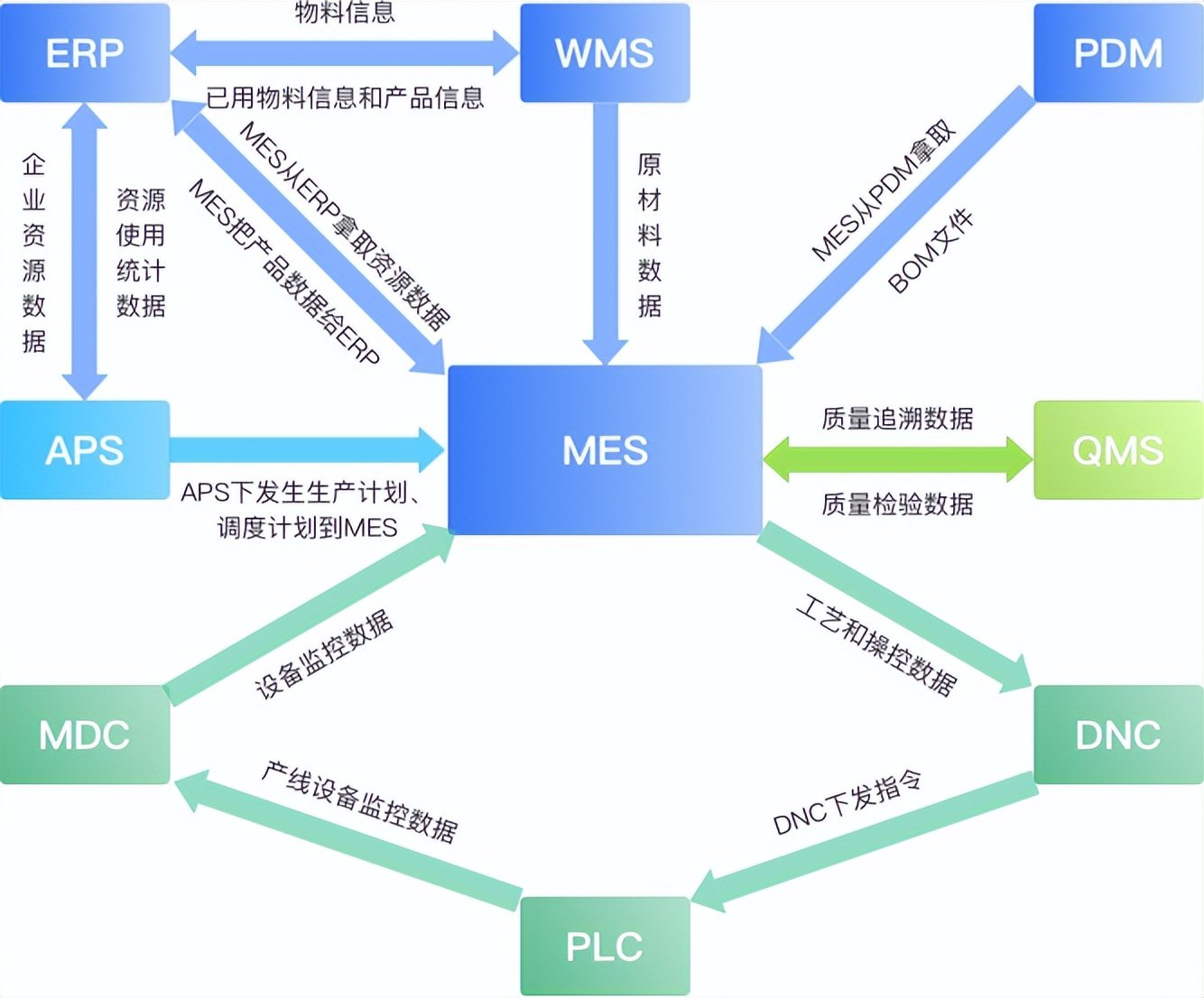
1.背景
近期,GPT 大模型的发布给自然语言处理(NLP)领域带来了令人震撼的体验。随着这一事件的发生,一系列开源大模型也迅速崛起。依据一些评估机构的评估,这些开源模型大模型的表现也相当不错。一些大模型的评测情况可以去这里查询:Huggingface 的 Open LLM 排行榜,UC 伯克利发布大语言模型排行榜等。
随着大模型的发展,大模型的训练与部署技术变的非常重要了。我们调研了 LORA 与 QLORA 等微调训练技术,以及 GPTQ 量化部署技术。在跑通最小 Demo 并验证效果后,把这些技术集成到 KubeAI 平台(得物 AI 平台),提供给大家去快速上手。
本篇主要分为技术理论与技术实战两个部分去讲解。
技术理论主要讲解微调训练与量化推理的理论部分,微调训练包括 LoRA,QLoRA, 部署包括 GPTQ 量化推理等,并针对关键代码进行走读,针对部署进行性能测试。
技术实战部分我们把这些技术集成到 KubeAI 平台上,供大家可以快速上手实战。依据前面同学的反馈情况,大约一天内可以完成大模型训练并部署推理上线。
2.LoRA 与 QLoRA 训练技术
2.1 LoRA 技术介绍
LoRA,英文全称 Low-Rank Adaptation of Large Language Models(中文为大语言模型的低阶适应)。
这是微软的研究人员为了解决大语言模型微调而开发的一项技术,其 github 地址为 https://github.com/microsoft/LoRA ,当前已经得到 HuggingFace 的 PEFT 库 https://github.com/huggingface/peft 的支持。
