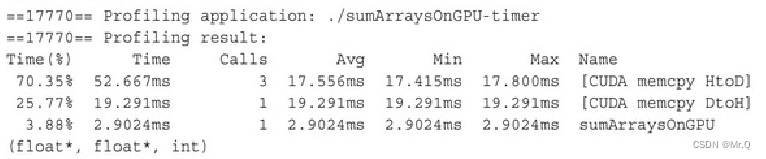
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共1100人左右 1 + 2 + 3)新人会进入3群
共识是保证一致的分布式系统的基础。为了在不可避免的故障中保证系统的可用性,系统需要一种确保集群中每个节点保持一致的方式,以便在发生故障时无缝地将工作转移到其他节点。Paxos、Raft和View Stamped Replication(VSR)等共识协议通过提供领导者选举、原子配置更改、同步等过程的逻辑,为分布式系统提供了弹性。
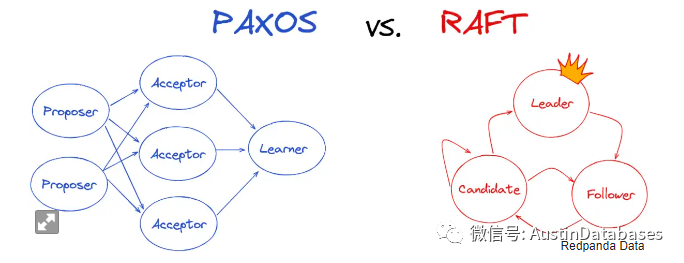
正如所有设计元素一样,分布式共识的不同方法提供了不同的权衡。Paxos是最古老的共识协议,并被许多系统使用,如Google Cloud Spanner、Apache Cassandra、Amazon DynamoDB和Neo4j。Paxos通过三阶段的无领导者、多数异步提交协议实现共识。虽然Paxos在推动正确性方面很有效,但众所周知,它难以理解、实现和推理。这部分是因为它隐藏了许多达成共识的挑战(例如领导者选举、重配置),使得将其拆分成子问题变得困难。
可靠、复制、冗余和容错的Raft(reliable, replicated, redundant, and fault-tolerant)可以被看作是Paxos的一种演变,注重可理解性。Raft可以达到与Paxos相同的正确性,但在实际世界中更容易理解和实现,因此通常可以提供更高的可靠性保证。例如,Raft使用稳定的领导形式,简化了复制日志管理,并且它的领导者选举过程更高效。
同时,由于Raft将共识问题的不同逻辑组件进行了拆分,例如通过在复制之前将领导者选举作为一个独立的步骤,它是一个灵活的协议,适用于复杂的现代分布式系统。这些系统需要在保持正确性和性能的同时,扩展到PB级的吞吐量,并且对于新的工程师来说更容易理解和开发。
因此,Raft协议已经迅速被广泛应用于当今的分布式和云原生系统,例如MongoDB、CockroachDB、TiDB和Redpanda,以实现更高的性能和事务的效率。
Redpanda是如何实现Raft的
当Redpanda创始人Alex Gallego确定世界需要一个新的流式数据平台来支持那些可能导致Apache Kafka故障的GBps+工作负载时,他决定从头开始重写Kafka。
Redpanda成为现在的这款产品的需求包括:1)简单且轻量化,以降低在大规模可靠地运行Kafka集群时的复杂性和低效性;2)充分利用现代硬件的性能,以提供大型工作负载的低延迟;3)即使在非常大的吞吐量情况下,也要保证数据的安全性。
实现Raft为这三个需求提供了坚实的基础:1)简单性:每个Redpanda分区都是一个Raft组,因此平台中的所有内容都是基于Raft进行推理,包括元数据管理和分区复制。与Kafka的复杂性形成对比,Kafka的数据复制由ISR(in-sync replicas)处理,元数据管理由ZooKeeper(或KRaft)处理,因此存在两个必须相互推理的系统。2)性能:Redpanda的Raft实现可以容忍少数副本的干扰,只要领导者和大多数副本是稳定的。在一部分副本延迟响应时,领导者无需等待它们的响应就可以继续进展,从而减少对延迟的影响。因此,Redpanda具有更好的容错性,并能在大规模上提供可预测的性能。3)可靠性:当Redpanda接收事件时,它们被写入一个主题分区,并追加到磁盘上的日志文件中。然后,每个主题分区形成一个Raft共识组,由一个领导者和若干个追随者组成,这取决于主题的复制因子。在给定2ƒ+1个节点的情况下,Redpanda的Raft组可以容忍ƒ个故障。例如,在一个拥有五个节点和复制因子为五的主题的集群中,可以发生两个节点的故障而主题仍保持正常运行。Redpanda利用Raft联合共识协议来实现一致性,即使在重新配置期间也是如此。
此外,Redpanda还通过一些关键方式扩展了核心的Raft功能,以实现现代云原生解决方案所需的可扩展性、可靠性和速度。它对Raft进行的创新包括对选举过程、心跳生成以及关键的支持Apache Kafka ACKS的改变。这些创新确保了在所有场景下实现最佳性能,这正是Redpanda能够更快地比Kafka提供数据安全性的原因。实际上,Jepsen测试已经验证了Redpanda是一个安全的系统,没有已知的一致性问题,并且具有可靠的基于Raft的共识层。
KRaft呢?
尽管Redpanda采取了一种原生的Raft方法,但传统的流式数据平台在采用现代共识方法方面一直拖后腿。Kafka本身是一个复制的分布式日志,但它在历史上一直依赖于另一个复制的分布式日志——Apache ZooKeeper来进行元数据管理和控制器选举。这带来了一些问题:
1)管理多个系统增加了管理负担;2)由于元数据处理和双重缓存,可扩展性有限;3)集群可能变得非常臃肿和资源密集,实际上,看到ZooKeeper和Kafka节点数量相等的集群并不罕见。
这些限制并没有被Apache Kafka的贡献者和维护人员所忽视。他们正在将ZooKeeper替换为自我管理的元数据仲裁系统:Kafka Raft(KRaft)。这种基于事件的Raft变体减少了Kafka元数据管理的管理挑战,并且证明了Kafka生态系统正在朝着现代共识和可靠性方法的方向发展。
不幸的是,KRaft并没有解决在Kafka集群中同时存在两个不同的共识系统的问题。在新的KRaft范式中,KRaft分区处理元数据和集群管理,但复制由代理处理,因此仍然存在这两个不同的平台和由此产生的效率低下的复杂性。
例如,由于Redpanda绕过了Kafka的页缓存和Java虚拟机(JVM)依赖,它可以将硬件级别的知识嵌入到其Raft实现中。通常,每次在Raft中进行写操作时,都需要刷新以确保写入到磁盘的持久性。在Redpanda对Raft的乐观方法中,较小的间断性刷新被放弃,而在调用结束时进行更大的刷新。虽然这会增加每个调用的延迟,但它降低了整体系统延迟并增加了总体吞吐量,因为它减少了刷新操作的总数。
虽然在分布式系统中有很多有效的方法来确保一致性和安全性(例如,区块链通过工作证明和权益证明协议做得非常好),但Raft是一种经过验证的方法,足够灵活,可以进行增强,就像Redpanda一样,以适应新的挑战。随着我们进入一个以数据驱动的可能性的新世界,部分受到人工智能和机器学习用例的推动,将来掌握在能够利用实时数据流的开发人员手中。
基于Raft的系统,结合C++和按核心的线程架构等性能工程化元素,正在推动关键应用程序的数据流未来。
Doug Flora是Redpanda Data的产品营销负责人。