添加全连接网络。微调时,只对新增的 Adapter 结构和 Layer Norm 层进行微调,从而保证了训练的高效性。 每当出现新的下游任务,通过添加Adapter模块来产生一个易于扩展的下游模型,从而避免全量微调与灾难性遗忘的问题。
Adapters Tuning效率很高,通过微调不到4%的模型参数,可以实现与 fine-tuning相当的性能。

左图:在每个Transformer layer中两次添加adapter——在多头注意力后的投影之后和在两个前馈层之后。
右图:adapter是一个bottleneck结构,包括两个前馈子层(Feedforward)和跳连接( skip-connection)。
- Feedforward down-project:将原始输入维度d(高维特征)投影到m(低维特征),通过控制m的大小来限制Adapter模块的参数量,通常情况下,m<<d;
- Nonlinearity:非线性层;
- Feedforward up-project:还原输入维度d,作为adapter模块的输出。通时通过一个skip connection来将Adapter的输入重新加到最终的输出中去(残差连接)
伪代码样子:
def transformer_block_with_adapter(x):
residual = x
x = SelfAttention(x)
x = FFN(x) # adapter
x = LN(x + residual)
residual = x
x = FFN(x) # transformer FFN
x = FFN(x) # adapter
x = LN(x + residual)
return x