对于大语音模型来说,其参数量非常多。GPT3 有 1750 亿参数,而且 LLAMA 系列模型包括 7B,13B,33B,65B,而其中最小的 7B 都有 70 亿参数。要让这些模型去适应特定的业务场景,需要对他们进行微调。如果直接对这些模型进行微调,由于参数量巨大,需要的 GPU 成本就会非常高。LoRA 就是用来解决对这些大语言模型进行低成本微调的技术。
LoRA 的做法是对这些预训练好的大模型参数进行冻结,也就是在微调训练的时候,这些模型的参数设置为不可训练。然后往模型中加入额外的网络层,并只训练这些新增的网络层参数。这样可训练的参数就会变的非常少,可以以低成本的 GPU 微调大语言模型。
参照 https://arxiv.org/abs/2106.09685
LoRA 在 Transformer 架构的每一层注入可训练的秩分解矩阵,与使用 Adam 微调的 GPT-3 175B 相比,LoRA 可以将可训练参数数量减少 10000 倍,GPU 内存需求减少 3 倍,并且在效果上相比于传统微调技术表现的相当或更好。
下面以 Transformer 的线性层为例,讲解下 LoRA 具体是如何操作的。
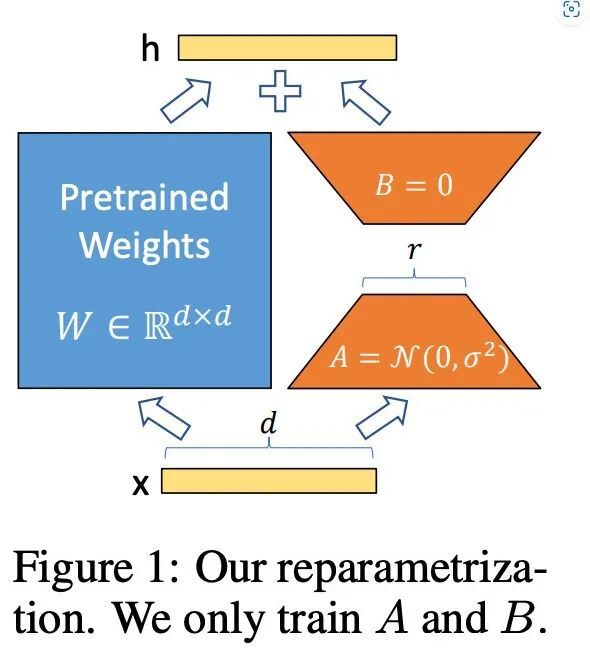
在 Transformer 模型中的线性层,通常进行矩阵乘法操作,如 Y = XW,其中 X 是输入矩阵,W 是权重矩阵,也是模型训练求解的参数。
对于 LoRA 方法在 Transformer 的线性层中的操作步骤:
-
在每个线性层旁边增加一个"旁路",由降维矩阵 A 和升维矩阵 B 构成。低秩分解在这里发挥作用,例如我们有一个 100x100 的矩阵 C,我们可以通过低秩分解将其分解为 A 和 B(假设秩设置为 1),其中 A 是 100x1 的矩阵,B 是 1x100 的矩阵。这样,原本 10000 个参数的矩阵 C 被分解为总共 200 个参数的矩阵 A 和 B。
-
训练过程中,原线性层的权重矩阵 W 保持不变,只训练降维矩阵 A 和升维矩阵 B。
-
在推理时,将矩阵 B 和 A 的乘积加到原始线性层的权重矩阵 W 上。因为 A 和 B 的秩较低,这个操作不会增加额外的推理延迟。
-
对于一般的任务,秩选取 1,2,4,8,16 足矣。
2.2 LoRA 关键代码走读
上面讲解了 LoRA 的关键,接下来我们针对最新的版本 PEFT 中的 LoRA 实现,进行关键代码走读。LoRA 的核心代码逻辑在:https://github.com/huggingface/peft/blob/main/src/peft/tuners/lora.py
其中有两个核心的类,一个是 LoraConfig,另一个是 LoraModel。

LoraConfig 是 LoRA 的核心配置类,它是用于配置 LoRAModel 的类,其中包含了一些用于控制模型行为的参数。
这个类的主要参数有:
-
r:LoRa(低秩逼近)注意力维度,就是前面所说的秩。默认值是 8。
-
target_modules:要应用 LoRa 的模块名列表。
-
lora_alpha:LoRa 的 alpha 参数。默认值是 8。
-
lora_dropout:LoRa 层的 dropout 概率。默认值是 0.0。
-
bias:LoRa 的偏置类型。可以是'none'、'all'或'lora_only'。
LoraModel 是 LoRA 模块的核心类,冻结 base model 的参数,旁路低秩矩阵的创建,替换,合并等逻辑都在这个类中。下面我们把他的关键逻辑结合上面的介绍走读一下。
2.2.1 初始化函数

从初始化函数中我们看到 LoraModel 也是继承 torch.nn.Module,相当于 pytorch 的一个网络模块。传入参数中 base_model 相当于被用来微调的基础大模型,config 包含 LoraConfig。在初始化中 LoraModel 把自己的前向传播函数 forword 设置为大模型的 forward 方法。
2.2.2 初始化:使用新的 LoraLayer 替换 target_modules 中配置的 Layer,实现上面所说的添加旁路低秩矩阵的功能。
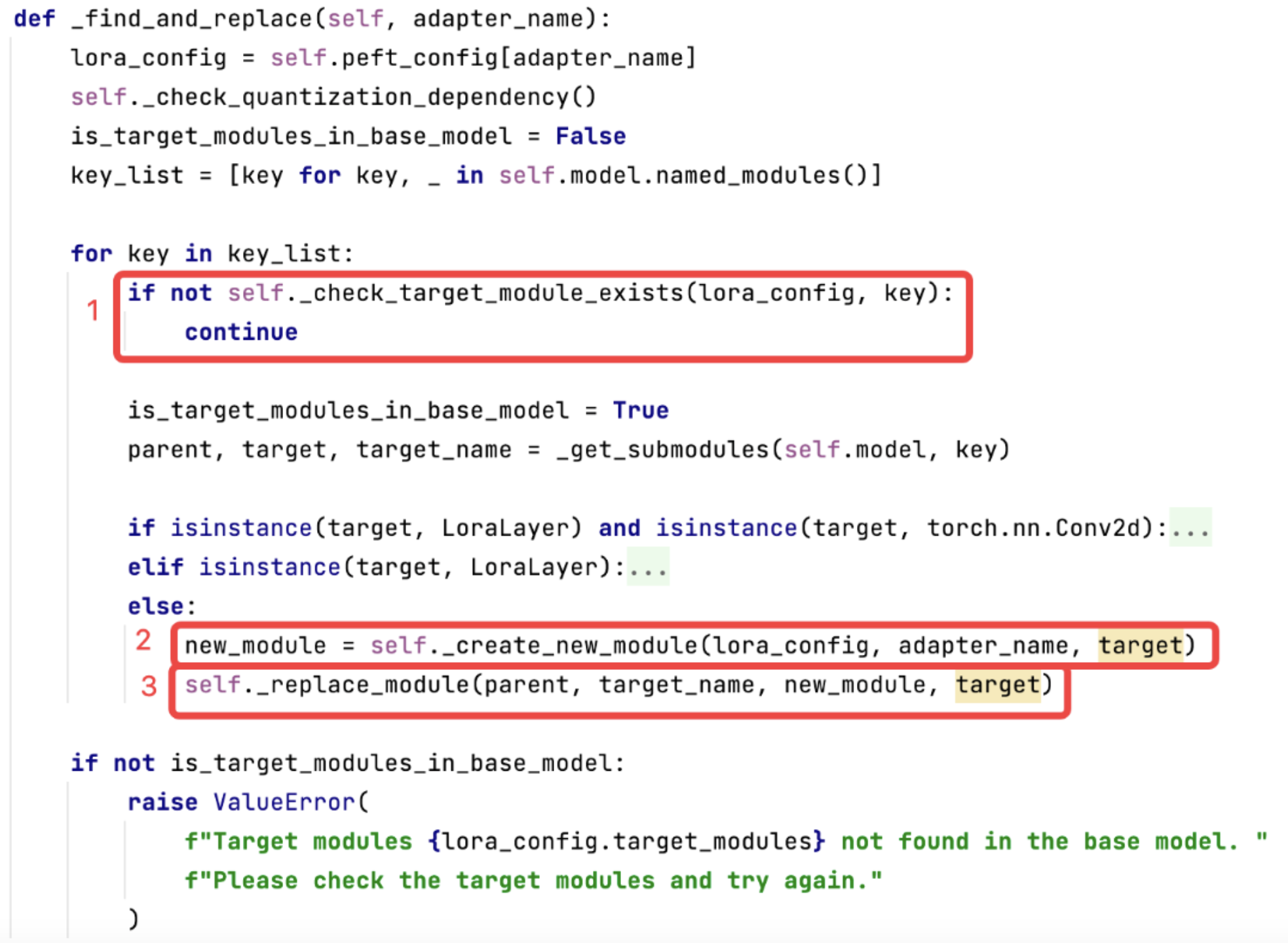
上述代码的主要功能:
-
依据 LoraConfig 中配置的 tagetModules,在 base_model(大模型)中找到这些 Module
-
创建新的 LoraLayer,新的 LorayLayer 中会包含原来 target_module 的 layer,并在其旁边并行旁路,旁路主要是低秩矩阵 Lora_A 与 Lora_B 组成的低秩两个低秩矩阵的加法
-
使用新创建的 LoraLayer 替换原来的 target_module 的 layer。
通过这一步实现了在大模型的 target_modules 的 layer 中增加旁路低秩矩阵。
2.2.3 初始化:冻结大模型的参数
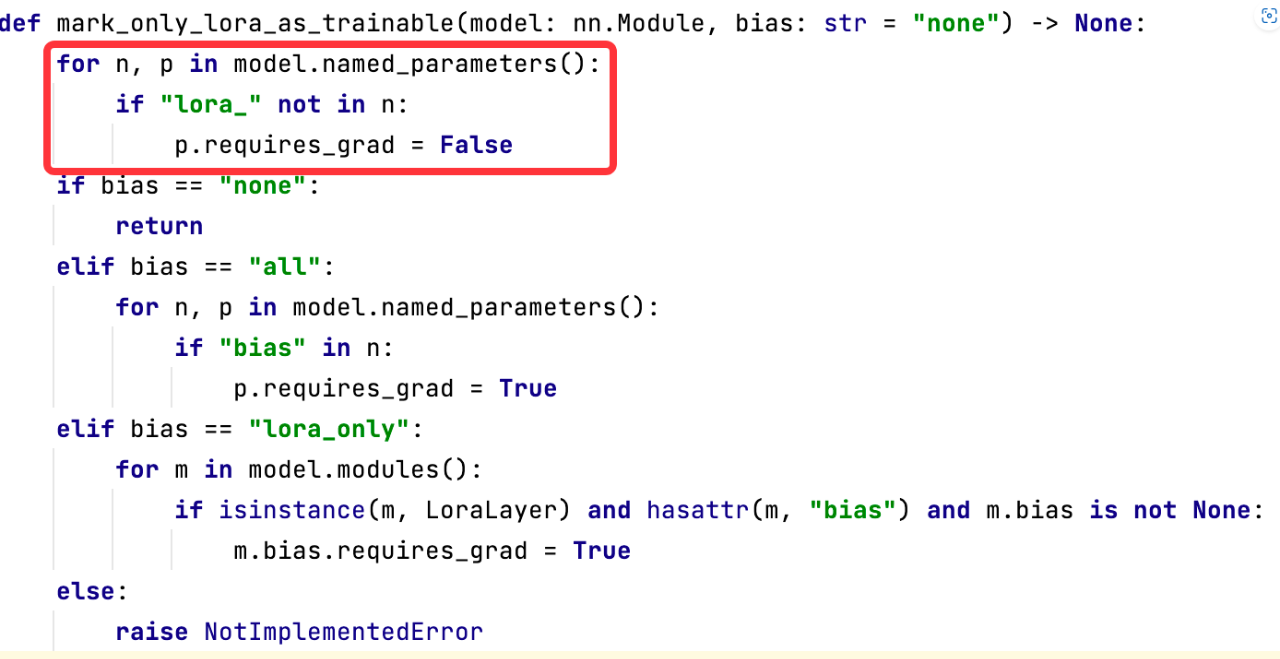
可见除了新增的 LoraLayer 的模块外,其他所有参数都被冻结。
2.2.4 前向传播:添加了旁路低秩矩阵后的运算逻辑(以 LineLayer 为例)
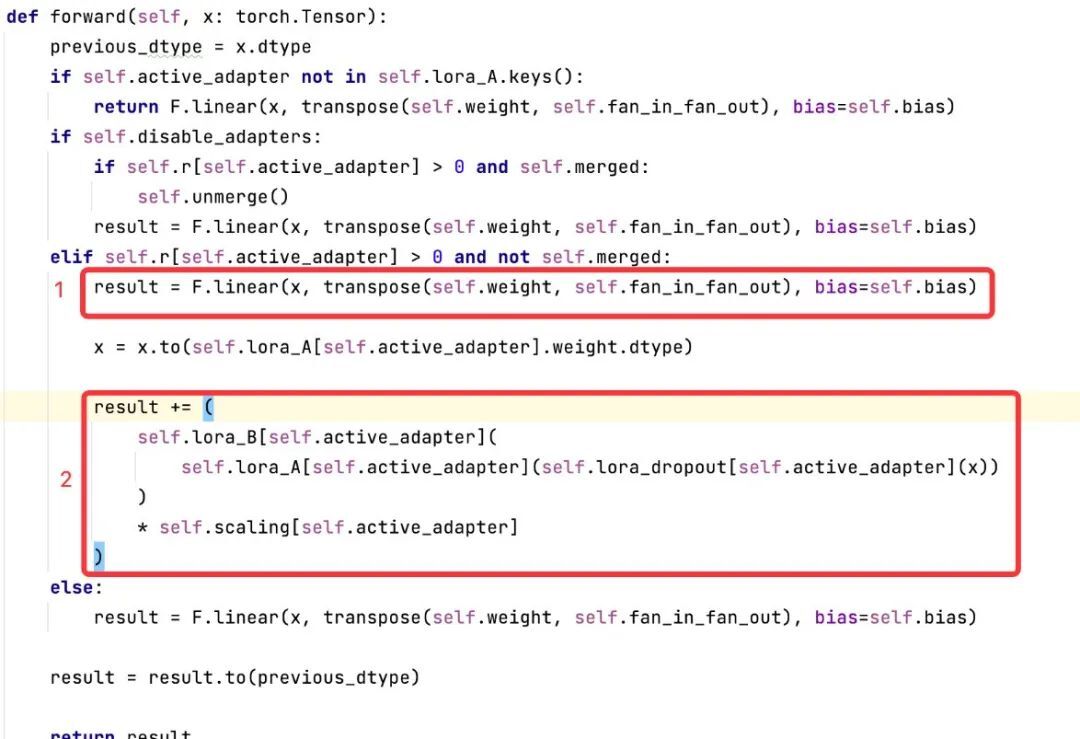
在上述代码中:
-
使用大模型 target_module 中线性层进行计算,得出结果 result。
-
使用 lora_A 与 lora_B 的低秩矩阵进行计算 并把计算结果加到 result 上。
以上是主要逻辑,其他逻辑可以深入代码去了解。PEFT 库中 Lora 的实现与论文中所述一致。
2.3 QLORA 技术介绍
LoRA 技术虽然可以在一定程度上节省显存,提升训练速度,但是把大模型以 float16 的方式运行,还是会占用很多显存。比如:在 batch size 开到极小的情况下,单卡 A100(80G 显存)只能微调 7B 系列的模型,13B 模型在正常情况下需要 120G 显存,微调 65B 模型需要超过 780G 的显存。
为此华盛顿大学的研究者提出了 QLoRA 技术,极端情况下单个 24GB GPU 上实现 33B 的微调,可以在单个 48Gi 显存微调 65B 模型。当然这种情况下微调会变得比较慢。
论文参考 https://arxiv.org/abs/2305.14314。
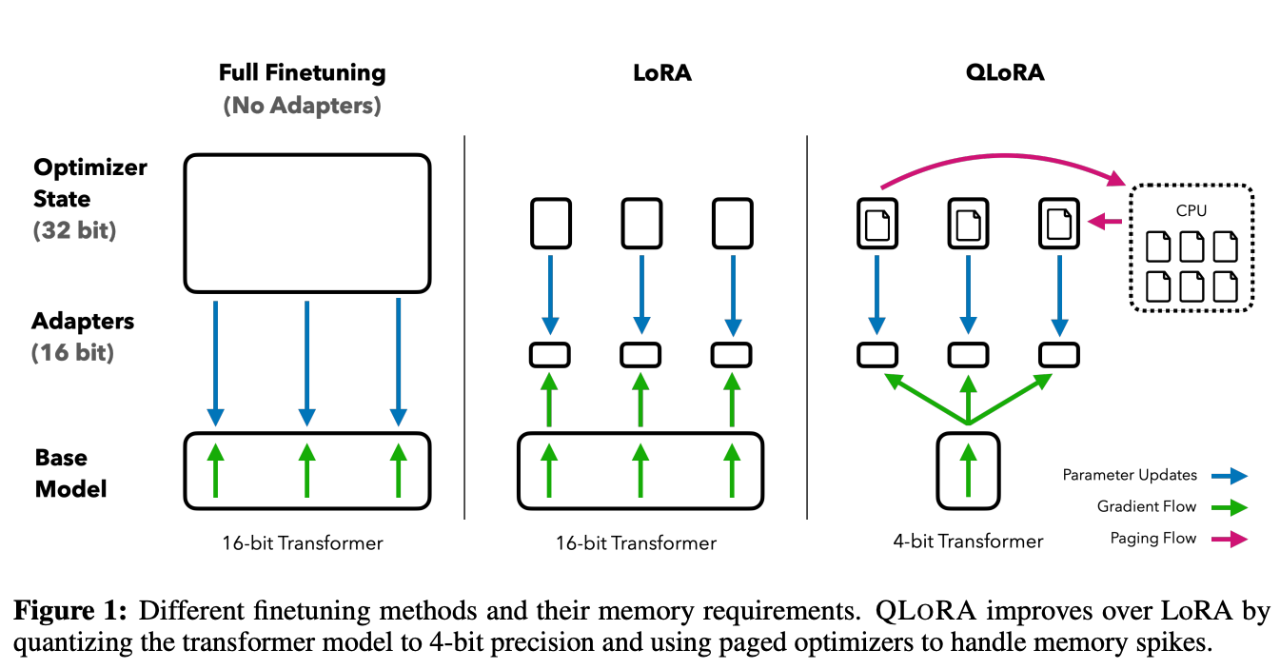
上图中描述了 LoRA 与 QLoRA 在微调训练的时候的区别,从 QLoRA 的名字可以看出,QLoRA 实际上是 Quantize+LoRA 技术,简单的说就是把大模型(Base Model)在训练的时候从 16bit 压缩到 4bit。从而降低训练的显存。
-
4 位 NormalFloat,QLoRA 使用 NF4(Normal Float 4)bit 来量化压缩预训练模型。这是一种优化的 4 位量化方法,它针对神经网络权重通常遵循零中心正态分布的特性进行优化。使用标准正态分布函数将权重缩放到[-1, 1]的范围内。相比传统的 4 位量化,它的权重信息损失少,从而提高了模型量化的整体精度。
-
双重量化,双重量化是一种内存优化策略,它对量化所使用的常数进行二次量化,进一步减小内存占用。这意味着我们可以在保持精度的同时,降低了内存需求。
-
Page Optimizer,这是一种内存管理技术,利用了 NVIDIA 的统一内存特性,在 CPU 和 GPU 之间进行自动 page 对 page 传输,它在 GPU 内存不足时,可以将一部分数据暂时移到 CPU 内存,需要时再移回。这降低了在大型模型训练时由于内存不足而造成的问题。
在我们的平台经过实测,训练 33B 的模型最低需要 26G 显存。但是需要把 batch-szie 设置为 1,这样训练速度会比较慢。在实际操作中可以再适当加大 batch size 的值,配合 4bit 量化,就可以在少量 GPU 资源情况下训练 33B 大模型了,当然 13B 的大模型使用 QLORA 同样效果不错。
目前最新版本的 PEFT 库也添加了对 QLoRA 的支持,喜欢代码的同学可以去深入了解下。
3.量化推理介绍
3.1 GPTQ 量化介绍
GPTQ(Generative Pretrained Transformer Quantization)是一种新的后训练量化方法,可以有效地执行对有数百亿参数的模型的量化,并且能够将这些模型压缩到每个参数 3 或 4 位,而不会有显著的精度损失,论文参考https://arxiv.org/abs/2210.17323。
所谓后训练量化是指在模型训练完成之后进行量化,模型的权重会从 32 位浮点数(或其他较高精度格式)转换为较低精度格式,例如 4 位整数。这种转换大大减小了模型的大小,并减少了运行模型所需的计算量。但是,这也可能会导致一定程度的精度损失。
3.2 GPTQ 量化数据对比
目前业界有几种量化方法,包括 GGML,GPTQ 等,经过实测,我们发现 GPTQ 量化部署精度损失少,性能也不错。
我们通过对 13B 的模型进行 4bit 量化测试,发现经过 GPTQ 量化后的对比如下:

4.实战:kubeai 平台大模型训练与推理
前面我们介绍了大模型的训练技术:LoRA 与 QLoRA 的工作原理,介绍了通过 GPTQ 量化部署的步骤。我们把这些步骤集成在 KubeAI 的训练推理平台中,供大家研究,并同时提供 7B,13B,33B 大模型备选。KubeAI 中选择 GPT 服务/定制版(Finetune)即可体验。
4.1 kubeAI 平台的训练与推理工作流程
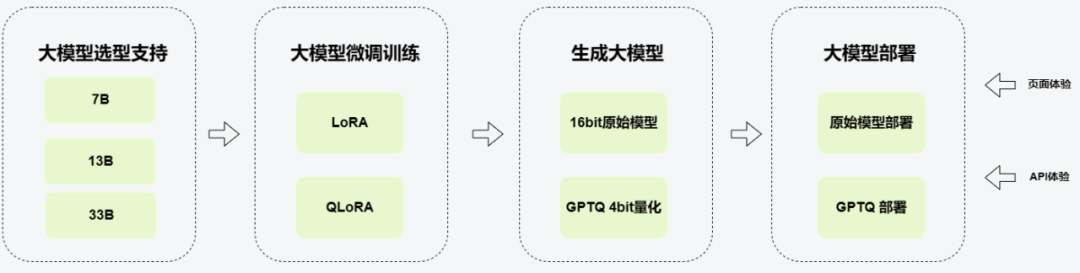
-
大模型选型支持,kubeAI 平台提供(7B,13B,33B)三种类型,后续逐渐增加更多支持。
-
大模型微调训练,现在支持 LoRA,QLoRA 两种方式,后续会增加其他方式。
-
训练后,会产生两个大模型,一个是 16Bit 的原始模型,一个是 GPTQ4bit 量化后的模型(配合 QLoRA)。
-
我们提供一键部署的功能,用户选择对应的模型后,可以一键部署成服务,并提供页面与 API 接口供用户体验效果。
4.2 用户在 kubeAI 进行训练与推理部署大模型的步骤

-
选择大模型,目前提供(7B,13B,33B)三个版本。
-
上传训练数据,目前支持 alpaca 数据格式。
-
配置训练参数,只需要依据 GPU 情况配置 batch size 与训练步骤,大部分使用默认参数即可。
-
点击开始训练。
-
训练结束后选择模型,点击部署,即可一键部署成服务。
-
部署服务后,点击访问链接,会有一个访问页面,页面上会提供相应的 API 调用接口。
4.3 kubeAI 平台基于知识库的推理功能
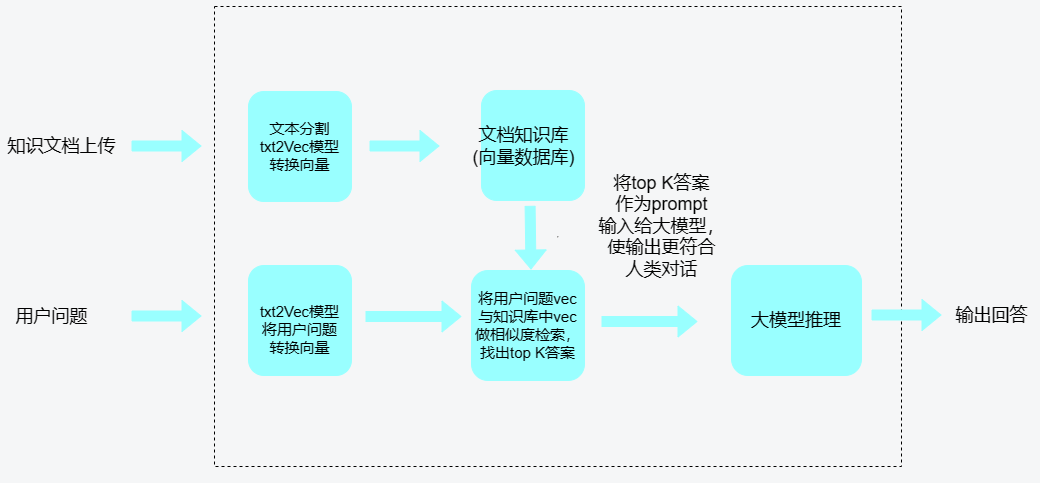
-
推理大模型实现,可离线部署,可以针对专业场景做训练优化。
-
文本向量模型,可离线部署,还可以针对局部场景做训练优化。
-
可快速实现接入多种数据源,支持 pdf、txt、md、docx、csv 等文件类型接入。
-
在分句、文档读取等方面,针对中文使用场景优化。
5.总结
我们调研了大模型的微调训练方法 LoRA 与 QLoRA,以及大模型的推理部署 GPTQ 量化部署。把上面的微调训练到推理部署的整个链路集成到 kubeAI 平台上,提供给大家快速实验。此外还集成了以文档形式上传到知识库,配合知识库进行推理的场景。
大模型的训练与推理方法除了以上所提 LORA、QLORA、GPTQ 外,还有其他技术。因为大模型社区比较火爆,后面肯定会有更优的微调训练与量化部署技术。后续我们会持续跟踪,如果在效果与性能上优于当前支持的方法,平台也将及时基于目前的框架继续集成这些新的方法。
*文/linggong
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!




![最适合新手的Java项目/SpringBoot+SSM项目《苍穹外卖》/项目实战、笔记(超详细、新手)[持续更新……]](https://img-blog.csdnimg.cn/9b88e095844946b8873fc535ef3e99e4.png)